Tænker du på et databasedesign til revisionslogning? Husk, hvad der skete med Hans og Grete:De troede, at det var en god måde at spore deres skridt, at efterlade et enkelt spor af brødkrummer.
Når vi designer en datamodel, er vi trænet i at anvende filosofien om, at nu er alt, der eksisterer . For eksempel, hvis vi designer et skema til at gemme priser for et produktkatalog, tror vi måske, at databasen kun behøver at fortælle os prisen på hvert produkt på nuværende tidspunkt. Men hvis vi ville vide, om priserne blev ændret, og i givet fald hvornår og hvordan disse ændringer fandt sted, ville vi være i problemer. Selvfølgelig kunne vi designe databasen specifikt til at føre en kronologisk registrering af ændringer – almindeligvis kendt som et revisionsspor eller revisionslog.
Revisionslogning gør det muligt for en database at have en 'hukommelse' af tidligere hændelser. Hvis vi fortsætter med prislisteeksemplet, vil en ordentlig revisionslog gøre det muligt for databasen at fortælle os præcis, hvornår en pris blev opdateret, hvad prisen var før den blev opdateret, hvem der opdaterede den, og hvorfra.
Løsninger til logføring af databaserevision
Det ville være fantastisk, hvis databasen kunne holde et øjebliksbillede af sin tilstand for hver ændring, der sker i dens data. På denne måde kunne du gå tilbage til et hvilket som helst tidspunkt og se, hvordan dataene var på det præcise tidspunkt, ligesom hvis du spolede en film tilbage. Men den måde at generere revisionslogning på er åbenbart umulig; den resulterende mængde information og den tid, det ville tage at generere logfilerne, ville være for høj.
Revisionslogningsstrategier er kun baseret på generering af revisionsspor for data, der kan slettes eller ændres. Enhver ændring i dem skal revideres for at rulle ændringer tilbage, forespørge data i historiktabeller eller spore mistænkelig aktivitet.
Der er flere populære teknikker til revisionslogning, men ingen af dem tjener ethvert formål. De mest effektive er ofte dyre, ressourcekrævende eller ydeevneforringende. Andre er billigere med hensyn til ressourcer, men er enten ufuldstændige, besværlige at vedligeholde eller kræver et offer i designkvalitet. Hvilken strategi du vælger, afhænger af applikationskravene og de ydeevnegrænser, ressourcer og designprincipper, du skal respektere.
Out-of-the-box logningsløsninger
Disse revisionslogningsløsninger fungerer ved at opsnappe alle kommandoer sendt til databasen og generere en ændringslog i et separat lager. Sådanne programmer tilbyder flere konfigurations- og rapporteringsmuligheder for at spore brugerhandlinger. De kan logge alle handlinger og forespørgsler sendt til en database, selv når de kommer fra brugere med de højeste privilegier. Disse værktøjer er optimeret til at minimere ydeevnepåvirkningen, men det koster ofte penge.
Prisen på dedikerede revisionssporløsninger kan retfærdiggøres, hvis du håndterer meget følsomme oplysninger (såsom medicinske journaler), hvor enhver ændring af dataene skal overvåges perfekt og auditeres, og revisionssporet skal være uændret. Men når kravene til revisionssporet ikke er så strenge, kan omkostningerne ved en dedikeret logningsløsning være for høje.
De native overvågningsværktøjer, der tilbydes af relationelle databasesystemer (RDBMS'er), kan også bruges til at generere revisionsspor. Tilpasningsmuligheder tillader filtrering af, hvilke hændelser der registreres, for ikke at generere unødvendig information eller overbelaste databasemotoren med logningsoperationer, der ikke vil blive brugt senere. De logfiler, der genereres på denne måde, tillader detaljeret sporing af de operationer, der udføres på tabellerne. De er dog ikke nyttige til at forespørge i historietabeller, da de kun registrerer hændelser.
Den mest økonomiske mulighed for at vedligeholde et revisionsspor er at designe din database specifikt til revisionslogning. Denne teknik er baseret på log-tabeller, der er udfyldt af triggere eller mekanismer, der er specifikke for den applikation, der opdaterer databasen. Der er ingen universelt accepteret tilgang til revisionslogning af databasedesign, men der er flere almindeligt anvendte strategier, som hver især har sine fordele og ulemper.
