I del 2 af denne serie tilføjede du muligheden for at gemme ændringer foretaget gennem REST API til en database ved hjælp af SQLAlchemy og lærte, hvordan du serialiserer disse data til REST API ved hjælp af Marshmallow. At forbinde REST API til en database, så applikationen kan foretage ændringer i eksisterende data og skabe nye data, er fantastisk og gør applikationen meget mere nyttig og robust.
Det er dog kun en del af den kraft, en database tilbyder. En endnu mere kraftfuld funktion er R del af RDBMS systemer:relationer . I en database er en relation evnen til at forbinde to eller flere tabeller sammen på en meningsfuld måde. I denne artikel lærer du, hvordan du implementerer relationer og forvandler din Person database til en mini-blogging-webapplikation.
I denne artikel lærer du:
- Hvorfor er mere end én tabel i en database nyttig og vigtig
- Hvordan tabeller er relateret til hinanden
- Hvordan SQLAlchemy kan hjælpe dig med at administrere relationer
- Hvordan relationer hjælper dig med at bygge en mini-blogapplikation
Hvem er denne artikel til
Del 1 af denne serie guidede dig gennem opbygningen af en REST API, og del 2 viste dig, hvordan du forbinder denne REST API til en database.
Denne artikel udvider dit programmeringsværktøjsbælte yderligere. Du lærer, hvordan du opretter hierarkiske datastrukturer repræsenteret som en-til-mange-relationer af SQLAlchemy. Derudover vil du udvide den REST API, du allerede har bygget, for at give CRUD-understøttelse (Create, Read, Update and Delete) til elementerne i denne hierarkiske struktur.
Webapplikationen, der præsenteres i del 2, vil få sine HTML- og JavaScript-filer ændret på vigtige måder for at skabe en mere fuldt funktionel mini-blogapplikation. Du kan gennemgå den endelige version af koden fra del 2 i GitHub-lageret for den pågældende artikel.
Hold ud, mens du kommer i gang med at skabe relationer og din mini-blogapplikation!
Yderligere afhængigheder
Der er ingen nye Python-afhængigheder ud over, hvad der var påkrævet for del 2-artiklen. Du vil dog bruge to nye JavaScript-moduler i webapplikationen for at gøre tingene nemmere og mere konsekvente. De to moduler er følgende:
- Handlebars.js er en skabelonmotor til JavaScript, ligesom Jinja2 til Flask.
- Moment.js er et datetime-parsing- og formateringsmodul, der gør visning af UTC-tidsstempler lettere.
Du behøver ikke at downloade nogen af disse, da webapplikationen får dem direkte fra Cloudflare CDN (Content Delivery Network), som du allerede gør for jQuery-modulet.
Persondata udvidet til blogging
I del 2, People data eksisterede som en ordbog i build_database.py Python kode. Dette er, hvad du brugte til at udfylde databasen med nogle indledende data. Du vil ændre People datastruktur for at give hver person en liste over noter forbundet med dem. De nye People datastrukturen vil se sådan ud:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Hver person i People ordbogen indeholder nu en nøgle kaldet notes , som er knyttet til en liste, der indeholder tuples af data. Hver tuple i notes listen repræsenterer en enkelt note indeholdende indholdet og et tidsstempel. Tidsstemplerne initialiseres (i stedet for dynamisk oprettet) for at demonstrere bestilling senere i REST API.
Hver enkelt person er forbundet med flere noter, og hver enkelt note er forbundet med kun én person. Dette hierarki af data er kendt som en en-til-mange-relation, hvor et enkelt overordnet objekt er relateret til mange underordnede objekter. Du vil se, hvordan dette en-til-mange forhold administreres i databasen med SQLAlchemy.
