Med introduktionen af Azure SQL Database og tilføjelsen af mere funktionalitet i v12 begynder databaseadministratorer at se deres organisationer mere interesserede i at flytte databaser til denne platform.
Jeg begyndte for nylig at dykke mere ned i Azure SQL Database for at se, hvad der er drastisk anderledes end at understøtte boxversionen i datacentre over hele verden og Azure SQL Database. I min tidligere artikel, "Tuning:Et godt sted at starte," dækkede jeg min tilgang til at komme i gang med at tune SQL Server. Jeg besluttede at gennemgå dette i forhold til Azure SQL Database for at opdage de store forskelle.
I min oprindelige artikel startede jeg med almindelige indstillinger på instansniveau, som jeg ser ignoreret eller efterladt som standard, samt vedligeholdelseselementer. Disse inkluderer hukommelse, maxdop, omkostningstærskel for parallelisme, aktivering af optimering til ad hoc-arbejdsbelastninger og konfiguration af tempdb. Med Azure SQL Database er du ikke ansvarlig for forekomsten og kan ikke ændre disse indstillinger. Azure SQL Database er en platform som en tjeneste (PaaS), hvilket betyder, at Microsoft administrerer instansen for dig; du er simpelthen lejer med din database eller dine databaser.
Du er dog ansvarlig for vedligeholdelsen, så du skal opdatere statistik og håndtere indeksfragmentering som du gør for kasseproduktet. Til disse opgaver har jeg fundet ud af, at de fleste klienter administrerer disse processer med en dedikeret Azure VM, der kører SQL Server og bruger SQL Server Agent med planlagte job.
Efter trinene fra min artikel, er de næste områder, jeg begynder at se nærmere på, fil- og ventestatistikker og højprisforespørgsler. Hvis du spekulerer på, om dette aspekt af dit job som produktions-dba med lokale databaser vil ændre sig, når du arbejder med Azure SQL Database, er svaret ikke rigtig . Fil- og ventestatistikker er der stadig, men vi skal komme til dem på en lidt anden måde. Hvis du er vant til at bruge Paul Randals scripts til filstatistik og ventestatistikker (eller forespørgslerne til filstatistikker i en periode og ventestatistikker i en periode), så bliver du nødt til at foretage nogle ændringer for at disse scripts til at arbejde med Azure SQL Database.
Da jeg første gang prøvede Pauls filstatistikscript, mislykkedes det, fordi Azure SQL Database ikke understøttede sys.master_files :
Ugyldigt objektnavn 'sys.master_files'.
Jeg var i stand til at ændre scriptet til at bruge sys.databases i joinforbindelsen for at få databasenavnet og fjerne delen af scriptet for at få de individuelle filnavne, da vi kun har at gøre med en enkelt data- og logfil. Du kan se de ændringer, jeg skulle lave på følgende billede:
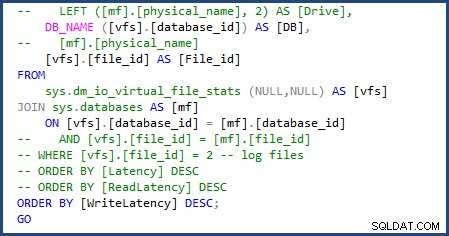
Da jeg kørte scriptet file-stats-over-a-periode-of-time efter, lavede jeg den samme ændring til sys.databases og fjernelse af referencerne til file_id i joinforbindelsen mislykkedes det, fordi Azure SQL Database v12 ikke understøttede globale ##temp-tabeller.
Da jeg ændrede alle de globale ##temp-tabeller til lokale, havde jeg et andet problem med, at scriptet ikke var i stand til at droppe eksisterende temp-tabeller, der blev brugt, fordi lokale #temp-tabeller ikke kan refereres direkte ved navn, som globale ##temp-tabeller kan, men dette var let at overvinde ved at ændre sådanne kontroller til OBJECT_ID('tempdb..#SQLskillsStats1') . Jeg lavede den samme ændring for den anden midlertidige tabel og opdaterede kodeblokken i begyndelsen og slutningen af scriptet.
Jeg var nødt til at foretage en ændring mere og fjerne [mf].[type_desc] og LEFT ([mf].[physical_name], 2) AS [Drive] da de er afhængige af sys.master_files . Scriptet var derefter komplet og klar til brug med Azure SQL Database.
Jeg bruger regelmæssigt file-stats-over-en-periode-of-time, når jeg fejler problemer med ydeevnen. De kumulative data har sit formål, men jeg er mere interesseret i specifikke tidssegmenter, hvor brugerens arbejdsbelastninger køres.
