Stort set alle computersøjlerelaterede præstationsproblemer, jeg er stødt på gennem årene, har haft en (eller flere) af følgende grundlæggende årsager:
- Implementeringsbegrænsninger
- Mangel på omkostningsmodelunderstøttelse i forespørgselsoptimeringsværktøjet
- Udvidelse af beregnet kolonnedefinition før optimering starter
Et eksempel på en implementeringsbegrænsning er ikke i stand til at oprette et filtreret indeks på en beregnet kolonne (selv når den fortsætter). Der er ikke meget vi kan gøre ved denne problemkategori; vi er nødt til at bruge løsninger, mens vi venter på, at produktforbedringer kommer frem.
Manglen på understøttelse af omkostningsmodel til optimeringsværktøj betyder, at SQL Server tildeler en lille fast omkostning til skalære beregninger, uanset kompleksitet eller implementering. Som en konsekvens heraf beslutter serveren ofte at genberegne en lagret beregnet kolonneværdi i stedet for at læse den vedvarende eller indekserede værdi direkte. Dette er især smertefuldt, når det beregnede udtryk er dyrt, for eksempel når det involverer at kalde en skalær brugerdefineret funktion.
Problemerne omkring definitionsudvidelse er lidt mere involverede og har vidtrækkende effekter.
Problemerne med beregnet kolonneudvidelse
SQL Server udvider normalt beregnede kolonner til deres underliggende definitioner under bindingsfasen af forespørgselsnormalisering. Dette er en meget tidlig fase i forespørgselskompileringsprocessen, længe før der træffes beslutninger om planudvælgelse (herunder triviel plan).
I teorien kan tidlig udvidelse muliggøre optimeringer, som ellers ville blive savnet. For eksempel kan optimeringsværktøjet være i stand til at anvende forenklinger givet andre oplysninger i forespørgslen og metadata (f.eks. begrænsninger). Dette er den samme slags ræsonnement, der fører til, at visningsdefinitioner udvides (medmindre en NOEXPAND tip er brugt).
Senere i kompileringsprocessen (men stadig før selv en triviel plan er blevet overvejet), søger optimeringsværktøjet at matche tilbage udtryk til vedvarende eller indekserede beregnede kolonner. Problemet er, at optimeringsaktiviteter i mellemtiden kan have ændret de udvidede udtryk, så det ikke længere er muligt at matche tilbage.
Når dette sker, ser den endelige udførelsesplan ud, som om optimeringsværktøjet har forpasset en "åbenbar" mulighed for at bruge en vedvarende eller indekseret beregnet kolonne. Der er få detaljer i udførelsesplaner, der kan hjælpe med at bestemme årsagen, hvilket gør dette til et potentielt frustrerende problem at fejlfinde og rette på.
Matchning af udtryk til beregnede kolonner
Det er værd at være særligt klart, at der er to separate processer her:
- Tidlig udvidelse af beregnede kolonner; og
- Senere forsøg på at matche udtryk til beregnede kolonner.
Bemærk især, at et hvilket som helst forespørgselsudtryk kan matches til en passende beregnet kolonne senere, ikke kun udtryk, der opstod ved at udvide beregnede kolonner.
Matchning af beregnet kolonneudtryk kan muliggøre planforbedringer, selv når teksten i den oprindelige forespørgsel ikke kan ændres. Oprettelse af en beregnet kolonne, der matcher et kendt forespørgselsudtryk, giver f.eks. optimeringsværktøjet mulighed for at bruge statistik og indekser knyttet til den beregnede kolonne. Denne funktion ligner konceptuelt indekseret visningsmatchning i Enterprise Edition. Beregnet kolonnematchning er funktionel i alle udgaver.
Fra et praktisk synspunkt har min egen erfaring været, at matchning af generelle forespørgselsudtryk til beregnede kolonner faktisk kan gavne ydeevne, effektivitet og stabilitet i eksekveringsplanen. På den anden side har jeg sjældent (hvis nogensinde) fundet ud af, at beregnet kolonneudvidelse er umagen værd. Det ser bare aldrig ud til at give nogen brugbare optimeringer.
