
Tilbage i marts startede jeg en serie om gennemgående præstationsmyter i SQL Server. En overbevisning, jeg støder på fra tid til anden, er, at du kan overdimensionere varchar- eller nvarchar-kolonner uden nogen form for straf.
Lad os antage, at du gemmer e-mail-adresser. I et tidligere liv beskæftigede jeg mig en del med dette – på det tidspunkt udtalte RFC 3696, at en e-mailadresse kunne være på 320 tegn (64chars@255chars). En nyere RFC, #5321, anerkender nu, at 254 tegn er det længste, en e-mail-adresse kan være. Og hvis nogen af jer har en så lang adresse, så burde vi måske snakke. :-)
Nu, uanset om du går efter den gamle standard eller den nye, skal du understøtte muligheden for, at nogen vil bruge alle de tilladte tegn. Hvilket betyder, at du skal bruge 254 eller 320 tegn. Men det, jeg har set folk gøre, er slet ikke at bekymre sig om at undersøge standarden, og blot antage, at de skal understøtte 1.000 tegn, 4.000 tegn eller endda mere.
Så lad os tage et kig på, hvad der sker, når vi har tabeller med en e-mailadressekolonne af varierende størrelse, men som gemmer nøjagtig de samme data:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Lad os nu generere 10.000 fiktive e-mailadresser fra systemmetadata og udfylde alle fire tabeller med de samme data:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;REBUIL_V;
For at validere, at hver tabel indeholder nøjagtig de samme data:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Alle fire af dem giver 35 og 77 for mig; dit kilometertal kan variere. Lad os også sikre os, at alle fire tabeller optager det samme antal sider på disken:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Alle fire af disse forespørgsler giver 89 sider (igen, dit kilometertal kan variere).
Lad os nu tage en typisk forespørgsel, der resulterer i en klynget indeksscanning:
SELECT id, email FROM dbo.Email_<size>;
Hvis vi ser på ting som varighed, aflæsninger og estimerede omkostninger, virker de alle ens:
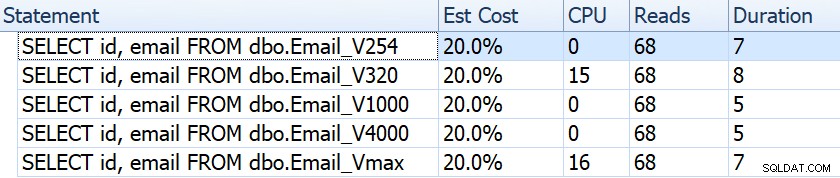
Dette kan lulle folk ind i en falsk antagelse om, at der overhovedet ikke er nogen præstationspåvirkning. Men hvis vi kigger lidt nærmere på værktøjstippet til den grupperede indeksscanning i hver plan, ser vi en forskel, der kan spille ind i andre, mere omfattende forespørgsler:

Herfra ser vi, at jo større kolonnedefinitionen er, desto højere er den estimerede række og datastørrelse. I denne simple forespørgsel er I/O-omkostningerne (0,0512731) den samme på tværs af alle forespørgsler, uanset definition, fordi den klyngede indeksscanning skal læse alle dataene alligevel.
Men der er andre scenarier, hvor denne estimerede række og samlede datastørrelse vil have en indflydelse:operationer, der kræver yderligere ressourcer, såsom sorteringer. Lad os tage denne latterlige forespørgsel, der ikke tjener noget egentligt formål, bortset fra at kræve flere sorteringsoperationer:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Vi kører disse fire forespørgsler, og vi ser, at planerne alle ser sådan ud:

Advarselsikonet på SELECT-operatøren vises dog kun på 4000/max-tabellerne. Hvad er advarslen? Det er en advarsel om overdreven hukommelsesbevilling, introduceret i SQL Server 2016. Her er advarslen for varchar(4000):

Og for varchar(max):

Lad os se lidt nærmere og se, hvad der foregår, i det mindste ifølge sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Resultater:

I mit scenarie blev varigheden ikke påvirket af hukommelsesbevillingsforskellene (bortset fra max-tilfældet), men du kan tydeligt se den lineære progression, der falder sammen med den deklarerede størrelse af kolonnen. Som du kan bruge til at ekstrapolere, hvad der ville ske på et system med utilstrækkelig hukommelse. Eller en mere omfattende forespørgsel mod et meget større datasæt. Eller betydelig samtidighed. Ethvert af disse scenarier kan kræve spild for at behandle sorteringsoperationerne, og varigheden vil næsten helt sikkert blive påvirket som et resultat.
Men hvor kommer disse større hukommelsesbevillinger fra? Husk, det er den samme forespørgsel, mod nøjagtig de samme data. Problemet er, at SQL Server for visse operationer skal tage højde for, hvor meget data *kan* være i en kolonne. Det gør det ikke baseret på faktisk profilering af dataene, og det kan ikke lave nogen antagelser baseret på <=201 histogramtrinværdier. I stedet skal den anslå, at hver række har en værdi, der er halvdelen af den deklarerede kolonnestørrelse . Så for en varchar(4000) antager den, at hver e-mail-adresse er 2.000 tegn lang.
Når det ikke er muligt at have en e-mailadresse længere end 254 eller 320 tegn, er der ikke noget at vinde ved at overdimensionere, og der er masser at miste potentielt. At øge størrelsen af en kolonne med variabel bredde senere er meget nemmere end at håndtere alle ulemperne nu.
Selvfølgelig overstørrelse char eller nchar kolonner kan have meget mere åbenlyse straffe.