Brute Force-tilgang
Den database, du byggede, gemte dataene i en tabel, og en tabel er en todimensionel række af rækker og kolonner. Kan People ordbogen ovenfor være repræsenteret i en enkelt tabel med rækker og kolonner? Det kan være på følgende måde i din person database tabel. Desværre, at inkludere alle de faktiske data i eksemplet skaber en rullepanel for tabellen, som du vil se nedenfor:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Fedt, et mini-blogprogram! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Dette kunne være nyttigt | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Nå, noget nyttigt | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Jeg vil gøre virkelig dybtgående observationer | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Måske bliver de mere tydelige, end jeg troede | 2019-02-06 22:17:54 |
| 6 | Påske | Kanin | 2018-08-08 21:16:01 | Har nogen set mine påskeæg? | 2019-01-07 22:47:54 |
| 7 | Påske | Kanin | 2018-08-08 21:16:01 | Jeg er virkelig forsinket med at levere disse! | 2019-04-06 22:17:54 |
Ovenstående tabel ville faktisk fungere. Alle data er repræsenteret, og en enkelt person er knyttet til en samling af forskellige noter.
Fordele
Konceptuelt har ovenstående tabelstruktur den fordel, at den er forholdsvis enkel at forstå. Du kan endda gøre det tilfældet, at dataene kunne bevares til en flad fil i stedet for en database.
På grund af den todimensionelle tabelstruktur kan du gemme og bruge disse data i et regneark. Regneark er blevet presset i brug som datalagring en del.
Ulempe
Selvom ovenstående tabelstruktur ville fungere, har den nogle reelle ulemper.
For at repræsentere samlingen af noter gentages alle data for hver person for hver unik note, persondataene er derfor overflødige. Dette er ikke så stort for dine persondata, da der ikke er så mange kolonner. Men tænk, hvis en person havde mange flere kolonner. Selv med store diskdrev kan dette blive et problem med lagring, hvis du har at gøre med millioner af rækker af data.
At have overflødige data som denne kan føre til vedligeholdelsesproblemer som tiden går. For eksempel, hvad nu hvis påskeharen besluttede at et navneskifte var en god idé. For at gøre dette skal hver post, der indeholder påskeharens navn, opdateres for at holde dataene konsistente. Denne form for arbejde mod databasen kan føre til datainkonsistens, især hvis arbejdet udføres af en person, der kører en SQL-forespørgsel i hånden.
Navngivning af kolonner bliver akavet. I tabellen ovenfor er der et timestamp kolonne bruges til at spore oprettelses- og opdateringstidspunktet for en person i tabellen. Du vil også have lignende funktionalitet til oprettelse og opdateringstid for en note, men fordi timestamp er allerede brugt, et konstrueret navn note_timestamp bruges.
Hvad hvis du ville tilføje yderligere en-til-mange-relationer til person bord? For eksempel at inkludere en persons børn eller telefonnumre. Hver person kunne have flere børn og flere telefonnumre. Dette kunne gøres relativt nemt for Python People ordbogen ovenfor ved at tilføje children og phone_numbers nøgler med nye lister, der indeholder dataene.
Dog repræsenterer de nye en-til-mange-forhold i din person databasetabellen ovenfor bliver væsentligt vanskeligere. Hver ny en-til-mange-relation øger antallet af rækker, der er nødvendige for at repræsentere det for hver enkelt indtastning i de underordnede data dramatisk. Derudover bliver problemerne forbundet med dataredundans større og sværere at håndtere.
Endelig ville de data, du ville få tilbage fra ovenstående tabelstruktur, ikke være særlig pytoniske:det ville bare være en stor liste over lister. SQLAlchemy ville ikke være i stand til at hjælpe dig særlig meget, fordi forholdet ikke er der.
Relationel databasetilgang
Baseret på det, du har set ovenfor, bliver det klart, at forsøg på at repræsentere selv et moderat komplekst datasæt i en enkelt tabel bliver uoverskuelig ret hurtigt. Givet det, hvilket alternativ tilbyder en database? Det er her R del af RDBMS databaser kommer i spil. At repræsentere relationer fjerner de ulemper, der er skitseret ovenfor.
