Hvis du bruger tabelpartitionering med en eller flere partitioner, der er gemt i en skrivebeskyttet filgruppe, kan SQL-opdaterings- og sletsætninger mislykkes med en fejl. Selvfølgelig er dette den forventede adfærd, hvis nogen af ændringerne ville kræve skrivning til en skrivebeskyttet filgruppe; det er dog også muligt at støde på denne fejltilstand, hvor ændringerne er begrænset til filgrupper markeret som læs-skriv.
Eksempeldatabase
For at demonstrere problemet vil vi oprette en simpel database med en enkelt brugerdefineret filgruppe, som vi senere vil markere som værende skrivebeskyttet. Bemærk, at du skal tilføje filnavnstien, så den passer til din testinstans.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Partitionsfunktion og skema
Vi vil nu oprette en grundlæggende partitioneringsfunktion og -skema, der vil dirigere rækker med data inden 1. januar 2000 til den skrivebeskyttede partition. Senere data vil blive opbevaret i læse-skrive primære filgruppe:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); Range right-specifikationen betyder, at rækker med grænseværdien 1. januar 2000 vil være i læse-skrive-partitionen.
Partitioneret tabel og indekser
Vi kan nu oprette vores testtabel:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); Tabellen har en klynget primærnøgle i datetime-kolonnen og er også opdelt i denne kolonne. Der er ikke-klyngede indekser på de to andre heltalskolonner, som er opdelt på samme måde (indeksene er justeret med basistabellen).
Eksempel på data
Til sidst tilføjer vi et par rækker med eksempeldata og gør datapartitionen før 2000 skrivebeskyttet:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Du kan bruge følgende testopdateringssætninger til at bekræfte, at data i den skrivebeskyttede partition ikke kan ændres, mens data med en dt værdi den 1. januar 2000 eller senere kan skrives til:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; En uventet fejl
Vi har to rækker:en skrivebeskyttet (1999-12-31); og én læse-skrive (2000-01-01):

Prøv nu følgende forespørgsel. Den identificerer den samme skrivbare "2000-01-01" række, som vi lige har opdateret, men bruger et andet where-sætningsprædikat:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Den estimerede (førudførelse) plan er:

De fire (!) Compute Scalars er ikke vigtige for denne diskussion. De bruges til at bestemme, om det ikke-klyngede indeks skal vedligeholdes for hver række, der ankommer til operatøren Clustered Index Update.
Det mere interessante er, at denne opdateringserklæring mislykkes med en fejl svarende til:
Msg 652, Level 16, State 1Indekset "PK_dbo_Test__c1_dt" for tabellen "dbo.Test" (RowsetId 72057594039042048) ligger i en skrivebeskyttet filgruppe ("ReadOnlyFileGroup"), som ikke kan ændres.
Ikke partitionseliminering
Hvis du har arbejdet med partitionering før, tænker du måske, at 'partitioneliminering' kan være årsagen. Logikken ville se sådan ud:
I de tidligere udsagn blev der angivet en bogstavelig værdi for partitioneringskolonnen i where-sætningen, så SQL Server ville være i stand til med det samme at bestemme hvilken(e) partition(er) der skulle tilgås. Ved at ændre where-sætningen, så den ikke længere refererer til partitioneringskolonnen, har vi tvunget SQL Server til at få adgang til hver partition ved hjælp af en Clustered Index Scan.
Det er alt sammen sandt, generelt, men det er ikke grunden til, at opdateringserklæringen fejler her.
Den forventede adfærd er, at SQL Server skal være i stand til at læse fra enhver og alle partitioner under udførelse af forespørgsler. En dataændringshandling bør kun mislykkes hvis udførelsesmotoren faktisk forsøger at ændre en række gemt i en skrivebeskyttet filgruppe.
For at illustrere det, lad os lave en lille ændring til den forrige forespørgsel:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; Hvor-klausulen er nøjagtig den samme som før. Den eneste forskel er, at vi nu (bevidst) sætter partitioneringskolonnen lig med sig selv. Dette vil ikke ændre værdien, der er gemt i den kolonne, men det påvirker resultatet. Opdateringen lykkes nu (omend med en mere kompleks udførelsesplan):

Optimeringsværktøjet har introduceret nye Split-, Sort- og Collapse-operatorer og tilføjet det nødvendige maskineri til at vedligeholde hvert potentielt berørt ikke-klyngede indeks separat (ved hjælp af en bred- eller pr-indeks-strategi).
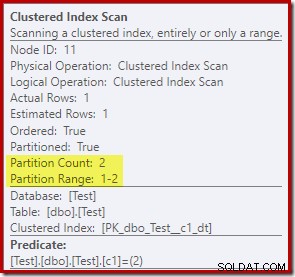
Egenskaberne for Clustered Index Scan viser, at begge partitioner af tabellen blev tilgået ved læsning:
I modsætning hertil viser Clustered Index Update, at kun læse-skrive-partitionen blev tilgået til skrivning:
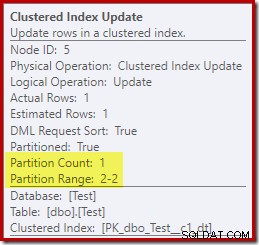
Hver af de ikke-klyngede indeksopdateringsoperatører viser lignende oplysninger:kun den skrivbare partition (#2) blev ændret under kørsel, så der opstod ingen fejl.
Årsagen afsløret
Den nye plan lykkes ikke fordi de ikke-klyngede indekser vedligeholdes separat; eller er det (direkte) på grund af Split-Sort-Collapse-kombinationen, der er nødvendig for at undgå forbigående duplikatnøglefejl i det unikke indeks.
Den egentlige årsag er noget, jeg kort nævnte i min tidligere artikel, "Optimering af opdateringsforespørgsler" - en intern optimering kendt som Rowset Sharing . Når dette bruges, deler Clustered Index Update det samme underliggende storage engine-rækkesæt som en Clustered Index Scan, Seek eller Key Lookup på læsesiden af planen.
Med Rowset Sharing-optimeringen søger SQL Server efter offline eller skrivebeskyttede filgrupper ved læsning. I planer, hvor Clustered Index Update bruger et separat rækkesæt, udføres offline/skrivebeskyttet kontrol kun for hver række ved opdatering (eller slet) iterator.
Udokumenterede løsninger
Lad os først få de sjove, nørdede, men upraktiske ting af vejen.
Optimeringen af delt rækkesæt kan kun anvendes, når ruten fra den klyngede indekssøgning, scanning eller nøgleopslag er en pipeline . Ingen blokerende eller semi-blokerende operatører er tilladt. Sagt på en anden måde skal hver række kunne komme fra læsekilde til skrivedestination, før den næste række læses.
Som en påmindelse er her eksempeldata, erklæring og udførelsesplan for den mislykkede opdater igen:
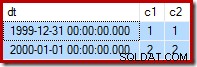
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Halloween-beskyttelse
En måde at introducere en blokerende operatør på planen er at kræve eksplicit Halloween Protection (HP) til denne opdatering. Adskillelse af læsning fra skrivning med en blokerende operatør vil forhindre rækkesætdelingsoptimering i at blive brugt (ingen pipeline). Udokumenteret og ikke-understøttet (kun testsystem!) sporingsflag 8692 tilføjer en Eager Table Spool til eksplicit HP:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Den faktiske udførelsesplan (tilgængelig, fordi fejlen ikke længere er kastet) er:

Kombinationen Sorter i Split-Sort-Skjul sammen, som blev set i den tidligere vellykkede opdatering, giver den nødvendige blokering for at deaktivere rækkesætdeling i dette tilfælde.
Anti-Rowset Sharing Trace Flag
Der er et andet udokumenteret sporingsflag, der deaktiverer optimering af rækkesætdeling. Dette har den fordel, at det ikke introducerer en potentielt dyr blokeringsoperatør. Det kan selvfølgelig ikke bruges i praksis (medmindre du kontakter Microsoft Support og får noget skriftligt, der anbefaler dig at aktivere det, formoder jeg). Ikke desto mindre, til underholdningsformål, er her sporflag 8746 i aktion:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Den faktiske udførelsesplan for den erklæring er:

Du er velkommen til at eksperimentere med forskellige værdier (dem, der faktisk ændrer de lagrede værdier, hvis du vil) for at overbevise dig selv om forskellen her. Som nævnt i mit tidligere indlæg, kan du også bruge udokumenteret sporingsflag 8666 til at afsløre egenskaben for rækkesætdeling i udførelsesplanen.
Hvis du vil se rækkesætdelingsfejlen med en delete-sætning, skal du blot erstatte opdateringen og sæt-klausulerne med en delete, mens du bruger den samme where-klausul.
Understøttede løsninger
Der er en række potentielle måder at sikre, at rækkesætdeling ikke anvendes i forespørgsler i den virkelige verden uden brug af sporingsflag. Nu hvor du ved, at kerneproblemet kræver en delt og pipelinet klynget indekslæse- og skriveplan, kan du sikkert komme med din egen. Alligevel er der et par eksempler, som er særligt værd at se på her.
Tvungen indeks / dækkende indeks
En naturlig idé er at tvinge læsesiden af planen til at bruge et ikke-klynget indeks i stedet for det klyngede indeks. Vi kan ikke tilføje et indekstip direkte til testforespørgslen som skrevet, men aliasing af tabellen tillader dette:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Dette kan virke som den løsning, forespørgselsoptimeringsværktøjet skulle have valgt i første omgang, da vi har et ikke-klynget indeks på where-sætningsprædikatet kolonne c1. Udførelsesplanen viser, hvorfor optimeringsværktøjet valgte, som det gjorde:
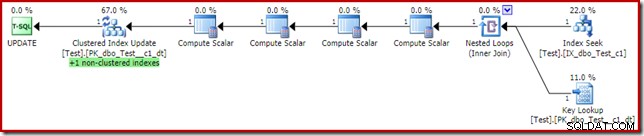
Omkostningerne ved nøgleopslaget er nok til at overbevise optimeringsværktøjet om at bruge det klyngede indeks til læsning. Opslaget er nødvendigt for at hente den aktuelle værdi af kolonne c2, så Compute Scalars kan beslutte, om det ikke-klyngede indeks skal vedligeholdes.
Tilføjelse af kolonne c2 til det ikke-klyngede indeks (nøgle eller inkludere) ville undgå problemet. Optimeringsværktøjet ville vælge det nu-dækkende indeks i stedet for det klyngede indeks.
Når det er sagt, er det ikke altid muligt at forudse, hvilke kolonner der skal bruges, eller at inkludere dem alle, selvom sættet er kendt. Husk, at kolonnen er nødvendig, fordi c2 er i set-sætningen af opdateringserklæringen. Hvis forespørgslerne er ad hoc (f.eks. indsendt af brugere eller genereret af et værktøj), skal hvert ikke-klyngede indeks inkludere alle kolonner for at gøre dette til en robust mulighed.
En interessant ting ved planen med nøgleopslaget ovenfor er, at den ikke gør det generere en fejl. Dette er på trods af Key Lookup og Clustered Index Update ved hjælp af et delt rækkesæt. Årsagen er, at den ikke-klyngede Index Seek lokaliserer rækken med c1 =2 før Nøgleopslag berører det klyngede indeks. Den delte rækkesæt-kontrol for offline/skrivebeskyttede filgrupper udføres stadig ved opslag, men den berører ikke den skrivebeskyttede partition, så der opstår ingen fejl. Som et sidste (relateret) interessepunkt skal du bemærke, at indekssøgningen berører begge partitioner, men nøgleopslaget rammer kun én.
Ekskluderer den skrivebeskyttede partition
En triviel løsning er at stole på partitioneliminering, så læsesiden af planen aldrig rører den skrivebeskyttede partition. Dette kan gøres med et eksplicit prædikat, for eksempel en af disse:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Hvor det er umuligt eller ubelejligt at ændre hver forespørgsel for at tilføje et partitionselimineringsprædikat, kan andre løsninger som opdatering gennem en visning være egnede. For eksempel:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; En ulempe ved at bruge en visning er, at en opdatering eller sletning, der retter sig mod den skrivebeskyttede del af basistabellen, vil lykkes uden berørte rækker, i stedet for at fejle med en fejl. En i stedet for trigger på bordet eller visningen kan være en løsning på det i nogle situationer, men kan også introducere flere problemer...men jeg afviger.
Som tidligere nævnt er der mange potentielle understøttede løsninger. Pointen med denne artikel er at vise, hvordan deling af rækkesæt forårsagede den uventede opdateringsfejl.