[ Del 1 | Del 2 | Del 3 | Del 4 ]
Halloween-problemet kan have en række vigtige virkninger på udførelsesplaner. I denne sidste del af serien ser vi på de tricks, som optimeringsværktøjet kan bruge for at undgå Halloween-problemet, når der kompileres planer for forespørgsler, der tilføjer, ændrer eller sletter data.
Baggrund
Gennem årene er der blevet forsøgt en række metoder for at undgå Halloween-problemet. En tidlig teknik var simpelthen at undgå at bygge nogen udførelsesplaner, der involverede læsning fra og skrivning til nøgler af samme indeks. Dette var ikke særlig vellykket ud fra et præstationssynspunkt, ikke mindst fordi det ofte betød, at man skulle scanne basistabellen i stedet for at bruge et selektivt ikke-klynget indeks til at finde de rækker, der skulle ændres.
En anden tilgang var fuldstændig at adskille læse- og skrivefaserne af en opdateringsforespørgsel ved først at lokalisere alle rækker, der kvalificerer sig til ændringen, gemme dem et sted og først derefter begynde at udføre ændringerne. I SQL Server er denne fuldfaseadskillelse opnås ved at placere den nu velkendte Eager Table Spool på inputsiden af opdateringsoperatøren:
Spolen læser alle rækker fra dens input og gemmer dem i en skjult tempdb arbejdsbord. Siderne i denne arbejdstabel kan forblive i hukommelsen, eller de kræver muligvis fysisk diskplads, hvis rækkerne er store, eller hvis serveren er under hukommelsestryk.
Fuldfaseseparation kan være mindre end ideel, fordi vi generelt ønsker at køre så meget af planen som muligt som en pipeline, hvor hver række er færdigbehandlet, før vi går videre til den næste. Pipelining har mange fordele, herunder at undgå behovet for midlertidig opbevaring og kun at røre hver række én gang.
SQL Server Optimizer
SQL Server går meget længere end de to teknikker, der er beskrevet hidtil, selvom den selvfølgelig inkluderer begge som muligheder. SQL Server-forespørgselsoptimeringsværktøjet registrerer forespørgsler, der kræver Halloween-beskyttelse, bestemmer hvor meget beskyttelse er påkrævet, og bruger omkostningsbaseret analyse for at finde den billigste metode til at yde denne beskyttelse.
Den nemmeste måde at forstå dette aspekt af Halloween-problemet på er at se på nogle eksempler. I de følgende afsnit er opgaven at tilføje en række tal til en eksisterende tabel – men kun tal, der ikke allerede eksisterer:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 rækker
Det første eksempel behandler en række tal fra 1 til 5 inklusive:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
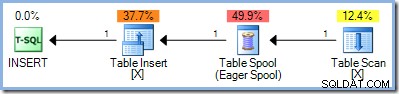
); Da denne forespørgsel læser fra og skriver til nøglerne i det samme indeks på testtabellen, kræver udførelsesplanen Halloween-beskyttelse. I dette tilfælde bruger optimeringsværktøjet fuld faseadskillelse ved hjælp af en Ivrig bordspole:
50 rækker
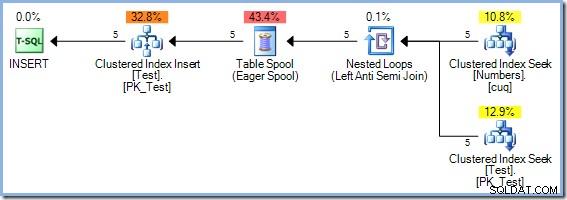
Med fem rækker nu i testtabellen kører vi den samme forespørgsel igen og ændrer WHERE klausul til at behandle tallene fra 1 til 50 inklusive :
Denne plan giver korrekt beskyttelse mod Halloween-problemet, men den har ikke en ivrig bordspole. Optimizeren genkender, at Hash Match join-operatøren blokerer for sit build-input; alle rækker læses ind i en hash-tabel, før operatøren starter matchningsprocessen ved hjælp af rækker fra sonde-inputtet. Som en konsekvens giver denne plan naturligvis faseadskillelse (kun for testbordet) uden behov for en spole.
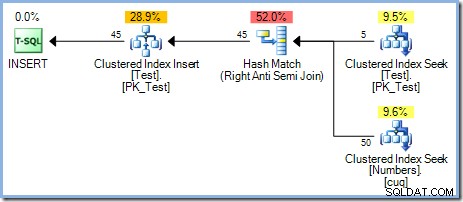
Optimizeren valgte en Hash Match-deltagelsesplan frem for Nested Loops-sammenføjningen, som ses i 5-rækkers planen af omkostningsbaserede årsager. Hash Match-planen med 50 rækker har en samlet estimeret pris på 0,0347345 enheder. Vi kan tvinge den indlejrede sløjfer-plan, der blev brugt tidligere, med et tip for at se, hvorfor optimeringsværktøjet ikke valgte indlejrede sløjfer:
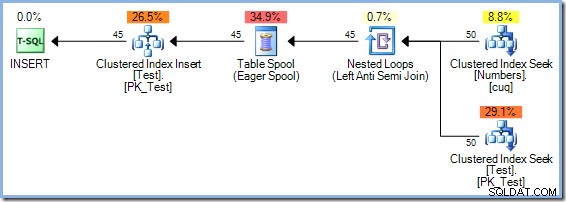
Denne plan har en anslået pris på 0,0379063 enheder inklusive spolen, lidt mere end Hash Match-planen.
500 rækker
Med 50 rækker nu i testtabellen øger vi antallet af tal yderligere til 500 :
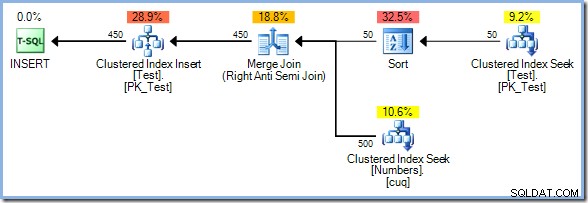
Denne gang vælger optimeringsværktøjet en Merge Join, og igen er der ingen Eager Table Spool. Sorteringsoperatøren sørger for den nødvendige faseadskillelse i denne plan. Den bruger sit input fuldt ud, før den returnerer den første række (sorteringen kan ikke vide, hvilken række der sorterer først, før alle rækker er blevet set). Optimeringsværktøjet besluttede, at sortering 50 rækker fra testtabellen ville være billigere end ivrig spooling 450 rækker lige før opdateringsoperatøren.
Sort plus Merge Join-planen har en estimeret pris på 0,0362708 enheder. Alternativerne Hash Match og Nested Loops kommer ud på 0,0385677 enheder og 0,112433 hhv. enheder.
Noget mærkeligt ved sorteringen
Hvis du har kørt disse eksempler for dig selv, har du måske bemærket noget mærkeligt ved det sidste eksempel, især hvis du kiggede på Plan Explorer værktøjstip til testtabellen Seek and the Sort:
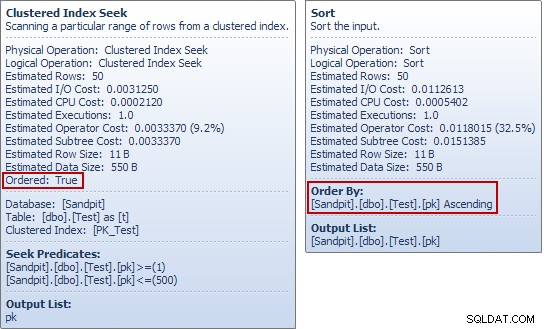
The Seek producerer en ordret strøm af pk værdier, så hvad er meningen med at sortere i den samme kolonne umiddelbart bagefter? For at besvare det (meget rimelige) spørgsmål starter vi med kun at se på SELECT del af INSERT forespørgsel:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;>
Denne forespørgsel producerer udførelsesplanen nedenfor (med eller uden ORDER BY). Jeg tilføjede for at imødekomme visse tekniske indvendinger, du måtte have):
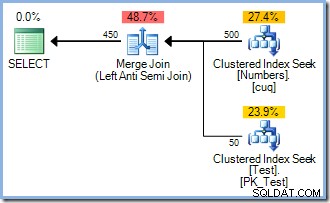
Bemærk manglen på en sorteringsoperator. Så hvorfor gjorde INSERT planen omfatter en sortering? Simpelthen for at undgå Halloween-problemet. Optimeringsværktøjet mente, at udføre en overflødig sortering (med dens indbyggede faseadskillelse) var den billigste måde at udføre forespørgslen på og garantere korrekte resultater. Smart.
Halloween-beskyttelsesniveauer og -egenskaber
SQL Server Optimizer har specifikke funktioner, der gør det muligt at ræsonnere om niveauet af Halloween Protection (HP), der kræves på hvert punkt i forespørgselsplanen, og den detaljerede effekt, hver operatør har. Disse ekstra funktioner er inkorporeret i den samme egenskabsramme, som optimeringsværktøjet bruger til at holde styr på hundredvis af andre vigtige informationer under sine søgeaktiviteter.
Hver operatør har en påkrævet HP ejendom og en leveret HP ejendom. Det påkrævede egenskaben angiver det nødvendige HP-niveau på det tidspunkt i træet for korrekte resultater. Den leverede egenskaben afspejler den HP leveret af den aktuelle operatør og den kumulative HP-effekter leveret af dets undertræ.
Optimeringsværktøjet indeholder logik til at bestemme, hvordan hver fysisk operatør (f.eks. en Compute Scalar) påvirker HP-niveauet. Ved at udforske en bred vifte af planalternativer og afvise planer, hvor den leverede HP er mindre end den påkrævede HP hos opdateringsoperatøren, har optimeringsværktøjet en fleksibel måde at finde korrekte, effektive planer, der ikke altid kræver en Ivrig bordspole.
Planlæg ændringer til Halloween-beskyttelse
Vi så optimeringsværktøjet tilføje en overflødig sortering til Halloween Protection i det tidligere Merge Join-eksempel. Hvordan kan vi være sikre på, at dette er mere effektivt end en simpel Ivrig bordspole? Og hvordan kan vi vide, hvilke funktioner i en opdateringsplan der kun er til Halloween-beskyttelse?
Begge spørgsmål kan besvares (i et testmiljø, naturligvis) ved hjælp af udokumenteret sporingsflag 8692 , som tvinger optimizeren til at bruge en Ivrig bordspole til Halloween-beskyttelse. Husk, at Merge Join-planen med den redundante sortering havde en estimeret pris på 0,0362708 magiske optimeringsenheder. Vi kan sammenligne det med alternativet Eager Table Spool ved at genkompilere forespørgslen med sporingsflag 8692 aktiveret:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
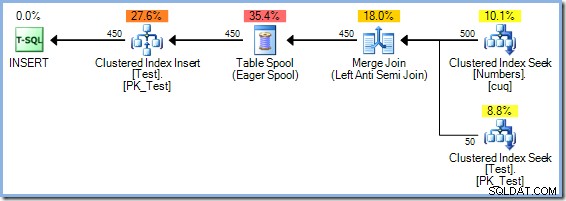
Eager Spool-planen har en anslået pris på 0,0378719 enheder (op fra 0,0362708 med den overflødige sortering). De her viste omkostningsforskelle er ikke særlig markante på grund af opgavens trivielle karakter og rækkernes lille størrelse. Opdateringsforespørgsler fra den virkelige verden med komplekse træer og større rækkeantal producerer ofte planer, der er meget mere effektive takket være SQL Server optimizers evne til at tænke dybt over Halloween Protection.
Andre ikke-spool muligheder
At placere en blokerende operatør optimalt inden for en plan er ikke den eneste strategi, der er åben for optimeringsværktøjet for at minimere omkostningerne ved at yde beskyttelse mod Halloween-problemet. Det kan også ræsonnere om rækken af værdier, der behandles, som følgende eksempel viser:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Udførelsesplanen viser, at der ikke er behov for Halloween-beskyttelse, på trods af at vi læser fra og opdaterer nøglerne til et fælles indeks:
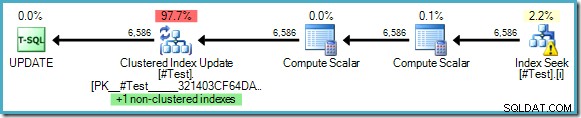
Optimizeren kan se, at ændring af 'some_value' fra 5 til 10 aldrig kunne forårsage, at en opdateret række ses en anden gang af Index Seek (som kun leder efter rækker, hvor some_value er 5). Denne begrundelse er kun mulig, hvor der bruges bogstavelige værdier i forespørgslen, eller hvor forespørgslen angiver OPTION (RECOMPILE) , hvilket gør det muligt for optimeringsværktøjet at opsnuse værdierne af parametrene til en engangsudførelsesplan.
Selv med bogstavelige værdier i forespørgslen, kan optimeringsværktøjet forhindres i at anvende denne logik, hvis databaseindstillingen FORCED PARAMETERIZATION er ON . I så fald erstattes de bogstavelige værdier i forespørgslen af parametre, og optimeringsværktøjet kan ikke længere være sikker på, at Halloween Protection ikke er påkrævet (eller ikke vil være påkrævet, når planen genbruges med forskellige parameterværdier):

Hvis du undrer dig over, hvad der sker, hvis FORCED PARAMETERIZATION er aktiveret og forespørgslen angiver OPTION (RECOMPILE) , svaret er, at optimeringsværktøjet kompilerer en plan for de sniffede værdier, og så kan anvende optimeringen. Som altid med OPTION (RECOMPILE) , er forespørgselsplanen med specifik værdi ikke cachelagret til genbrug.
Top
Dette sidste eksempel viser, hvordan Top operatør kan fjerne behovet for Halloween-beskyttelse:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Der kræves ingen beskyttelse, fordi vi kun opdaterer én række. Indekssøgningen kan ikke finde den opdaterede værdi, fordi behandlingspipelinen stopper, så snart den første række er opdateret. Igen kan denne optimering kun anvendes, hvis der bruges en konstant bogstavelig værdi i TOP , eller hvis en variabel, der returnerer værdien '1', sniffes med OPTION (RECOMPILE) .
Hvis vi ændrer TOP (1) i forespørgslen til en TOP (2) , vælger optimeringsværktøjet en Clustered Index Scan i stedet for Index Seek:

Vi opdaterer ikke nøglerne til det grupperede indeks, så denne plan kræver ikke Halloween-beskyttelse. Tvinger brugen af det ikke-klyngede indeks med et tip i TOP (2) forespørgsel gør omkostningerne ved beskyttelsen tydelige:

Optimizeren vurderede, at Clustered Index Scan ville være billigere end denne plan (med dens ekstra Halloween-beskyttelse).
Odds and Ends
Der er et par andre punkter, jeg vil komme med om Halloween Protection, som ikke har fundet en naturlig plads i serien før nu. Det første er spørgsmålet om Halloween-beskyttelse, når et rækkeversionsisoleringsniveau er i brug.
