For næsten et år siden i dag postede jeg min løsning til paginering i SQL Server, som indebar at bruge en CTE til kun at finde nøgleværdierne for det pågældende sæt af rækker og derefter slutte tilbage fra CTE til kildetabellen for at hente de andre kolonner for netop den "side" af rækker. Dette viste sig at være mest fordelagtigt, når der var et smalt indeks, der understøttede den bestilling, som brugeren havde anmodet om, eller når bestillingen var baseret på clustering-nøglen, men endda klarede sig lidt bedre uden et indeks til at understøtte den påkrævede sortering.
Siden da har jeg spekuleret på, om ColumnStore-indekser (både klyngede og ikke-klyngede) kunne hjælpe nogen af disse scenarier. TL;DR :Baseret på dette eksperiment isoleret set er svaret på titlen på dette indlæg et rungende NEJ . Hvis du ikke ønsker at se testopsætningen, koden, udførelsesplanerne eller graferne, er du velkommen til at springe til mit resumé, mens du husker på, at min analyse er baseret på en meget specifik use case.
Opsætning
På en ny VM med SQL Server 2016 CTP 3.2 (13.0.900.73) installeret, kørte jeg gennem nogenlunde samme opsætning som før, kun denne gang med tre tabeller. Først en traditionel tabel med en smal klyngenøgle og flere understøttende indekser:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Dernæst en tabel med et klynget ColumnStore-indeks:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Og endelig en tabel med et ikke-klynget ColumnStore-indeks, der dækker alle kolonnerne:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Bemærk, at for begge tabeller med ColumnStore-indekser udelod jeg det indeks, der ville understøtte hurtigere søgninger på "Telefonbog"-sorteringen (efternavn, fornavn).
Testdata
Jeg udfyldte derefter den første tabel med 1.000.000 tilfældige rækker, baseret på et script, jeg har genbrugt fra tidligere indlæg:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Så brugte jeg den tabel til at udfylde de to andre med nøjagtig de samme data, og genopbyggede alle indekserne:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Den samlede størrelse af hver tabel:
| Tabel | Reserveret | Data | Indeks |
|---|---|---|---|
| Kunder | 463.200 KB | 154.344 KB | 308.576 KB |
| Customers_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Customers_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
Og rækkeantallet/sidetallet for de relevante indekser (det unikke indeks på e-mail var der mere for mig at passe mit eget datagenereringsscript end noget andet):
| Tabel | Indeks | Rækker | Sider |
|---|---|---|---|
| Kunder | PK_Kunder | 1.000.000 | 19.377 |
| Kunder | Telefonbog_Kunder | 1.000.000 | 17.209 |
| Kunder | Active_Customers | 808.012 | 13.977 |
| Customers_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Customers_CCI | Customers_CCI | 1.000.000 | 3.826 |
| Customers_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Customers_NCCI | Customers_NCCI | 1.000.000 | 16.971 |
Procedurer
Så, for at se, om ColumnStore-indekserne ville slå ind og gøre nogen af scenarierne bedre, kørte jeg det samme sæt forespørgsler som før, men nu mod alle tre tabeller. Jeg blev i det mindste en lille smule klogere og lavede to lagrede procedurer med dynamisk SQL for at acceptere tabelkilden og sorteringsrækkefølgen. (Jeg er godt klar over SQL-injektion; det er ikke, hvad jeg ville gøre i produktionen, hvis disse strenge kom fra en slutbruger, så tag det ikke som en anbefaling at gøre det. Jeg stoler lige nok på mig selv i min lukket miljø, at det ikke er et problem for disse tests.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Så lavede jeg noget mere dynamisk SQL for at generere alle de kombinationer af opkald, jeg skulle foretage for at kalde både de gamle og nye lagrede procedurer, i alle tre af de ønskede sorteringsrækkefølger og på forskellige sidetal (for at simulere behov en side nær begyndelsen, midten og slutningen af sorteringsrækkefølgen). Så jeg kunne kopiere PRINT output og indsæt det i SQL Sentry Plan Explorer for at få runtime-metrics, jeg kørte denne batch to gange, én gang med procedures CTE ved hjælp af P_Old , og derefter igen ved at bruge P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Dette producerede output som dette (36 kalder i alt for den gamle metode (P_Old ), og 36 kalder på den nye metode (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Jeg ved, det hele er meget besværligt; vi kommer snart til punchline, det lover jeg.