Med filstatistik er vi bekymrede over vores latenstid pr. databasefil, og hvordan vi kan justere for at hjælpe med at reducere den samlede I/O. Fremgangsmåden er den samme som SQL Server, hvor du skal tune dine forespørgsler korrekt og have de korrekte indekser. Hvis arbejdsbyrden bare er for stor, skal du flytte til et hurtigere DTU-databaseniveau. For mig er dette fantastisk:du kaster bare hardware efter det; men det er ikke rigtig hardware i traditionel forstand. Med Azure SQL Database kommer du til at starte med et billigere niveau og skalere, efterhånden som din virksomhed og I/O-krav vokser – hovedsageligt ved blot at vende en switch.
Det var nemmere at prøve at finde den bedste metode til at få ventestatistik. Standardscriptet, som mange af os bruger, fungerer stadig, men det trækker ventestatistikker for den container, som din database kører i. Disse ventetider gælder stadig for dit system, men kan omfatte ventetider, der er påløbet af andre databaser i samme container. Azure SQL Database indeholder en ny DMV, sys.dm_db_wait_stats , som filtrerer til den aktuelle database. Hvis du er ligesom mig og primært bruger Paul's wait stats script, der udelader alle de godartede ventetider, skal du bare ændre sys.dm_os_wait_stats til sys.dm_db_wait_stats . Den samme ændring fungerer også for vente-over-en-periode-af-tids-scriptet, men du skal også foretage ændringen fra globale variabler til lokale.
Når det kommer til at finde højprisforespørgsler, finder et af mine yndlingsscripts at køre de mest brugte eksekveringsplaner. Min erfaring er, at tuning af en forespørgsel, der kaldes 100.000 gange om dagen, normalt er en større gevinst end at finjustere en forespørgsel, der har den højeste IO, men kun køres én gang om ugen. Følgende forespørgsel er, hvad jeg bruger til at finde de mest brugte planer:
VÆLG usecounts , cacheobjtype , objtype , [text]FRA sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle) HVOR usecounts> 1 OG objtype IN (N'Adhoc', N'Prepared BY'counts)sOR DESCEDBY' før>Når jeg bruger denne forespørgsel i demoer, tømmer jeg altid min plancache for at nulstille værdierne. Da jeg prøvede at køre
DBCC FREEPROCCACHEi Azure SQL Database fik jeg følgende fejl:Det viser sig, at
SQL Azure understøtter i øjeblikket ikke DBCC FREEPROCCACHE (Transact-SQL), så du kan ikke manuelt fjerne en eksekveringsplan fra cachen. Men hvis du foretager ændringer i tabellen eller visningen, der refereres til af forespørgslen (ALTER TABLE og ALTER VIEW), vil planen blive fjernet fra cachen.DBCC FREEPROCCACHEunderstøttes ikke i Azure SQL Database. Dette var bekymrende for mig, hvad nu hvis jeg er i produktion og har nogle dårlige planer og vil rydde procedurecachen, som jeg kan med boksversionen. Lidt Google/Bing-forskning førte mig til at finde Microsoft-artiklen "Understanding the Procedure Cache on SQL Azure," som siger:Ved at diskutere dette med Kimberly Tripp efter ikke at have set den beskrevne adfærd, fjerner den ikke planen fra cachen, men den ugyldiggør planen (og så vil planen til sidst blive ældet ud af cachen). Selvom dette er nyttigt i visse situationer, var det ikke, hvad jeg havde brug for. Til min demo ønskede jeg at nulstille tællerne i sys.dm_exec_cached_plans. At generere en ny plan ville ikke give mig de ønskede resultater. Jeg kontaktede mit team, og Glenn Berry bad mig prøve følgende script:
ALTER DATABASE SCOPED CONFIGURATION RYD PROCEDURE_CACHE;Denne kommando virkede; Jeg var i stand til at rydde procedurecachen for den specifikke database. Database Scoped Configurations er en ny funktion tilføjet i SQL Server 2016 RC0; Glenn bloggede om det her:Brug af ALTER DATABASE SCOPED CONFIGURATION i SQL Server 2016.
Jeg er spændt på at flytte flere af mine egne databaser ind i Azure SQL Database og fortsætte med at lære om de nye funktioner og skalerbarhedsmuligheder. Jeg ser også frem til at arbejde med SentryOne DB Sentry, en nylig tilføjelse til SentryOne-platformen. Jeg er mest interesseret i at eksperimentere med DTU Usage dashboardet, som Mike Wood beskrev i sit seneste indlæg.