Rækkeversionering
SQL Server giver to isolationsniveauer, READ COMMITTED SNAPSHOT og SNAPSHOT ISOLATION der bruger et versionslager i tempdb at give en konsistent visning af databasen på erklærings- eller transaktionsniveau. SQL Server kunne undgå Halloween Protection fuldstændigt under disse isolationsniveauer, da versionslagret kan levere data upåvirket af ændringer, som den aktuelt eksekverende sætning måtte have foretaget indtil videre. Denne idé er i øjeblikket ikke implementeret i en frigivet version af SQL Server, selvom Microsoft har indgivet et patent, der beskriver, hvordan dette ville fungere, så måske vil en fremtidig version inkorporere denne teknologi.
Honger og videresendte poster
Hvis du er bekendt med det indre af heap-strukturer, spekulerer du måske på, om et bestemt Halloween-problem kan opstå, når videresendte poster genereres i en heap-tabel. Hvis dette er nyt for dig, vil en heap-record blive videresendt, hvis en eksisterende række opdateres, så den ikke længere passer på den originale dataside. Motoren efterlader en videresendelsesstump og flytter den udvidede post til en anden side.
Der kan opstå et problem, hvis en plan, der indeholder en heap-scanning, opdaterer en post, så den videresendes. Heap-scanningen kan støde på rækken igen, når scanningspositionen når siden med den videresendte post. I SQL Server undgås dette problem, fordi Storage Engine garanterer altid at følge videresendelsesanvisninger med det samme. Hvis scanningen støder på en post, der er blevet videresendt, ignorerer den den. Med denne beskyttelse på plads behøver forespørgselsoptimeringsværktøjet ikke bekymre sig om dette scenarie.
SCHEMABINDING og T-SQL skalarfunktioner
Der er meget få lejligheder, hvor det er en god idé at bruge en T-SQL skalarfunktion, men hvis du skal bruge en, skal du være opmærksom på en vigtig effekt, det kan have med hensyn til Halloween Protection. Medmindre en skalarfunktion er erklæret med SCHEMABINDING option, antager SQL Server, at funktionen tilgår tabeller. For at illustrere, overvej den simple T-SQL skalarfunktion nedenfor:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Denne funktion har ikke adgang til nogen tabeller; i virkeligheden gør den ikke andet end at returnere parameterværdien, der er sendt til den. Se nu på følgende INSERT forespørgsel:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Udførelsesplanen er præcis, som vi ville forvente, uden Halloween-beskyttelse nødvendig:
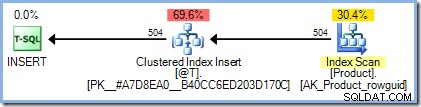
Tilføjelse af vores gør-intet-funktion har dog en dramatisk effekt:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Udførelsesplanen inkluderer nu en Ivrig bordspole til Halloween-beskyttelse. SQL Server antager, at funktionen tilgår data, hvilket kan omfatte læsning fra produkttabellen igen. Som du måske husker, er en INSERT plan, der indeholder en reference til måltabellen på læsesiden af planen, kræver fuld Halloween-beskyttelse, og så vidt optimeringsværktøjet ved, kan det være tilfældet her.
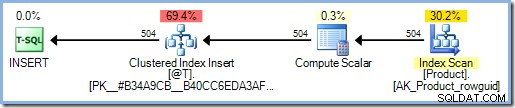
Tilføjelse af SCHEMABINDING mulighed for funktionsdefinitionen betyder, at SQL Server undersøger funktionens krop for at bestemme, hvilke tabeller den får adgang til. Den finder ingen sådan adgang, og tilføjer derfor ingen Halloween-beskyttelse:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
Dette problem med T-SQL skalarfunktioner påvirker alle opdateringsforespørgsler – INSERT , UPDATE , DELETE , og MERGE . At vide, hvornår du støder på dette problem, bliver vanskeligere, fordi unødvendig Halloween-beskyttelse ikke altid vises som en ekstra Ivrig bordspole, og skalarfunktionskald kan for eksempel være skjult i visninger eller beregnede kolonnedefinitioner.
[ Del 1 | Del 2 | Del 3 | Del 4 ]