Beregnet kolonnebrug
Beregnede kolonner, der er ingen af delene persisted eller indekseret har gyldige anvendelser. For eksempel kan de understøtte automatisk statistik, hvis kolonnen er deterministisk og præcis (ingen flydende komma-elementer). De kan også bruges til at spare lagerplads (på bekostning af lidt ekstra brug af runtime-processor). Som et sidste eksempel kan de give en pæn måde at sikre, at en simpel beregning altid udføres korrekt, i stedet for at blive skrevet eksplicit ud i forespørgsler hver gang.
Vedvarende beregnede kolonner blev føjet til produktet specifikt for at gøre det muligt at bygge indekser på deterministiske, men "upræcise" (flydende komma) kolonner. Efter min erfaring er denne tilsigtede brug relativt sjælden. Måske er det simpelthen fordi jeg ikke støder så meget på data med flydende komma.
Bortset fra flydende kommaindekser er vedvarende kolonner ret almindelige. Til en vis grad kan det skyldes, at uerfarne brugere antager, at en beregnet kolonne altid skal bevares, før den kan indekseres. Mere erfarne brugere kan bruge vedvarende kolonner, simpelthen fordi de har fundet ud af, at ydeevnen har en tendens til at være bedre på den måde.
Indekseret beregnede kolonner (vedvarende eller ej) kan bruges til at give bestilling og en effektiv adgangsmetode. Det kan være nyttigt at gemme en beregnet værdi i et indeks uden også at bevare den i basistabellen. Ligeledes kan egnede beregnede kolonner også inkluderes i indekser i stedet for at være nøglekolonner.
Dårlig ydeevne
En væsentlig årsag til dårlig ydeevne er en simpel fejl i at bruge en indekseret eller vedvarende beregnet kolonneværdi som forventet. Jeg har mistet tallet på antallet af spørgsmål, jeg har haft gennem årene, hvor jeg spurgte, hvorfor optimeringsværktøjet ville vælge en forfærdelig udførelsesplan, når der findes en åbenbart bedre plan, der bruger en indekseret eller vedvarende beregnet kolonne.
Den præcise årsag varierer i hvert enkelt tilfælde, men er næsten altid enten en fejlagtig omkostningsbaseret beslutning (fordi skalarer er tildelt en lav fast omkostning); eller en fejl i at matche et udvidet udtryk tilbage til en vedvarende beregnet kolonne eller indeks.
Match-back-fejlene er særligt interessante for mig, fordi de ofte involverer komplekse interaktioner med ortogonale motorfunktioner. Lige så ofte efterlader fejlen i at "matche tilbage" et udtryk (i stedet for en kolonne) på en position i det interne forespørgselstræ, der forhindrer en vigtig optimeringsregel i at matche. I begge tilfælde er resultatet det samme:en suboptimal eksekveringsplan.
Nu synes jeg, det er rimeligt at sige, at folk generelt indekserer eller fortsætter en beregnet kolonne med den stærke forventning om, at den lagrede værdi rent faktisk vil blive brugt. Det kan komme som noget af et chok at se SQL Server omberegne det underliggende udtryk hver gang, mens man ignorerer den bevidst angivne lagrede værdi. Folk er ikke altid særligt interesserede i de interne interaktioner og mangler i omkostningsmodellen, der førte til det uønskede resultat. Selv hvor der findes løsninger, kræver disse tid, dygtighed og indsats for at opdage og teste.
Kort sagt:mange mennesker ville simpelthen foretrække, at SQL Server bruger den vedvarende eller indekserede værdi. Altid.
En ny mulighed
Historisk set har der ikke været nogen måde at tvinge SQL Server til altid at bruge den lagrede værdi (ingen ækvivalent til NOEXPAND tip til visninger). Der er nogle omstændigheder, hvor en planguide vil fungere, men det er ikke altid muligt at generere den nødvendige planform i første omgang, og ikke alle planelementer og positioner kan forceres (f.eks. filtre og beregne skalarer).
Der er stadig ingen pæn, fuldt dokumenteret løsning, men en nylig opdatering til SQL Server 2016 har givet en interessant ny tilgang. Det gælder for SQL Server 2016-forekomster, der er patchet med mindst kumulativ opdatering 2 til SQL Server 2016 SP1 eller kumulativ opdatering 4 til SQL Server 2016 RTM.
Den relevante opdatering er dokumenteret i:RETNING:Kan ikke genopbygge partitionen online for en tabel, der indeholder en beregnet partitioneringskolonne i SQL Server 2016
Som så ofte med supportdokumentation, siger dette ikke præcist, hvad der er blevet ændret i motoren for at løse problemet. Det ser bestemt ikke særlig relevant ud i forhold til vores aktuelle bekymringer, at dømme efter titlen og beskrivelsen. Ikke desto mindre introducerer denne rettelse et nyt understøttet sporingsflag 176 , som er kontrolleret i en kodemetode kaldet FDontExpandPersistedCC . Som metodenavnet antyder, forhindrer dette en vedvarende beregnet kolonne i at blive udvidet.
Der er tre vigtige forbehold til dette:
- Den beregnede kolonne skal være vedvarende . Selvom den er indekseret, skal kolonnen også bevares.
- Match tilbage fra generelle forespørgselsudtryk til vedvarende beregnede kolonner er deaktiveret .
- Dokumentationen beskriver ikke sporingsflagets funktion og foreskriver det ikke til anden brug. Hvis du vælger at bruge sporingsflag 176 for at forhindre udvidelse af vedvarende beregnede kolonner, vil det derfor være på eget ansvar.
Dette sporingsflag er effektivt som en opstart –T mulighed, både globalt og sessionsomfang ved hjælp af DBCC TRACEON , og pr. forespørgsel med OPTION (QUERYTRACEON) .
Eksempel
Dette er en forenklet version af et spørgsmål (baseret på et problem i den virkelige verden), som jeg besvarede på Database Administrators Stack Exchange for et par år siden. Tabeldefinitionen inkluderer en vedvarende beregnet kolonne:
CREATE TABLE dbo.T( ID heltal IDENTITY NOT NULL, A varchar(20) NOT NULL, B varchar(20) NOT NULL, C varchar(20) NOT NULL, D date NULL, Beregnet SOM A + '-' + B + '-' + C PERSISTED, BEGRÆNSNING PK_T_ID PRIMÆR NØGLE KLYNGET (ID),);GOINDSÆT dbo.T MED (TABLOCKX) (A, B, C, D)VÆLG A =STR(SV.tal % 10, 2 ), B =STR(SV.tal % 20, 2), C =STR(SV.tal % 30, 2), D =DATEADD(DAG, 0 - SV.nummer, SYSUTCDATETIME())FRA master.dbo.spt_values AS SVWHERE SV.[type] =N'P';
Forespørgslen nedenfor returnerer alle rækker fra tabellen i en bestemt rækkefølge, mens den også returnerer den næste værdi af kolonne D i samme rækkefølge:
VÆLG T1.ID, T1.Computed, T1.D, NextD =( VÆLG TOP (1) t2.D FRA dbo.T AS T2 HVOR T2.Computed =T1.Computed OG T2.D> T1.D ORDER AF T2.D ASC )FRA dbo.T AS T1ORDER BY T1.Computed, T1.D;
Et oplagt dækkende indeks til at understøtte den endelige bestilling og opslag i underforespørgslen er:
OPRET UNIKT IKKE-KLUSTERET INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);
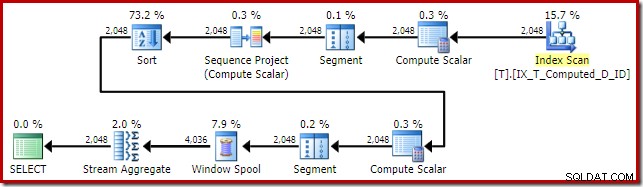
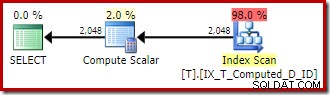
Udførelsesplanen leveret af optimizeren er overraskende og skuffende:
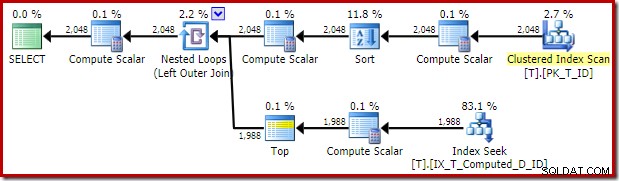
Indekssøgningen på indersiden af Nested Loops Join ser ud til at være i orden. Clustered Index Scan og Sort på det ydre input er dog uventet. Vi havde håbet på at se en bestilt scanning af vores dækkende ikke-klyngede indeks i stedet.
