I en tidligere artikel diskuterede vi stjerneskemamodellen. Snefnugskemaet er ved siden af stjerneskemaet med hensyn til dets betydning i datavarehusmodellering. Det blev udviklet ud fra stjerneskemaet, og det giver nogle fordele i forhold til sin forgænger. Men disse fordele har en pris. I denne artikel vil vi diskutere, hvornår og hvordan man bruger snefnugskemaet.
Snefnugskemaet
Snefnugskemaets navn kommer fra det faktum, at dimensionstabeller forgrener sig og ligner et snefnug. Når vi ser på modellen ovenfor, vil vi bemærke, at det er en faktatabel omgivet af et par dimensionstabeller, hvoraf nogle udfører den førnævnte forgrening. I modsætning til stjerneskemaet kan dimensionstabeller i snefnugskemaet have deres egne kategorier.
Den herskende idé bag snefnugskemaet er, at dimensionstabeller er fuldstændig normaliserede. Hver dimensionstabel kan beskrives ved en eller flere opslagstabeller. Hver opslagstabel kan beskrives ved en eller flere yderligere opslagstabeller. Dette gentages, indtil modellen er fuldt normaliseret. Processen med at normalisere dimensionstabeller for stjerneskemaer kaldes snefnug.
Du vil høre meget om normalisering i denne artikel. Hvad er normalisering? Grundlæggende er det at organisere en database på en måde, der minimerer redundans og beskytter dataintegriteten. Tjek dette indlæg for at lære mere om normalisering og denormalisering.
Eksempel på snefnugskema:Salgsmodel
Tidligere brugte vi et stjerneskema til at modellere en fiktiv salgsafdeling – dette ville være beslægtet med en datamart, der bruges til at spore salgsaktiviteter og resultater. Modellen har fem dimensioner:produkt , tid , butik , salg type og medarbejder . I fact_sales tabel, pris og mængde gemmes og grupperes baseret på værdier i dimensionstabeller. For en genopfriskning, se salgsmodellen med stjerneskemaet nedenfor:
Her er den samme model organiseret som et snefnugskema:
dim_employee og dim_sales_type dimensionstabeller er nøjagtig de samme som i stjerneskemamodellen, fordi de allerede er normaliserede.
På den anden side anvendte vi normaliseringsregler på resten af dimensionstabellerne.


dim_product dimensionstabel fra stjerneskemaet er opdelt i to tabeller i snefnugmodellen. dim_product_type tabel blev tilføjet for at referere til den matchende type i dim_product bord. Ved at bruge dette undgik vi nogle dataintegritetsproblemer.
Det er logisk at antage, at vi allerede har alle produktnavne og deres relaterede typer indsat som en del af ETL-processen, men antag, at vi skal tilføje flere produktnavne og typer. I et stjerneskema kunne vi fejlagtigt indtaste den forkerte produkttype i tabellen. I snefnugskemaet:
- Hvis vi støder på et nyt produkttypenavn, kan vi tilføje en ny produkttype og derefter relatere denne type til en nyligt tilføjet post. Dette kan dog resultere i, at brugeren indtaster forkerte oplysninger, ligesom i stjerneskema.
- Vi kunne kontrollere, om det produktnavn, vi vil tilføje, allerede eksisterer. Hvis ja, kan vi få dens ID; hvis ikke, kommer der en advarsel, der spørger os, om vi vil tilføje et nyt produkt og en relateret type.

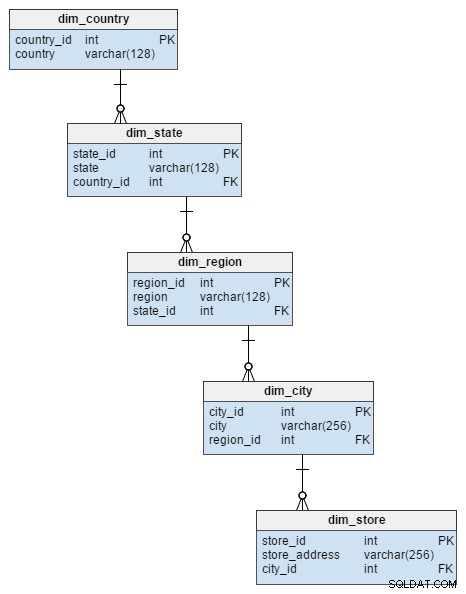
dim_store dimensionstabel fra stjerneskemaet er repræsenteret af 5 tabeller i snefnugskemaet. Disse opdeler by, region, stat og land attributter, der blev gemt i dim_store bord. Normalisering af denne tabel undgik ikke kun risiko for dataintegritet, det sparede også en del diskplads.
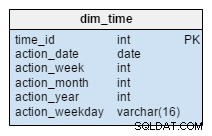
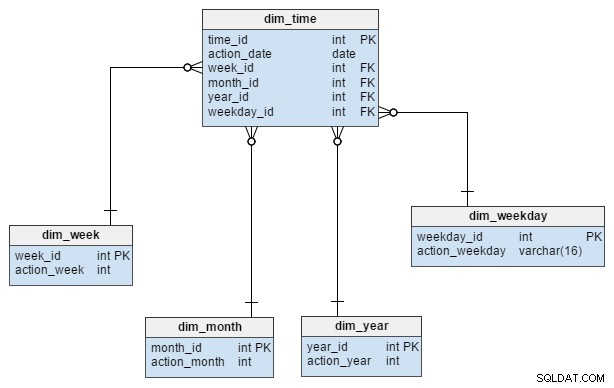
dim_time dimension er repræsenteret med fem tabeller. Vi kan tænke på dim_week , dim_month , dim_year og dim_weekday tabeller som ordbøger, der beskriver dim_time bord.
dim_week , dim_month , dim_year og dim_weekday tabeller er fire forskellige hierarkier, der bruges til at beskrive vores tidsdimension. Vi kunne tilføje flere dimensioner som kvartaler eller andre relaterede tabeller, hvis vi havde brug for dem. I dette eksempel dim_month er en ordbog indeholdende 12 måneder; fra denne dimension alene har vi ingen måde at vide, hvilket år den måned tilhører; det er funktionen af dim_year bord.
Eksempel på snefnugskema:Model for leveringsordrer
Det andet datamarked, vi diskuterede, var for forsyningsordrer. Idéen er at gemme og aggregere alle leveringsordredata for følgende fire dimensioner:produkt , tid , leverandør og medarbejder . Endnu en gang tager vi et kig på det relevante stjerneskema:
Konverterer dette til snefnugskemaet, får vi følgende model:
De samme normaliseringsregler som dem, der er beskrevet for salgsmodellen, blev brugt på dim_product , dim_time og dim_supplier dimensionstabeller.
Fordele og ulemper ved snefnugskemaet
Der er to hovedfordele til snefnugskemaet:
- Bedre datakvalitet (data er mere strukturerede, så problemer med dataintegritet reduceres)
- Der bruges mindre diskplads end i en denormaliseret model
Den mest bemærkelsesværdige ulempe for snefnugmodellen er, at den kræver mere komplekse forespørgsler. Disse forespørgsler kan med deres øgede antal joinforbindelser reducere ydeevnen betydeligt.
Vi omskriver den samme forespørgsel, der blev brugt i stjerneskemaartiklen til salgsmodellen for snefnugskema. Her er den forespørgsel, der er nødvendig for at returnere mængden af alle telefontyper, der sælges i Berlin-butikker i 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Starflake-skemaet
Et starflake-skema er en kombination af snefnug- og stjerneskemaerne. Vi kan se det som et snefnugskema, der har nogle dimensionstabeller denormaliseret. Når det bruges korrekt, kan starflake-skemaet give den bedste tilgang fra begge verdener. Det er klart, at snefnugdelen af modellen skal spare diskplads, mens stjernedelen skal forbedre ydeevnen.
Ovenstående model er grundlæggende en snefnugmodel med en denormaliseret dim_time bord. Da dette skema reducerer antallet af nødvendige forespørgselssammenføjninger, kan det forbedre ydeevnen. På den anden side mister vi ikke en nævneværdig mængde af diskpladsen, da de fleste tabelattributter og fremmednøgleattributter deler int type.
Galaxy-skemaet
I data warehousing er et galakseskema, når to eller flere faktatabeller deler en eller flere dimensionstabeller. En grund til at bruge dette skema er at spare diskplads. Vi har lavet et eksempel på et galakseskema nedenfor:
Her har vi to faktatabeller, fact_sales og fact_supply_order , der direkte deler tredimensionelle tabeller:dim_product , dim_employee og dim_time . Bemærk, at selv dim_store og dim_supplier del den samme opslagstabel, dim_city .
Vi sparer plads på denne måde, men vi skal have et par ting i tankerne, før vi samler to datamarts (i dette tilfælde salgs- og leveringsordrer) i ét galakseskema:
- Er der nogen logik bag at slutte sig til dem? F.eks. Ville begge data marts blive brugt af samme afdeling?
- Er vi sikre på, at vi har brug for præcis samme dimension og granulering for begge data marts?
Snefnugskemaet bruges ofte i datamodellering. Det kan være det rigtige valg i situationer, hvor diskplads er vigtigere end ydeevne. Hvis vi ønsker en balance mellem pladsbesparelse og ydeevne, kan vi bruge starflake-skemaet. Alligevel afhænger den rigtige pasform til ethvert specifikt problem af mange parametre. Dette er et af de områder inden for IT, hvor vi kan ’lege’ med faktorer for at komme frem til den bedste løsning.