For at implementere understøttelse af flere sprog i din datamodel behøver du ikke at genopfinde hjulet. Denne artikel viser dig de forskellige måder at gøre det på og hjælper dig med at vælge den, der fungerer bedst for dig.
Begrebet lokalisering er afgørende for udviklingen af en softwareapplikation, især når denne applikations omfang er global. Understøttelse af flere sprog er det vigtigste aspekt at overveje; et databasedesign, der understøtter en flersproget applikation, giver dig mulighed for at diversificere dine målmarkeder og dermed nå ud til mange flere kunder. Desuden kunne et sådant databasedesign være en del af din langsigtede strategi for design af lokaliseringsklare systemer.
Nøglen til at inkorporere support på flere sprog i din applikation er at gøre det på en måde, der ikke drastisk øger udviklings- eller vedligeholdelsesomkostningerne. Da databasemodellering er en uadskillelig del af softwareudviklingsprocessen, skal du tænke over den bedste datamodeldesignstrategi for at give din applikation flersproget support.
En ordentlig datamodel skulle give dig mulighed for at ændre applikationen eller tilføje ny funktionalitet, mens du bibeholder understøttelse af flere sprog – uden at tilføje ekstra indsats eller omkostninger. Det bør også give dig mulighed for at inkorporere nye sprog uden at røre ved applikationen; du behøver kun at tilføje de tilsvarende oversættelsesdata til databasen.
Simpel implementering vs. fleksibilitet og funktionalitet
Der er forskellige tilgange til at skabe et databasedesign til flersprogede applikationer. Hver har sine fordele og ulemper. Dem, der er nemmere at implementere, giver mindre fleksibilitet og mindre funktionalitet; dem, der tilbyder mere fleksibilitet og funktionalitet, har mere komplekse implementeringer.
Mit råd her er altid at gå efter dem, der tilbyder mere funktionalitet og fleksibilitet , selvom de er dyrere at implementere. Nogle gange begår vi den fejl at tro, at en applikation er for lille, at det ikke er værd at implementere komplekse skemaer for at løse ting som flersproget support. Men i sidste ende vil den applikation vokse, og vi vil fortryde, at vi valgte den "hurtige og beskidte" tilgang, der virkede enklere og billigere.
Det ideelle til at implementere tilbehørsfunktionalitet til en applikation – det være sig support på flere sprog, ændringslogning, brugergodkendelse eller noget andet – er, at den funktionalitet har sit eget underskema og sin logik indkapslet i genanvendelige komponenter. På denne måde kan både tilbehørsfunktionaliteten og dets underskema inkorporeres i enhver ny applikation med minimal indsats.
Et intelligent databasedesign og datamodelleringsværktøj som Vertabelo er en stor hjælp til effektiv styring af dine skemaer og underskemaer. Tjek også disse tips til bedre databasedesign og sørg for at følge dem alle. Før du begynder at tegne dit ER-diagram, foreslår jeg, at du overvejer denne vigtige serie af databasemodelleringstip.
Nogle tiltalende (men uønskede) flersprogede databasedesignløsninger
Nemmest – men mindst anbefalet
Lad os starte med den mindst anbefalede, men nemmeste måde at implementere en flersproget applikationsdatabase på. Det giver dig mulighed for hurtigt at løse behovet for at understøtte en flersproget applikation, men det vil give dig problemer, når applikationen vokser i funktionalitet eller i geografisk dækning.
Denne enkle strategi består i at tilføje en ekstra kolonne for hver tekstkolonne, der skal oversættes, og for hvert sprog, som teksterne skal oversættes til.
For eksempel i Movies tabel nedenfor, er der en OriginalTitle Mark. Der tilføjes en ekstra titelkolonne for hvert sprog, der skal oversættes:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Die Hard | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | Tilbage til fremtiden | Volver al fremtid | Ritorno al fremtid | Retour vers le futur |
| 3 | Jurassic Park | Jurásico-parken | Giurassico parco | Parc jurassique |
Applikationen skal hente beskrivelsesdataene fra kolonnen, der svarer til det sprog, brugeren har valgt. Når du skal tilføje et nyt sprog, skal du tilføje en ekstra kolonne til tabellen for at indeholde de tekster, der er oversat til det nye sprog. Du skal også tilpasse applikationen for at anerkende det tilføjede sprog og kolonner.
