Baggrund
En af de første ting, jeg ser på, når jeg fejlfinder et ydelsesproblem, er ventestatistikker via sys.dm_os_wait_stats DMV. For at se, hvad SQL Server venter på, bruger jeg forespørgslen fra Glenn Berrys nuværende sæt af SQL Server Diagnostic Queries. Afhængigt af outputtet begynder jeg at grave i specifikke områder inden for SQL Server.
Som et eksempel, hvis jeg ser høje CXPACKET-ventinger, tjekker jeg antallet af kerner på serveren, antallet af NUMA-noder og værdierne for max grad af parallelitet og omkostningstærskel for parallelisme. Dette er baggrundsinformation, som jeg bruger til at forstå konfigurationen. Inden jeg overhovedet overvejer at foretage ændringer, samler jeg mere kvantitative data, da et system med CXPACKET venter ikke nødvendigvis har en forkert indstilling for max grad af parallelitet.
Tilsvarende har et system, der har høje ventetider på I/O-relaterede ventetyper, såsom PAGEIOLATCH_XX, WRITELOG og IO_COMPLETION, ikke nødvendigvis et ringere lagerundersystem. Når jeg ser I/O-relaterede ventetyper, mens toppen venter, vil jeg straks gerne forstå mere om den underliggende opbevaring. Er det direkte tilsluttet lager eller et SAN? Hvad er RAID-niveauet, hvor mange diske findes der i arrayet, og hvad er hastigheden på diskene? Jeg vil også gerne vide, om andre filer eller databaser deler lageret. Og selvom det er vigtigt at forstå konfigurationen, er et logisk næste skridt at se på virtuelle filstatistik via sys.dm_io_virtual_file_stats DMV.
Introduceret i SQL Server 2005, er denne DMV en erstatning for funktionen fn_virtualfilestats, som de af jer, der kørte på SQL Server 2000 og tidligere, sikkert kender og elsker. DMV'en indeholder kumulative I/O-oplysninger for hver databasefil, men dataene nulstilles ved genstart af forekomsten, når en database lukkes, tages offline, frakobles og vedhæftes igen osv. Det er vigtigt at forstå, at statistiske data for virtuelle filer ikke er repræsentative for nuværende performance – det er et øjebliksbillede, der er en aggregering af I/O-data siden sidste clearing af en af de førnævnte hændelser. Selvom dataene ikke er tidspunkter, kan de stadig være nyttige. Hvis de højeste ventetider på en forekomst er I/O-relaterede, men den gennemsnitlige ventetid er mindre end 10 ms, er lagring sandsynligvis ikke et problem – men at korrelere outputtet med det, du ser i sys.dm_io_virtual_stats, er stadig umagen værd at bekræfte lav ventetider. Yderligere, selvom du ser høje forsinkelser i sys.dm_io_virtual_stats, har du stadig ikke bevist, at lagring er et problem.
Opsætningen
For at se på virtuel filstatistik har jeg oprettet to kopier af AdventureWorks2012-databasen, som du kan downloade fra Codeplex. Til det første eksemplar, herefter kendt som EX_AdventureWorks2012, kørte jeg Jonathan Kehayias' script for at udvide tabellerne Sales.SalesOrderHeader og Sales.SalesOrderDetail til henholdsvis 1,2 millioner og 4,9 millioner rækker. Til den anden database, BIG_AdventureWorks2012, brugte jeg scriptet fra mit tidligere partitioneringsindlæg til at oprette en kopi af Sales.SalesOrderHeader-tabellen med 123 millioner rækker. Begge databaser blev gemt på et eksternt USB-drev (Seagate Slim 500GB), med tempdb på min lokale disk (SSD).
Før testning oprettede jeg fire brugerdefinerede lagrede procedurer i hver database (Create_Custom_SPs.zip), som ville fungere som min "normale" arbejdsbyrde. Min testproces var som følger for hver database:
- Genstart forekomsten.
- Optag virtuelle filstatistik.
- Kør den "normale" arbejdsbelastning i to minutter (procedurer kaldet gentagne gange via et PowerShell-script).
- Optag virtuelle filstatistik.
- Genopbyg alle indekser for den eller de relevante salgsordretabeller.
- Optag virtuelle filstatistik.
Dataene
For at fange virtuelle filstatistik oprettede jeg en tabel til at indeholde historisk information og brugte derefter en variation af Jimmy Mays forespørgsel fra hans DMV All-Stars-script til snapshot:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Jeg genstartede forekomsten og fangede derefter filstatistik med det samme. Da jeg filtrerede outputtet til kun at se EX_AdventureWorks2012- og tempdb-databasefilerne, blev der kun fanget tempdb-data, da der ikke var blevet anmodet om data fra EX_AdventureWorks2012-databasen:

Output fra indledende registrering af sys.dm_os_virtual_file_stats
Jeg kørte derefter den "normale" arbejdsbyrde i to minutter (antallet af udførelser af hver lagret procedure varierede lidt), og efter at den var fuldført, fangede jeg filstatistik igen:

Output fra sys.dm_os_virtual_file_stats efter normal arbejdsbelastning
Vi ser en latenstid på 57ms for EX_AdventureWorks2012-datafilen. Ikke ideelt, men over tid med min normale arbejdsbyrde ville dette nok udligne sig. Der er minimal latenstid for tempdb, hvilket forventes, da den arbejdsbyrde, jeg kørte, ikke genererer meget tempdb-aktivitet. Dernæst genopbyggede jeg alle indekser for tabellerne Sales.SalesOrderHeaderEnlarged og Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Genopbygningerne tog mindre end et minut, og læg mærke til stigningen i læselatens for EX_AdventureWorks2012-datafilen og stigningerne i skrivelatens for EX_AdventureWorks2012-dataene og logfiler:

Output fra sys.dm_os_virtual_file_stats efter genopbygning af indeks
Ifølge det øjebliksbillede af filstatistik er latenstiden forfærdelig; over 600ms for at skrive! Hvis jeg så denne værdi for et produktionssystem, ville det være let umiddelbart at få mistanke om problemer med opbevaring. Det er dog også værd at bemærke, at AvgBPerWrite også steg, og større blokskrivninger tager længere tid at fuldføre. AvgBPerWrite-stigningen forventes for indeksgenopbygningsopgaven.
Forstå, at når du ser på disse data, får du ikke et komplet billede. En bedre måde at se på latenstider ved hjælp af virtuelle filstatistik er at tage snapshots og derefter beregne latens for den forløbne tidsperiode. For eksempel bruger scriptet nedenfor to snapshots (aktuelt og tidligere) og beregner derefter antallet af læsninger og skrivninger i denne tidsperiode, forskellen i io_stall_read_ms og io_stall_write_ms værdier og dividerer derefter io_stall_read_ms delta med antallet af læsninger og io_stall_write_ms med delta antal skriverier. Med denne metode beregner vi mængden af tid, SQL Server ventede på I/O for læsning eller skrivning, og dividerer det derefter med antallet af læsninger eller skrivninger for at bestemme latens.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Når vi udfører dette for at beregne latens under indeksgenopbygningen, får vi følgende:

Latens beregnet ud fra sys.dm_io_virtual_file_stats under index2_0AdventureW for index2_0AdventureW em>
Nu kan vi se, at den faktiske latency i det tidsrum var høj – hvilket vi ville forvente. Og hvis vi derefter gik tilbage til vores normale arbejdsbyrde og kørte den i et par timer, ville de gennemsnitlige værdier beregnet ud fra virtuelle filstatistik falde over tid. Faktisk, hvis vi ser på PerfMon-data, som blev fanget under testen (og derefter behandlet gennem PAL), ser vi betydelige stigninger i Gns. Disk sek/Læs og Gns. Disk sec/Write, som korrelerer med det tidspunkt, hvor indeksgenopbygningen kørte. Men på andre tidspunkter er latensværdierne et godt stykke under acceptable værdier:
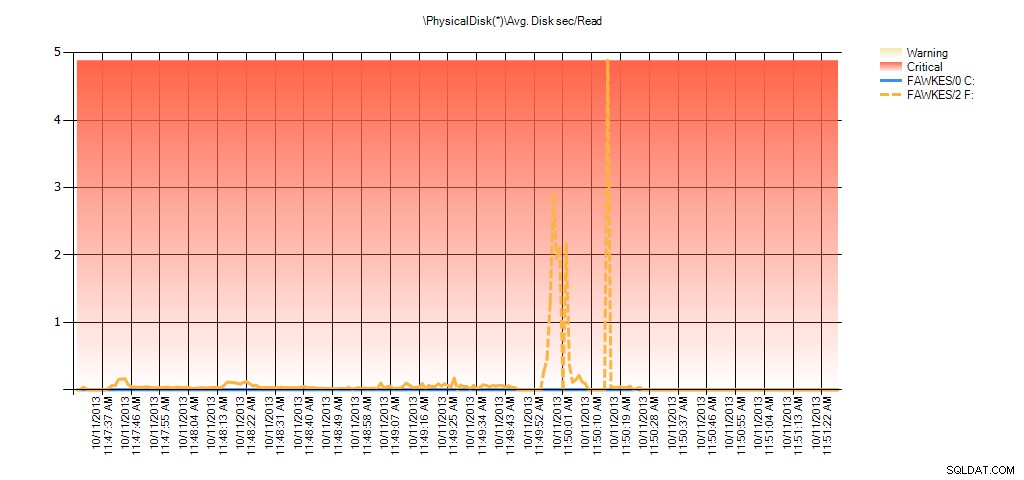
Oversigt over gns. disksek./læst fra PAL til EX_AdventureWorks2012 under test
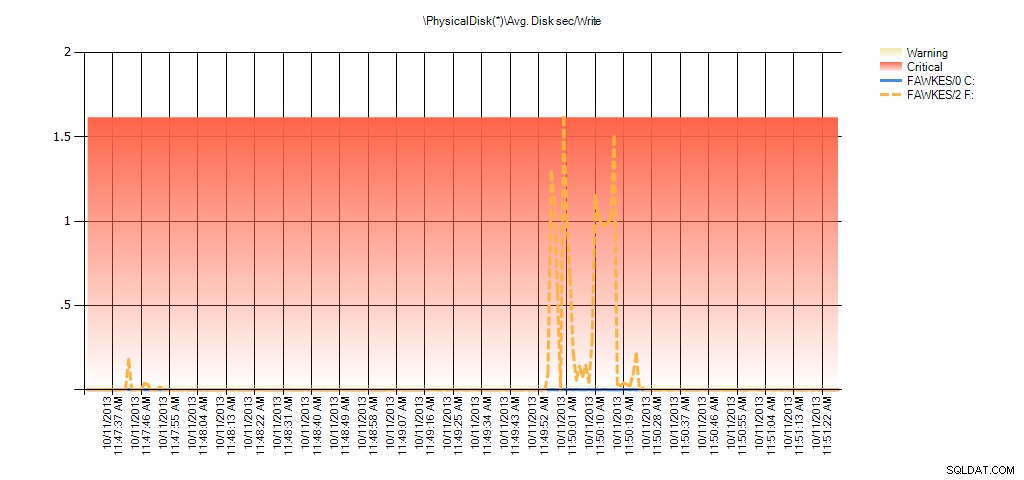
Oversigt over gns. disksek./skriv fra PAL til EX_AdventureWorks2012 under test
Du kan se den samme adfærd for BIG_AdventureWorks 2012-databasen. Her er latensinformationen baseret på det virtuelle filstatistik-øjebliksbillede før indeksgenopbygningen og efter:

Latens beregnet ud fra sys.dm_io_virtual_file_stats under index rebuild eller BIG2_0Adventure em>
Og Performance Monitor-data viser de samme spidser under genopbygningen:
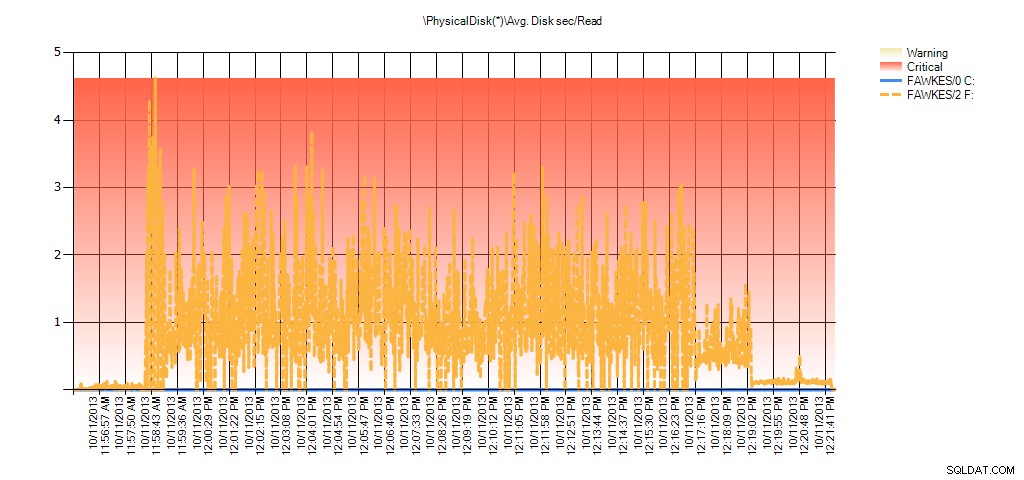
Sammendrag af gns. disksek./læst fra PAL til BIG_AdventureWorks2012 under test
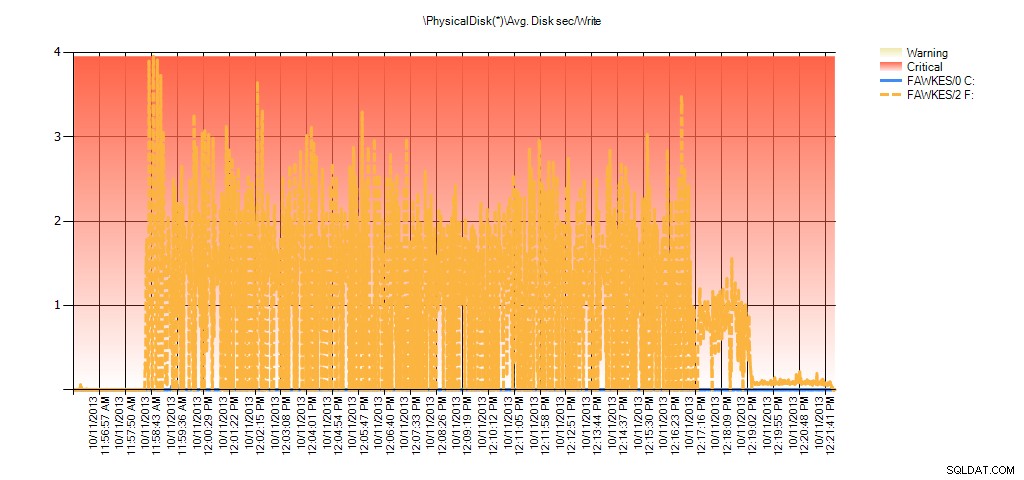
Sammendrag af gns. disksek./skriv fra PAL til BIG_AdventureWorks2012 under test
Konklusion
Virtuelle filstatistik er et godt udgangspunkt, når du vil forstå I/O-ydeevne for en SQL Server-instans. Hvis du ser I/O-relaterede ventetider, når du ser på ventestatistikker, er det et logisk næste skridt at se på sys.dm_io_virtual_file_stats. Du skal dog forstå, at de data, du ser, er et aggregat siden statistikken sidst blev ryddet af en af de tilknyttede hændelser (forekomstgenstart, offline af database osv.). Hvis du ser lave latenser, så følger I/O-undersystemet med ydelsesbelastningen. Men hvis du ser høje latenser, er det ikke en selvfølge, at lagring er et problem. For virkelig at vide, hvad der foregår, kan du begynde at tage snapshot-filstatistik, som