Når SQL Server optimerer en forespørgsel, producerer den i en udforskningsfase kandidatplaner og vælger blandt dem den, der har de laveste omkostninger. Den valgte plan formodes at have den laveste køretid blandt de undersøgte planer. Sagen er, at optimeringsværktøjet kun kan vælge mellem strategier, der er kodet ind i den. For eksempel, når du optimerer gruppering og aggregering, på datoen for dette skrivende, kan optimeringsværktøjet kun vælge mellem Stream Aggregate og Hash Aggregate-strategier. Jeg dækkede de tilgængelige strategier i tidligere dele i denne serie. I del 1 dækkede jeg den forudbestilte Stream Aggregate-strategi, i Del 2 Sort + Stream Aggregate-strategien, i Del 3 Hash Aggregate-strategien og i Del 4 parallelle overvejelser.
Hvad SQL Server optimizer i øjeblikket ikke understøtter, er tilpasning og kunstig intelligens. Det vil sige, at hvis du kan finde ud af en strategi, der under visse forhold er mere optimal end dem, som optimizeren understøtter, kan du ikke forbedre optimizeren til at understøtte den, og optimizeren kan ikke lære at bruge den. Men hvad du kan gøre, er at omskrive forespørgslen ved hjælp af alternative forespørgselselementer, der kan optimeres med den strategi, du har i tankerne. I denne femte og sidste del af serien demonstrerer jeg denne teknik med forespørgselsjustering ved hjælp af forespørgselsrevisioner.
Stor tak til Paul White (@SQL_Kiwi) for hjælpen med nogle af de omkostningsberegninger, der præsenteres i denne artikel!
Ligesom i de foregående dele i serien, vil jeg bruge PerformanceV3-eksempeldatabasen. Brug følgende kode til at fjerne unødvendige indekser fra ordretabellen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Standard optimeringsstrategi
Overvej følgende grundlæggende grupperings- og aggregeringsopgaver:
Returner den maksimale ordredato for hver afsender, medarbejder og kunde.
For optimal ydeevne opretter du følgende understøttende indekser:
OPRET INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Følgende er de tre forespørgsler, du vil bruge til at håndtere disse opgaver, sammen med estimerede undertræomkostninger samt I/O, CPU og statistik over forløbet tid:
-- Forespørgsel 1-- Estimerede undertræsomkostninger:3,5344-- logiske læsninger:2484, CPU-tid:281 ms, forløbet tid:279 ms SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid; -- Forespørgsel 2-- Anslåede undertræsomkostninger:3,62798-- logiske læsninger:2610, CPU-tid:250 ms, forløbet tid:283 ms SELECT empid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY empid; -- Forespørgsel 3-- Anslåede undertræsomkostninger:4,27624-- logiske læsninger:3479, CPU-tid:406 ms, forløbet tid:506 ms SELECT custid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY custid;
Figur 1 viser planerne for disse forespørgsler:
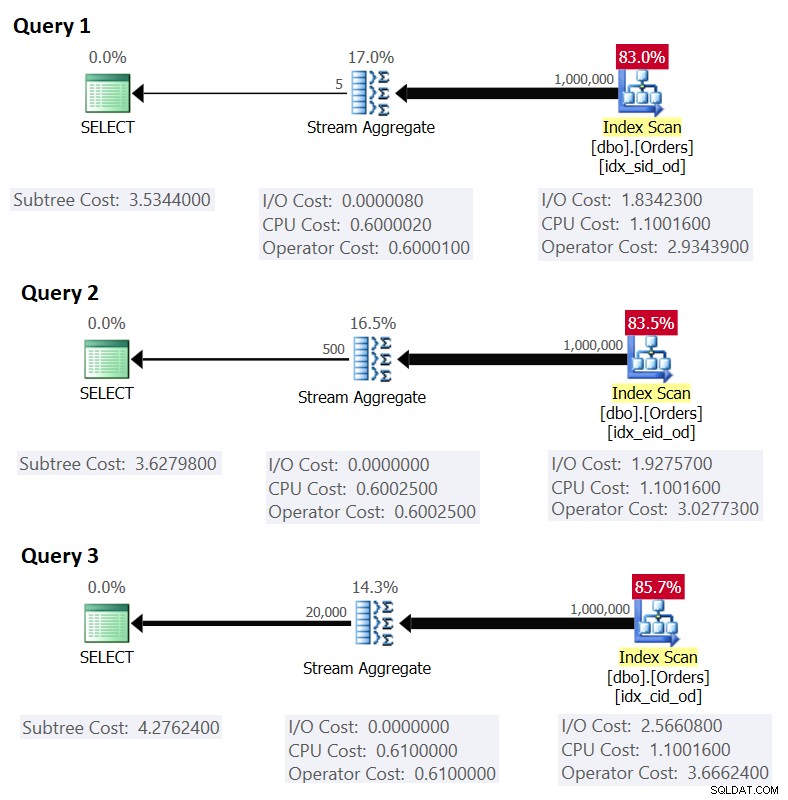 Figur 1:Planer for grupperede forespørgsler
Figur 1:Planer for grupperede forespørgsler
Husk, at hvis du har et dækkende indeks på plads, med grupperingssætkolonnerne som de førende nøglekolonner, efterfulgt af aggregeringskolonnen, vil SQL Server sandsynligvis vælge en plan, der udfører en ordnet scanning af det dækkende indeks, der understøtter Stream Aggregate-strategien . Som det fremgår af planerne i figur 1, er Index Scan-operatøren ansvarlig for det meste af planomkostningerne, og inden for den er I/O-delen den mest fremtrædende.
Før jeg præsenterer en alternativ strategi og forklarer de omstændigheder, hvorunder den er mere optimal end standardstrategien, lad os evaluere omkostningerne ved den eksisterende strategi. Da I/O-delen er den mest dominerende til at bestemme planomkostningerne for denne standardstrategi, lad os først lige vurdere, hvor mange logiske sidelæsninger, der kræves. Senere estimerer vi også planomkostningerne.
For at estimere antallet af logiske læsninger, som Index Scan-operatoren vil kræve, skal du vide, hvor mange rækker du har i tabellen, og hvor mange rækker der passer på en side baseret på rækkestørrelsen. Når du har disse to operander, er din formel for det påkrævede antal sider på bladniveauet i indekset derefter CEILING(1e0 * @numrows / @rowsperpage). Hvis alt, du har, kun er tabelstrukturen og ingen eksisterende eksempeldata at arbejde med, kan du bruge denne artikel til at estimere antallet af sider, du ville have på bladniveauet i det understøttende indeks. Hvis du har gode repræsentative eksempeldata, selvom de ikke er i samme skala som i produktionsmiljøet, kan du beregne det gennemsnitlige antal rækker, der passer på en side, ved at forespørge katalog og dynamiske administrationsobjekter, som f.eks.:
SELECT I.name, row_count, in_row_data_page_count, CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage FROM sys.indexes AS I INNER JOIN sys.dm_db_partition_stats AS P ON I.object_id =P.object_id OG I.index_id =P.index_id WHERE I.object_id =OBJECT_ID('dbo.Orders') OG I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Denne forespørgsel genererer følgende output i vores eksempeldatabase:
name row_count in_row_data_page_count avgrowsperpage ------------------ ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Nu hvor du har antallet af rækker, der passer på en bladside i indekset, kan du estimere det samlede antal bladsider i indekset baseret på antallet af rækker, du forventer, at din produktionstabel har. Dette vil også være det forventede antal logiske læsninger, der skal anvendes af Index Scan-operatøren. I praksis er der mere til antallet af læsninger, der kan finde sted, end blot antallet af sider på bladniveauet i indekset, såsom ekstra læsninger produceret af læse-forud-mekanismen, men jeg vil ignorere dem for at holde vores diskussion enkel .
For eksempel er det estimerede antal logiske læsninger for forespørgsel 1 i forhold til det forventede antal rækker CEILING(1e0 * @numorws / 404). Med 1.000.000 rækker er det forventede antal logiske læsninger 2476. Forskellen mellem 2476 og det rapporterede sideantal i rækker på 2473 kan tilskrives den afrunding, jeg foretog, da jeg beregnede det gennemsnitlige antal rækker pr. side.
Hvad angår planomkostningerne, forklarede jeg, hvordan man omvendt konstruerer Stream Aggregate-operatørens omkostninger i del 1 i serien. På lignende måde kan du omvendt manipulere omkostningerne ved Index Scan-operatøren. Planomkostningerne er så summen af omkostningerne for Index Scan og Stream Aggregate-operatørerne.
For at beregne omkostningerne for indeksscanningsoperatøren vil du starte med omvendt udvikling af nogle af de vigtige omkostningsmodelkonstanter:
@randomio =0,003125 -- Random I/O cost@seqio =0,000740740740741 -- Sekventiel I/O cost@cpubase =0,000157 -- CPU base cost@cpurow =0,0000011 -- CPU-pris pr. række
Med ovenstående omkostningsmodelkonstanter fundet ud, kan du fortsætte med at ændre formlerne for I/O-omkostninger, CPU-omkostninger og samlede operatøromkostninger for indeksscanningsoperatøren:
I/O-pris:@randomio + (@numpages - 1e0) * @seqio =0,003125 + (@numpages - 1e0) * 0,000740740740741CPU-pris:@cpubase + @numrows * @cpurow =0,0001s0.001s0.001s. pris:0,002541259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000011
For eksempel er indeksscanningsoperatorprisen for forespørgsel 1 med 2473 sider og 1.000.000 rækker:
0,002541259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000011 =2,93439
Følgende er den omvendte manipulerede formel for Stream Aggregate-operatøromkostningerne:
0,000008 + @numrows * 0,0000006 + @numgroups * 0,0000005
Som et eksempel, for forespørgsel 1, har vi 1.000.000 rækker og 5 grupper, derfor er den anslåede pris 0,6000105.
Ved at kombinere omkostningerne for de to operatører er her formlen for hele planomkostningerne:
0,002549259259259 + @numpages * 0,000740740740741 + @numrows * 0,0000017 + @numgroups * 0,0000005
For forespørgsel 1 med 2473 sider, 1.000.000 rækker og 5 grupper får du:
0,002549259259259 + 2473 * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,0000005 =3,5344
Dette matcher, hvad figur 1 viser som den anslåede pris for forespørgsel 1.
Hvis du stolede på et anslået antal rækker pr. side, ville din formel være:
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numrows * 0,0000005
Som et eksempel, for forespørgsel 1, med 1.000.000 rækker, 404 rækker pr. side og 5 grupper, er den anslåede pris:
0,002549259259259 + CEILING(1e0 * 1000000 / 404) * 0,000740740740741 + 1000000 * 0,0000017 + 5 * 0,000000 / 405 =3
Som en øvelse kan du anvende tallene for forespørgsel 2 (1.000.000 rækker, 385 rækker pr. side, 500 grupper) og forespørgsel 3 (1.000.000 rækker, 289 rækker pr. side, 20.000 grupper) i vores formel, og se, at resultaterne matcher hvad Figur 1 viser.
Justering af forespørgsler med forespørgselsomskrivninger
Standard forudbestilte Stream Aggregate-strategi til beregning af et MIN/MAX-aggregat pr. gruppe er afhængig af en bestilt scanning af et understøttende dækkende indeks (eller en anden foreløbig aktivitet, der udsender de bestilte rækker). En alternativ strategi, med et understøttende dækkende indeks til stede, ville være at udføre en indekssøgning pr. gruppe. Her er en beskrivelse af en pseudoplan baseret på en sådan strategi for en forespørgsel, der grupperer efter grpcol og anvender en MAX(aggcol):
set @curgrpcol =grpcol fra første række opnået ved en scanning af indekset, bestilt frem; mens slutningen af indekset ikke nåsbegin sæt @curagg =aggcol fra række opnået ved en søg til det sidste punkt, hvor grpcol =@curgrpcol, bestilt baglæns; udsende række (@curgrpcol, @curagg); sæt @curgrpcol =grpcol fra række til højre for sidste række for nuværende gruppe;slut;
Hvis du tænker over det, er den standardscanningsbaserede strategi optimal, når grupperingssættet har lav tæthed (stort antal grupper, med et lille antal rækker pr. gruppe i gennemsnit). Den søgningsbaserede strategi er optimal, når grupperingssættet har høj tæthed (lille antal grupper, med et stort antal rækker pr. gruppe i gennemsnit). Figur 2 illustrerer begge strategier, der viser, hvornår hver er optimal.
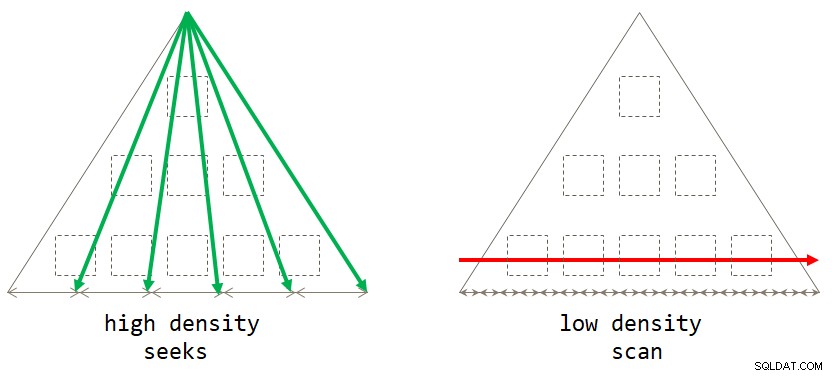 Figur 2:Optimal strategi baseret på grupperingssættæthed
Figur 2:Optimal strategi baseret på grupperingssættæthed
Så længe du skriver løsningen i form af en grupperet forespørgsel, vil SQL Server i øjeblikket kun overveje scanningsstrategien. Dette vil fungere godt for dig, når grupperingssættet har lav tæthed. Når du har høj tæthed, for at få søger-strategien, skal du anvende en forespørgselsomskrivning. En måde at opnå dette på er at forespørge i tabellen, der indeholder grupperne, og at bruge en skalær aggregeret underforespørgsel mod hovedtabellen for at opnå aggregatet. For for eksempel at beregne den maksimale ordredato for hver afsender, skal du bruge følgende kode:
SELECT shipperid, ( SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid BESTILLING AF O.orderdate DESC ) AS maxod FROM dbo.Shippers AS S;
Indekseringsretningslinjerne for hovedtabellen er de samme som dem, der understøtter standardstrategien. Vi har allerede disse indekser på plads for de tre førnævnte opgaver. Du vil sandsynligvis også have et understøttende indeks på grupperingssættets kolonner i tabellen, der indeholder grupperne, for at minimere I/O-omkostningerne i forhold til den tabel. Brug følgende kode til at oprette sådanne understøttende indekser til vores tre opgaver:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid);CREATE INDEX idx_eid ON dbo.Employees(empid);CREATE INDEX idx_cid ON dbo.Customers(custid);
Et lille problem er dog, at løsningen baseret på underforespørgslen ikke er en nøjagtig logisk ækvivalent af løsningen baseret på den grupperede forespørgsel. Hvis du har en gruppe uden tilstedeværelse i hovedtabellen, vil førstnævnte returnere gruppen med en NULL som aggregatet, hvorimod sidstnævnte slet ikke returnerer gruppen. En simpel måde at opnå en ægte logisk ækvivalent til den grupperede forespørgsel på er at kalde underforespørgslen ved at bruge CROSS APPLY-operatoren i FROM-udtrykket i stedet for at bruge en skalær underforespørgsel i SELECT-udtrykket. Husk, at CROSS APPLY ikke returnerer en venstre række, hvis den anvendte forespørgsel returnerer et tomt sæt. Her er de tre løsningsforespørgsler, der implementerer denne strategi for vores tre opgaver, sammen med deres præstationsstatistikker:
-- Forespørgsel 4 -- Estimerede undertræsomkostninger:0,0072299 -- logiske læsninger:2 + 15, CPU-tid:0 ms, forløbet tid:43 ms VÆLG S.shipperid, A.orderdate AS maxod FRA dbo.Shippers AS S KRYDSANVEND (VÆLG TOP (1) O.orderdato FRA dbo.Ordrer AS O HVOR O.shipperid =S.shipperid BESTILLING AF O.orderdato DESC ) SOM A; -- Forespørgsel 5 -- Estimerede undertræsomkostninger:0,089694 -- logiske læsninger:2 + 1620, CPU-tid:0 ms, forløbet tid:148 ms VÆLG E.empid, A.orderdate AS maxod FRA dbo.Employees AS E CROSS APPLY ( VÆLG TOP (1) O.orderdate FRA dbo.Orders AS O HVOR O.empid =E.empid BESTILLING AF O.orderdate DESC ) AS A; -- Forespørgsel 6 -- Estimerede Subtree Cost:3,5227 -- logiske læsninger:45 + 63777, CPU-tid:171 ms, forløbet tid:306 ms VÆLG C.custid, A.orderdate AS maxod FRA dbo.Customers AS CROSS APPLY ( VÆLG TOP (1) O.orderdato FRA dbo.Ordre AS O HVOR O.custid =C.custid BESTILLING AF O.orderdate DESC ) SOM A;
Planerne for disse forespørgsler er vist i figur 3.
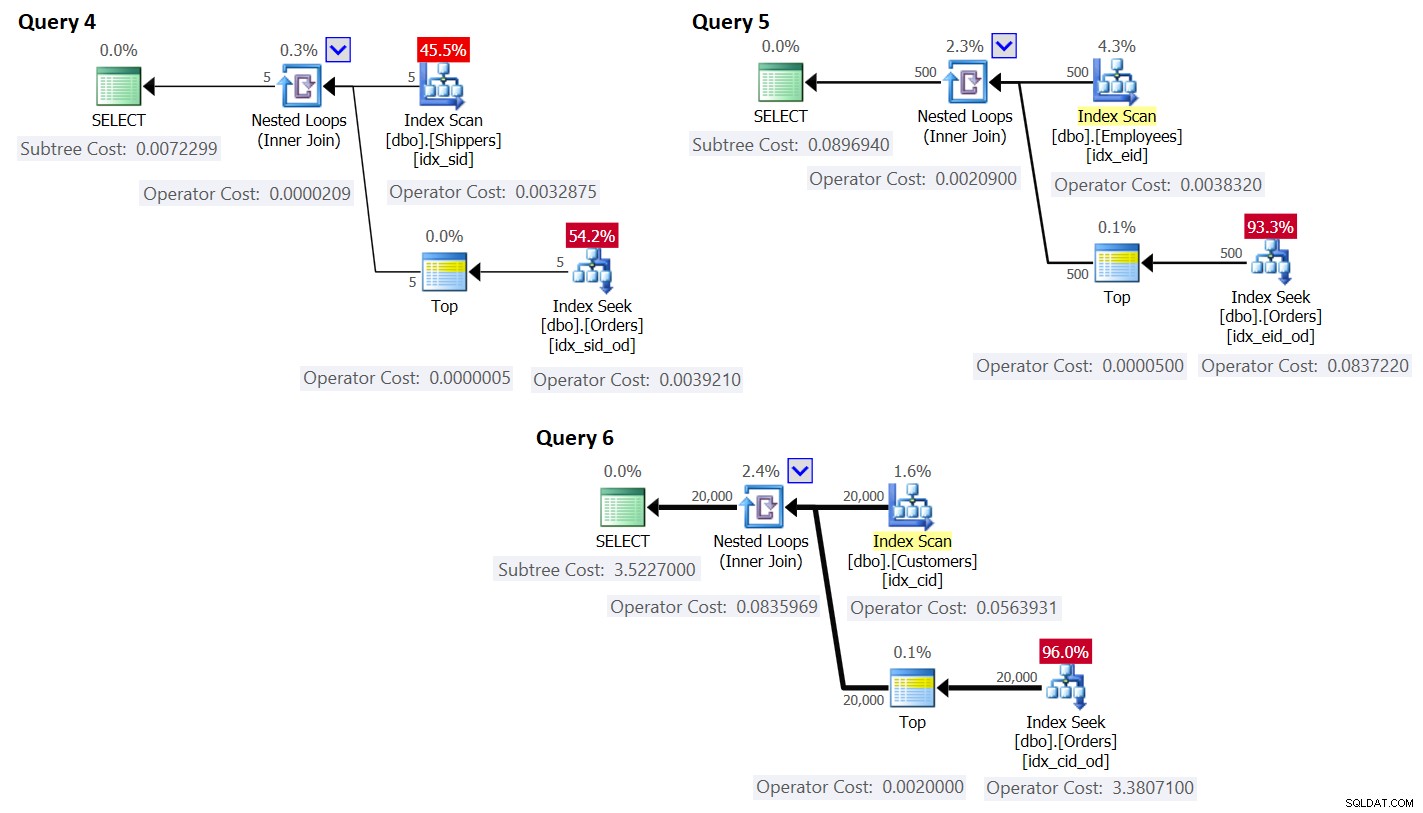 Figur 3:Planer for forespørgsler med omskrivning
Figur 3:Planer for forespørgsler med omskrivning
Som du kan se, opnås grupperne ved at scanne indekset på gruppetabellen, og aggregatet opnås ved at anvende en søgning i indekset på hovedtabellen. Jo højere tætheden af grupperingssættet er, jo mere optimal er denne plan sammenlignet med standardstrategien for den grupperede forespørgsel.
Ligesom vi gjorde tidligere for standardscanningsstrategien, lad os anslå antallet af logiske læsninger og planlægge omkostningerne for søgningsstrategien. Det estimerede antal logiske læsninger er antallet af læsninger for den enkelte udførelse af Index Scan-operatoren, der henter grupperne, plus læsningerne for alle udførelser af Index Seek-operatoren.
Det estimerede antal logiske læsninger for indeksscanningsoperatøren er ubetydelig sammenlignet med søgningerne; stadig, det er CEILING(1e0 * @antalgrupper / @rækkesperside). Tag forespørgsel 4 som et eksempel; sig, at indekset idx_sid passer til ca. 600 rækker pr. bladside (det faktiske antal afhænger af de faktiske shipperid-værdier, da datatypen er VARCHAR(5)). Med 5 grupper passer alle rækker på en enkelt bladside. Hvis du havde 5.000 grupper, ville de passe ind på 9 sider.
Det estimerede antal logiske læsninger for alle udførelser af Index Seek-operatoren er @numgroups * @indexdepth. Indeksets dybde kan beregnes som:
LOFT(LOG(LOFT(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Brug forespørgsel 4 som et eksempel, og sig, at vi kan passe til omkring 404 rækker pr. bladside i indekset idx_sid_od, og omkring 352 rækker pr. non-leaf-side. Igen vil de faktiske tal afhænge af faktiske værdier gemt i shipperid-kolonnen, da dens datatype er VARCHAR(5)). For estimater skal du huske, at du kan bruge de her beskrevne beregninger. Med gode repræsentative eksempeldata tilgængelige kan du bruge følgende forespørgsel til at finde ud af antallet af rækker, der kan passe på blad- og ikke-bladsiderne i det givne indeks:
SELECT CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype, FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage FROM (SELECT * FROM sys.indexes WHERE object_id =OBJECT_ID =OBJECT_ID =2) ('dbo.Orders') AND name ='idx_sid_od') AS I CROSS APPLY sys.dm_db_index_physical_stats (DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P WHERE P.index_level <=1; Jeg fik følgende output:
pagetype rowsperpage -------- ---------------------------- leaf 404 nonleaf 352
Med disse tal er dybden af indekset i forhold til antallet af rækker i tabellen:
LOFT(LOG(LOFT(1e0 * @tal / 404), 352)) + 1
Med 1.000.000 rækker i tabellen resulterer dette i en indeksdybde på 3. Ved omkring 50 millioner rækker øges indeksdybden til 4 niveauer, og ved omkring 17,62 milliarder rækker øges den til 5 niveauer.
I hvert fald, med hensyn til antallet af grupper og antallet af rækker, forudsat ovenstående antal rækker pr. side, beregner følgende formel det estimerede antal logiske læsninger for forespørgsel 4:
LOFT(1e0 * @antalgrupper / 600) + @antalgrupper * (LOFT(LOG(LOFT(1e0 * @talgrupper / 404), 352)) + 1)
For eksempel, med 5 grupper og 1.000.000 rækker, får du kun 16 læsninger i alt! Husk, at den standardscanningsbaserede strategi for den grupperede forespørgsel involverer lige så mange logiske læsninger som CEILING(1e0 * @numrows / @rowsperpage). Ved at bruge forespørgsel 1 som eksempel og antage omkring 404 rækker pr. bladside i indekset idx_sid_od, med det samme antal rækker på 1.000.000, får du omkring 2.476 læsninger. Forøg antallet af rækker i tabellen med en faktor på 1.000 til 1.000.000.000, men hold antallet af grupper fast. Antallet af læsninger, der kræves med søgningsstrategien, ændres meget lidt til 21, hvorimod antallet af læsninger, der kræves med scanningsstrategien, stiger lineært til 2.475.248.
Det smukke ved seeks-strategien er, at så længe antallet af grupper er lille og fast, har den næsten konstant skalering i forhold til antallet af rækker i tabellen. Det skyldes, at antallet af søgninger bestemmes af antallet af grupper, og dybden af indekset relaterer sig til antallet af rækker i tabellen på en logaritmisk måde, hvor logbasen er antallet af rækker, der passer på en side uden blade. Omvendt har den scanningsbaserede strategi lineær skalering med hensyn til antallet af involverede rækker.
Figur 4 viser antallet af læsninger estimeret for de to strategier, anvendt af forespørgsel 1 og forespørgsel 4, givet et fast antal grupper på 5 og forskellige antal rækker i hovedtabellen.
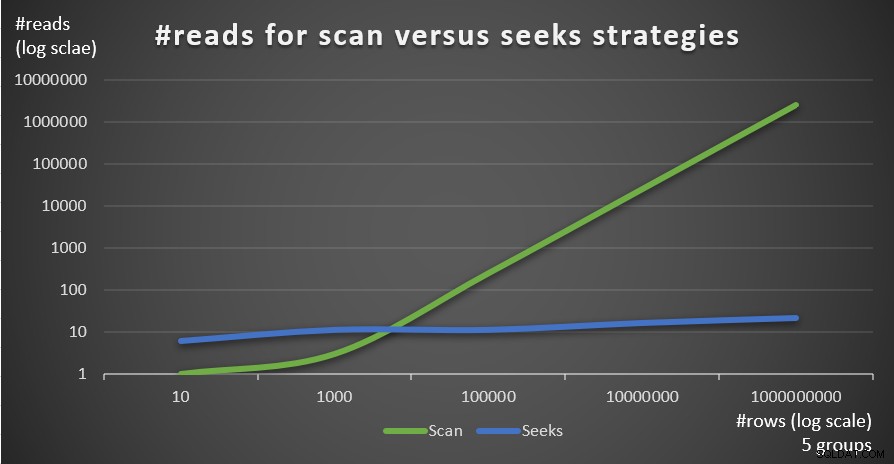 Figur 4:#reads for scanning versus søger strategier (5 grupper)
Figur 4:#reads for scanning versus søger strategier (5 grupper)
Figur 5 viser antallet af læsninger estimeret for de to strategier givet et fast antal rækker på 1.000.000 i hovedtabellen og forskellige antal grupper.
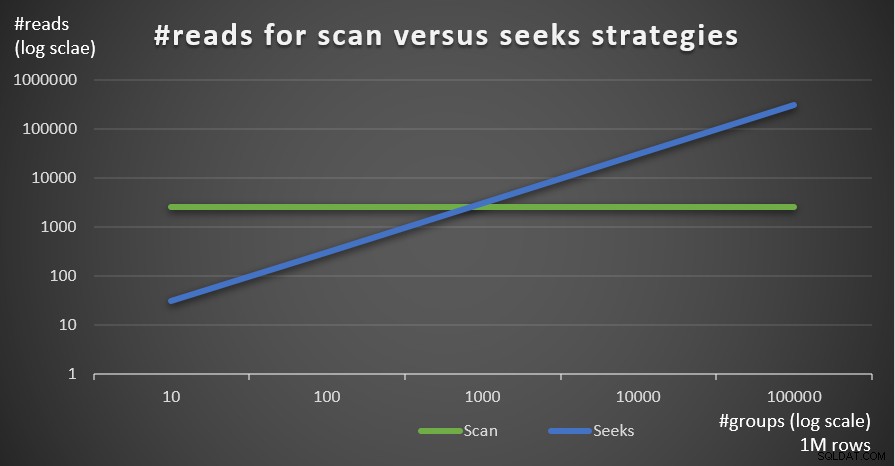 Figur 5:#reads for scanning versus søger strategier (1M rækker)
Figur 5:#reads for scanning versus søger strategier (1M rækker)
Du kan meget tydeligt se, at jo højere tætheden af grupperingssættet (mindre antal grupper) og jo større hovedtabellen er, jo mere foretrækkes søgestrategien i forhold til antallet af læsninger. Hvis du undrer dig over I/O-mønsteret, der bruges af hver strategi; sikkert, indekssøgningsoperationer udfører tilfældige I/O, hvorimod en indeksscanningsoperation udfører sekventiel I/O. Alligevel er det ret tydeligt, hvilken strategi der er mest optimal i de mere ekstreme tilfælde.
Hvad angår omkostningerne til forespørgselsplanen, lad os igen bruge planen for forespørgsel 4 i figur 3 som eksempel, opdele den til de individuelle operatører i planen.
Den omvendte formel for omkostningerne ved indeksscanningsoperatøren er:
0,002541259259259 + @numpages * 0,000740740740741 + @numgroups * 0,0000011
I vores tilfælde, med 5 grupper, som alle passer på én side, er prisen:
0,002541259259259 + 1 * 0,000740740740741 + 5 * 0,0000011 =0,0032875
Omkostningerne vist i planen er de samme.
Som før kan du estimere antallet af sider i bladniveauet af indekset baseret på det estimerede antal rækker pr. side ved hjælp af formlen CEILING(1e0 * @numrows / @rowsperpage), som i vores tilfælde er CEILING(1e0 * @ numgroups / @groupsperpage). Lad os sige, at indekset idx_sid passer til omkring 600 rækker pr. bladside, med 5 grupper, du skal bruge for at læse én side. I hvert fald bliver omkostningsformlen for indeksscanningsoperatøren:
0,002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011
Den omvendte omkostningsformel for Nested Loops-operatøren er:
@executions * 0,00000418
I vores tilfælde oversættes dette til:
@numgroups * 0,00000418
For forespørgsel 4, med 5 grupper, får du:
5 * 0,00000418 =0,0000209
Omkostningerne vist i planen er de samme.
Den omvendte omkostningsformel for Top-operatøren er:
@executions * @toprows * 0,00000001
I vores tilfælde oversættes dette til:
@numgroups * 1 * 0,00000001
Med 5 grupper får du:
5 * 0,0000001 =0,0000005
Omkostningerne vist i planen er de samme.
Hvad angår Index Seek-operatøren, fik jeg her stor hjælp fra Paul White; tak min ven! Beregningen er forskellig for den første udførelse og for genbindingerne (ikke-første udførelser, der ikke genbruger den tidligere udførelses resultat). Ligesom vi gjorde med Index Scan-operatøren, lad os starte med at identificere omkostningsmodellens konstanter:
@randomio =0,003125 -- Tilfældige I/O-omkostninger @seqio =0,000740740740741 -- Sekventielle I/O-omkostninger @cpubase =0,000157 -- CPU-basisomkostninger @cpurow =0,0000011 -- CPU-omkostninger pr. række
For én udførelse, uden et rækkemål anvendt, er I/O- og CPU-omkostningerne:
I/O-pris:@randomio + (@numpages - 1e0) * @seqio =0,002384259259259 + @numpages * 0,000740740740741CPU-pris:@cpubase + @numrows * @cpurow =0.07 +1 s 0.0sDa vi bruger TOP (1), har vi kun én side og en række involveret, så omkostningerne er:
I/O-pris:0,002384259259259 + 1 * 0,000740740740741 =0,003125CPU-pris:0,000157 + 1 * 0,0000011 =0,0001581Så omkostningerne ved den første udførelse af Index Seek-operatøren i vores tilfælde er:
@firstexecution =0,003125 + 0,0001581 =0,0032831Hvad angår omkostningerne ved genbindingerne, er den som sædvanlig lavet af CPU- og I/O-omkostninger. Lad os kalde dem henholdsvis @rebindcpu og @rebindio. Med forespørgsel 4, der har 5 grupper, har vi 4 rebinds (kald det @rebinds). @rebindcpu omkostningerne er den nemme del. Formlen er:
@rebindcpu =@rebinds * (@cpubase + @cpurow)I vores tilfælde oversættes dette til:
@rebindcpu =4 * (0,000157 + 0,0000011) =0,0006324@rebindio-delen er lidt mere kompleks. Her beregner omkostningsformlen statistisk det forventede antal adskilte sider, som genbindingerne forventes at læse ved hjælp af sampling med udskiftning. Vi kalder dette element @pswr (for særskilte sider samplet med erstatning). Ideen er, at vi har @indexdatapages antal sider i indekset (i vores tilfælde 2.473), og @rebinds antal genbindinger (i vores tilfælde 4). Hvis vi antager, at vi har samme sandsynlighed for at læse en given side med hver genindbinding, hvor mange forskellige sider forventes vi at læse i alt? Dette svarer til at have en pose med 2.473 bolde, og fire gange blindt trække en bold fra posen og derefter returnere den til posen. Statistisk set, hvor mange forskellige bolde forventes du at trække i alt? Formlen for dette, ved hjælp af vores operander, er:
@pswr =@indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))Med vores numre får du:
@pswr =2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) =3,99757445099277Dernæst beregner du antallet af rækker og sider, du i gennemsnit har pr. gruppe:
@grouprows =@cardinality * @density@grouppages =CEILING(@indexdatapages * @density)I vores forespørgsel 4 er kardinaliteten 1.000.000, og tætheden er 1/5 =0,2. Så du får:
@grouprows =1000000 * 0,2 =200000@numpages =CEILING(2473 * 0,2) =495Derefter beregner du I/O-omkostningerne uden filtrering (kald det @io) som:
@io =@randomio + (@seqio * (@grouppages - 1e0))I vores tilfælde får du:
@io =0,003125 + (0,000740740740741 * (495 - 1e0)) =0,369050925926054Og endelig, da søgningen kun udtrækker én række i hver genbinding, beregner du @rebindio ved hjælp af følgende formel:
@rebindio =(1e0 / @grouprows) * ((@pswr - 1e0) * @io)I vores tilfælde får du:
@rebindio =(1e0 / 200000) * ((3,99757445099277 - 1e0) * 0,369050925926054) =0,000005531288Endelig er operatørens omkostninger:
Operatoromkostninger:@firstexecution + @rebindcpu + @rebindio =0,0032831 + 0,0006324 + 0,000005531288 =0,003921031288Dette er det samme som Index Seek-operatøromkostningerne vist i planen for forespørgsel 4.
Du kan nu aggregere omkostningerne for alle operatørerne for at få den komplette pris for forespørgselsplanen. Du får:
Forespørgselsplan Omkostninger:0,002541259259259 + loft (1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @NumGroups * 0,0000011 + @NumGroups * 0,00000418 + @NumGroups * 0,00000001 + 0,0032831 + ( @@numgroups * --10) / (@numrows / @numrows)) * (LOFT(1e0 * @numrows / @rowsperpage) * (1e0 - POWER((LOFT(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @ rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,000740740740741 * (LOFT((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Efter forenkling får du følgende komplette omkostningsformel for vores Seeks-strategi:
0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @numgroups * 0,00016229 + (groups@numgroups) /cerowing @numerrows) /numerrow @antals)/cerows @0001s) ) * (1e0 - POWER((LOFT(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0) * (0,003125 + (0,0007407407 (4007407) * CEILING((@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0)))Som et eksempel, ved brug af T-SQL, er her beregningen af forespørgselsplanens omkostninger med vores Seeks-strategi for forespørgsel 4:
DEKLARE @numrows AS FLOAT =1000000, @numgroups AS FLOAT =5, @rowsperpage AS FLOAT =404, @groupsperpage AS FLOAT =600; SELECT 0,005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0,000740740740741 + @numgroups * 0,0000011 + @antalgroups * 0,0001629s *0,00016229 +(rækker @tals) /nummers @tals/pages)@numerrows) @numerrows) /nummers (1e0 - POWER((LOFT(1e0 * @numrows / @rowsperpage) - 1e0) / CEILING(1e0 * @numrows / @rowsperpage), @antalgroups - 1e0)) - 1e0) * (0,003125 + (0,0007407407407ING(407407ING(407407407407407) (@numrows / @rowsperpage) * (1e0 / @numgroups)) - 1e0))) AS seeksplancost;Denne beregning beregner omkostningerne 0,0072295 for forespørgsel 4. De anslåede omkostninger vist i figur 3 er 0,0072299. Det er ret tæt på! Som en øvelse skal du beregne omkostningerne for forespørgsel 5 og forespørgsel 6 ved hjælp af denne formel og kontrollere, at du får tal tæt på dem, der er vist i figur 3.
Husk, at omkostningsformlen for den standardscanningsbaserede strategi er (kald den Scan strategi):
0,002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0,000740740740741 + @numrows * 0,0000017 + @numrows * 0,0000005Ved at bruge forespørgsel 1 som eksempel og antage 1.000.000 rækker i tabellen, 404 rækker pr. side og 5 grupper, er den estimerede pris for forespørgselsplanen for scanningsstrategien 3,5366.
Figur 6 viser de estimerede omkostninger til forespørgselsplan for de to strategier, anvendt af forespørgsel 1 (scanning) og forespørgsel 4 (søger), givet et fast antal grupper på 5 og forskellige antal rækker i hovedtabellen.
Figur 6:pris for scan versus søger strategier (5 grupper)
Figur 7 viser de estimerede omkostninger til forespørgselsplan for de to strategier, givet et fast antal rækker i hovedtabellen på 1.000.000 og forskellige antal grupper.
Figur 7:pris for scan versus søgestrategier (1M rækker)
Som det fremgår af disse fund, jo højere grupperingssættæthed og jo flere rækker i hovedtabellen, jo mere optimal er søgningsstrategien sammenlignet med scanningsstrategien. Så sørg for at prøve den APPLY-baserede løsning i scenarier med høj tæthed. I mellemtiden kan vi håbe, at Microsoft vil tilføje denne strategi som en indbygget mulighed for grupperede forespørgsler.
Konklusion
Denne artikel afslutter en serie i fem dele om tærskler for forespørgselsoptimering for forespørgsler, der grupperer og samler data. Et mål med serien var at diskutere detaljerne ved de forskellige algoritmer, som optimizeren kan bruge, de betingelser, hvorunder hver algoritme foretrækkes, og hvornår du skal gribe ind med dine egne forespørgselsomskrivninger. Et andet mål var at forklare processen med at opdage de forskellige muligheder og sammenligne dem. Naturligvis kan den samme analyseproces anvendes til filtrering, sammenføjning, vinduesvisning og mange andre aspekter af forespørgselsoptimering. Forhåbentlig føler du dig nu mere rustet til at håndtere forespørgselsjustering end før.