Vi kan tvinge optimeringsværktøjet til at bruge det ikke-klyngede indeks med et tabeltip:
VÆLG T1.ID, T1.Computed, T1.D, NextD =( VÆLG TOP (1) t2.D FRA dbo.T AS T2 HVOR T2.Computed =T1.Computed OG T2.D> T1.D ORDER AF T2.D ASC )FRA dbo.T AS T1 MED (INDEX(IX_T_Computed_D_ID)) -- Nyt!ORDER BY T1.Computed, T1.D;
Den resulterende eksekveringsplan er:
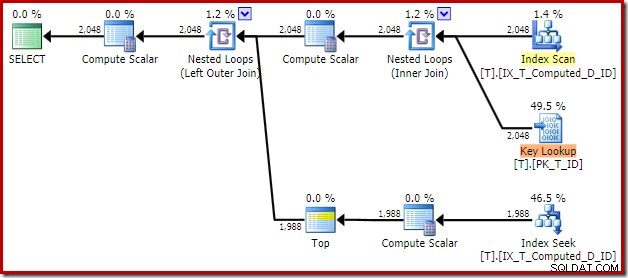
Scanning af det ikke-klyngede indeks fjerner sorteringen, men tilføjer et nøgleopslag! Opslagene i denne nye plan er overraskende, i betragtning af at vores indeks helt sikkert dækker alle kolonner, der er nødvendige for forespørgslen.
Ser på egenskaberne for nøgleopslagsoperatøren:
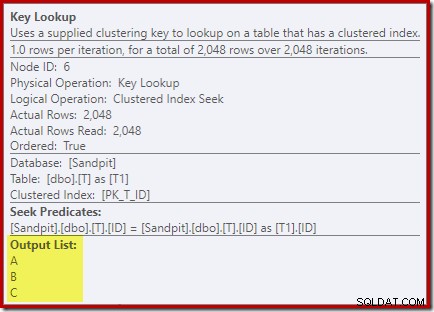
Af en eller anden grund har optimeringsværktøjet besluttet, at tre kolonner, der ikke er nævnt i forespørgslen, skal hentes fra basistabellen (da de ikke er til stede i vores ikke-klyngede indeks af design).
Når vi kigger rundt i udførelsesplanen, opdager vi, at de opsøgte kolonner er nødvendige for den indvendige side Index Seek:

Den første del af dette søgeprædikat svarer til korrelationen T2.Computed = T1.Computed i den oprindelige forespørgsel. Optimeringsværktøjet har udvidet definitionerne af begge beregnede kolonner, men kun formået at matche tilbage til den vedvarende og indekserede beregnede kolonne for det indre sidealias T1 . Forlader T2 reference udvidet har resulteret i, at den ydre side af joinforbindelsen skal have basistabelkolonnerne (A , B og C ) nødvendig for at beregne det udtryk for hver række.
Som det nogle gange er tilfældet, er det muligt at omskrive denne forespørgsel, så problemet forsvinder (en mulighed er vist i mit gamle svar på Stack Exchange-spørgsmålet). Ved at bruge SQL Server 2016 kan vi også prøve at spore flag 176 for at forhindre, at de beregnede kolonner udvides:
VÆLG T1.ID, T1.Computed, T1.D, NextD =( VÆLG TOP (1) t2.D FRA dbo.T AS T2 HVOR T2.Computed =T1.Computed OG T2.D> T1.D ORDER AF T2.D ASC )FRA dbo.T AS T1ORDER BY T1.Computed, T1.DOPTION (QUERYTRACEON 176); -- Nyt!
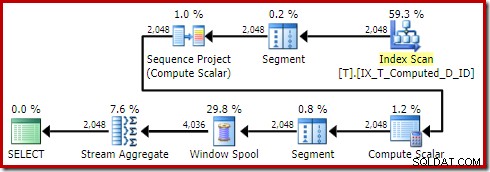
Udførelsesplanen er nu meget forbedret:
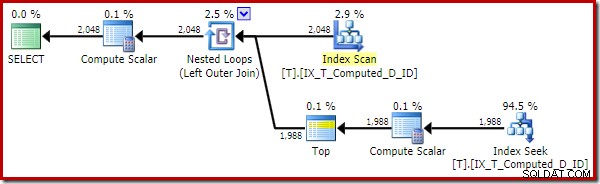
Denne udførelsesplan indeholder kun referencer til de beregnede kolonner. Compute Scalars gør ikke noget nyttigt og ville blive ryddet op, hvis optimeringsværktøjet var lidt mere ryddeligt rundt i huset.
