Du har brug for datamodellering for at spare dig selv eller din organisation for mange penge, timer og problemer. Læs videre for at finde ud af, hvordan datamodeller gør sin magi.
Datamodellering er processen med at skabe et konceptuelt billede af den information, en database indeholder eller bør indeholde. Som et resultat af denne proces skabes en datamodel, der giver form til dataobjekter (alle de enheder, for hvilke der skal lagres oplysninger), foreningerne eller relationerne mellem dem og regler eller begrænsninger, der styrer den information, der kommer ind i databasen .
Meget flot, men er det virkelig nødvendigt at arbejde med datamodeller? Kan vi ikke bare springe dette trin over, spare lidt tid og gå direkte til at oprette objekter i databasen? Et kursus i databasemodellering vil besvare disse spørgsmål, men hvis du vil have et resumé, vil jeg give dig grunde nok til at have en datamodel ved hånden, når du skal arbejde med information, der er gemt i en database. Når du er færdig med at læse denne artikel, vil du være enig med mig i, at arbejde med en database uden en ordentlig model svarer til at bygge et hus – eller endda en skyskraber – uden et ordentligt fundament.
Lad os starte med at overveje to sammenhænge, hvor datamodellering hovedsageligt udføres:
- Strategisk modellering, som udføres som en del af den generelle informationssystemstrategi i en organisation.
- Databasedesign, som er en del af designfasen i softwareudviklingsprocessen.
I begge situationer er der masser af grunde til at lave datamodellering. Først vil vi se dem, der har at gøre med informationssystemstrategi, derefter dem, der er relateret til softwareudvikling.
Højere informationskvalitet
En datamodel er afgørende for at give klarhed og konsistens i metadataene , definitionerne af de objekter, der udgør en database. Dette er med til at øge informationskvaliteten. For eksempel kan en datamodel sikre, at de korrekte formater bruges til dataelementer som telefonnumre og postnumre, og i en database, hvor kundedata er gemt, kan den sikre, at hver kunde har mindst én adresse.
Du kan også sikre kvaliteten af de oplysninger, der er lagret i en database, ved at pålægge regler, så kun gyldige data kommer ind i tabellerne. For at gøre dette, når du designer datamodellen, indstiller du værdidomænet for hvert felt og adskiller de felter, der skal have værdier, fra dem, der kan stå tomme.
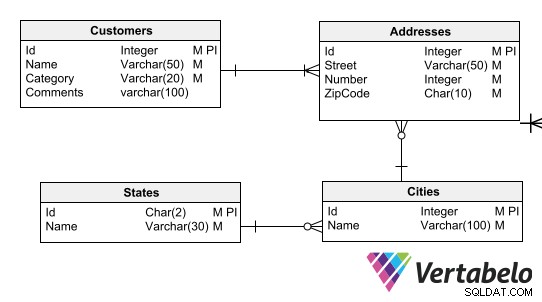
Datamodeldefinitioner sikrer dataoverholdelse til forretningsregler. For eksempel vil du måske tvinge hver klient til at have en adresse med det korrekte postnummerformat, eller at hver adresse skal knyttes til en by og hver by med en stat.
Informationskvaliteten forbedres også ved at pålægge restriktioner, der sikrer referentiel integritet og opretholder den tilsigtede kardinalitet i relationerne mellem enheder. Disse begrænsninger kan kun udledes af en ordentlig datamodel.
Genbrug af dataaktiver
Når man udvikler et nyt system eller tilføjer ny funktionalitet til et eksisterende system, er det almindeligt, at nogle af de dataenheder, som den nye udvikling kræver, allerede findes i en database og derfor kan genbruges. Den eneste måde at finde ud af, hvilke entiteter der allerede eksisterer, er at gennemse opdaterede datamodeller, der tilstrækkeligt beskriver strukturerne af de databaser, der bruges af organisationen.
Konceptuelle, logiske og fysiske datamodeller bør vedligeholdes for at give visninger med forskellige abstraktionsniveauer, så du nemt kan opdage genbrugelige dataaktiver. Du kan udnytte et specialiseret designværktøj, såsom Vertabelo-platformen, til at lette oprettelsen af forskellige typer datamodeller og endda til at udlede en fra en anden.
Denne gode praksis undgår at generere overflødige data i forskellige skemaer, hvilket før eller siden fører til inkonsekvent information (mere om dette nedenfor).
Migration til skymiljøer
Med DaaS (Data as a Service) infrastrukturer eller databaser i skyen, er der visse krav, såsom databasprivatliv , dynamisk skalerbarhed , og effektivitet i at administrere flere lejere , blive mere kritisk.
Datamodeller er et uvurderligt værktøj til at opfylde disse krav, da de gør det lettere at verificere, at et skemadesign er i overensstemmelse med dem. Til gengæld giver de dig mulighed for at definere partitionerne af skemaerne og deres lagerkrav, hvilket er afgørende for korrekt dimensionering af det nødvendige serviceniveau og den forventede lagervækst, når databaser ligger i private eller offentlige skyer.
Databasedesignartefakter såsom ER-diagrammer er de foretrukne værktøjer, når du forbereder migrering til et cloudmiljø. En guide til, hvordan du bruger ER-diagrammer kan give dig et glimt af deres anvendelighed i databasemigrering.
Databasemodellering for Big Data og NoSQL
Ikke-relationelle databaser, såsom NoSQL og dimensionelle skemaer, kan tvinge os til at tilsidesætte (i det mindste et øjeblik) vores traditionelle relationelle tankegang. Men det betyder ikke, at vi kan undvære datamodeller. Tværtimod bliver datamodellering endnu vigtigere.
Når du skal arbejde med Big Data, står du som regel over for enorme siloer af information, der skal nedbrydes, forfines og struktureres på en sådan måde, at du eller en dataanalytiker kan få strategisk indsigt fra det. Et omhyggeligt skemadesign er påkrævet, både for raffinerede informationslagre eller datavarehuse og til iscenesættelse af lagre, der bruges til datarensning og datastruktureringsprocesser.
Der er en misforståelse, hovedsageligt af programmører, at NoSQL-databaser ikke bruger skemaer og derfor ikke kræver datamodeller. Intet kunne være længere fra sandheden. Da NoSQL-teknologier ikke giver en standardiseret måde at se metadataene på (noget enhver RDBMS gør), bliver datamodeller afgørende for at lade folk bruge og dele informationen, der er gemt i databasen.
Fusioner og opkøb
Enhver fusion mellem to organisationer udgør en gigantisk udfordring for deres respektive it-afdelinger. En væsentlig del af denne udfordring ligger i databasekonsolidering. Hvis begge organisationer har opdaterede datamodeller, kan denne konsolidering foretages i modellerne i stedet for direkte i databaserne, hvilket væsentligt reducerer indsatsen afsat til opgaven.
Indtil videre har vi set fordelene ved datamodellering i forbindelse med IT-strategisk planlægning af en organisation. Hvis disse grunde ikke er nok til at overbevise dig om vigtigheden af datamodellering, så lad os også se på de fordele, det medfører for softwareudvikling.
Reducerede udviklingsomkostninger
I de tidlige stadier af et udviklingsprojekt, når budgettet analyseres, kan der stilles spørgsmålstegn ved behovet for at lægge kræfter i at opbygge en datamodel. Hvis projektlederne og lederne er kloge nok, vil de sammenligne, hvad det koster at bygge og vedligeholde en datamodel med de omkostninger, der vil blive sparet og beslutte sig for at bygge modellen.
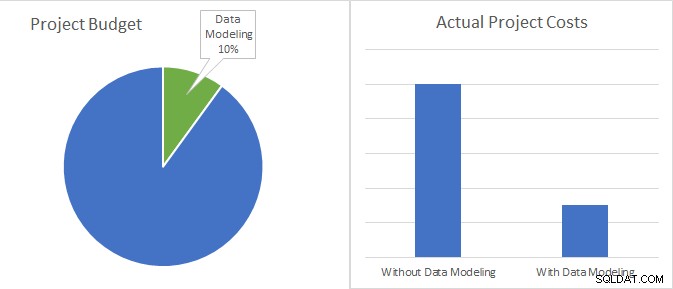
Datamodellering er kun 10 % af et udviklingsprojektbudget og har potentiale til at reducere de faktiske projektomkostninger til mindre end en tredjedel.
Overvej blot følgende. I de fleste tilfælde er omkostningerne ved datamodellering (det vil sige omkostningerne ved den indsats, der kræves for at bygge og vedligeholde modellen) mindre end 10 % af det samlede budget for et softwareprojekt. Til sammenligning er omkostningsbesparelserne forbundet med at bruge datamodeller op til 70 %, alt sammen fra reduktionerne i timerne til kodning og vedligeholdelse.
Så inden for softwareudvikling er den første og vigtigste grund til at lave datamodellering det ubestridelige ROI (return on investment), som projektledere skal overveje i de tidlige stadier af hvert projekt.
Bedre definitioner af krav
I softwareudvikling kan du garantere en større forståelse for det system, der skal udvikles, hvis datamodelleringsaktiviteterne udføres sideløbende med kravindsamlingen. Kravene vil være mere fuldstændige og mere korrekte.