Resultater
Jeg tog disse to sæt med 36 sætninger og startede to nye sessioner i Plan Explorer, hvor jeg kørte hvert sæt flere gange for at sikre, at vi fik data fra en varm cache og tog gennemsnit (jeg kunne også sammenligne kold og varm cache, men jeg tror, der er nok variable her).
Jeg kan umiddelbart fortælle dig et par simple fakta uden overhovedet at vise dig understøttende grafer eller planer:
- I intet tilfælde slog den "gamle" metode den nye CTE-metode Jeg promoverede i mit tidligere indlæg, uanset hvilken type indekser der var til stede. Så det gør det nemt næsten at ignorere halvdelen af resultaterne, i det mindste med hensyn til varighed (som er den metriske slutbrugere bekymrer sig mest om).
- Intet ColumnStore-indeks klarede sig godt, når man bladrede mod slutningen af resultatet – de gav kun fordele i begyndelsen, og kun i et par tilfælde.
- Når du sorterer efter den primære nøgle (grupperet eller ej), tilstedeværelsen af ColumnStore-indekser hjalp ikke – igen med hensyn til varighed.
Med disse resuméer af vejen, lad os tage et kig på nogle få tværsnit af varighedsdataene. Først resultaterne af forespørgslen sorteret efter fornavn faldende, derefter e-mail, uden håb om at bruge et eksisterende indeks til sortering. Som du kan se i diagrammet, var ydeevnen inkonsekvent – ved lavere sidetal klarede den ikke-klyngede ColumnStore sig bedst; ved højere sidetal vandt det traditionelle indeks altid:
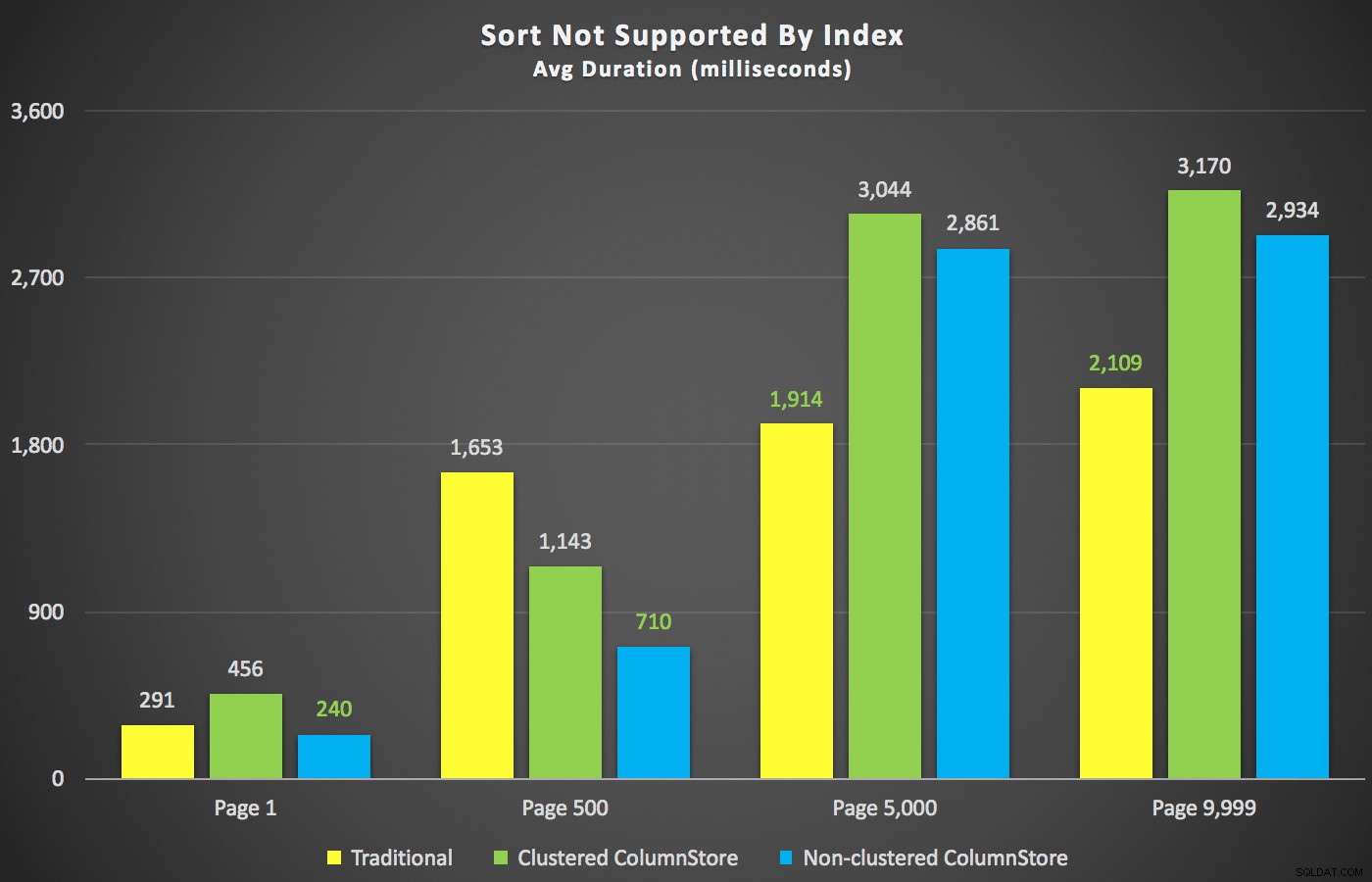 Varighed (millisekunder) for forskellige sidetal og forskellige indekstyper
Varighed (millisekunder) for forskellige sidetal og forskellige indekstyper
Og så de tre planer, der repræsenterer de tre forskellige typer indekser (med gråtoner tilføjet af Photoshop for at fremhæve de store forskelle mellem planerne):
