Lad os sige, at du vil finde alle de patienter, der aldrig har fået en influenzasprøjte. Eller i AdventureWorks2012 , kan et lignende spørgsmål være, "vis mig alle de kunder, der aldrig har afgivet en ordre." Udtrykt ved hjælp af NOT IN , et mønster, jeg ser alt for ofte, der ville se sådan ud (jeg bruger de forstørrede overskrifts- og detaljetabeller fra dette script af Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Når jeg ser dette mønster, kryber jeg sammen. Men ikke af præstationsmæssige årsager – det skaber trods alt en anstændig nok plan i dette tilfælde:
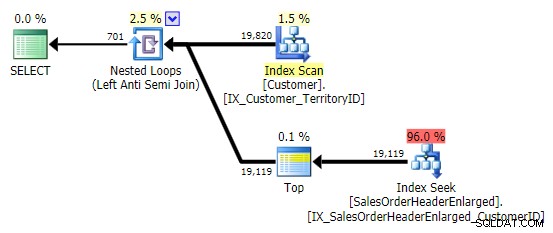
Hovedproblemet er, at resultaterne kan være overraskende, hvis målkolonnen er NULLable (SQL Server behandler dette som en venstre anti-semi join, men kan ikke pålideligt fortælle dig, om en NULL på højre side er lig med – eller ikke lig med – referencen i venstre side). Desuden kan optimering opføre sig anderledes, hvis kolonnen er NULLbar, selvom den faktisk ikke indeholder nogen NULL-værdier (Gail Shaw talte om dette tilbage i 2010).
I dette tilfælde er målkolonnen ikke nullbar, men jeg ville gerne nævne de potentielle problemer med NOT IN – Jeg vil muligvis undersøge disse spørgsmål mere grundigt i et fremtidigt indlæg.
TL;DR-version
I stedet for NOT IN , brug en korreleret NOT EXISTS for dette forespørgselsmønster. Altid. Andre metoder kan konkurrere med det med hensyn til ydeevne, når alle andre variabler er de samme, men alle de andre metoder introducerer enten ydeevneproblemer eller andre udfordringer.
Alternativer
Så hvilke andre måder kan vi skrive denne forespørgsel på?
YDRE ANVENDELSE
En måde, vi kan udtrykke dette resultat på, er at bruge en korreleret OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logisk set er dette også en venstre anti semi join, men den resulterende plan mangler den venstre anti semi join operator og ser ud til at være en del dyrere end NOT IN tilsvarende. Dette er fordi det ikke længere er en venstre anti semi join; det behandles faktisk på en anden måde:en ydre join bringer alle matchende og ikke-matchende rækker ind, og *derefter* anvendes et filter for at eliminere matchene:
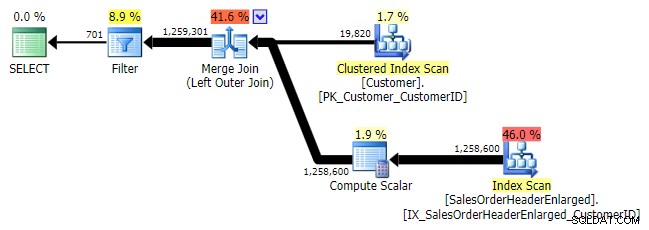
VENSTRE YDRE JOIN
Et mere typisk alternativ er LEFT OUTER JOIN hvor højre side er NULL . I dette tilfælde ville forespørgslen være:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Dette giver de samme resultater; dog, ligesom OUTER APPLY, bruger den den samme teknik til at samle alle rækkerne, og først derefter eliminere kampene:
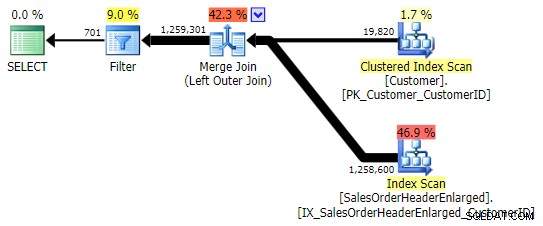
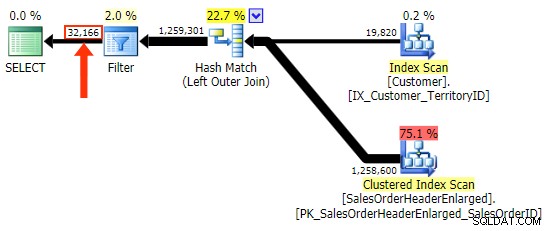
Du skal dog være forsigtig med, hvilken kolonne du tjekker for NULL . I dette tilfælde CustomerID er det logiske valg, fordi det er sammenføjningskolonnen; det er tilfældigvis også indekseret. Jeg kunne have valgt SalesOrderID , som er clustering-nøglen, så den er også i indekset på CustomerID . Men jeg kunne have valgt en anden kolonne, der ikke er i (eller som senere bliver fjernet fra) det indeks, der blev brugt til joinforbindelsen, hvilket fører til en anden plan. Eller endda en NULLbar kolonne, hvilket fører til forkerte (eller i det mindste uventede) resultater, da der ikke er nogen måde at skelne mellem en række, der ikke eksisterer, og en række, der eksisterer, men hvor den kolonne er NULL . Og det er måske ikke indlysende for læseren/udvikleren/fejlfinderen, at dette er tilfældet. Så jeg vil også teste disse tre WHERE klausuler:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Den første variation producerer den samme plan som ovenfor. De to andre vælger en hash join i stedet for en merge join og et smallere indeks i Customer tabel, selvom forespørgslen i sidste ende ender med at læse nøjagtigt det samme antal sider og mængden af data. Men mens h.SubTotal variation giver de korrekte resultater:
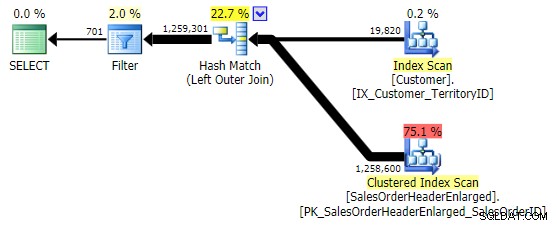
h.Comment variation gør det ikke, da den inkluderer alle rækker, hvor h.Comment IS NULL , samt alle de rækker, der ikke eksisterede for nogen kunde. Jeg har fremhævet den subtile forskel i antallet af rækker i outputtet, efter at filteret er blevet anvendt:
Ud over at jeg skal være forsigtig med kolonnevalg i filteret, har jeg et andet problem med LEFT OUTER JOIN form er, at den ikke er selvdokumenterende, på samme måde som en indre joinforbindelse i den "gammeldags" form af FROM dbo.table_a, dbo.table_b WHERE ... er ikke selvdokumenterende. Med det mener jeg, at det er nemt at glemme joinkriterierne, når det skubbes til WHERE klausul, eller for at den blandes med andre filterkriterier. Jeg ved godt, at dette er ret subjektivt, men der er det.
UNDTAGET
Hvis alt, vi er interesseret i, er sammenføjningskolonnen (som per definition er i begge tabeller), kan vi bruge EXCEPT – et alternativ, der tilsyneladende ikke kommer meget op i disse samtaler (sandsynligvis fordi – normalt – du skal udvide forespørgslen for at inkludere kolonner, du ikke sammenligner):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Dette kommer med nøjagtig samme plan som NOT IN variation ovenfor:
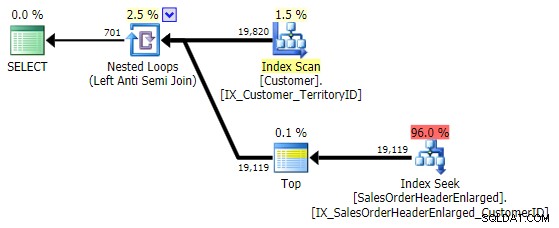
En ting at huske på er, at EXCEPT inkluderer en implicit DISTINCT – så hvis du har tilfælde, hvor du vil have flere rækker med samme værdi i tabellen "venstre", vil denne formular eliminere disse dubletter. Ikke et problem i dette specifikke tilfælde, bare noget at huske på – ligesom UNION versus UNION ALL .
FINDER IKKE
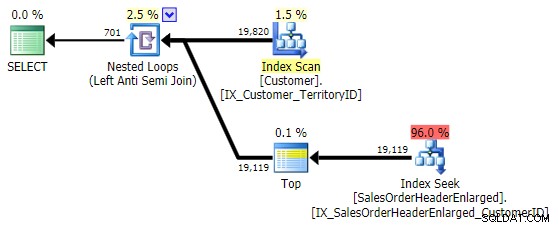
Min præference for dette mønster er absolut NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Og ja, jeg bruger SELECT 1 i stedet for SELECT * … ikke af ydeevnemæssige årsager, da SQL Server er ligeglad med hvilke(n) kolonne(r) du bruger inde i EXISTS og optimerer dem væk, men blot for at tydeliggøre hensigten:dette minder mig om, at denne "underforespørgsel" faktisk ikke returnerer nogen data.)