I stedet for at forsøge at repræsentere hierarkiske data i en enkelt tabel, er dataene opdelt i flere tabeller med en mekanisme til at relatere dem til hinanden. Tabellerne er opdelt langs indsamlingslinjer, så for dine People ordbogen ovenfor, betyder det, at der vil være en tabel, der repræsenterer personer, og en anden, der repræsenterer noter. Dette bringer din oprindelige person tilbage tabel, som ser sådan ud:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Påske | Kanin | 2018-08-08 21:16:01.886834 |
For at repræsentere de nye noteoplysninger skal du oprette en ny tabel kaldet note . (Husk vores enkeltstående tabelnavnekonvention.) Tabellen ser således ud:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Fedt, et mini-blogprogram! | 2019-01-06 22:17:54 |
| 2 | 1 | Dette kunne være nyttigt | 2019-01-08 22:17:54 |
| 3 | 1 | Nå, noget nyttigt | 2019-03-06 22:17:54 |
| 4 | 2 | Jeg vil gøre virkelig dybtgående observationer | 2019-01-07 22:17:54 |
| 5 | 2 | Måske bliver de mere tydelige, end jeg troede | 2019-02-06 22:17:54 |
| 6 | 3 | Har nogen set mine påskeæg? | 2019-01-07 22:47:54 |
| 7 | 3 | Jeg er virkelig forsinket med at levere disse! | 2019-04-06 22:17:54 |
Bemærk, at ligesom person tabel, note tabellen har en unik identifikator kaldet note_id , som er den primære nøgle til note bord. En ting, der ikke er indlysende, er inkluderingen af person_id værdi i tabellen. Hvad bruges det til? Det er det, der skaber forholdet til person bord. Hvorimod note_id er den primære nøgle til tabellen, person_id er det, der er kendt som en fremmednøgle.
Fremmednøglen giver hver indtastning i note tabel den primære nøgle for person optage det er forbundet med. Ved at bruge dette kan SQLAlchemy samle alle de noter, der er knyttet til hver person ved at forbinde person.person_id primær nøgle til note.person_id fremmednøgle, hvilket skaber en relation.
Fordele
Ved at opdele datasættet i to tabeller og introducere begrebet en fremmednøgle, har du gjort dataene lidt mere komplekse at tænke på, du har løst ulemperne ved en enkelt tabelrepræsentation. SQLAlchemy vil hjælpe dig med at kode den øgede kompleksitet ret nemt.
Dataene er ikke længere overflødige i databasen. Der er kun én personpost for hver person, du vil gemme i databasen. Dette løser opbevaringsproblemet med det samme og forenkler vedligeholdelsesproblemerne dramatisk.
Hvis påskeharen stadig ville ændre navne, skulle du kun ændre en enkelt række i person tabel og alt andet relateret til denne række (såsom note tabel) ville straks drage fordel af ændringen.
Kolonnenavngivning er mere konsekvent og meningsfuldt. Fordi person- og notedata findes i separate tabeller, kan oprettelses- og opdateringstidsstemplet navngives konsekvent i begge tabeller, da der ikke er nogen konflikt for navne på tværs af tabeller.
Derudover behøver du ikke længere at oprette permutationer af hver række for nye en-til-mange-relationer, du måske vil repræsentere. Tag vores children og phone_numbers eksempel fra tidligere. Implementering af dette ville kræve child og phone_number tabeller. Hver tabel ville indeholde en fremmednøgle af person_id relaterer det tilbage til person tabel.
Ved at bruge SQLAlchemy ville de data, du får tilbage fra ovenstående tabeller, være mere umiddelbart nyttige, da det, du får, er et objekt for hver personrække. Dette objekt har navngivne attributter svarende til kolonnerne i tabellen. En af disse attributter er en Python-liste, der indeholder de relaterede noteobjekter.
