I sidste måned dækkede jeg en Special Islands-udfordring. Opgaven var at identificere aktivitetsperioder for hvert service-id, og tolerere et hul på op til et input antal sekunder (@allowedgap ). Forbeholdet var, at løsningen skulle være kompatibel før 2012, så du kunne ikke bruge funktioner som LAG og LEAD eller samle vinduesfunktioner med en ramme. Jeg fik en række meget interessante løsninger postet i kommentarerne af Toby Ovod-Everett, Peter Larsson og Kamil Kosno. Sørg for at gennemgå deres løsninger, da de alle er ret kreative.
Mærkeligt nok kørte en række af løsningerne langsommere med det anbefalede indeks end uden. I denne artikel foreslår jeg en forklaring på dette.
Selvom alle løsninger var interessante, ville jeg her fokusere på løsningen af Kamil Kosno, som er ETL-udvikler hos Zopa. I sin løsning brugte Kamil en meget kreativ teknik til at efterligne LAG og LEAD uden LAG og LEAD. Du vil sandsynligvis finde teknikken praktisk, hvis du skal udføre LAG/LEAD-lignende beregninger ved hjælp af kode, der er kompatibel med før 2012.
Hvorfor er nogle løsninger hurtigere uden det anbefalede indeks?
Som en påmindelse foreslog jeg at bruge følgende indeks til at understøtte løsningerne på udfordringen:
OPRET INDEX idx_sid_ltm_lid PÅ dbo.EventLog(serviceid, logtime, logid);
Min før 2012-kompatible løsning var følgende:
DECLARE @allowedgap AS INT =66; -- i sekunder MED C1 AS( VÆLG logid, serviceid, logtid AS s, -- vigtigt, 's'> 'e', for senere at bestille DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth FROM C1 UNPIVOT(logtime FOR hændelsestype IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 SOM grp FRA C2 CROSS APPLY ( VALUES( CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' OG tæller =1) ELLER (hændelsestype ='e' OG tæller =0))SELECT serviceid, s AS starttid, DATEADD(second, -@allowedgap, e) AS endtimeFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;
Figur 1 har planen for min løsning med det anbefalede indeks på plads.
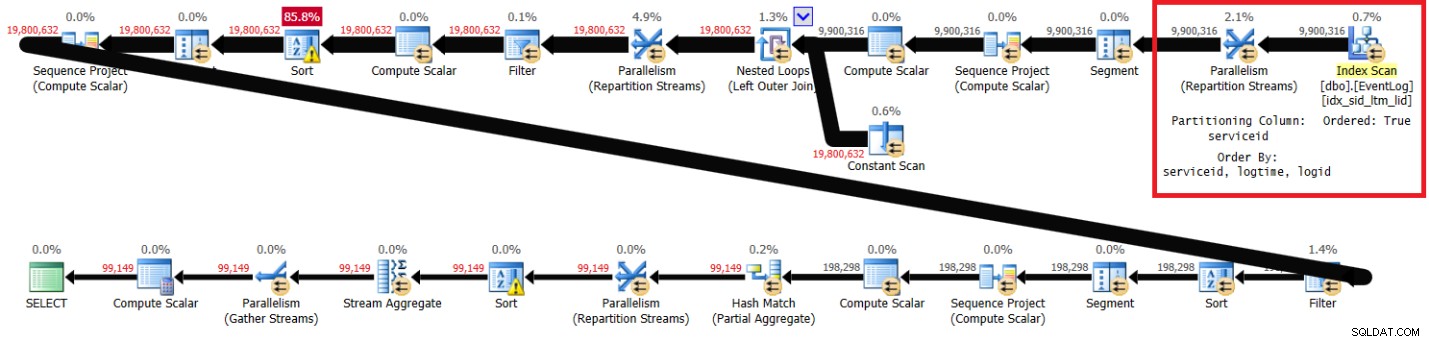 Figur 1:Plan for Itziks løsning med anbefalet indeks
Figur 1:Plan for Itziks løsning med anbefalet indeks
Bemærk, at planen scanner det anbefalede indeks i nøglerækkefølge (Bestilt egenskab er sand), opdeler strømmene efter service-id ved hjælp af en ordrebevarende udveksling og anvender derefter den indledende beregning af rækkenumre baseret på indeksrækkefølge uden behov for sortering. Følgende er ydeevnestatistikken, som jeg fik for denne forespørgselsudførelse på min bærbare computer (forløbet tid, CPU-tid og topventetid udtrykt i sekunder):
forløbet:43, CPU:60, logisk læsning:144.120, top ventetid:CXPACKET:166
Jeg droppede derefter det anbefalede indeks og kørte løsningen igen:
DROP INDEX idx_sid_ltm_lid TIL dbo.EventLog;
Jeg fik planen vist i figur 2.