vist her, eller du kan simpelthen bruge Performance Monitor til at se på latency i realtid. Det er meget nemt at oprette et dataindsamlersæt i PerfMon, der fanger de fysiske disktællere Gns. Disk Sec/Læs og Gns. Disk Sec/Read for alle diske, der er vært for databasefiler. Planlæg dataindsamleren til at starte og stoppe med jævne mellemrum, og prøv hver n sekunder (f.eks. 15), og når du har fanget PerfMon-data i et passende tidspunkt, skal du køre dem gennem PAL for at undersøge latens over tid.
Hvis du opdager, at I/O-forsinkelse opstår under din normale arbejdsbyrde og ikke kun under vedligeholdelsesopgaver, der driver I/O, stadig kan ikke pege på opbevaring som det underliggende problem. Lagerforsinkelse kan eksistere af en række forskellige årsager, såsom:
- SQL Server skal læse for mange data som følge af ineffektive forespørgselsplaner eller manglende indekser
- For lidt hukommelse er allokeret til instansen, og de samme data læses fra disken igen og igen, fordi den ikke kan forblive i hukommelsen
- Implicitte konverteringer forårsager indeks- eller tabelscanninger
- Forespørgsler udfører SELECT *, når ikke alle kolonner er nødvendige
- Problemer med videresendt registrering i dynger forårsager yderligere I/O
- Lav sidetæthed fra indeksfragmentering, sideopdelinger eller forkerte fyldfaktorindstillinger forårsager yderligere I/O
Uanset hvad årsagen er, er det væsentlige at forstå om ydeevne – især hvad angår I/O – at der sjældent er ét datapunkt, som du kan bruge til at lokalisere problemet. At finde det sande problem kræver flere fakta, som, når de er sat sammen, hjælper dig med at afdække problemet.
Bemærk endelig, at lagringsforsinkelsen i nogle tilfælde kan være fuldstændig acceptabel. Før du kræver hurtigere lagring eller ændringer af kode, skal du gennemgå arbejdsbelastningsmønstrene og Service Level Agreement (SLA) for databasen. I tilfælde af et datavarehus, som servicerer rapporter til brugere, er SLA'en for forespørgsler sandsynligvis ikke de samme værdier på under-sekunder, som du ville forvente for et OLTP-system med høj volumen. I DW-løsningen kan I/O-forsinkelser på mere end et sekund være helt acceptabel og forventet. Forstå forventningerne til virksomheden og dens brugere, og afgør derefter, hvilken handling, hvis nogen, der skal tages. Og hvis ændringer er påkrævet, skal du indsamle de kvantitative data, du har brug for til at understøtte dit argument, nemlig ventestatistikker, virtuelle filstatistikker og forsinkelser fra Performance Monitor.