Det vigtige er, at det optimale indeks nu bruges korrekt, og sortering og nøgleopslag er blevet elimineret. Alt sammen ved at forhindre SQL Server i at gøre noget, vi aldrig ville have forventet, at den ville gøre i første omgang (udvidelse af en vedvarende og indekseret beregnet kolonne).
Brug af LEAD
Det oprindelige Stack Exchange-spørgsmål var rettet mod SQL Server 2008, hvor LEAD er ikke tilgængelig. Lad os prøve at udtrykke kravet til SQL Server 2016 ved hjælp af den nyere syntaks:
VÆLG T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FROM dbo.T AS T1ORDER BY T1.Computed;SQL Server 2016-udførelsesplanen er:
Denne planform er ret typisk for en enkel rækketilstandsvinduefunktion. Det ene uventede element er sorteringsoperatoren i midten. Hvis datasættet var stort, kunne denne sortering have stor indflydelse på ydeevne og hukommelsesforbrug.
Problemet er endnu en gang beregnet kolonneudvidelse. I dette tilfælde sidder et af de udvidede udtryk i en position, der forhindrer normal optimeringslogik i at forenkle sorteringen.
Prøver nøjagtig den samme forespørgsel med sporingsflag 176:
VÆLG T1.ID, T1.Computed, T1.D, NextD =LEAD(T1.D) OVER ( PARTITION BY T1.Computed ORDER BY T1.D)FRA dbo.T AS T1ORDER BY T1.ComputedOPTION (QUERYTRACEON 176 );Fremstiller planen:
Sorten er forsvundet, som den burde. Bemærk også i forbifarten, at denne forespørgsel kvalificerede til en triviel plan, hvilket helt undgår omkostningsbaseret optimering.
Deaktiveret matchning af generelle udtryk
En af advarslerne nævnt tidligere var, at sporingsflag 176 også deaktiverer matchning fra udtryk i kildeforespørgslen til vedvarende beregnede kolonner.
For at illustrere, overvej følgende version af eksempelforespørgslen.
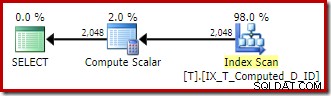
LEADberegning er blevet fjernet, og referencerne til den beregnede kolonne iSELECTogORDER BYklausuler er blevet erstattet med de underliggende udtryk. Kør det først uden sporingsflag 176:VÆLG T1.ID, beregnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.C;Udtrykkene matches til den vedvarende beregnede kolonne, og udførelsesplanen er en simpel ordnet scanning af det ikke-klyngede indeks:
Compute Scalar der er endnu en gang blot tilbageværende arkitektonisk skrammel.
Prøv nu den samme forespørgsel med sporingsflag 176 aktiveret:
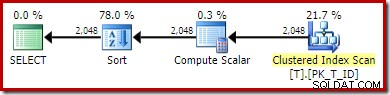
VÆLG T1.ID, beregnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1.B + '-' + T1.COPTION (QUERYTRACEON 176); -- Nyt!Den nye udførelsesplan er:
Den ikke-klyngede indeksscanning er blevet erstattet med en klynget indeksscanning. Compute Scalar evaluerer udtrykket, og sorteringsrækkefølgen efter resultatet. Frataget evnen til at matche udtryk til vedvarende beregnede kolonner, kan optimeringsværktøjet ikke gøre brug af den vedvarende værdi eller det ikke-klyngede indeks.
Bemærk, at begrænsningen af udtryksmatchning kun gælder for vedvarende beregnede kolonner, når sporingsflag 176 er aktivt. Hvis vi gør den beregnede kolonne indekseret, men ikke persisted, fungerer udtryksmatching korrekt.
For at droppe den vedvarende attribut skal vi først droppe det ikke-klyngede indeks. Når ændringen er foretaget, kan vi sætte indekset lige tilbage (fordi udtrykket er deterministisk og præcist):
DROP INDEX IX_T_Computed_D_ID ON dbo.T;GOALTER TABLE dbo.TALTER COLUMN ComputedDROP PERSISTED;GOCREATE UNIQUE NOTCLUSTERED INDEX IX_T_Computed_D_IDON dbo.T (Computed, D, ID);Optimeringsværktøjet har nu ingen problemer med at matche forespørgselsudtrykket til den beregnede kolonne, når sporingsflag 176 er aktivt:
-- Beregnet kolonne eksisterede ikke længere-- men stadig indekseret. TF 176 aktiv.VÆLG T1.ID, beregnet =T1.A + '-' + T1.B + '-' + T1.C, T1.DFROM dbo.T AS T1ORDER BY T1.A + '-' + T1. B + '-' + T1.COPTION (QUERYTRACEON 176);Udførelsesplanen vender tilbage til den optimale ikke-klyngede indeksscanning uden en sortering:
For at opsummere:Sporingsflag 176 forhindrer vedvarende beregnet kolonneudvidelse. Som en bivirkning forhindrer den også matchning af forespørgselsudtryk til kun vedvarende beregnede kolonner.
Skemametadata indlæses kun én gang i bindingsfasen. Sporingsflag 176 forhindrer udvidelse, så den beregnede kolonnedefinition er ikke indlæst på det tidspunkt. Senere udtryk-til-kolonne-matchning kan ikke fungere uden den beregnede kolonnedefinition at matche imod.
Den indledende metadataindlæsning bringer alle kolonner ind, ikke kun dem, der henvises til i forespørgslen (den optimering udføres senere). Dette gør alle beregnede kolonner tilgængelige for matchning, hvilket generelt er en god ting. Desværre, hvis en af de indlæste beregnede kolonner indeholder en skalær brugerdefineret funktion, deaktiverer dens tilstedeværelse parallelitet for hele forespørgslen, selv når den problematiske kolonne ikke bruges. Sporflag 176 kan også hjælpe med dette, hvis den pågældende søjle bliver ved. Ved ikke at indlæse definitionen er en skalær brugerdefineret funktion aldrig til stede, så parallelitet er ikke deaktiveret.
Sidste tanker
Det forekommer mig, at SQL Server-verdenen er et bedre sted, hvis optimeringsværktøjet behandlede vedvarende eller indekserede beregnede kolonner mere som almindelige kolonner. I næsten alle tilfælde ville dette bedre matche udviklerens forventninger end det nuværende arrangement. At udvide beregnede kolonner til deres underliggende udtryk og senere forsøge at matche dem tilbage er ikke så vellykket i praksis, som teorien kunne antyde.
Indtil SQL Server giver specifik support for at forhindre vedvarende eller indekseret udvidelse af beregnede kolonner, er det nye sporingsflag 176 en fristende mulighed for SQL Server 2016-brugere, omend en ufuldkommen. Det er lidt uheldigt, at det deaktiverer generel udtryksmatching som en bivirkning. Det er også en skam, at den beregnede kolonne skal bevares, når den indekseres. Der er så risikoen for at bruge et sporingsflag til andet end dets dokumenterede formål at overveje.
Det er rimeligt at sige, at de fleste problemer med beregnede kolonneforespørgsler i sidste ende kan løses på andre måder, givet tilstrækkelig tid, indsats og ekspertise. På den anden side ser sporflag 176 ofte ud til at virke som magi. Valget er, som de siger, dit.
For at afslutte, her er nogle interessante beregnede kolonneproblemer, som drager fordel af sporingsflag 176:
- Beregnet kolonneindeks ikke brugt
- VEDVARENDE beregnet kolonne bruges ikke i partitionering af vinduesfunktion
- Vedvarende beregnet kolonne forårsager scanning
- Beregnet kolonneindeks bruges ikke med MAX datatyper
- Alvorligt ydeevneproblem med vedvarende beregnede kolonner og joinforbindelser
- Hvorfor "Compute Scalar", når jeg VÆLGER en vedvarende beregnet kolonne?
- Basiskolonner brugt i stedet for vedvarende beregnet kolonne for motor
- Computed Column med UDF deaktiverer parallelisme for forespørgsler på *andre* kolonner