Ulempe
Hvor brute force-tilgangen var lettere at forstå, gør begrebet fremmednøgler og relationer tænkningen om dataene noget mere abstrakt. Denne abstraktion skal overvejes for hvert forhold, du etablerer mellem tabeller.
At gøre brug af relationer betyder at forpligte sig til at bruge et databasesystem. Dette er endnu et værktøj til at installere, lære og vedligeholde ud over det program, der rent faktisk bruger dataene.
SQLAlchemy-modeller
For at bruge de to ovenstående tabeller og forholdet mellem dem, skal du oprette SQLAlchemy-modeller, der er opmærksomme på begge tabeller og forholdet mellem dem. Her er SQLAlchemy Person model fra del 2, opdateret til at inkludere en relation til en samling notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Linje 1 til 8 i ovenstående Python-klasse ser præcis ud som det, du oprettede før i del 2. Linje 9 til 16 opretter en ny attribut i Person klasse kaldet notes . Denne nye notes attributter er defineret i følgende kodelinjer:
-
Linje 9: Ligesom de andre attributter i klassen opretter denne linje en ny attribut kaldet
notesog sætter det lig med en forekomst af et objekt kaldetdb.relationship. Dette objekt opretter den relation, du føjer tilPersonklasse og oprettes med alle de parametre, der er defineret i de efterfølgende linjer. -
Linje 10: Strengparameteren
'Note'definerer SQLAlchemy-klassen, somPersonklasse vil være relateret til.Noteklasse er ikke defineret endnu, hvorfor det er en streng her. Dette er en fremadrettet reference og hjælper med at håndtere problemer, som rækkefølgen af definitioner kan forårsage, når der er behov for noget, som ikke er defineret før senere i koden.'Note'streng tilladerPersonklasse for at findeNoteklasse ved runtime, som er efter bådePersonogNoteer blevet defineret. -
Linje 11:
backref='person'parameter er vanskeligere. Det opretter, hvad der er kendt som en baglæns reference iNotegenstande. Hver forekomst af enNoteobjekt vil indeholde en attribut kaldetperson.personattribut refererer til det overordnede objekt, som en bestemtNoteinstans er forbundet med. At have en reference til det overordnede objekt (personi dette tilfælde) i barnet kan være meget nyttigt, hvis din kode gentager sig over noter og skal indeholde oplysninger om forælderen. Dette sker overraskende ofte i display-gengivelseskode. -
Linje 12:
cascade='all, delete, delete-orphan'parameter bestemmer, hvordan noteobjektforekomster skal behandles, når der foretages ændringer i den overordnedePersoneksempel. For eksempel når enPersonobjektet slettes, vil SQLAlchemy oprette den nødvendige SQL for at slettePersonfra databasen. Derudover fortæller denne parameter, at den også skal slette alleNotetilfælde forbundet med det. Du kan læse mere om disse muligheder i SQLAlchemy-dokumentationen. -
Linje 13:
single_parent=Trueparameter er påkrævet, hvisdelete-orphaner en del af den tidligerecascadeparameter. Dette fortæller SQLAlchemy ikke at tillade forældreløseNoteforekomster (enNoteuden en forælderPersonobjekt) eksisterer, fordi hverNotehar en enlig forælder. -
Linje 14:
order_by='desc(Note.timestamp)'parameter fortæller SQLAlchemy, hvordanNoteskal sorteres forekomster knyttet til enPerson. Når enPersonobjekt er hentet, som standardnotesattributlisten vil indeholdeNotegenstande i ukendt rækkefølge. SQLAlchemydesc(...)funktionen vil sortere noderne i faldende rækkefølge fra nyeste til ældste. Hvis denne linje i stedet varorder_by='Note.timestamp', vil SQLAlchemy som standard brugeasc(...)funktion, og sorter noderne i stigende rækkefølge, ældst til nyeste.
Nu hvor din Person modellen har de nye notes attribut, og dette repræsenterer en-til-mange-forholdet til Note objekter, skal du definere en SQLAlchemy-model for en Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
Note klasse definerer de attributter, der udgør en note, som det ses i vores eksempel note database tabel fra oven. Attributterne er defineret her:
-
Linje 1 opretter
Noteklasse, som arver fradb.Model, præcis som du gjorde før, da du oprettedePersonklasse. -
Linje 2 fortæller klassen, hvilken databasetabel den skal bruge til at gemme
Notegenstande. -
Linje 3 opretter
note_idattribut, der definerer den som en heltalsværdi og som den primære nøgle forNoteobjekt. -
Linje 4 opretter
person_idattribut, og definerer den som fremmednøgle, der relatererNoteklasse tilPersonklasse ved hjælp afperson.person_idprimærnøgle. Dette ogPerson.notesattribut, er hvordan SQLAlchemy ved, hvad de skal gøre, når de interagerer medPersonogNotegenstande. -
Linje 5 opretter
contentattribut, som indeholder selve teksten i noten.nullable=Falseparameter angiver, at det er okay at oprette nye noter, der ikke har noget indhold. -
Linje 6 opretter
timestampattribut, og nøjagtigt somPersonklasse, denne indeholder oprettelses- eller opdateringstiden for en bestemtNoteeksempel.
Initialiser databasen
Nu hvor du har opdateret Person og oprettede Note modeller, skal du bruge dem til at genopbygge testdatabasen people.db . Du gør dette ved at opdatere build_database.py kode fra del 2. Sådan ser koden ud:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Ovenstående kode kom fra del 2 med et par ændringer for at skabe en-til-mange-forholdet mellem Person og Note . Her er de opdaterede eller nye linjer tilføjet til koden:
-
Linje 4 er blevet opdateret til at importere
Noteklasse defineret tidligere. -
Linje 7 til 39 indeholde den opdaterede
PEOPLEordbog, der indeholder vores persondata, sammen med listen over noter knyttet til hver person. Disse data vil blive indsat i databasen. -
Linje 49 til 61 gentag over
PEOPLEordbog, får hverpersonigen og bruge det til at oprette enPersonobjekt. -
Linje 53 itererer over
person.notesliste, får hvernoteigen. -
Linje 54 pakker
contentud ogtimestampfra hvernotetupel. -
Linje 55 til 60 opretter en
Noteobjekt og tilføjer det til personnotesamlingen ved hjælp afp.notes.append(). -
Linje 61 tilføjer
Personobjektptil databasesessionen. -
Linje 63 begår al aktiviteten i sessionen til databasen. Det er på dette tidspunkt, at alle data er skrevet til
personognotetabeller ipeople.dbdatabasefil.
Du kan se, at det fungerer med notes samling i Person objektforekomst p er ligesom at arbejde med enhver anden liste i Python. SQLAlchemy tager sig af den underliggende en-til-mange relationsinformation, når db.session.commit() opkald foretages.
For eksempel ligesom en Person instans har sit primære nøglefelt person_id initialiseret af SQLAlchemy, når den er forpligtet til databasen, forekomster af Note vil få deres primære nøglefelter initialiseret. Derudover er Note fremmednøgle person_id vil også blive initialiseret med den primære nøgleværdi for Person forekomst, den er forbundet med.
Her er et eksempel på en Person objekt før db.session.commit() i en slags pseudokode:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Her er eksemplet Person objekt efter db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Den vigtige forskel mellem de to er, at den primære nøgle til Person og Note objekter er blevet initialiseret. Databasemotoren tog sig af dette, da objekterne blev oprettet på grund af den automatiske inkrementering af primære nøgler, der er beskrevet i del 2.
Derudover er person_id fremmednøgle i alle Note forekomster er blevet initialiseret for at referere til dets overordnede. Dette sker på grund af den rækkefølge, som Person og Note objekter oprettes i databasen.