Denne løsning kræver ikke komplicerede JOINs for at opnå de oversatte tekster, og den kræver heller ikke duplikerede poster - kun replikering af tekstindholdskolonner. Men dens anvendelighed er begrænset til situationer, hvor kun nogle få tabeller skal oversættes.
Antag for eksempel, at du har en Products tabel og en Processes bord. Hver af dem har et beskrivelsesfelt, der skal oversættes; virker nemt nok, ikke? Men hvis hele applikationen (inklusive alle dens menuindstillinger, fejlmeddelelser osv.) skal være flersproget, er denne løsning uanvendelig.
Mere alsidig, men heller ikke tilrådeligt
For at fortsætte med ideen om at holde oversættelser inden for samme tabel, er et alternativ til den tidligere mulighed at forstørre tekstfelterne. Dette ville give os mulighed for at gemme alle oversættelser i det samme felt og organisere dem i en datastruktur (f.eks. et XML-dokument eller et JSON-objekt). Nedenfor har vi et eksempel:
| Film-id | OriginalTitel | Oversættelser |
| 1 | Die Hard | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | Tilbage til fremtiden | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Jurassic Park | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Denne mulighed kræver ikke yderligere kolonner, men tilføjer kompleksitet. Dataforespørgslerne skal nu være i stand til korrekt at behandle og fortolke den datastruktur, der bruges til flersprogsunderstøttelse. Hvis f.eks. JSON eller XML bruges til at gemme oversættelser, skal SQL-forespørgsler bruge en SQL-version, der understøtter den valgte datatype.
Den følgende SQL-kommando bruger MS SQL Server OPENJSON() funktion for at bruge indholdet af Translations felt som en underordnet tabel:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Da der ikke er nogen funktioner eller operatorer til at manipulere JSON- eller XML-formaterede data i standard SQL, er du tvunget til at skrive dine forespørgsler til en bestemt RDBMS, hvis du vil bruge denne teknik til at gemme oversatte tekster. For eksempel er den tidligere forespørgsel ikke understøttet af MySQL. Hvis du har brug for at læse JSON-dataene i Movies tabel med MySQL, ville du skrive denne forespørgsel:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Lagring af oversat tekst i forskellige poster
Du kan også vælge at bruge forskellige poster for hvert sprog. Du må dog indstille dig på at miste normaliseringen:de samme data gentages i flere poster, hvor kun oversættelsen varierer.
| MovieId | LanguageId | Titel |
|---|---|---|
| 1 | da | Die Hard |
| 1 | sp | Duro de matar |
| 1 | det | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | da | Tilbage til fremtiden |
| 2 | sp | Volver al fremtid |
| 2 | det | Ritorno al fremtid |
Med denne mulighed kan du oprette visninger af hver tabel, der kun returnerer rækkerne på et givet sprog:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Derefter, for at forespørge i tabellen, kan du bruge en anden visning i henhold til måloversættelsessproget. Men normaliseringen af modellen går tabt, og bordvedligeholdelse er unødvendigt komplekst.
Lagring af oversat tekst i separate tabeller
En måde at gemme de oversatte tekster på uden at bryde relationsmodellen er at have en detaljeretabel for hver tabel, der indeholder tekster, der skal oversættes. Den underordnede tabel, der indeholder oversættelserne, skal have de samme nøglefelter som modertabellen, plus et felt, der angiver oversættelsessproget.
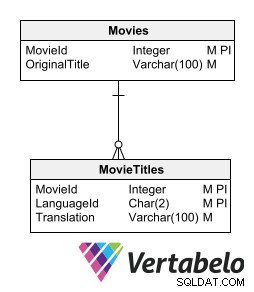
En underordnet tabel med oversættelser skal have de samme nøglefelter som modertabellen, plus et felt, der angiver oversættelsessproget.
Denne mulighed gør det muligt at inkorporere nye sprog uden at ændre tabelstrukturen. Det kræver ikke generering af redundant information eller brud på modelnormaliseringen.
Ulempen ved denne mulighed er, at den kræver oprettelse af en underordnet tabel for hver tabel, der gemmer tekstdata, der kræver oversættelse. Men ideen om at gemme oversættelser i relaterede tabeller bringer os tættere på den mest tilrådelige måde at designe en flersproget database på.
Den universelle løsning:Et oversættelsesunderskema
For at en applikation og dens database virkelig skal være flersproget, bør alle tekster have en oversættelse til hvert understøttet sprog – ikke kun tekstdataene i en bestemt tabel. Dette opnås med et oversættelsesunderskema, hvor alle data med tekstindhold, der kan nå brugerens øjne, gemmes.
I webapplikationer beregnet til brug på forskellige sprog er et oversættelsesunderskema en nødvendighed, ikke en mulighed. Alt andet vil føre til kompleksitet, der vil umuliggøre korrekt vedligeholdelse af applikationen.
Nøglen til at holde oversættelser i et separat skema er at opretholde et indekseret katalog med alle tekster, der skal oversættes, uanset om de er enhedsbeskrivelser, fejlmeddelelser eller menuindstillinger. Tanken er, at ingen tekst, der kan nå brugerens øjne, gemmes i nogen tabel uden for dette underskema.
En måde at organisere oversættelseskataloget på er at bruge tre tabeller:
- En hovedtabel over sprog.
- En tabel med tekster på originalsproget.
- En tabel med oversatte tekster.
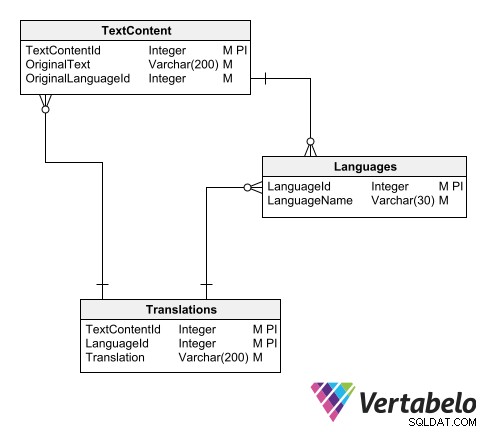
Skema for et universelt oversættelseskatalog.
I hovedtabellen over sprog indsætter vi blot en post for hvert sprog, der understøttes af datamodellen. Hver enkelt har en ID-kode og et navn:
| LanguageId | Sprognavn |
|---|---|
| da | Engelsk |
| sp | Spansk |
| det | Italiensk |
| fr | Fransk |
Teksttabellen registrerer alle tekster, der kræver oversættelse. Hver post har et vilkårligt id, den originale tekst og id'et for originalsproget.
I TextContent tabel, originalteksten og originalsprogets ID er ikke strengt nødvendige. Men de forenkler forespørgsler, der ikke kræver oversættelse. Når man f.eks. laver statistisk analyse eller styringskontrolforespørgsler (som normalt kun er tilgængelige for brugere, der forstår originalsproget), kan forespørgslerne forenkles ved at bruge standardteksterne (ikke-oversat).
De originale tekster er også nyttige for dem, der skal fylde tabellen over oversatte tekster. Indtastning af oversættelsesdata kan ske ved hjælp af en mini-applikation, der viser den originale tekst og oversættelser på alle tilgængelige sprog. Det er også muligt at generere information til oversættelsesunderskemaet gennem en automatisk proces ved hjælp af en oversættelses-API.
Link til hovedskemaet
I applikationens hovedskema erstattes kolonner med tekstværdier, der skal oversættes af id'er, der peger på tabellen over oversatte tekster:
Hovedskemaet er knyttet til oversættelsesskemaet gennem tabeller med tekster, der skal oversættes.
Du kan efterlade det originale tekstfelt i nogle af hovedskematabellerne for at lette forespørgsler, hvor oversættelse ikke er påkrævet, selvom dette genererer overflødig information. For eksempel kan vi beholde ProductDescription feltet i Products tabel for at lette statistiske forespørgsler eller for at udfylde dimensionerne af et datavarehus, idet man ser bort fra oversættelsesunderskemaet, når det ikke er nødvendigt.
- Multi-Language Database Design:Gør det én gang, og gør det rigtigt
Vi har set flere alternativer til at skabe et flersproget databasedesign. Nogle er nemmere og hurtigere at implementere. Den sidste løsning er lidt mere kompleks, men den giver dig meget mere fleksibilitet. Det vil også spare dig for problemer, når tiden kommer til at vedligeholde applikationen og databasen. Således vil det i det lange løb være meget billigere.
Til tider frister den korteste vej i databasedesign dig til at tro, at du vil spare tid og kræfter. Men når du vælger den, overser du, at du nok skal ned ad den flere gange. Hvis du ignorerer bedste praksis for flersproget databasedesign, vil du sandsynligvis ende med at udføre det samme arbejde igen og igen.