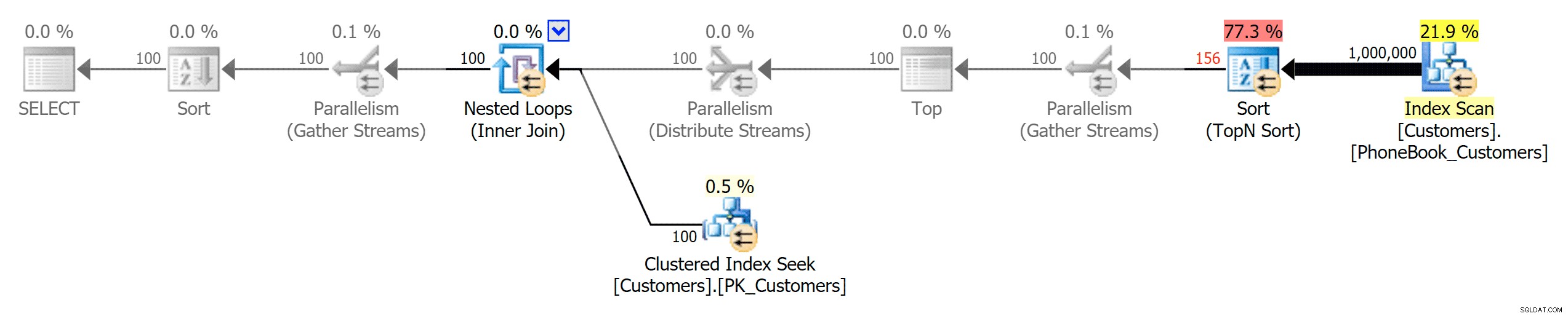 Plan for traditionelt indeks
Plan for traditionelt indeks
 Plan for klynget ColumnStore-indeks
Plan for klynget ColumnStore-indeks
 Plan for ikke-klyngede ColumnStore-indeks
Plan for ikke-klyngede ColumnStore-indeks
Et scenarie, jeg var mere interesseret i, selv før jeg begyndte at teste, var tilgangen til telefonbogssortering (efternavn, fornavn). I dette tilfælde var ColumnStore-indekserne faktisk ret skadelige for resultatets ydeevne:
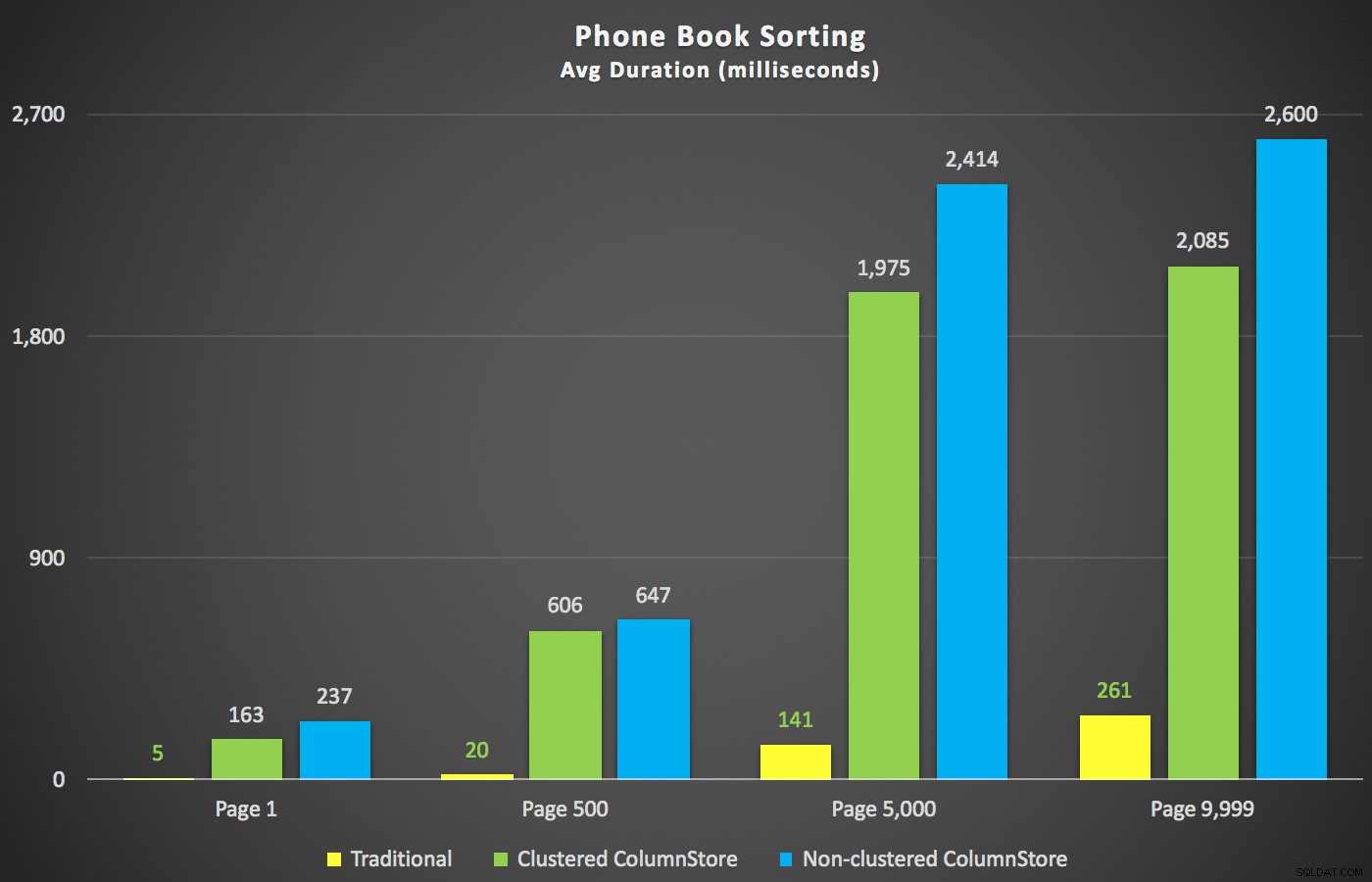
ColumnStore-planerne her er næsten spejlbilleder til de to ColumnStore-planer vist ovenfor for den ikke-understøttede sortering. Årsagen er den samme i begge tilfælde:dyre scanninger eller sorteringer på grund af mangel på et sorteringsunderstøttende indeks.
Så dernæst oprettede jeg understøttende "Telefonbog"-indekser på tabellerne med ColumnStore-indekserne også for at se, om jeg kunne lokke en anden plan og/eller hurtigere eksekveringstider i nogen af disse scenarier. Jeg oprettede disse to indekser og genopbyggede derefter igen:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Her var de nye varigheder:
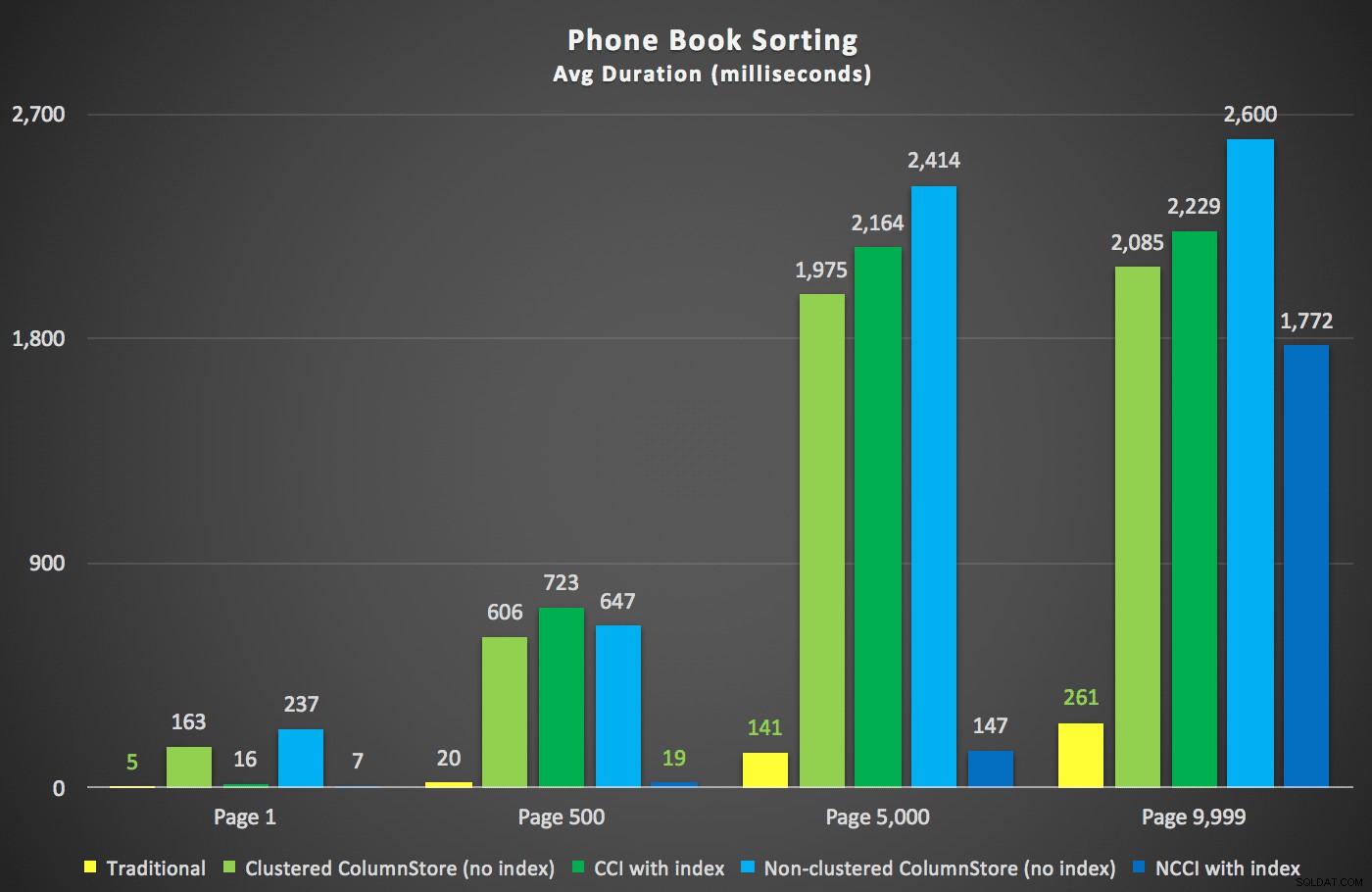
Det mest interessante her er, at nu ser sidesøgningsforespørgslen mod tabellen med det ikke-klyngede ColumnStore-indeks ud til at holde trit med det traditionelle indeks, indtil vi kommer ud over midten af tabellen. Ser vi på planerne, kan vi se, at på side 5.000 bruges en traditionel indeksscanning, og ColumnStore-indekset ignoreres fuldstændigt:
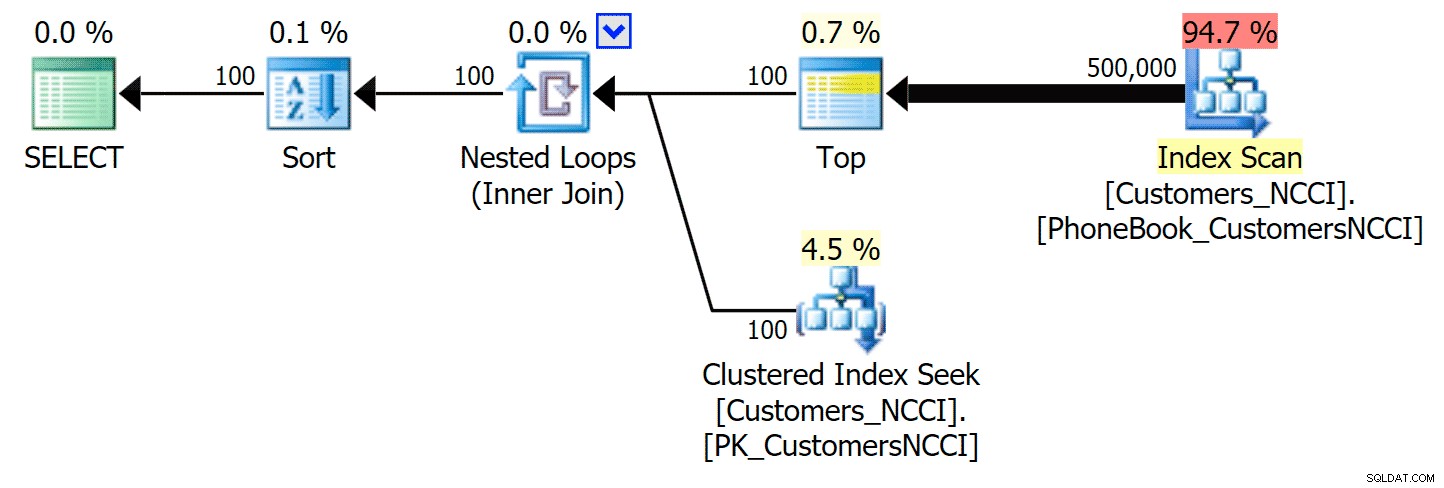 Telefonbogsplan ignorerer det ikke-klyngede ColumnStore-indeks
Telefonbogsplan ignorerer det ikke-klyngede ColumnStore-indeks
Men et sted mellem midtpunktet på 5.000 sider og "slutningen" af tabellen på 9.999 sider, har optimeringsværktøjet ramt en slags vippepunkt og vælger – for nøjagtig samme forespørgsel – nu at scanne det ikke-klyngede ColumnStore-indeks :
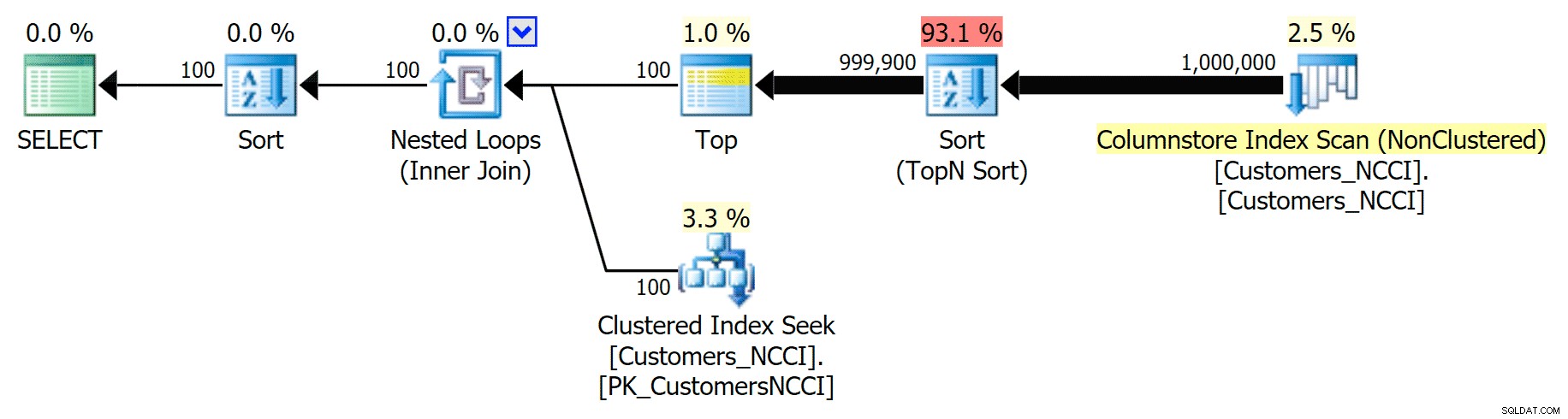 Tip til telefonbogsplan og bruger ColumnStore-indekset
Tip til telefonbogsplan og bruger ColumnStore-indekset
Dette viser sig at være en knap så god beslutning af optimeringsværktøjet, primært på grund af omkostningerne ved sorteringsoperationen. Du kan se, hvor meget bedre varigheden bliver, hvis du antyder det almindelige indeks:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Dette giver følgende plan, næsten identisk med den første plan ovenfor (en lidt højere pris for scanningen, dog simpelthen fordi der er mere output):
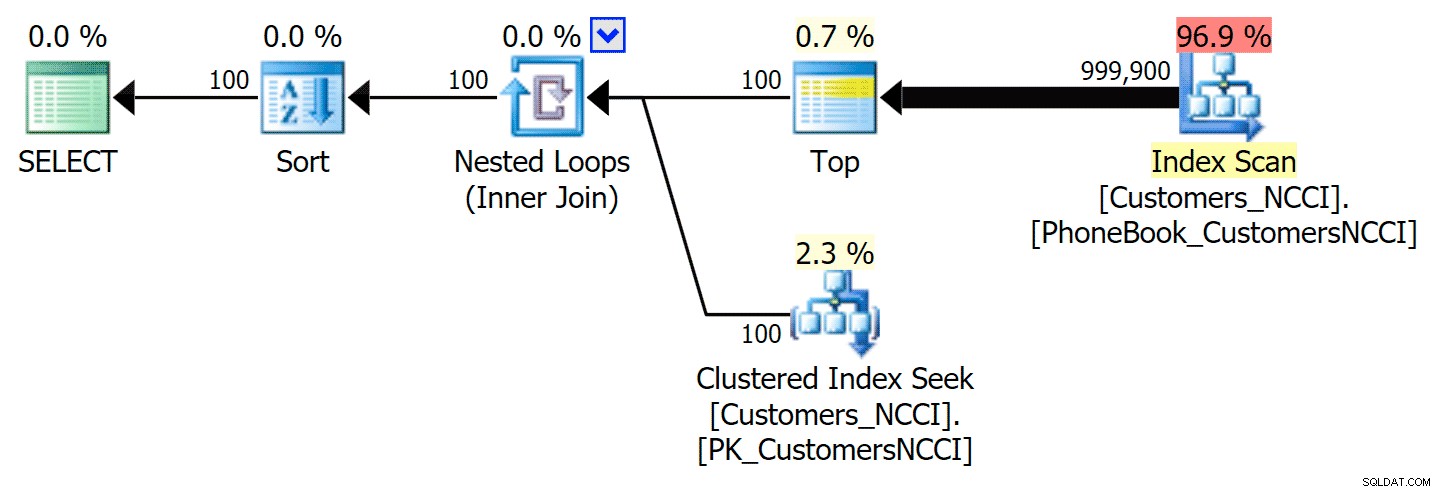 Telefonbogsplan med antydet indeks
Telefonbogsplan med antydet indeks
Du kan opnå det samme ved at bruge OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) i stedet for det eksplicitte indekstip. Bare husk på, at dette er det samme som ikke at have ColumnStore-indekset der i første omgang.
Konklusion