SQLAlchemy er opmærksom på forholdet mellem Person og Note genstande. Når en Person objektet er forpligtet til person databasetabel, får SQLAlchemy person_id primær nøgleværdi. Denne værdi bruges til at initialisere fremmednøgleværdien for person_id i en Note objekt, før det er forpligtet til databasen.
SQLAlchemy tager sig af dette databasehusholdningsarbejde på grund af de oplysninger, du har givet, da Person.notes attribut blev initialiseret med db.relationship(...) objekt.
Derudover er Person.timestamp attribut er blevet initialiseret med det aktuelle tidsstempel.
Kører build_database.py program fra kommandolinjen (i det virtuelle miljø genskaber databasen med de nye tilføjelser, gør den klar til brug med webapplikationen. Denne kommandolinje vil genopbygge databasen:
$ python build_database.py
build_database.py hjælpeprogrammet udsender ingen meddelelser, hvis det kører med succes. Hvis det giver en undtagelse, vil en fejl blive udskrevet på skærmen.
Opdater REST API
Du har opdateret SQLAlchemy-modellerne og brugt dem til at opdatere people.db database. Nu er det tid til at opdatere REST API for at give adgang til de nye noteroplysninger. Her er den REST API, du byggede i del 2:
| Handling | HTTP-udsagnsord | URL-sti | Beskrivelse |
|---|---|---|---|
| Opret | POST | /api/people | URL for at oprette en ny person |
| Læs | GET | /api/people | URL for at læse en samling af personer |
| Læs | GET | /api/people/{person_id} | URL til at læse en enkelt person af person_id |
| Opdater | PUT | /api/people/{person_id} | URL for at opdatere en eksisterende person med person_id |
| Slet | DELETE | /api/people/{person_id} | URL for at slette en eksisterende person med person_id |
REST API'en ovenfor giver HTTP URL-stier til samlinger af ting og til tingene selv. Du kan få en liste over personer eller interagere med en enkelt person fra denne liste over personer. Denne stistil forfiner det, der returneres på en venstre-til-højre måde, og bliver mere detaljeret, efterhånden som du går.
Du fortsætter dette venstre-til-højre-mønster for at blive mere detaljeret og få adgang til notesamlingerne. Her er den udvidede REST API, du vil oprette for at give noter til mini-blog-webapplikationen:
| Handling | HTTP-udsagnsord | URL-sti | Beskrivelse |
|---|---|---|---|
| Opret | POST | /api/people/{person_id}/notes | URL for at oprette en ny note |
| Læs | GET | /api/people/{person_id}/notes/{note_id} | URL til at læse en enkelt persons enkelte note |
| Opdater | PUT | api/people/{person_id}/notes/{note_id} | URL for at opdatere en enkelt persons enkelte note |
| Slet | DELETE | api/people/{person_id}/notes/{note_id} | URL for at slette en enkelt persons enkelte note |
| Læs | GET | /api/notes | URL for at få alle noter for alle personer sorteret efter note.timestamp |
Der er to variationer i notes del af REST API sammenlignet med den konvention, der bruges i people afsnit:
-
Der er ingen URL defineret til at hente alle
notesknyttet til en person, kun en URL for at få en enkelt note. Dette ville have gjort REST API komplet på en måde, men den webapplikation, du vil oprette senere, har ikke brug for denne funktionalitet. Derfor er det blevet udeladt. -
Der er inkluderet den sidste URL
/api/notes. Dette er en bekvemmelighedsmetode skabt til webapplikationen. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml file.
