Denne artikel ser nærmere på selektivitets- og kardinalitetsestimater for prædikater på COUNT(*) udtryk, som det kan ses i HAVING klausuler. Detaljerne er forhåbentlig interessante i sig selv. De giver også et indblik i nogle af de generelle tilgange og algoritmer, der bruges af kardinalitetsestimatoren.
Et simpelt eksempel ved hjælp af AdventureWorks-eksempeldatabasen:
SELECT A.City FROM Person.[Address] AS A GROUP BY A.City HAVING COUNT_BIG(*) = 1;
Vi er interesserede i at se, hvordan SQL Server udleder et estimat for prædikatet på tælleudtrykket i HAVING klausul.
Selvfølgelig HAVING klausul er bare syntaks sukker. Vi kunne lige så godt have skrevet forespørgslen ved hjælp af en afledt tabel eller almindeligt tabeludtryk:
-- Derived table
SELECT SQ1.City
FROM
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
) AS SQ1
WHERE SQ1.Expr1001 = 1;
-- CTE
WITH Grouped AS
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
)
SELECT G.City
FROM Grouped AS G
WHERE G.Expr1001 = 1; Alle tre forespørgselsformularer producerer den samme eksekveringsplan med identiske hashværdier for forespørgselsplanen.
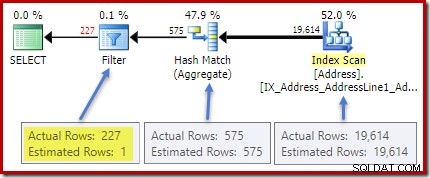
Planen efter udførelse (faktisk) viser et perfekt estimat for aggregatet; dog estimatet for HAVING klausulfilter (eller tilsvarende i de andre forespørgselsformer) er dårligt:
Statistik om City kolonne giver nøjagtige oplysninger om antallet af adskilte byværdier:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH DENSITY_VECTOR;
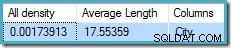
al densitet figuren er den gensidige af antallet af unikke værdier. Simpelthen beregner (1 / 0,00173913) =575 giver kardinalitetsestimatet for aggregatet. Gruppering efter by giver naturligvis én række for hver særskilt værdi.
Bemærk, at al tæthed kommer fra tæthedsvektoren. Pas på ikke at bruge densiteten ved et uheld værdi fra statistikheaderens output af DBCC SHOW_STATISTICS . Header-tætheden bibeholdes kun for bagudkompatibilitet; det bruges ikke af optimeringsværktøjet under estimering af kardinalitet i disse dage.
Problemet
Aggregatet introducerer en ny beregnet kolonne til arbejdsgangen, mærket Expr1001 i udførelsesplanen. Den indeholder værdien COUNT(*) i hver grupperet outputrække:
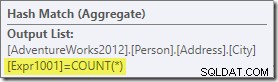
Der er åbenbart ingen statistisk information i databasen om denne nye beregnede kolonne. Selvom optimeringsværktøjet ved, at der vil være 575 rækker, ved det intet om fordelingen af tælleværdier i disse rækker.
Nå ikke helt ingenting:Optimizeren er klar over, at tælleværdierne vil være positive heltal (1, 2, 3...). Alligevel er det fordelingen af disse heltalsværdier blandt de 575 rækker, der ville være nødvendig for nøjagtigt at estimere selektiviteten af COUNT(*) = 1 prædikat.
Man kunne tro, at en form for distributionsinformation kunne udledes af histogrammet, men histogrammet giver kun specifik tælleinformation (i EQ_ROWS ) for histogramtrinværdier. Mellem histogramtrinene har vi kun en oversigt:RANGE_ROWS rækker har DISTINCT_RANGE_ROWS særskilte værdier. For tabeller, der er store nok til, at vi bekymrer os om kvaliteten af selektivitetsestimatet, er det meget sandsynligt, at det meste af tabellen er repræsenteret af disse intra-trin opsummeringer.
For eksempel de første to rækker i City kolonnehistogrammer er:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH HISTOGRAM;

Dette fortæller os, at der er præcis én række for "Abingdon", og 29 andre rækker efter "Abingdon", men før "Ballard", med 19 forskellige værdier i det 29-rækkers område. Følgende forespørgsel viser den faktiske fordeling af rækker blandt unikke værdier i det 29-rækkers intra-trin interval:
SELECT A.City, NumRows = COUNT_BIG(*) FROM Person.[Address] AS A WHERE A.City > N'Abingdon' AND A.City < N'Ballard' GROUP BY ROLLUP (A.City);

Der er 29 rækker med 19 forskellige værdier, ligesom histogrammet sagde. Alligevel er det klart, at vi ikke har noget grundlag for at evaluere selektiviteten af et prædikat på tællekolonnen i den forespørgsel. For eksempel, HAVING COUNT_BIG(*) = 2 ville returnere 5 rækker (for Alexandria, Altadena, Atlanta, Augsburg og Austin), men vi har ingen måde at bestemme det ud fra histogrammet.