Selvom der er et par kantsager ovenfor, hvor et ColumnStore-indeks (næppe) kan betale sig, forekommer det mig ikke, at de passer godt til dette specifikke pagineringsscenarie. Jeg tror, vigtigst af alt, mens ColumnStore viser betydelige pladsbesparelser på grund af komprimering, er runtime-ydeevnen ikke fantastisk på grund af sorteringskravene (selvom disse sorteringer anslås at køre i batch-tilstand, en ny optimering til SQL Server 2016).
Generelt kunne dette gøre med en hel del mere tid brugt på forskning og test; i piggy-backing off af tidligere artikler, jeg ønskede at ændre så lidt som muligt. Jeg ville elske at finde det vendepunkt, for eksempel, og jeg vil også gerne erkende, at disse ikke ligefrem er massive tests (på grund af VM-størrelse og hukommelsesbegrænsninger), og at jeg lod dig gætte på en masse runtime-metrikkene (mest for kortheds skyld, men jeg ved ikke, at et diagram over læsninger, der ikke altid er proportionale med varigheden, virkelig ville fortælle dig). Disse tests forudsætter også luksusen ved SSD'er, tilstrækkelig hukommelse, en altid varm cache og et enkeltbrugermiljø. Jeg vil virkelig gerne udføre et større batteri af tests mod flere data, på større servere med langsommere diske og instanser med mindre hukommelse, hele tiden med simuleret samtidighed.
Når det er sagt, kan dette også bare være et scenarie, som ColumnStore ikke er designet til at hjælpe med at løse i første omgang, da den underliggende løsning med traditionelle indekser allerede er ret effektiv til at trække et smalt sæt rækker ud – ikke ligefrem ColumnStores styrehus. Måske er en anden variabel, der skal tilføjes til matricen, sidestørrelsen – alle testene ovenfor trækker 100 rækker ad gangen, men hvad nu hvis vi er efter 10.000 eller 100.000 rækker ad gangen, uanset hvor stor den underliggende tabel er?
Har du en situation, hvor din OLTP-arbejdsbyrde blev forbedret blot ved at tilføje ColumnStore-indekser? Jeg ved godt, at de er designet til datavarehus-lignende arbejdsbelastninger, men hvis du har set fordele andre steder, vil jeg meget gerne høre om dit scenarie og se, om jeg kan inkorporere nogen differentiatorer i min testrig.