Bemærk:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes forhold. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes list. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribut. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Bemærk:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribut. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or operation. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
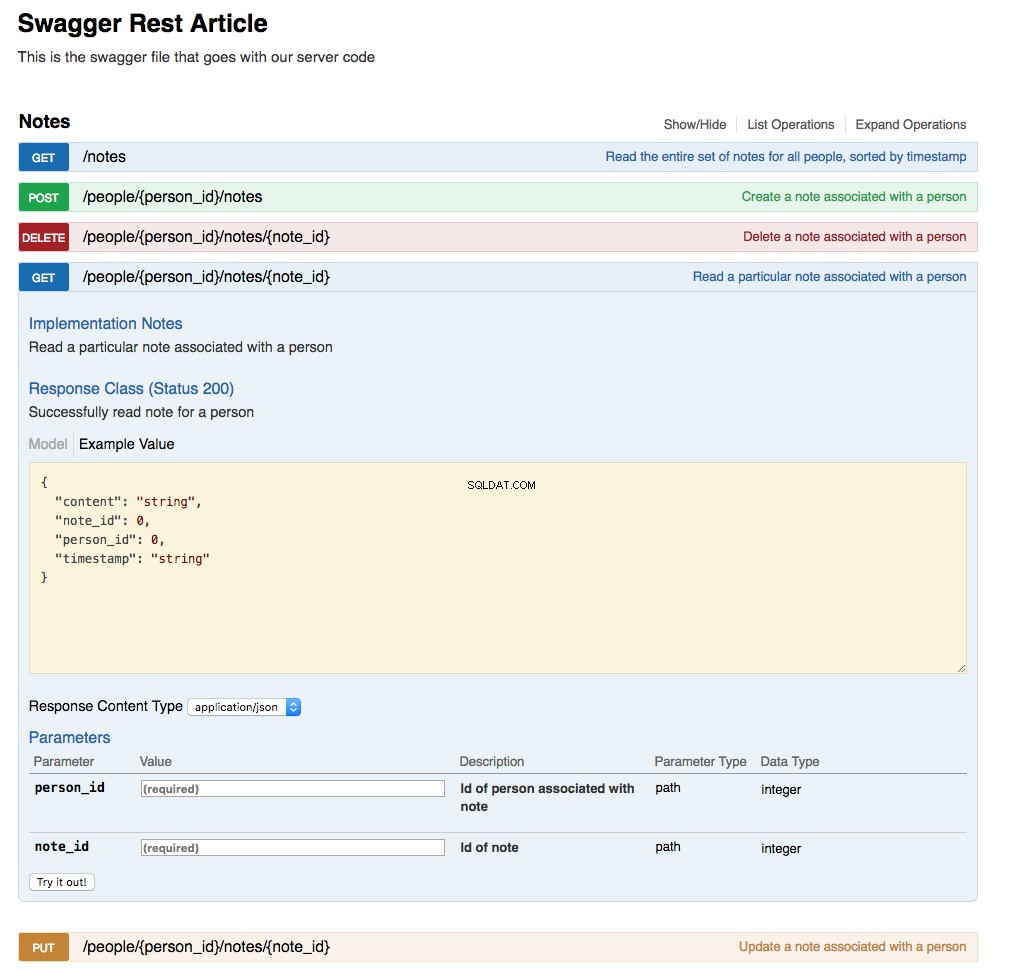
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
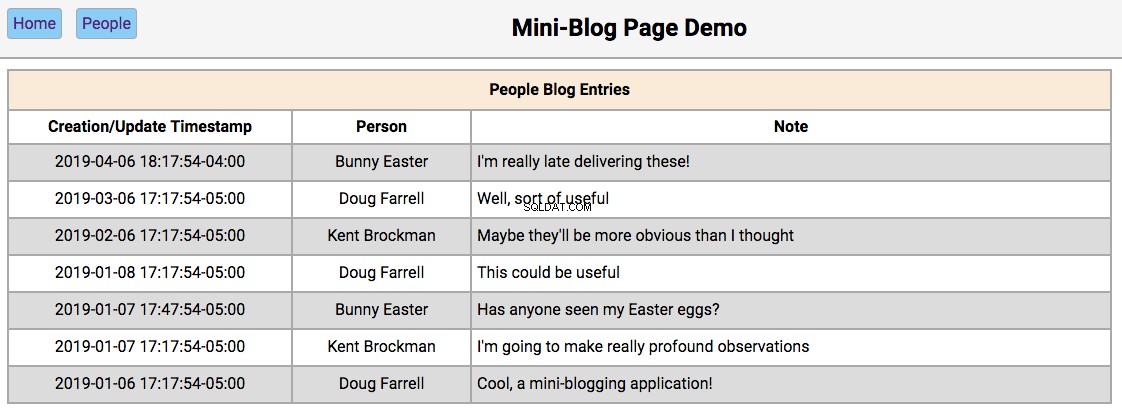
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
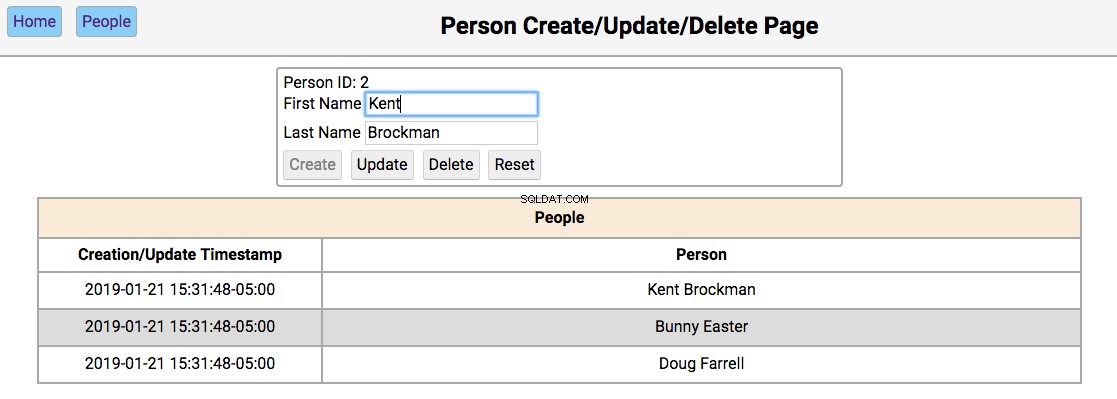
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
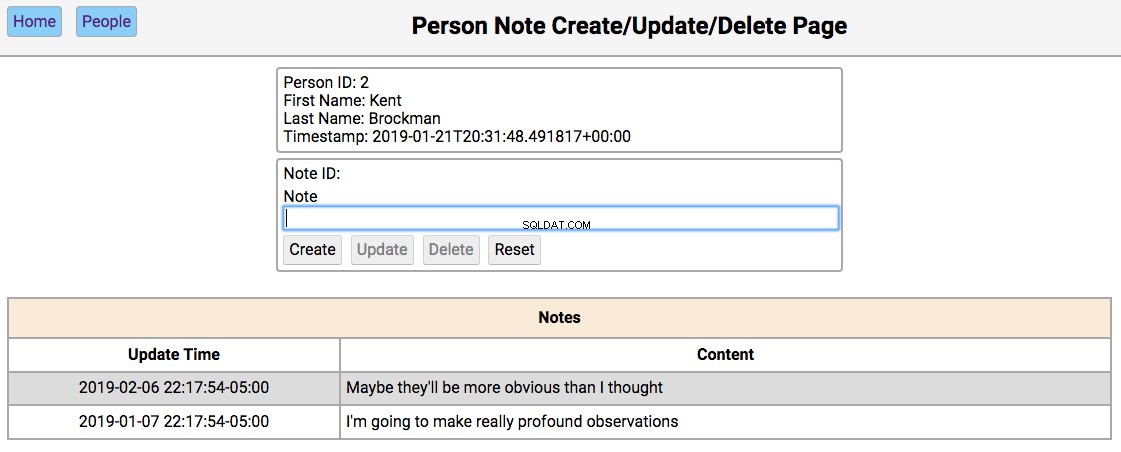
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Konklusion
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »