Når man ser på forespørgselsydeevne, er der mange gode informationskilder i SQL Server, og en af mine favoritter er selve forespørgselsplanen. I de sidste adskillige udgivelser, især startende med SQL Server 2012, har hver ny version inkluderet flere detaljer i udførelsesplanerne. Mens listen over forbedringer fortsætter med at vokse, er her et par egenskaber, som jeg har fundet værdifulde:
- NonParallelPlanReason (SQL Server 2012)
- Resterende prædikat pushdown-diagnostik (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- tempdb spilddiagnostik (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Sporingsflag aktiveret (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Operator Query Execution Statistics (SQL Server 2014 SP2, SQL Server 2016)
- Maksimal hukommelse aktiveret for en enkelt forespørgsel (SQL Server 2014 SP2, SQL Server 2016 SP1)
For at se, hvad der findes for hver version af SQL Server, skal du besøge siden Showplan Schema, hvor du kan finde skemaet for hver version siden SQL Server 2005.
Så meget som jeg elsker alle disse ekstra data, er det vigtigt at bemærke, at nogle oplysninger er mere relevante for en faktisk udførelsesplan, i forhold til en estimeret en (f.eks. tempdb-spildinformation). Nogle dage kan vi fange og bruge den faktiske plan til fejlfinding, andre gange skal vi bruge den estimerede plan. Meget ofte får vi den estimerede plan – den plan, der potentielt er blevet brugt til problematiske eksekveringer – fra SQL Servers plan-cache. Og det er passende at trække individuelle planer, når du tuner en specifik forespørgsel eller sæt eller forespørgsler. Men hvad med, når du vil have ideer til, hvor du kan fokusere din tuning-indsats i form af mønstre?
SQL Server-plancachen er en fantastisk kilde til information, når det kommer til justering af ydeevne, og jeg mener ikke blot fejlfinding og forsøg på at forstå, hvad der har kørt i et system. I dette tilfælde taler jeg om minedata fra selve planerne, som findes i sys.dm_exec_query_plan, gemt som XML i kolonnen query_plan.
Når du kombinerer disse data med information fra sys.dm_exec_sql_text (så du nemt kan se teksten i forespørgslen) og sys.dm_exec_query_stats (udførelsesstatistik), kan du pludselig begynde at lede efter ikke kun de forespørgsler, der er de tunge hitters eller udfører oftest, men de planer, der indeholder en bestemt jointype, eller indeksscanning, eller dem, der har de højeste omkostninger. Dette kaldes almindeligvis mining af plan-cachen, og der er flere blogindlæg, der fortæller om, hvordan man gør dette. Min kollega, Jonathan Kehayias, siger, at han hader at skrive XML, men han har adskillige indlæg med forespørgsler til mining af planens cache:
- Justering af 'omkostningstærskel for parallelitet' fra Plan-cachen
- Find implicitte kolonnekonverteringer i plancachen
- Sådan finder du, hvilke forespørgsler i planens cache, der bruger et bestemt indeks
- Gravning i SQL Plan-cachen:Find manglende indekser
- Sådan finder du nøgleopslag i plancachen
Hvis du aldrig har udforsket, hvad der er i din plan-cache, er forespørgslerne i disse indlæg en god start. Planens cache har dog sine begrænsninger. For eksempel er det muligt at udføre en forespørgsel og ikke få planen til at gå i cachen. Hvis du f.eks. har aktiveret muligheden for optimering til adhoc-arbejdsbelastninger, gemmes den kompilerede plan-stub ved første udførelse i planens cache, ikke den fulde kompilerede plan. Men den største udfordring er, at plancachen er midlertidig. Der er mange hændelser i SQL Server, som kan rydde planens cache helt eller rydde den for en database, og planer kan ældes ud af cachen, hvis de ikke bruges, eller fjernes efter en genkompilering. For at bekæmpe dette skal du typisk enten forespørge planens cache regelmæssigt eller snapshot af indholdet til en tabel på en planlagt basis.
Dette ændres i SQL Server 2016 med Query Store.
Når en brugerdatabase har Query Store aktiveret, bliver teksten og planerne for forespørgsler, der udføres mod denne database, fanget og bevaret i interne tabeller. I stedet for et midlertidigt syn på, hvad der i øjeblikket udføres, har vi et langsigtet billede af, hvad der tidligere er udført. Mængden af data, der opbevares, bestemmes af indstillingen CLEANUP_POLICY, som som standard er 30 dage. Sammenlignet med en plan-cache, der kan repræsentere blot et par timers udførelse af forespørgsler, er Query Store-dataene en game changer.
Overvej et scenario, hvor du laver en indeksanalyse – du har nogle indekser, der ikke bliver brugt, og du har nogle anbefalinger fra de manglende indeks-DMV'er. De manglende indeks-DMV'er giver ingen detaljer om, hvilken forespørgsel der genererede den manglende indeksanbefaling. Du kan forespørge planens cache ved at bruge forespørgslen fra Jonathans indlæg om Finding Missing Indexes. Hvis jeg udfører det mod min lokale SQL Server-instans, får jeg et par rækker af output relateret til nogle forespørgsler, jeg kørte tidligere.

Jeg kan åbne planen i Plan Explorer, og jeg kan se, at der er en advarsel på SELECT-operatøren, som er for det manglende indeks:
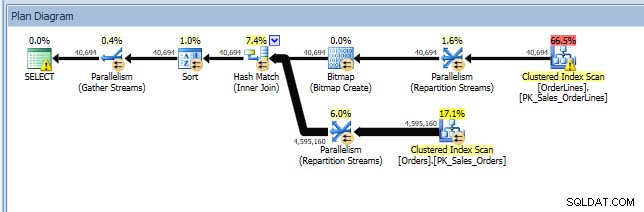
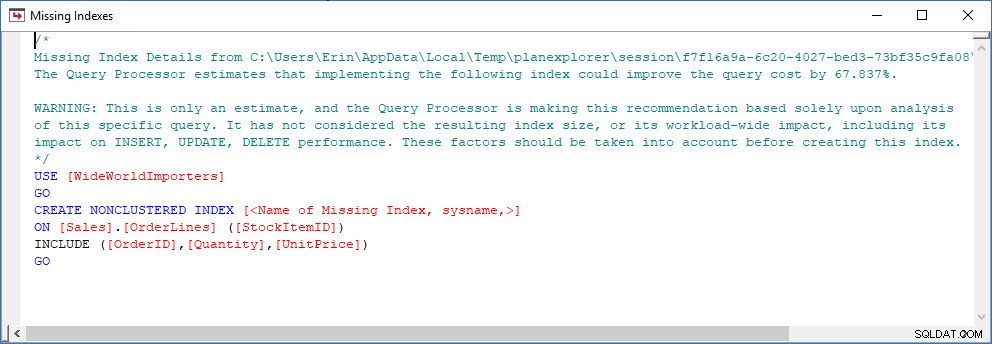
Dette er en god start, men igen, mit output afhænger af, hvad der er i cachen. Jeg kan tage Jonathans forespørgsel og ændre for Query Store og derefter køre den mod min demo WideWorldImporters-database:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
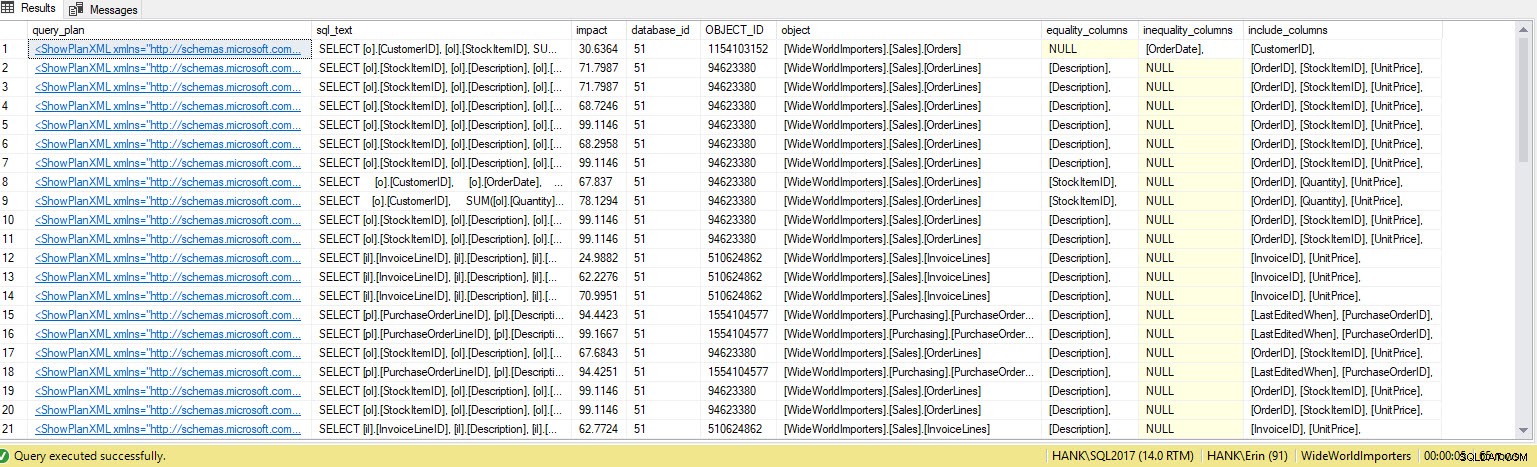
Jeg får mange flere rækker i outputtet. Igen repræsenterer Query Store-dataene en større visning af forespørgsler udført mod systemet, og brugen af disse data giver os en omfattende metode til ikke blot at bestemme, hvilke indekser der mangler, men hvilke forespørgsler disse indekser ville understøtte. Herfra kan vi grave dybere ned i Query Store og se på ydeevnemålinger og udførelsesfrekvens for at forstå virkningen af at oprette indekset og beslutte, om forespørgslen udføres ofte nok til at berettige indekset.
Hvis du ikke bruger Query Store, men du bruger SentryOne, kan du hente den samme information fra SentryOne-databasen. Forespørgselsplanen er gemt i dbo.PerformanceAnalysisPlan-tabellen i et komprimeret format, så den forespørgsel, vi bruger, er en lignende variant som den ovenfor, men du vil bemærke, at DEKOMPRESS-funktionen også bruges:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; På et SentryOne-system havde jeg følgende output (og selvfølgelig at klikke på en af query_plan-værdierne åbner den grafiske plan):

Et par fordele SentryOne tilbyder i forhold til Query Store er, at du ikke behøver at aktivere denne type indsamling pr. database, og den overvågede database behøver ikke at understøtte lagerkravene, da alle data er lagret i depotet. Du kan også fange disse oplysninger på tværs af alle understøttede versioner af SQL Server, ikke kun dem, der understøtter Query Store. Bemærk dog, at SentryOne kun indsamler forespørgsler, der overskrider tærskler såsom varighed og læsninger. Du kan justere disse standardtærskler, men det er et element, du skal være opmærksom på, når du miner SentryOne-databasen:ikke alle forespørgsler indsamles muligvis. Derudover er funktionen DEKOMPRESS ikke tilgængelig før SQL Server 2016; for ældre versioner af SQL Server, vil du enten ønske at:
- Sikkerhedskopier SentryOne-databasen og gendan den på SQL Server 2016 eller nyere for at køre forespørgslerne;
- bcp dataene ud af tabellen dbo.PerformanceAnalysisPlan og importer dem til en ny tabel på en SQL Server 2016-instans;
- forespørg SentryOne-databasen via en sammenkædet server fra en SQL Server 2016-instans; eller,
- forespørg databasen fra applikationskoden, som kan parse for specifikke ting efter dekomprimering.
Med SentryOne har du mulighed for at mine ikke kun plancachen, men også de data, der opbevares i SentryOne-depotet. Hvis du kører SQL Server 2016 eller nyere, og du har aktiveret Query Store, kan du også finde disse oplysninger i sys.query_store_plan . Du er ikke begrænset til kun dette eksempel på at finde manglende indekser; alle forespørgsler fra Jonathans andre plan-cache-indlæg kan ændres til at blive brugt til at mine data fra SentryOne eller fra Query Store. Yderligere, hvis du er fortrolig nok med XQuery (eller villig til at lære), kan du bruge Showplan-skemaet til at finde ud af, hvordan du analyserer planen for at finde den information, du ønsker. Dette giver dig mulighed for at finde mønstre og anti-mønstre i dine forespørgselsplaner, som dit team kan rette, før de bliver et problem.