Database Audit Logging Design Teknikker
Rækkeversionering til revisionslogning
En måde at vedligeholde et revisionsspor for en tabel på er at tilføje et felt, der angiver versionsnummeret for hver post. Indsættelser i tabellen gemmes med et oprindeligt versionsnummer. Eventuelle ændringer eller sletninger bliver faktisk til indsættelsesoperationer, hvor nye poster genereres med de opdaterede data, og versionsnummeret øges med én. Du kan se et eksempel på dette revisionslogningsdesign nedenfor:
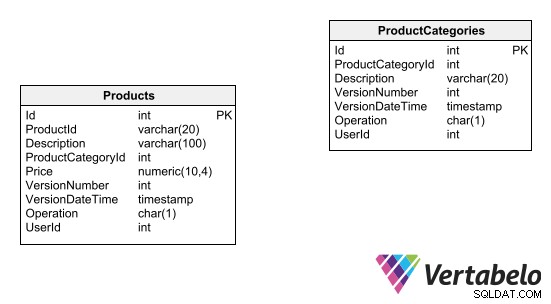
Bemærk:Tabeldesign med indlejret rækkeversionering kan ikke sammenkædes af fremmednøglerelationer.
Ud over versionsnummeret bør der tilføjes nogle ekstra felter til tabellen for at bestemme oprindelsen og årsagen til hver ændring, der er foretaget i en post:
- Datoen/tidspunktet, hvor ændringen blev registreret.
- Brugeren og applikationen.
- Den udførte handling (indsæt, opdatering, slet) osv. For at revisionssporet skal være effektivt, skal tabellen kun understøtte indsættelser (opdateringer og sletninger bør ikke være tilladt). Tabellen kræver også nødvendigvis en surrogat primær nøgle, da enhver anden kombination af felter vil være genstand for gentagelse.
For at få adgang til de opdaterede tabeldata gennem forespørgsler skal du oprette en visning, der kun returnerer den seneste version af hver post. Derefter skal du erstatte navnet på tabellen med navnet på visningen i alle forespørgsler undtagen dem, der specifikt er beregnet til at se kronologien af poster.
Denne versioneringsmuligheds fordel er, at den ikke kræver brug af yderligere tabeller for at generere revisionssporet. Derudover tilføjes kun nogle få felter til de reviderede tabeller. Men det har en enorm ulempe:det vil tvinge dig til at lave nogle af de mest almindelige databasedesignfejl. Disse omfatter ikke at bruge referentiel integritet eller naturlige primære nøgler, når det er nødvendigt at gøre det, hvilket gør det umuligt at anvende de grundlæggende principper for design af entitetsforholdsdiagrammer. Du kan besøge disse nyttige ressourcer om databasedesignfejl, så du vil blive advaret om, hvilken anden praksis der bør undgås.
Skyggetabeller
En anden mulighed for revisionsspor er at generere en skyggetabel for hver tabel, der skal revideres. Skyggetabellerne indeholder de samme felter som de tabeller, de reviderer, plus de specifikke revisionsfelter (de samme som nævnt for rækkeversionsteknikken).
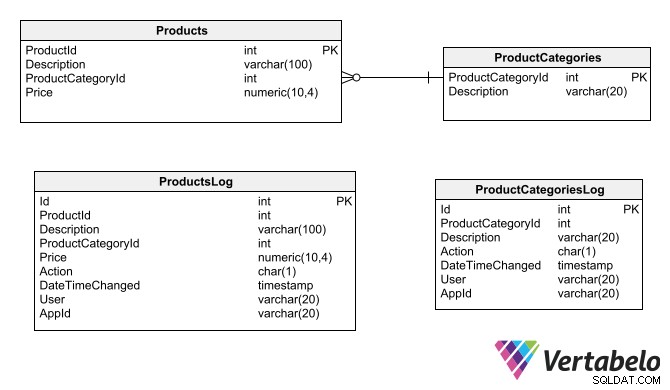
Skyggetabeller replikerer de samme felter som de tabeller, de reviderer, plus de felter, der er specifikke for revisionsformål.
For at generere revisionsspor i skyggetabeller er den sikreste mulighed at oprette indsæt, opdatere og slette triggere, der for hver berørt post i den originale tabel genererer en post i revisionstabellen. Udløserne skal have adgang til alle de revisionsoplysninger, du har brug for at registrere i skyggetabellen. Du bliver nødt til at bruge databasemotorens specifikke funktionalitet til at indhente data såsom den aktuelle dato og klokkeslæt, logget bruger, applikationsnavn og den placering (netværksadresse eller computernavn), hvor operationen opstod.
Hvis det ikke er muligt at bruge triggere, bør logikken til at generere revisionssporene være en del af applikationsstakken, i et lag, der er ideelt placeret lige før datapersistenslaget, så det kan opsnappe alle operationer rettet mod databasen.