Et kvalificeret gæt
Den tilgang, SQL Server tager, er at antage, at hver gruppe er mest sandsynlig at indeholde det samlede gennemsnitlige (gennemsnitlige) antal rækker. Dette er simpelthen kardinaliteten divideret med antallet af unikke værdier. For eksempel, for 1000 rækker med 20 unikke værdier, vil SQL Server antage, at (1000 / 20) =50 rækker pr. gruppe er den mest sandsynlige værdi.
Hvis vi vender tilbage til vores oprindelige eksempel, betyder det, at kolonnen med det beregnede antal "mest sandsynligt" indeholder en værdi omkring (19614 / 575) ~=34.1113 . Siden density er den gensidige af antallet af unikke værdier, kan vi også udtrykke det som kardinalitet * tæthed =(19614 * 0,00173913), hvilket giver et meget lignende resultat.
Distribution
At sige, at middelværdien højst sandsynligt er, tager os kun så langt. Vi skal også fastslå, præcis hvor sandsynligt det er; og hvordan sandsynligheden ændrer sig, når vi bevæger os væk fra middelværdien. At antage, at alle grupper har præcis 34.113 rækker i vores eksempel, ville ikke være et meget "uddannet" gæt!
SQL Server håndterer dette ved at antage en normalfordeling. Dette har den karakteristiske klokkeform, som du måske allerede er bekendt med (billede fra den linkede Wikipedia-indgang):
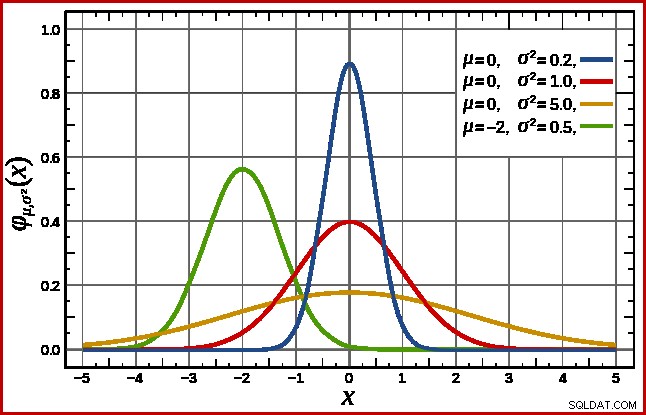
Den nøjagtige form af normalfordelingen afhænger af to parametre :middelværdien (µ ) og standardafvigelsen (σ ). Middelværdien bestemmer toppens placering. Standardafvigelsen angiver, hvor "fladet" klokkekurven er. Jo fladere kurven er, jo lavere er toppen, og jo mere er sandsynlighedstætheden fordelt over andre værdier.
SQL Server kan udlede middelværdien fra statistisk information som allerede nævnt. Standardafvigelsen af de beregnede tællekolonneværdier er ukendt. SQL Server estimerer det som kvadratroden af middelværdien (med en lille justering detaljeret senere). I vores eksempel betyder det, at de to parametre for normalfordelingen groft er 34,1113 og 5,84 (kvadratroden).
standarden normalfordeling (den røde kurve i diagrammet ovenfor) er et bemærkelsesværdigt specialtilfælde. Dette sker, når middelværdien er nul, og standardafvigelsen er 1. Enhver normalfordeling kan transformeres til standardnormalfordelingen ved at trække middelværdien fra og dividere med standardafvigelsen.
Områder og intervaller
Vi er interesserede i at estimere selektivitet, så vi leder efter sandsynligheden for, at den tælleberegnede kolonne har en bestemt værdi (x). Denne sandsynlighed er ikke givet af y-akseværdien ovenfor, men af arealet under kurven til venstre for x.
For normalfordelingen med middelværdi 34,1113 og standardafvigelse 5,84 er arealet under kurven til venstre for x =30 omkring 0,2406:
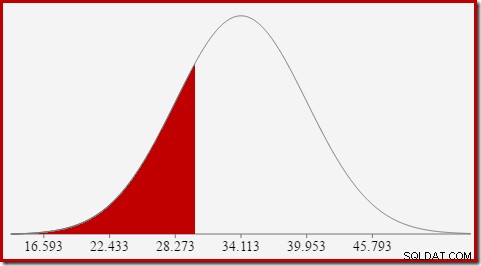
Dette svarer til sandsynligheden for, at kolonnen for beregnet antal er mindre end eller lig med 30 for vores eksempelforespørgsel.