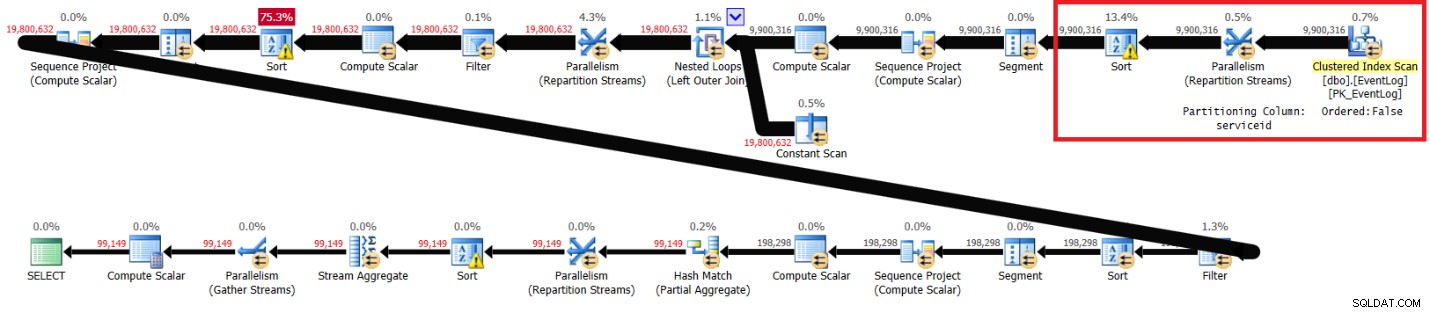 Figur 2:Plan for Itziks løsning uden anbefalet indeks
Figur 2:Plan for Itziks løsning uden anbefalet indeks
De fremhævede afsnit i de to planer viser forskellen. Planen uden det anbefalede indeks udfører en uordnet scanning af det klyngede indeks, opdeler strømmene efter serviceid ved hjælp af en ikke-ordrebevarende udveksling og sorterer derefter rækkerne, som vinduesfunktionen har brug for (efter serviceid, logtime, logid). Resten af arbejdet ser ud til at være det samme i begge planer. Du skulle tro, at planen uden det anbefalede indeks skulle være langsommere, da den har en ekstra slags, som den anden plan ikke har. Men her er præstationsstatistikken, som jeg fik for denne plan på min bærbare computer:
forløbet:31, CPU:89, logiske læsninger:172.598, CXPACKET venter:84
Der er mere CPU-tid involveret, hvilket til dels skyldes den ekstra sortering; der er mere I/O involveret, sandsynligvis på grund af yderligere sorteringsspild; dog er den forløbne tid omkring 30 procent hurtigere. Hvad kunne forklare dette? En måde at prøve at finde ud af dette på er at køre forespørgslen i SSMS med Live Query Statistics-indstillingen aktiveret. Da jeg gjorde dette, sluttede operatøren af parallelisme (omfordelingsstrømme) længst til højre på 6 sekunder uden det anbefalede indeks og på 35 sekunder med det anbefalede indeks. Den vigtigste forskel er, at førstnævnte får dataene forudbestilt fra et indeks og er en ordrebevarende udveksling. Sidstnævnte får dataene uordnet og er ikke en ordrebevarende udveksling. Ordrebevarende børser har en tendens til at være dyrere end ikke-ordrebevarende. Også, i det mindste i den længst højre del af planen indtil den første sortering, leverer førstnævnte rækkerne i samme rækkefølge som udvekslingsopdelingskolonnen, så du ikke får alle tråde til virkelig at behandle rækkerne parallelt. Den senere leverer rækkerne uordnet, så du får alle tråde til at behandle rækker virkelig parallelt. Du kan se, at den øverste ventetid i begge planer er CXPACKET, men i førstnævnte tilfælde er ventetiden det dobbelte af sidstnævnte, hvilket fortæller dig, at parallelismehåndtering i sidstnævnte tilfælde er mere optimal. Der kan være nogle andre faktorer på spil, som jeg ikke tænker på. Hvis du har yderligere ideer, der kan forklare den overraskende præstationsforskel, så del venligst.
På min bærbare resulterede dette i, at udførelsen uden at det anbefalede indeks var hurtigere end det med det anbefalede indeks. Alligevel var det på en anden testmaskine omvendt. Når alt kommer til alt, har du en ekstra slags med spildpotentiale.
Af nysgerrighed testede jeg en seriel udførelse (med MAXDOP 1-muligheden) med det anbefalede indeks på plads og fik følgende præstationsstatistik på min bærbare computer:
forløbet:42, CPU:40, logiske tal:143.519
Som du kan se, svarer køretiden til køretiden for den parallelle udførelse med det anbefalede indeks på plads. Jeg har kun 4 logiske CPU'er i min bærbare computer. Selvfølgelig kan dit kilometertal variere med forskellig hardware. Pointen er, at det er umagen værd at teste forskellige alternativer, inklusive med og uden den indeksering, som du skulle tro, det skulle hjælpe. Resultaterne er nogle gange overraskende og kontraintuitive.
Kamils løsning
Jeg var virkelig fascineret af Kamils løsning og kunne især godt lide den måde, hvorpå han emulerede LAG og LEAD med en før 2012-kompatibel teknik.
Her er koden, der implementerer det første trin i løsningen:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog;
Denne kode genererer følgende output (viser kun data for serviceid 1):
serviceid logtime end_time starttime---------- -------------------- ---------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Dette trin beregner to rækkenumre, der er en adskilt for hver række, opdelt efter serviceid og ordnet efter logtid. Det aktuelle rækkenummer repræsenterer sluttidspunktet (kald det sluttid), og det aktuelle rækkenummer minus én repræsenterer starttidspunktet (kald det starttid).
Følgende kode implementerer det andet trin i løsningen:
MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FRA RNS UNPIVOT(rækkenummer FOR time_type IN (starttid, sluttid)) AS U;
Dette trin genererer følgende output:
serviceid logtime rownum time_type---------- -------------------- ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 sluttid1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:0 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-08-09:09 4 sluttidspunkt1 2018-09-12 08:05:00 4 starttidspunkt1 2018-09-12 08:05:00 5 sluttidspunkt1 2018-09-12 08:06:02 5 starttidspunkt1 2018-09-12:06 slut ...
Dette trin ophæver hver række i to rækker, og duplikerer hver logindtastning – én gang for tidstypen start_time og en anden for sluttid. Som du kan se, ud over minimum- og maksimumrækkenumrene, vises hvert rækkenummer to gange – én gang med logtidspunktet for den aktuelle begivenhed (start_tid) og en anden med logtidspunktet for den forrige begivenhed (sluttidspunkt).
Følgende kode implementerer det tredje trin i løsningen:
MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FRA RNS UNPIVOT(rækkenummer FOR time_type IN (start_tid, sluttid)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_tid, sluttid)) AS P;
Denne kode genererer følgende output:
serviceid rownum start_time end_time -------------------- ------------ --------------- ----------------------------------1 0 2018-09-12 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:01:2018- 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12:08:0 2018-09-12 08:05:001 6 NULL 2018-09-12 08:06:02...
Dette trin pivoterer dataene, grupperer par af rækker med det samme rækkenummer og returnerer én kolonne for den aktuelle hændelseslogtid (starttid) og en anden for den forrige hændelseslogtid (sluttid). Denne del emulerer effektivt en LAG-funktion.
Følgende kode implementerer det fjerde trin i løsningen:
DECLARE @allowedgap AS INT =66; MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT( MAX(logtime) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Denne kode genererer følgende output:
serviceid rownum start_time end_time start_time_grp end_time_grp--------- ------- -------------------- ---- ---------------- -------------------- --------------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2... /pre>Dette trin filtrerer par, hvor forskellen mellem det forrige sluttidspunkt og det aktuelle starttidspunkt er større end det tilladte mellemrum, og rækker med kun én hændelse. Nu skal du forbinde hver aktuelle rækkes starttidspunkt med den næste rækkes sluttidspunkt. Dette kræver en LEAD-lignende beregning. For at opnå dette opretter koden igen rækkenumre, der er én fra hinanden, kun denne gang repræsenterer det aktuelle rækkenummer starttidspunktet (start_time_grp ) og det aktuelle rækkenummer minus én repræsenterer sluttidspunktet (end_time_grp).
Som før er næste trin (nummer 5) at frigøre rækkerne. Her er koden, der implementerer dette trin:
DECLARE @allowedgap AS INT =66; MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog), Ranger as (SELECT) serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Ranges UNPIVOT(grp FOR grp_type IN(starttidspunkt_grp, sluttidspunkt_grp)) AS U;Output:
serviceid rownum start_time end_time grp grp_type---------------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 9-2018-08:end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Som du kan se, er grp-kolonnen unik for hver ø inden for et service-id.
Trin 6 er det sidste trin i løsningen. Her er koden, der implementerer dette trin, som også er den komplette løsningskode:
DECLARE @allowedgap AS INT =66; MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog), Ranger as (SELECT) serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) IS NOT NULL OG MAX(end_time) IS NOT NULL);Dette trin genererer følgende output:
serviceid start_time end_time -------------------------------------- ------ ----------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Dette trin grupperer rækkerne efter serviceid og grp, filtrerer kun relevante grupper og returnerer den minimale starttid som begyndelsen af øen og den maksimale sluttid som slutningen af øen.
Figur 3 har den plan, jeg fik for denne løsning med det anbefalede indeks på plads:
OPRET INDEX idx_sid_ltm_lid PÅ dbo.EventLog(serviceid, logtime, logid);Planlæg med anbefalet indeks i figur 3.
Figur 3:Plan for Kamils løsning med anbefalet indeks
Her er ydeevnestatistikken, som jeg fik for denne udførelse på min bærbare computer:
forløbet:44, CPU:66, logisk læsning:72979, top ventetid:CXPACKET:148Jeg droppede derefter det anbefalede indeks og kørte løsningen igen:
DROP INDEX idx_sid_ltm_lid TIL dbo.EventLog;Jeg fik planen vist i figur 4 for udførelsen uden det anbefalede indeks.
Figur 4:Plan for Kamils løsning uden anbefalet indeks
Her er præstationsstatistikken, som jeg fik for denne udførelse:
forløbet:30, CPU:85, logisk læsning:94813, top ventetid:CXPACKET:70Køretider, CPU-tider og CXPACKET-ventetider er meget lig min løsning, selvom de logiske læsninger er lavere. Kamils løsning kører også hurtigere på min bærbare computer uden det anbefalede indeks, og det ser ud til, at det skyldes lignende årsager.
Konklusion
Anomalier er en god ting. De gør dig nysgerrig og får dig til at gå og undersøge årsagen til problemet og som et resultat heraf lære nye ting. Det er interessant at se, at nogle forespørgsler på visse maskiner kører hurtigere uden den anbefalede indeksering.
Endnu en gang tak til Toby, Peter og Kamil for jeres løsninger. I denne artikel dækkede jeg Kamils løsning med hans kreative teknik til at efterligne LAG og LEAD med rækkenumre, unpivoting og pivotering. Du vil finde denne teknik nyttig, når du har brug for LAG- og LEAD-lignende beregninger, der skal understøttes i miljøer før 2012.