Denne type logtabel bør kun tillade indsættelse af poster; hvis de tillader ændring eller sletning, vil revisionssporet ikke længere opfylde sin funktion. Tabellerne skal også bruge primære surrogatnøgler, da de originale tabellers afhængigheder og relationer ikke kan anvendes på dem.
Hvis tabellen, som du har oprettet et revisionsspor til, har tabeller, som det afhænger af, bør disse også have tilsvarende skyggetabeller. Dette er for at revisionssporet ikke bliver forældreløst, hvis der foretages ændringer i de andre tabeller.
Skyggetabeller er praktiske på grund af deres enkelhed, og fordi de ikke påvirker datamodellens integritet; revisionssporene forbliver i separate tabeller og er nemme at forespørge på. Ulempen er, at ordningen ikke er fleksibel:Enhver ændring i hovedbordets struktur skal afspejles i den tilsvarende skyggetabel, hvilket gør det vanskeligt at vedligeholde modellen. Derudover, hvis revisionslogning skal anvendes på et stort antal tabeller, vil antallet af skyggetabeller også være højt, hvilket gør skemavedligeholdelse endnu sværere.
Generiske tabeller til revisionslogning
En tredje mulighed er at oprette generiske tabeller til revisionslogfiler. Sådanne tabeller tillader logning af enhver anden tabel i skemaet. Der kræves kun to tabeller til denne teknik:
En overskriftstabel, der registrerer:
- Datoen og tidspunktet for ændringen.
- Navnet på tabellen.
- Nøglen til den berørte række.
- Brugerdataene.
- Den udførte handlingstype.
En detaljetabel, der registrerer:
- Navnene på hvert berørt felt.
- Feltværdien(erne) før ændringen.
- Feltværdien(erne) efter ændringen. (Du kan om nødvendigt udelade dette, da det kan fås ved at konsultere følgende post i revisionssporet eller den tilsvarende post i den reviderede tabel.)
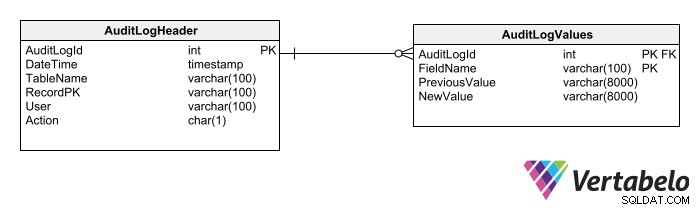
Brugen af generiske revisionslogtabeller sætter grænser for, hvilke typer data der kan revideres.
Denne revisionslogningsstrategis fordel er, at den ikke kræver andre tabeller end de to nævnte ovenfor. Desuden gemmes poster kun i den for de felter, der er påvirket af en handling. Det betyder, at der ikke er behov for at replikere en hel række af en tabel, når kun ét felt er ændret. Derudover giver denne teknik dig mulighed for at føre en log over så mange tabeller, som du vil – uden at fylde skemaet med et stort antal ekstra tabeller.
Ulempen er, at de felter, der gemmer værdierne, skal være af en enkelt type – og brede nok til at gemme selv de største af felterne i de tabeller, som du vil generere en revisionslog for. Det er mest almindeligt at bruge felter af typen VARCHAR, der accepterer et stort antal tegn.
Hvis du f.eks. skal generere en revisionslog for en tabel, der har ét VARCHAR-felt på 8.000 tegn, skal feltet, der gemmer værdierne i revisionstabellen, også have 8.000 tegn. Dette er sandt, selvom du bare gemmer et heltal i det felt. På den anden side, hvis din tabel har felter med komplekse datatyper, såsom billeder, binære data, BLOB'er osv., bliver du nødt til at serialisere deres indhold, så de kan gemmes i logtabellernes VARCHAR-felter.
Vælg dit databaserevisionslogdesign med omhu
Vi har set flere alternativer til at generere revisionslogning, men ingen af dem er rigtig optimale. Du skal vedtage en logningsstrategi, der ikke væsentligt påvirker ydeevnen af din database, ikke får den til at vokse for meget og kan opfylde dine sporbarhedskrav. Hvis du kun ønsker at gemme logfiler for nogle få borde, kan skyggetabeller være den mest bekvemme mulighed. Hvis du vil have fleksibiliteten til at logge enhver tabel, kan generiske logningstabeller være bedst.
Har du opdaget en anden måde at føre en revisionslog for dine databaser på? Del det i kommentarfeltet nedenfor – dine andre databasedesignere vil være meget taknemmelige!