Dette leder fint videre til ideen om, at vi generelt ikke leder efter sandsynligheden for en bestemt værdi, men efter et interval . For at finde det sandsynligvis, at antallet lig med en heltalsværdi, skal vi tage højde for det faktum, at heltal spænder over et interval på størrelse 1. Hvordan vi konverterer et heltal til et interval er noget vilkårligt. SQL Server håndterer dette ved at tilføje og trække 0.5 fra for at give den nedre og øvre grænse for intervallet.
For at finde sandsynligheden for, at den beregnede tælleværdi er lig med 30, skal vi for eksempel fratrække arealet under normalfordelingskurven for (x =29,5) fra arealet for (x =30,5). Resultatet svarer til udsnittet for (29,5
Arealet af den røde skive er omkring 0,0533 . Til en god første tilnærmelse er dette selektiviteten af et count =30 prædikat i vores testforespørgsel.
At beregne arealet under en normalfordeling til venstre for en given værdi er ikke ligetil. Den generelle formel er givet af den kumulative fordelingsfunktion (CDF). Problemet er, at CDF ikke kan udtrykkes i form af elementære matematiske funktioner, så numeriske tilnærmelsesmetoder skal bruges i stedet.
Da alle normalfordelinger let kan transformeres til standardnormalfordelingen (middel =0, standardafvigelse =1), virker tilnærmelserne alle til at estimere standardnormalen. Det betyder, at vi er nødt til at transformere vores intervalgrænser fra den særlige normalfordeling, der passer til forespørgslen, til standardnormalfordelingen. Dette gøres, som tidligere nævnt, ved at trække middelværdien fra og dividere med standardafvigelsen.
Hvis du er fortrolig med Excel, er du måske opmærksom på funktionerne NORM.DIST og NORM.S.DIST, som kan beregne CDF'er (ved hjælp af numeriske tilnærmelsesmetoder) for en bestemt normalfordeling eller standardnormalfordelingen.
Der er ingen CDF-beregner indbygget i SQL Server, men vi kan sagtens lave en. Givet at CDF for standard normalfordelingen er:
…hvor erf er fejlfunktionen:
En T-SQL-implementering for at opnå CDF'en for standard normalfordelingen er vist nedenfor. Den bruger en numerisk tilnærmelse til fejlfunktionen der er meget tæt på den, SQL Server bruger internt:
Et eksempel, for at beregne CDF for x =30 ved hjælp af normalfordelingen for vores testforespørgsel:
Bemærk normaliseringstrinnet for at konvertere til standardnormalfordelingen. Proceduren returnerer værdien 0,2407196…, som matcher det tilsvarende Excel-resultat med syv decimaler.
Følgende kode ændrer vores eksempelforespørgsel til at producere et større estimat for filteret (sammenligningen er nu med værdien 32, som er meget tættere på middelværdien end før):
Estimatet fra optimeringsværktøjet er nu 36.7807 .
For at beregne estimatet manuelt skal vi først behandle nogle få sidste detaljer:
Den følgende procedure inkorporerer alle detaljerne i denne artikel. Det kræver CDF-proceduren givet tidligere:
Vi kan nu bruge denne procedure til at generere et estimat for vores nye testforespørgsel:
Outputtet er:
Dette kan sammenlignes meget godt med optimeringsværktøjets kardinalitetsestimat på 36.7807.