Datamodellering hjælper med at afdække forretningsregler og stille spørgsmål under kravudvikling, samtidig med at dataintegriteten sikres. Det er mere effektivt end procesmodelleringsaktiviteter som f.eks. use case-design eller workflow-design, og naturligvis mere udtryksfuldt og mindre omfattende end prosabeskrivelsen af forretningsreglerne.
Hurtigere udvikling
Når udviklere har ordentlige datamodeller ved hånden, kan de udføre deres arbejde med færre fejl. Datamodelleringsværktøjer genererer og vedligeholder automatisk databaseskemaer og skaber DDL-scripts (Data Definition Language), der ofte er for lange, komplekse og rodede til, at udviklere kan generere manuelt.
Til gengæld fremmer disse værktøjer samarbejde ved at tillade, at modeller kan deles mellem udviklere. Når der er behov for ændringer, kan du lave dem i datamodellen og sikre, at alle udviklere bliver informeret, og at de vil blive anvendt på databaserne uden at ødelægge noget.
Alt dette gør, at systemerne kan leveres hurtigere og med færre fejl.
Forøgelse af agile metoder
Agile metoder sigter mod at fremskynde udviklingsprocessen ved at fokusere indsatsen på at levere fungerende software og undgå bureaukrati, overdreven dokumentation og faser, der udføres efter hinanden.
Databasemodellering står over for en betydelig udfordring, når man arbejder i agile miljøer, da designeren skal kunne arbejde på "det store billede", mens udviklere kun har brug for de dataobjekter, der kræves til hver brugerhistorie. For at nå til enighed mellem datamodelbyggere og udviklere bruger agile metoder teknikker såsom sandboxing og forgrening .
En sandkasse er arbejdsmiljøet for hver udvikler. Designeren kan arbejde med grenene af hoveddatamodellen i hver udviklers sandkasse, som vil give feedback for at forfine den. Ved slutningen af hver etape (eller sprint) slår databasedesigneren de forskellige grene sammen for at holde hele modellen opdateret.
Du tror måske, at datamodellering bremser agile teams, og at udviklere skal vente, indtil modellerne er klar til at begynde deres arbejde. Men i virkeligheden opretholder brugen af teknikker som sandboxing og branching principperne for smidighed og opnår samtidig ovennævnte hastighedsforbedringer.
Hvad hvis jeg ikke bruger datamodeller?
Du tror måske, at du stadig kan overleve uden fordelene ved de hidtil nævnte datamodeller for at spare tid. Men hvis du beslutter dig imod datamodellering, risikerer du at løbe ind i alvorlige problemer såsom:
- Unødvendig redundans:Da der ikke er nogen model til at se dataobjekterne klart, vil forskellige versioner af de samme objekter vises med forskellig information. For eksempel kan et lagersystem rapportere, at 500 enheder af en vare blev solgt i den sidste måned, mens et logistiksystem kan rapportere, at 1000 enheder af samme vare blev afsendt i samme periode. Hvilket er rigtigt? Hvem ved.
- Slåge apps:Fraværet af en datamodel gør optimeringsopgaver vanskelige, hvilket reducerer applikationernes reaktionsevne.
- Manglende evne til at opfylde kvalitetsstandarder:Hvis der ikke er nogen datamodel, vil dine databaser ikke blive dokumenteret, hvilket er obligatorisk i scenarier såsom databasemigrering.
- Dårlig softwarekvalitet:Kravene til softwareudvikling vil være ringe, og brugerne vil ikke have de applikationer, de har brug for eller ønsker.
- Højere udviklingsomkostninger:Jeg har allerede nævnt de betydelige omkostningsbesparelser, der kan opnås i et udviklingsprojekt ved at bruge datamodeller. Hvis du vælger ikke at bruge dem, skal du tage stilling til, hvem der skal betale for de ekstra udviklings- og vedligeholdelsesomkostninger. Og hvem vil komme med undskyldninger, når fristerne ikke overholdes.
Er du stadig ikke overbevist?
Hvis det, du har læst indtil nu, ikke er nok til at overbevise dig om vigtigheden af datamodellering, så husk, at data bliver et stadigt mere værdifuldt aktiv for alle slags organisationer. Modellering af strukturerne til at drage fordel af information har hidtil uset relevans i dag.
Overvej dette:under guldfeberen var de fyre, der tjente flest penge, ikke dem, der gravede efter guldklumper, men snarere dem, der leverede værktøjerne til at udvinde guldet. I 2021 kommer guldklumper i form af indsigtsfuld information, og minearbejderne, der udvinder så værdifuldt materiale, skal have datamodeller.