Undrer du dig over, hvad Postgresql-skemaer er, og hvorfor de er vigtige, og hvordan du kan bruge skemaer til at gøre dine databaseimplementeringer mere robuste og vedligeholdelige? Denne artikel vil introducere det grundlæggende i skemaer i Postgresql og vise dig, hvordan du opretter dem med nogle grundlæggende eksempler. Fremtidige artikler vil dykke ned i eksempler på, hvordan man sikrer og bruger skemaer til rigtige applikationer.
For det første, for at rydde op i potentiel terminologiforvirring, lad os forstå, at i Postgresql-verdenen er udtrykket "skema" måske noget desværre overbelastet. I den bredere kontekst af relationelle databasestyringssystemer (RDBMS) kan udtrykket "skema" forstås som at henvise til det overordnede logiske eller fysiske design af databasen, dvs. definitionen af alle tabeller, kolonner, visninger og andre objekter der udgør databasedefinitionen. I den bredere kontekst kan et skema være udtrykt i et entity-relationship (ER) diagram eller et script med data definition language (DDL) sætninger, der bruges til at instansiere applikationsdatabasen.
I Postgresql-verdenen kan udtrykket "skema" måske bedre forstås som et "navneområde". Faktisk er skemaer i Postgresql-systemtabellerne optaget i tabelkolonner kaldet "navneplads", som, IMHO, er mere nøjagtig terminologi. Som en praktisk sag, når jeg ser "skema" i konteksten af Postgresql, omfortolker jeg det lydløst som at sige "navneplads".
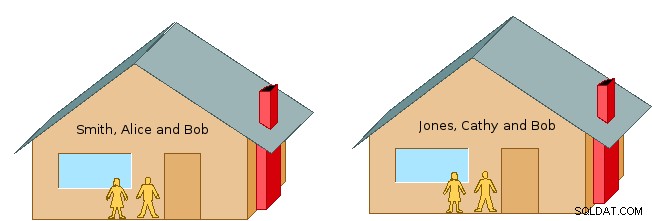
Men du kan spørge:"Hvad er et navneområde?" Generelt er et navneområde et ret fleksibelt middel til at organisere og identificere information ved navn. Forestil dig for eksempel to nabohusstande, familien Smith, Alice og Bob og Jones, Bob og Cathy (jf. figur 1). Hvis vi kun brugte fornavne, kunne det blive forvirrende med hensyn til, hvilken person vi mente, når vi taler om Bob. Men ved at tilføje efternavnet Smith eller Jones, identificerer vi entydigt, hvilken person vi mener.
Navnerum er ofte organiseret i et indlejret hierarki. Dette muliggør effektiv klassificering af enorme mængder information i en meget finmasket struktur, som f.eks. internetdomænenavnesystemet. På øverste niveau definerer ".com", ".net", ".org", ".edu" osv. brede navnerum, inden for hvilke der er registrerede navne for specifikke enheder, så for eksempel "severalnines.com" og "postgresql.org" er unikt definerede. Men under hver af dem er der en række almindelige underdomæner som f.eks. "www", "mail" og "ftp", som alene er duplikative, men inden for de respektive navneområder er unikke.
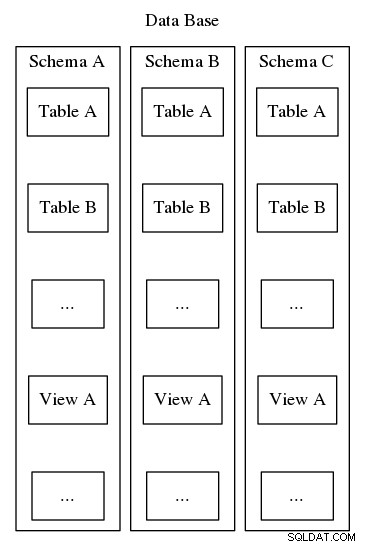
Postgresql-skemaer tjener det samme formål med at organisere og identificere, men i modsætning til det andet eksempel ovenfor, kan Postgresql-skemaer ikke indlejres i et hierarki. Selvom en database kan indeholde mange skemaer, er der kun et niveau, og derfor skal skemanavne i en database være unikke. Desuden skal hver database indeholde mindst ét skema. Når en ny database instansieres, oprettes et standardskema med navnet "offentlig". Indholdet af et skema omfatter alle de andre databaseobjekter såsom tabeller, visninger, lagrede procedurer, triggere osv. For at visualisere, se figur 2, som viser en matryoshka dukke-lignende indlejring, der viser, hvor skemaer passer ind i strukturen af en Postgresql-database.
Udover blot at organisere databaseobjekter i logiske grupper for at gøre dem mere overskuelige, tjener skemaer det praktiske formål at undgå navnekollision. Et operationelt paradigme involverer at definere et skema for hver databasebruger for at give en vis grad af isolation, et rum hvor brugere kan definere deres egne tabeller og visninger uden at forstyrre hinanden. En anden tilgang er at installere tredjepartsværktøjer eller databaseudvidelser i individuelle skemaer for at holde alle de relaterede komponenter logisk sammen. En senere artikel i denne serie vil detaljere en ny tilgang til robust applikationsdesign, der anvender skemaer som et indirekte middel til at begrænse eksponeringen af databasens fysiske design og i stedet præsentere en brugergrænseflade, der løser syntetiske nøgler og letter langsigtet vedligeholdelse og konfigurationsstyring efterhånden som systemkravene udvikler sig.
Lad os lave noget kode!
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperDen enkleste kommando til at oprette et skema i en database er
CREATE SCHEMA hollywood;Denne kommando kræver oprettelsesrettigheder i databasen, og det nyoprettede skema "hollywood" vil være ejet af brugeren, der påkalder kommandoen. En mere kompleks påkaldelse kan omfatte valgfrie elementer, der angiver en anden ejer, og kan endda inkludere DDL-sætninger, der instansierer databaseobjekter i skemaet, alt i én kommando!
Det generelle format er
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]hvor "brugernavn" er, hvem der vil eje skemaet, og "schema_element" kan være en af visse DDL-kommandoer (se Postgresql-dokumentationen for detaljer). Superbruger-privilegier er nødvendige for at bruge AUTHORIZATION-indstillingen.
Så for at oprette et skema med navnet "hollywood", som indeholder en tabel med navnet "film" og se navngivet "vindere" i én kommando, kunne du gøre
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Yderligere databaseobjekter kan efterfølgende oprettes direkte, f.eks. vil en ekstra tabel blive tilføjet til skemaet med
CREATE TABLE hollywood.actors (name text, dob date, gender text);Bemærk i ovenstående eksempel præfikset af tabelnavnet med skemanavnet. Dette er påkrævet, fordi der som standard, dvs. uden eksplicit skemaspecifikation, oprettes nye databaseobjekter inden for det aktuelle skema, som vi vil dække herefter.
Husk, hvordan vi i eksemplet med fornavnepladsen ovenfor havde to personer ved navn Bob, og vi beskrev, hvordan man afkonflikter eller skelner mellem dem ved at inkludere efternavnet. Men inden for hver af Smith- og Jones-husstandene for sig, forstår hver familie "Bob" for at referere til den, der hører til den særlige husstand. Så for eksempel i forbindelse med hver enkelt husstand, behøver Alice ikke at tiltale sin mand som Bob Jones, og Cathy behøver ikke at henvise til sin mand som Bob Smith:de kan hver især bare sige "Bob".
Det aktuelle Postgresql-skema ligner husstanden i ovenstående eksempel. Objekter i det aktuelle skema kan henvises til ukvalificeret, men henvisning til lignende navngivne objekter i andre skemaer kræver, at navnet kvalificeres ved at sætte skemanavnet foran som ovenfor.
Det aktuelle skema er afledt af konfigurationsparameteren "search_path". Denne parameter gemmer en kommasepareret liste over skemanavne og kan undersøges med kommandoen
SHOW search_path;eller indstil til en ny værdi med
SET search_path TO schema [, schema, ...];Det første skemanavn på listen er det "aktuelle skema" og er det sted, hvor nye objekter oprettes, hvis de er angivet uden skemanavn-kvalifikation.
Den kommaseparerede liste over skemanavne tjener også til at bestemme den søgerækkefølge, hvorved systemet lokaliserer eksisterende ukvalificerede navngivne objekter. For eksempel, tilbage til Smith og Jones-kvarteret, vil en pakkelevering, der kun er adresseret til "Bob", kræve besøg hos hver husstand, indtil den første beboer ved navn "Bob" er fundet. Bemærk, dette er muligvis ikke den tilsigtede modtager. Den samme logik gælder for Postgresql. Systemet søger efter tabeller, visninger og andre objekter i skemaer i rækkefølgen af søgestien, og derefter bruges det først fundne navnematch-objekt. Skema-kvalificerede navngivne objekter bruges direkte uden reference til søgestien.
I standardkonfigurationen afsløres denne værdi
, hvis du forespørger efter konfigurationsvariablen search_pathSHOW search_path;
Search_path
--------------
"$user", publicSystemet fortolker den første værdi vist ovenfor som det nuværende loggede brugernavn og imødekommer det tidligere nævnte use case, hvor hver bruger tildeles et brugernavngivet skema til et arbejdsområde adskilt fra andre brugere. Hvis der ikke er oprettet et sådant brugernavnet skema, ignoreres denne post, og det "offentlige" skema bliver det aktuelle skema, hvor nye objekter oprettes.
Tilbage til vores tidligere eksempel på at oprette "hollywood.actors"-tabellen, hvis vi ikke havde kvalificeret tabelnavnet med skemanavnet, ville tabellen være blevet oprettet i det offentlige skema. Hvis vi forventede at skabe alle objekter inden for et specifikt skema, kan det være praktisk at indstille søgesti-variablen som f.eks.
SET search_path TO hollywood,public;gør det lettere at skrive ukvalificerede navne for at oprette eller få adgang til databaseobjekter.
Der er også en systeminformationsfunktion, som returnerer det aktuelle skema med en forespørgsel
select current_schema();I tilfælde af stavning med fedtfinger kan ejeren af et skema ændre navnet, forudsat at brugeren også har oprettelsesrettigheder til databasen med
ALTER SCHEMA old_name RENAME TO new_name;Og til sidst, for at slette et skema fra en database, er der en drop-kommando
DROP SCHEMA schema_name;DROP-kommandoen vil mislykkes, hvis skemaet indeholder objekter, så de skal slettes først, eller du kan eventuelt rekursivt slette et skema alt dets indhold med CASCADE-indstillingen
DROP SCHEMA schema_name CASCADE;Disse grundlæggende ting vil få dig i gang med at forstå skemaer!