Proceduren kan bruges til andre tælleintervaller bortset fra lighedstest. Det eneste, der kræves, er at indstille
For at bruge dette med vores procedure, sætter vi
Resultatet er 572.5964:
Et sidste eksempel med
Optimeringsestimatet er
Siden
Igen stemmer dette overens med optimeringsestimatet.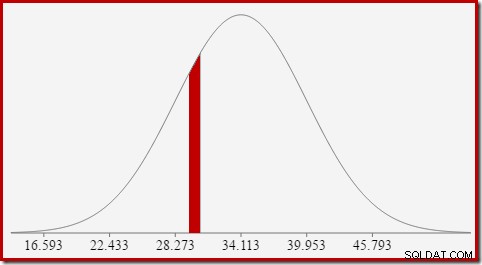
Den kumulative distributionsfunktion
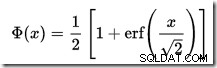
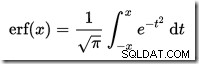
CREATE PROCEDURE dbo.GetStandardNormalCDF
(
@x float,
@cdf float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE
@sign float,
@erf float;
SET @sign = SIGN(@x);
SET @x = ABS(@x) / SQRT(2);
SET @erf = 1;
SET @erf = @erf + (0.0705230784 * @x);
SET @erf = @erf + (0.0422820123 * POWER(@x, 2));
SET @erf = @erf + (0.0092705272 * POWER(@x, 3));
SET @erf = @erf + (0.0001520143 * POWER(@x, 4));
SET @erf = @erf + (0.0002765672 * POWER(@x, 5));
SET @erf = @erf + (0.0000430638 * POWER(@x, 6));
SET @erf = POWER(@erf, -16);
SET @erf = 1 - @erf;
SET @erf = @erf * @sign;
SET @cdf = 0.5 * (1 + @erf);
END; DECLARE @cdf float;
DECLARE @x float;
-- HAVING COUNT_BIG(*) = x
SET @x = 30;
-- Normalize 30 by subtracting the mean
-- and dividing by the standard deviation
SET @x = (@x - 34.1113) / 5.84;
EXECUTE dbo.GetStandardNormalCDF
@x = @x,
@cdf = @cdf OUTPUT;
SELECT CDF = @cdf; Sidste detaljer og eksempler
SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) = 32;
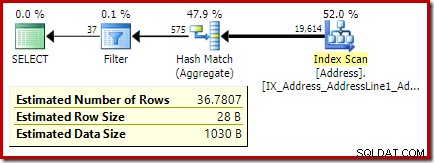
COUNT(*) = 1 , som ikke er detaljeret her. COUNT(*) = 1 tilfælde, bruger den ældre CE den samme logik som den nye CE (tilgængelig i SQL Server 2014 og fremefter).CREATE PROCEDURE dbo.GetCountPredicateEstimate
(
@From integer,
@To integer,
@Cardinality float,
@Density float,
@Selectivity float OUTPUT,
@Estimate float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
DECLARE
@Start float,
@End float,
@Distinct float,
@Mean float,
@MeanAdj float,
@Stdev float,
@NormStart float,
@NormEnd float,
@CDFStart float,
@CDFEnd float;
-- Validate input and apply defaults
IF ISNULL(@From, 0) = 0 SET @From = 1;
IF @From < 1 RAISERROR ('@From must be >= 1', 16, 1);
IF ISNULL(@Cardinality, -1) <= 0 RAISERROR('@Cardinality must be positive', 16, 1);
IF ISNULL(@Density, -1) <= 0 RAISERROR('@Density must be positive', 16, 1);
IF ISNULL(@To, 0) = 0 SET @To = CEILING(1 / @Density);
IF @To < @From RAISERROR('@To must be >= @From', 16, 1);
-- Convert integer range to interval
SET @Start = @From - 0.5;
SET @End = @To + 0.5;
-- Get number of distinct values
SET @Distinct = 1 / @Density;
-- Calculate mean
SET @Mean = @Cardinality * @Density;
-- Adjust mean;
SET @MeanAdj = @Mean * ((@Distinct - 1) / @Distinct);
-- Get standard deviation (guess)
SET @Stdev = SQRT(@MeanAdj);
-- Normalize interval
SET @NormStart = (@Start - @Mean) / @Stdev;
SET @NormEnd = (@End - @Mean) / @Stdev;
-- Calculate CDFs
EXECUTE dbo.GetStandardNormalCDF
@x = @NormStart,
@cdf = @CDFStart OUTPUT;
EXECUTE dbo.GetStandardNormalCDF
@x = @NormEnd,
@cdf = @CDFEnd OUTPUT;
-- Selectivity
SET @Selectivity =
CASE
-- Unbounded start
WHEN @From = 1 THEN @CDFEnd
-- Unbounded end
WHEN @To >= @Distinct THEN 1 - @CDFStart
-- Normal interval
ELSE @CDFEnd - @CDFStart
END;
-- Return row estimate
SET @Estimate = @Selectivity * @Distinct;
END TRY
BEGIN CATCH
DECLARE @EM nvarchar(4000) = ERROR_MESSAGE();
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION;
RAISERROR (@EM, 16, 1);
RETURN;
END CATCH;
END; DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = 32,
@To = 32,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
Eksempler på ulighedsinterval
@From og @To parametre til heltalsintervalgrænserne. For at angive ubegrænset skal du indtaste nul eller NULL som du foretrækker.SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) < 50;

@From = NULL og @To = 49 (fordi 50 er udelukket med mindre end):DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = NULL,
@To = 49,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
BETWEEN :SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) BETWEEN 25 AND 30;

BETWEEN er inklusive, passerer vi proceduren @From = 25 og @To = 30 . Resultatet er: