I vores tidligere Hybrid Cloud-blogs nævner vi ofte, at en af de primære muligheder for at benytte Hybrid Cloud-topologiopsætningen er at bruge dette som dit mål for gendannelse efter katastrofe. Det er almindeligt for en organisationsstruktur, at en Disaster Recovery Plan (DRP) altid behandles før den arkitektoniske implementering af din databaseopsætning, enten i skyen eller on-prem. Du tror måske, at alt vil fejle uforudsigeligt og kan påvirke din virksomhed tragisk, hvis det ikke bliver behandlet og forstået korrekt. At overvinde disse udfordringer kræver en effektiv DRP (Disaster Recovery Plan), som dit system er godt konfigureret til i henhold til din applikation, infrastruktur og forretningskrav. Nøglen til succes i disse typer situationer er, hvor hurtigt vi kan løse eller komme os over problemet.
Mens DRP adresserer katastrofeforhold, vil Business Continuity sørge for, at DRP er testet og operationelt til enhver tid, når det er nødvendigt. Dine Disaster Recovery-muligheder for dine databaser skal sikre kontinuerlig drift og grænser til forventningernes grænser. Det skal være i overensstemmelse med din ønskede RTO og RPO. Det er bydende nødvendigt at sikre, at produktionsdatabaser er tilgængelige for applikationerne selv under katastrofer; ellers kan det ende med at blive en dyr handel. DBA'er, arkitekterne, er nødt til at sikre, at databasemiljøer kan tåle katastrofer og er SLA-kompatibel med disaster recovery. Databaseimplementeringer skal konfigureres korrekt for at sikre, at katastrofer ikke påvirker databasens tilgængelighed og forretningskontinuitet.
Indstillinger for katastrofegendannelse
Din PostgreSQL-klynge skal konfigureres med en systematisk tilgang, der forpligter sig til bedste praksis og er acceptabel i forhold til industristandarderne. Sammen med de systematiske tilgange hjælper følgende processer eller mekanismer dig med at sikre, at din PostgreSQL implementeret til en Hybrid Cloud har disse tilstedeværelser:
-
Failover/Switchover
-
Automatisk sikkerhedskopiering
-
Meget tilgængelig
-
Belastningsbalancering
-
Stærkt distribueret miljø
Failover/Switchover
Failover er en automatiseret proces, hvis din master fejler; enten hot standby eller varm standby server forfremmes til rollen som primær/master. Det er en bedste praksis, der giver et miljø med høj tilgængelighed at have mindst en sekundær node til at fungere som kandidat til en failover-knude. Når først den primære server svigter, bør standby-serveren begynde failover-procedurerne, og derefter skal den sekundære eller standby-server tage rollen som en master. Et failover-system bruger minimum to servere i almindelig praksis, som fungerer som den primære og standby. Dens forbindelseskontrol er assisteret af en hjerteslagsmekanisme, der udfører non-stop kontrol og verificerer, om begge er i god stand, og kommunikationen er i live. Men i nogle tilfælde kan forbindelsen give en falsk alarm. Derfor, i nogle opsætninger og miljøer, ligger tilstedeværelsen af et tredje system, såsom en overvågningsknude, på et separat netværk eller datacenter. Dette er en idiotsikker mulighed for at forhindre upassende eller uønsket failover. En idiotsikker verifikationsknude kan have ekstra funktioner og kontroller, som tilføjer kompleksitet. Denne opsætning kræver fuld og streng test for at sikre, at failover udføres rigtigt, når der er en ændring i implementeringen. Dette er også vigtigt for at forhindre enhver forringelse af din PostgreSQL
Lad os sige, at du har din sekundære eller standby-klynge på et andet datacenter med en anden hardwareopsætning; du ønsker måske ikke at failover brat, især hvis det ikke er et ideelt tilfælde på grund af blot en falsk positiv. Men i dette scenarie skal din datagendannelsesmålnode eller -klynge have de samme ressourcer og specifikationer som din primære node eller klynge. Hvis dit datagendannelsesmål er i en offentlig sky, og det primære er on-prem, skal du sikre dig, at det allerede er dækket af din kapacitetsplanlægning, og at ressourcer har næsten de samme specifikationer for at undgå uønskede resultater.
Når du bruger og forbereder din failover-mekanisme i din PostgreSQL-klynge i en hybridsky, skal du sikre dig, at dit værktøj passer perfekt til at udføre det job, der skal udføres. Der er tredjepartsværktøjer, der ikke er bundtet i PostgreSQL med hensyn til advance failover. For eksempel er der ClusterControl, pg_auto_failover af CitusData (c/o Microsoft), Pgpool-II, Bucardo og andre. Disse avancerede hjælpeværktøjer giver nodehegn eller kendt som STONITH (skyd den anden node i hovedet). Dette sikrer, at din mislykkede primære eller masterknude skal undgå at acceptere skrivninger eller komme tilbage online som sin tidligere tilstand for at betjene normale transaktioner. Dette problem er almindeligvis kendt som split-brain scenario. Den mister datasynkronisering på grund af en fejl (hardware- eller ressourceniveau), men stadig fungerer dine primære servere, som angiveligt kun er én primær server, som om, at de udfører normale modtagere af dataskriveanmodninger, hvilket forårsager datakorruption i hele klyngen.
Automatisk sikkerhedskopiering
Sikkerhedskopier giver altid høj sikkerhed og beskyttelse mod tab af data. Sikkerhedskopiering maksimerer din RPO, da den hjælper med at minimere tab af data, når en katastrofe rammer. Ting, du skal overveje og forberede til din automatiserede sikkerhedskopiering, dækker dit backupapparat/hardware, backup-dataredundans, sikkerhed, ydeevne, hastighed og datalagring.
Sikkerhedskopieringsapparat
Du skal have det bedste valg til din backup-enhed her. Hastighed, betydelig lagervolumen og høj tilgængelighed kan være dit ønskede valg. Nogle er afhængige af SAN- eller NAS-lager eller spreder deres data til andre tredjepartsleverandører af backuplager. Det er vigtigt, at din backup-enhed tilbyder hastighed til at skrive og læse data, især hvis du anvender komprimering og kryptering af dine data i hvile. Dekompression og dekryptering kræver ressourcer, så du skal overveje, hvornår du skal bruge datagendannelse. I denne tilstand skal du bestemme, at du skal opnå din maksimale RPO og forpligte den opnåelige SLA (Service-Level Agreement) til dine kunder. Det er også ideelt, at du muligvis skal isolere din sikkerhedskopi fra dit lokale netværk eller gemme den et fjerntliggende sted. En alternativ tilgang er at engagere sig med tredjepartsudbydere. For eksempel kan lagring af din backup i skyen være en mulighed, og deres facilitet er meget sofistikeret og opfylder dine krav.
Sikkerhedskopidataredundans
Spredning af dine data på flere steder er en ideel løsning. Dette styrker dine chancer for datagendannelse, for eksempel en menneskelig fejl eller en logisk softwarefejl, der får dig til at slette gamle kopier af sikkerhedskopien, men ved en fejl sletter hele vigtige sikkerhedskopier. I nogle sofistikerede miljøer, såsom lagring i et cloudmiljø, såsom Amazon S3, Cloud Storage by Google eller Azure Blob Storage, tilbyder du replikering af din gemte fil. Dette giver mere redundans og kan konfigureres på en fleksibel måde, der passer til dine krav.
Meget tilgængelig
En meget tilgængelig PostgreSQL-klynge i en Hybrid Cloud sikrer altid, at din databasekommunikation sikrer oppetid. Det ideelle tilfælde af høj tilgængelighed afhænger af målingen af din tilgængelighed. I dette tilfælde kan en fælles opsætning for en PostgreSQL implementeret i en hybridsky enten være din database hostet i en offentlig sky kan være din sekundære klynge, der fungerer som din datagendannelsesklynge i tilfælde af, at den primære klynge fejler eller lider af en netværkskatastrofe og kan tage meget nedetid. I nogle opsætninger er det muligt, at den sekundære klynge, der ligger i den offentlige sky, måske ikke er præcis så sofistikeret som den primære, lad os sige, at dette er din on-prem eller private cloud. Din applikation kan spille rundt for at begrænse de besøgende eller trafik, der kan oprette forbindelse til din database. Denne type scenarie kan reducere dine opsætningsomkostninger, men dette afhænger selvfølgelig kun af dine krav. Hvis din applikationstype er massiv og skal være non-stop med at modtage normale til travle trafiksituationer, skal du sørge for, at dine sekundære klyngressourcer skal være lige så effektive som de primære for at sikre høj tilgængelighed, dvs. 99,9999999 %.
For at opnå en meget tilgængelig PostgreSQL-klynge i et hybridt cloudmiljø skal du have en failover-mekanisme. I tilfælde af en fejl, og en primær klynge eller primær server går ned, kan en sekundær eller standby-server derefter tage rollen som en master, uanset hvor dens placering kan være. Det vigtigste er funktionaliteten, og ydeevnen, især fra applikations- eller klientsynspunktet, påvirkes ikke overhovedet eller i det mindste meget minimal.
Belastningsbalancering
Belastningsbalanceringsmekanisme til din PostgreSQL-klynge hjælper dit hybride cloud-opsætning, som er mere overskueligt og mindre risikabelt, især når der opstår høj trafikbelastning. I mange situationer får en server en alvorlig høj belastning, og serveren går i panik. Dette fører til en server ubrugelig tilstand på grund af travle ressourcer, der forbruges af en masse tråde, der kører i baggrunden. Denne situation kan forbedres ved at rette dårlige forespørgsler og designarkitekturen i din database. Dette bør omfatte, hvordan du distribuerer læsningen mod skrivebelastning og en dybdegående forståelse af dine applikationskrav som master-master-opsætning eller kun én master, men skalerer den lodret for at give højere computer- og hukommelsesressourcer. Der er også et stort udvalg af tredjepartsværktøjer såsom pgbouncer og Pgpool II til at hjælpe din PostgreSQL-implementering i et hybridt cloudmiljø.
Stærkt distribueret miljø
Skalerbarhed giver mere fleksibilitet og tolerabilitet i et hybridt cloudmiljø, og det er meget fordelt på flere lokationer eller forskellige cloud-udbydere (on-prem eller privat og offentlig sky), og dette er fantastisk til katastrofegendannelse. Det er fleksibelt, når det skal failover på en bestemt skylokation, der er gunstig for naturkatastrofer eller katastrofer, især hvis din udpegede region, hvor din primære klynge befinder sig, i øjeblikket er ødelagt eller påvirket af en naturlig årsag. Dette er en uundgåelig årsag, som du skal forstå og være pålidelig i forhold til den aktuelle situation. Din applikation og dine kunder skal betjenes kontinuerligt non-stop. Dette tjener det formål at være offentligt tilgængeligt i skyen, mens det også tjener i et privat eller lokalt miljø. Denne opsætning tilføjer mere høj kompleksitet og kræver avanceret viden på databasesiden og sikkerhed og netværk. Optimering og tuning er afgørende for succes her, da det er meget vigtigt, at mens du tjener en skærpet sikkerhed for at indkapsle dine data, mens du rejser på internettet, skal ydeevnen dokumenteres at stabilisere sig og ikke påvirkes af den implementerede opsætning.
På grund af kompleksiteten af opsætningen er et værktøj ideelt til at styre implementeringen og lette dine databasers overordnede status, overvåge det ene aspekt af din klynge, men på hele niveauet fra den lokale, private sky, og på det offentlige cloud-aspekt. Alle opsætninger skal holdes på et overskueligt og ligetil niveau, så det i tilfælde af alarmer og advarsler er nemt at rette og løse problemet korrekt og rettidigt.
ClusterControl til gendannelse efter katastrofe i et hybridt skymiljø
ClusterControl giver organisationen eller virksomhederne mulighed for at administrere databasen med fleksibilitet og reducere opsætningens overordnede kompleksitet. ClusterControl tilbyder failover, automatiseret backup, giver en høj tilgængelig opsætning, belastningsbalancering og understøtter en distribueret miljøimplementering, hvilket gør det nemmere at tilføje noder enten i en offentlig sky eller privat eller lokalt.
ClusterControl automatisk gendannelse
Den automatiske gendannelse af ClusterControl repræsenterer tonsvis af failover-mekanisme og gendannelseskarakteristika, især når en node går ned, eller en klynge går i en forringet tilstand. Dette kan nemt gøres som vist på skærmbilledet nedenfor:
Sikkerhedskopiering og gendannelse
ClusterControl har også en sikkerhedskopierings- og gendannelsesfunktion, der giver dig mulighed for at administrere din sikkerhedskopi, oprette en sikkerhedskopi, planlægge en sikkerhedskopiering og gendanne en sikkerhedskopi. Det er meget ligetil at administrere din sikkerhedskopi, og det er nemt at oprette eller planlægge en sikkerhedskopi, men tilbyder også avancerede muligheder. Det tilbyder også cloud backup muligheder, der giver dig mulighed for at have backup data redundans, hvilket styrker dine Disaster Recovery muligheder. Se nedenfor:
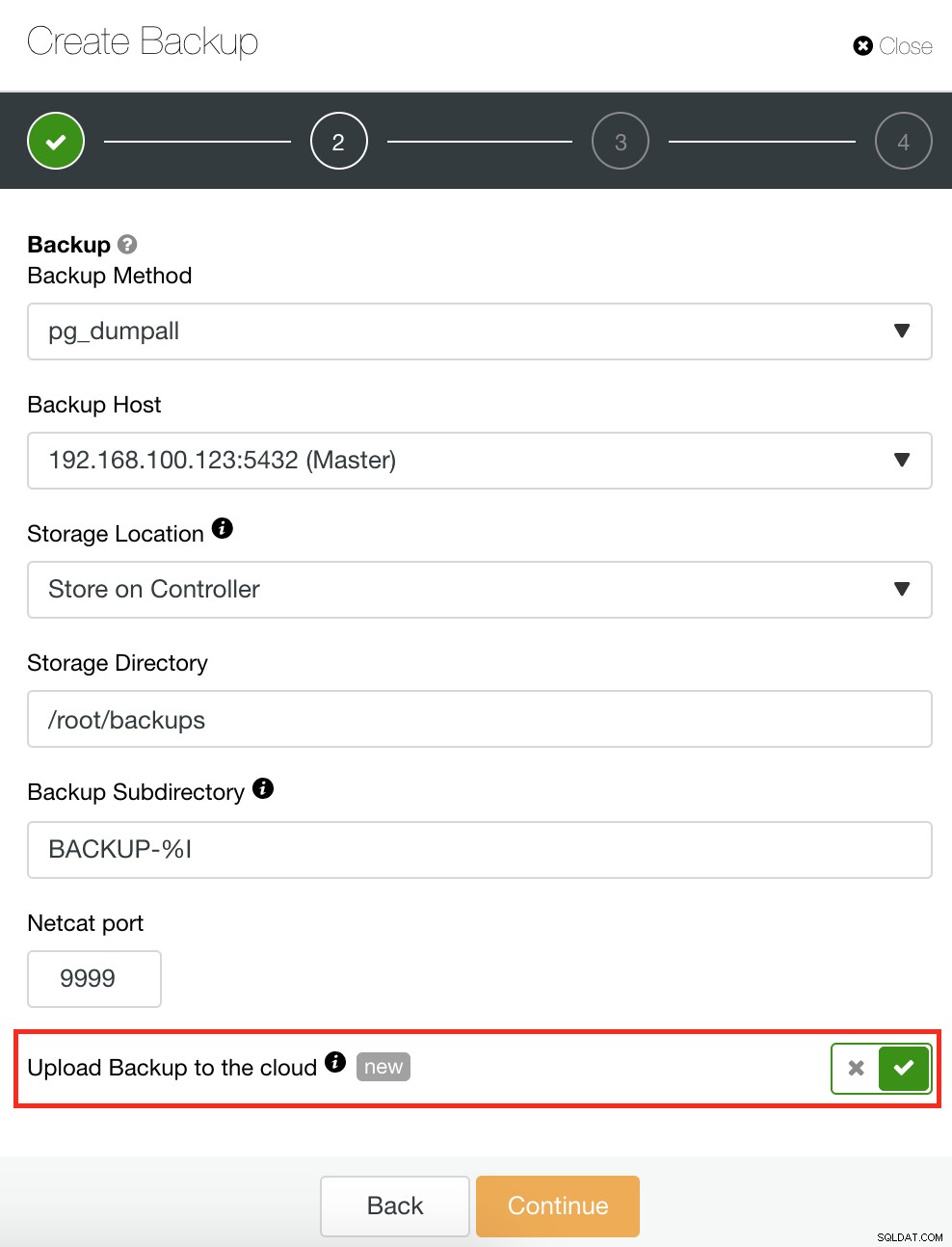
Som vist nedenfor giver administration af din sikkerhedskopi en enkel brugergrænseflade, hvor du kan vælge, hvilken sikkerhedskopi du vil gendanne, ellers bliver du måske nødt til at droppe. ClusterControl backup giver dig mulighed for at vælge en opbevaringsperiode, så hvis du har en lang liste, kan nogle af disse slettes, når den når sin opbevaringsperiode. 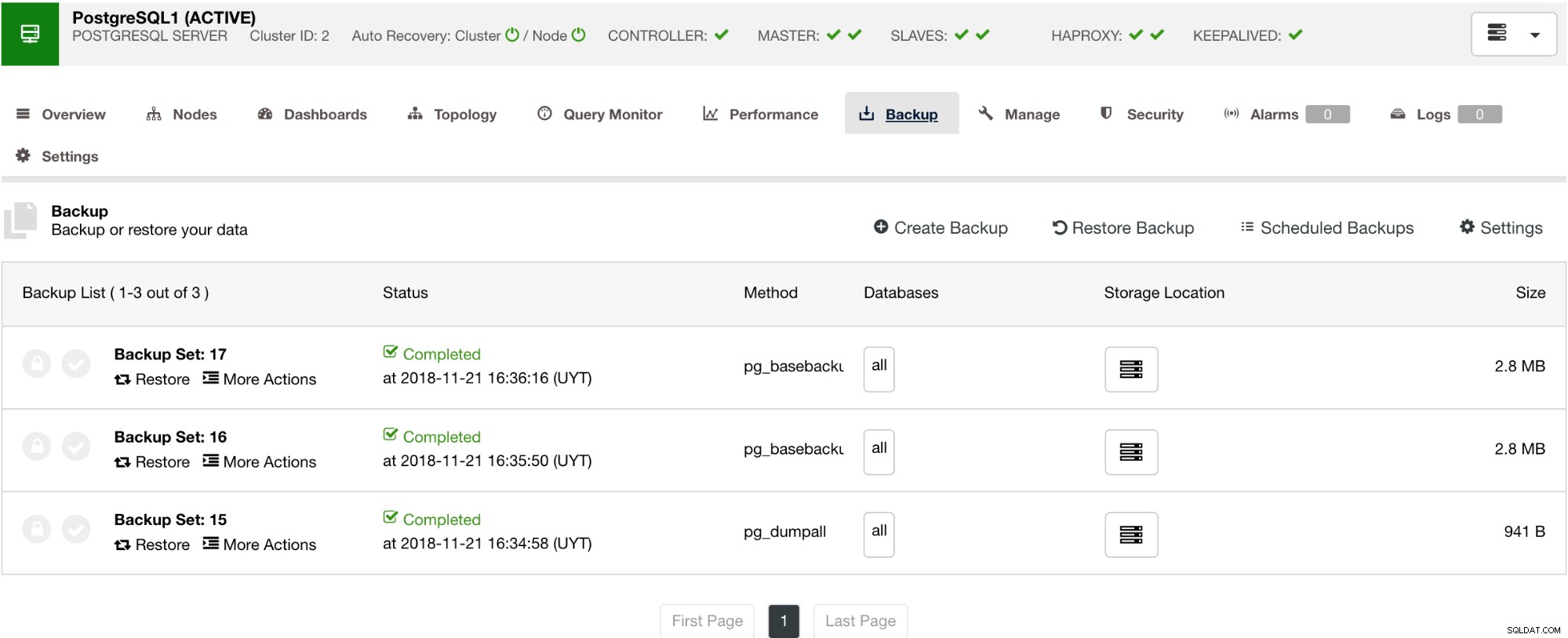
Understøtter mekanismer med høj tilgængelighed (HA) og belastningsbalancering (LB)
Du behøver ikke at konfigurere manuelt eller endda undersøge nogle måder at tilføje høj tilgængelighed i din PostgreSQL-klynge. Der er en nem og bekvem måde at få arbejdet gjort med ClusterControl. Hvis du kan se eksempelskærmbilledet, har det en HAProxy og Keepalved-opsætning. Se skærmbillede nedenfor:
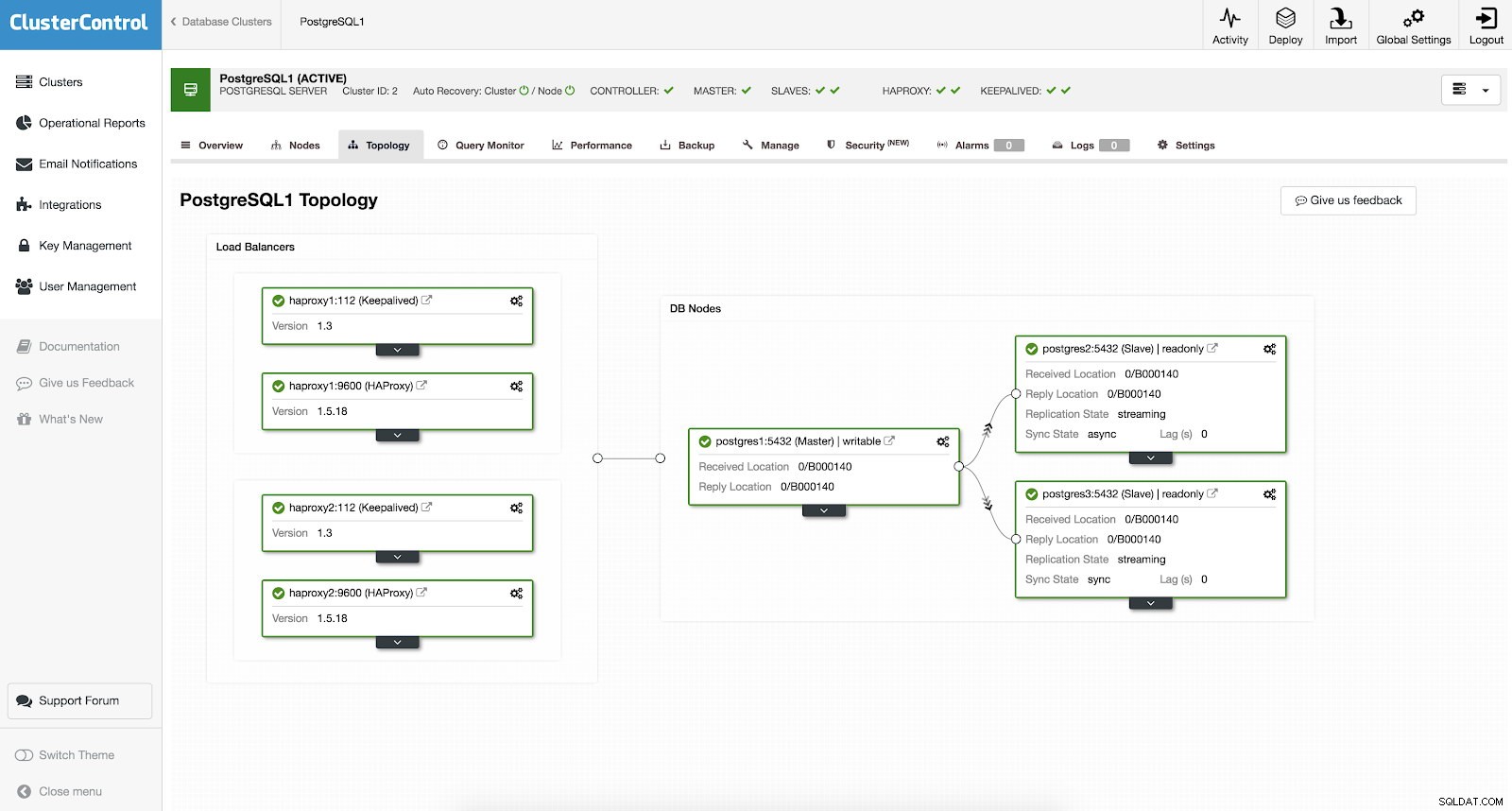
Opsætning af høj tilgængelighed med ClusterControl kan gøres ved at gå gennem
Understøtter distribueret miljø
Hvis du ønsker at fordele jævnt fra on-prem eller privat sky til offentlig sky, understøtter ClusterControl også cloud-implementering. Men for en PostgreSQL-klynge, og du planlægger at have en sekundær slave, der bor på en anden sky, kan du oprette en slaveklynge som vist nedenfor,
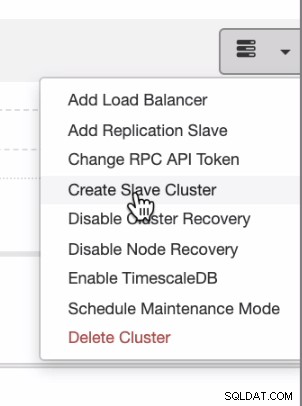
og du kan nå frem med slutresultatet som vist nedenfor,

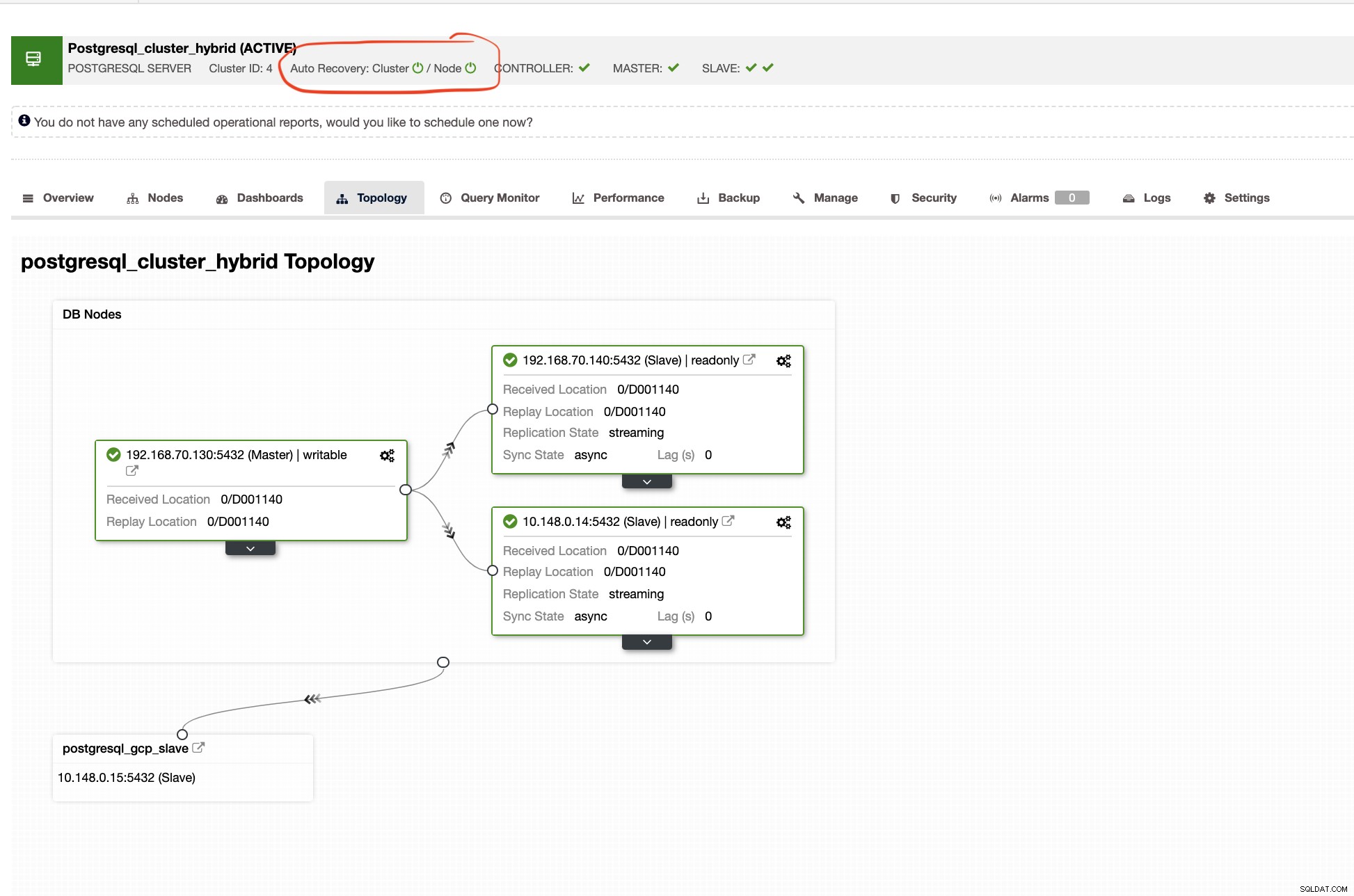
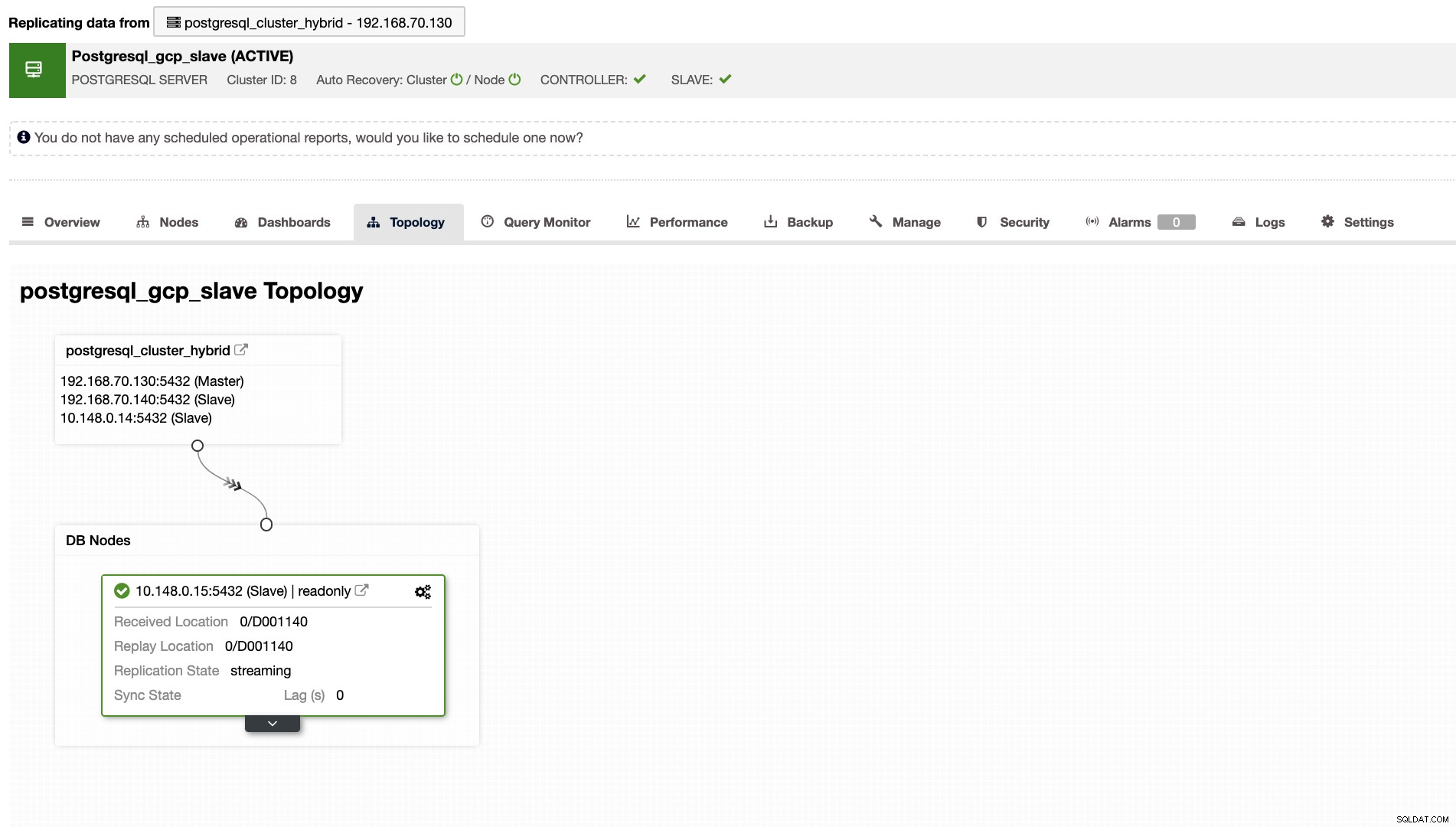
ClusterControl vil også vise dig den rigtige topologi for din klynge, når du har et hybridt cloudmiljø opsætning. Se følgende nedenfor,
I slaveklyngen vil topologien vise sit oprindelsestræ og afsløre sin herre. Slaven her vises, som den er placeret i et separat netværk, primært placeret i Google Cloud, mens masteren er lokalt.
Konklusion
Det er acceptabelt at indrømme, at en hybrid cloud-opsætning, især med PostgreSQL-klynge, tilføjer kompleksitet. Du skal have det rigtige værktøj med muligheder til stede for at understøtte din planlægning af genopretning efter katastrofe. Disse er meget vigtige for at redde og undgå din virksomhed fra den potentielle katastrofe med økonomisk skade og miste kundernes tillid. Invester i din teknologis rigtige værktøjer og færdigheder, og du vil redde din virksomhed fra negativ påvirkning.