Dens ydeevne ligner NOT IN og EXCEPT , og det producerer en identisk plan, men er ikke tilbøjelig til de potentielle problemer forårsaget af NULL'er eller dubletter:
Performancetests
Jeg kørte et væld af tests, med både en kold og varm cache, for at bekræfte, at min mangeårige opfattelse af NOT EXISTS at være det rigtige valg forblev sandt. Det typiske output så således ud:
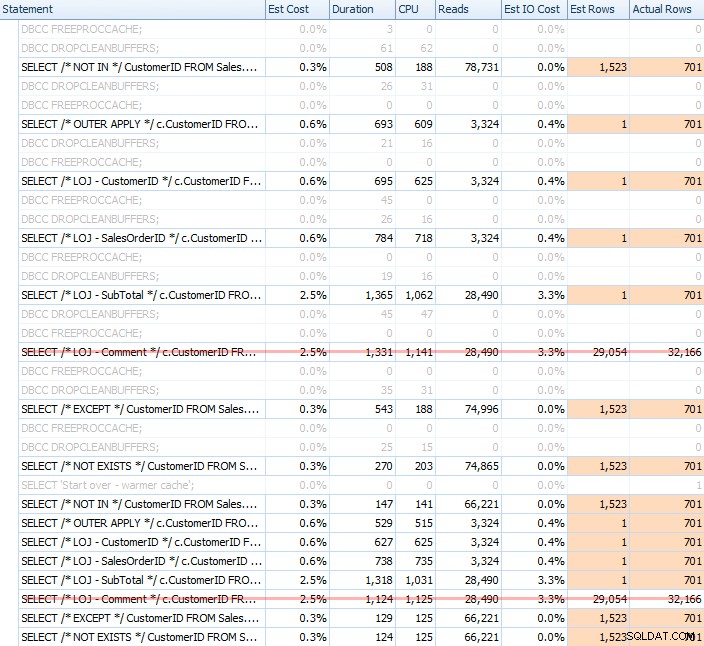
Jeg tager det forkerte resultat ud af blandingen, når jeg viser den gennemsnitlige ydeevne af 20 kørsler på en graf (jeg inkluderede det kun for at vise, hvor forkerte resultaterne er), og jeg udførte forespørgslerne i forskellig rækkefølge på tværs af tests for at sikre at én forespørgsel ikke konsekvent dragede fordel af arbejdet i en tidligere forespørgsel. Med fokus på varighed, her er resultaterne:
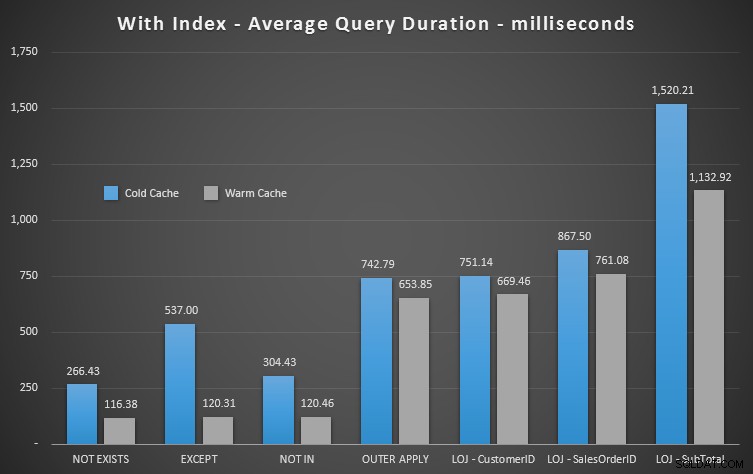
Hvis vi ser på varighed og ignorerer læsninger, er NOT EXISTS din vinder, men ikke meget. EXCEPT og NOT IN er ikke langt bagefter, men igen skal du se på mere end ydeevne for at afgøre, om disse muligheder er gyldige, og teste i dit scenario.
Hvad hvis der ikke er noget understøttende indeks?
Ovenstående forespørgsler drager naturligvis fordel af indekset på Sales.SalesOrderHeaderEnlarged.CustomerID . Hvordan ændres disse resultater, hvis vi dropper dette indeks? Jeg kørte det samme sæt test igen, efter at have droppet indekset:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Denne gang var der meget mindre afvigelse med hensyn til ydeevne mellem de forskellige metoder. Først vil jeg vise planerne for hver metode (hvoraf de fleste, ikke overraskende, indikerer anvendeligheden af det manglende indeks, vi lige har droppet). Så viser jeg en ny graf, der viser præstationsprofilen både med en kold cache og en varm cache.
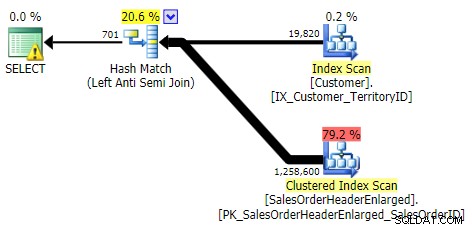
IKKE I, UNDTAGET, FINDER IKKE (alle tre var identiske)
YDRE ANVENDELSE
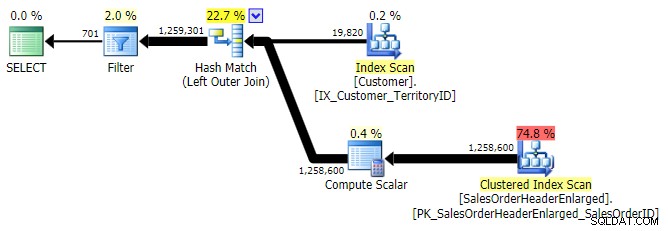
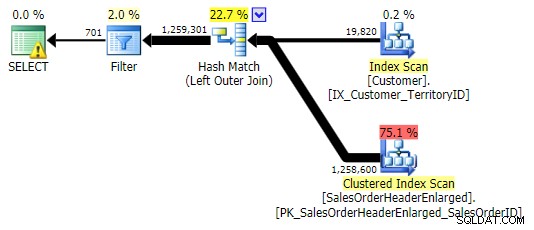
VENSTRE YDRE JOIN (alle tre var identiske bortset fra antallet af rækker)
Ydeevneresultater
Vi kan med det samme se, hvor nyttigt indekset er, når vi ser på disse nye resultater. I alle tilfælde undtagen ét (den venstre ydre joinforbindelse, der alligevel går uden for indekset), er resultaterne klart dårligere, når vi har droppet indekset:
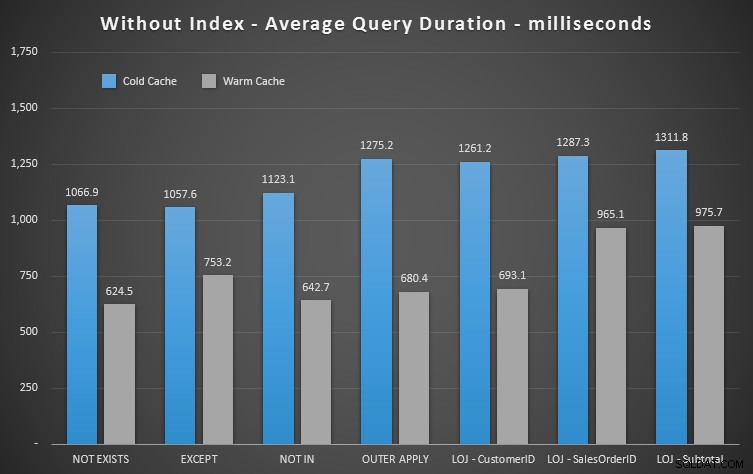
Så vi kan se, at selvom der er mindre mærkbar effekt, NOT EXISTS er stadig din marginale vinder i forhold til varighed. Og i situationer, hvor de andre tilgange er modtagelige for skemavolatilitet, er det også dit sikreste valg.
Konklusion
Dette var bare en meget langhåret måde at fortælle dig, at for mønsteret med at finde alle rækker i tabel A, hvor en betingelse ikke eksisterer i tabel B, NOT EXISTS vil typisk være dit bedste valg. Men som altid skal du teste disse mønstre i dit eget miljø ved at bruge dit skema, data og hardware og blandet med dine egne arbejdsbelastninger.