Tilbage i januar 2015 skrev min gode ven og kollega SQL Server MVP Rob Farley om en ny løsning på problemet med at finde medianen i SQL Server-versioner før 2012. Ud over at være en interessant læsning i sig selv, viser det sig at være et godt eksempel at bruge til at demonstrere nogle avancerede eksekveringsplananalyser og til at fremhæve nogle subtile adfærd i forespørgselsoptimerings- og eksekveringsmotoren.
Enkelt median
Selvom Robs artikel specifikt er rettet mod en grupperet medianberegning, vil jeg starte med at anvende hans metode på et stort enkelt medianberegningsproblem, fordi den fremhæver de vigtige spørgsmål tydeligst. Eksempeldataene kommer igen fra Aaron Bertrands originale artikel:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Anvendelse af Rob Farleys teknik på dette problem giver følgende kode:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Som sædvanlig har jeg kommenteret ud at tælle antallet af rækker i tabellen og erstattet det med en konstant for at undgå en kilde til præstationsafvigelse. Udførelsesplanen for den vigtige forespørgsel er som følger:

Denne forespørgsel kører i 5800ms på min testmaskine.
Sortspildet
Den primære årsag til denne dårlige ydeevne burde være klar ved at se på udførelsesplanen ovenfor:Advarslen på Sort-operatøren viser, at en utilstrækkelig arbejdsområdehukommelse forårsagede et niveau 2 (multi-pass) spild til fysisk tempdb disk:
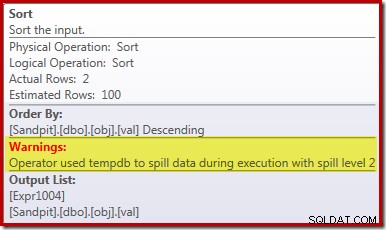
I versioner af SQL Server før 2012 skal du overvåge særskilt for sorteringsspildhændelser for at se dette. Under alle omstændigheder er den utilstrækkelige sorteringshukommelsesreservation forårsaget af en kardinalitetsestimateringsfejl, som den forudgående (estimerede) plan viser:

Kardinalitetsestimatet på 100 rækker ved sorteringsinputtet er et (vildt unøjagtigt) gæt fra optimeringsværktøjet på grund af det lokale variabeludtryk i den foregående Topoperator:

Bemærk, at denne fejl ved estimering af kardinalitet ikke er et rækkemålsproblem. Anvendelse af sporingsflag 4138 vil fjerne rækkemålseffekten under den første Top, men post-Top-estimatet vil stadig være et gæt på 100 rækker (så hukommelsesreservationen for sorteringen vil stadig være alt for lille):

Antydning af værdien af den lokale variabel
Der er flere måder, hvorpå vi kan løse dette problem med estimering af kardinalitet. En mulighed er at bruge et tip til at give optimizeren information om værdien i variablen:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Brug af tippet forbedrer ydeevnen til 3250ms fra 5800 ms. Efterudførelsesplanen viser, at sorteringen ikke længere spilder:

Der er dog et par ulemper ved dette. For det første kræver denne nye eksekveringsplan en 388 MB memory grant – hukommelse, som ellers kunne bruges af serveren til at cache planer, indekser og data:
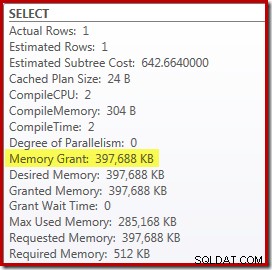
For det andet kan det være svært at vælge et godt tal for hintet, som vil fungere godt for alle fremtidige henrettelser uden at reservere hukommelse unødigt.
Bemærk også, at vi var nødt til at antyde en værdi for variablen, der er 10 % højere end den faktiske værdi af variablen for at eliminere spildet fuldstændigt. Dette er ikke ualmindeligt, fordi den generelle sorteringsalgoritme er noget mere kompleks end en simpel sortering på stedet. At reservere hukommelse svarende til størrelsen af det sæt, der skal sorteres, vil ikke altid (eller endda generelt) være nok til at undgå spild under kørsel.
Indlejring og genkompilering
En anden mulighed er at drage fordel af Parameter Embedding Optimization aktiveret ved at tilføje et rekompileringstip på forespørgselsniveau på SQL Server 2008 SP1 CU5 eller nyere. Denne handling giver optimeringsværktøjet mulighed for at se køretidsværdien af variablen og optimere i overensstemmelse hermed:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Dette forbedrer eksekveringstiden til 3150ms – 100 ms bedre end at bruge OPTIMIZE FOR antydning. Årsagen til denne yderligere lille forbedring kan ses fra den nye plan efter udførelse:

Udtrykket (2 – @Count % 2) – som tidligere set i den anden Top-operator – kan nu foldes ned til en enkelt kendt værdi. En omskrivning efter optimering kan derefter kombinere Top med Sort, hvilket resulterer i en enkelt Top N Sortering. Denne omskrivning var ikke tidligere mulig, fordi at sammenklappe Top + Sort til en Top N Sort kun fungerer med en konstant bogstavelig topværdi (ikke variable eller parametre).
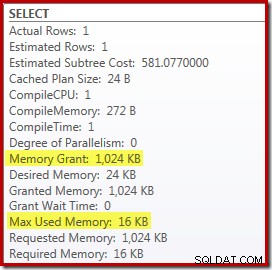
Udskiftning af Top og Sort med en Top N Sort har en lille gavnlig effekt på ydeevnen (100ms her), men det eliminerer også næsten helt hukommelseskravet, fordi en Top N Sort kun skal holde styr på N højeste (eller laveste) rækker i stedet for hele sættet. Som et resultat af denne ændring i algoritme viser efterudførelsesplanen for denne forespørgsel, at minimum 1 MB hukommelse var reserveret til Top N Sort i denne plan, og kun 16KB blev brugt under kørsel (husk, at fuld-sort-planen krævede 388 MB):
Undgå rekompilering
Den (åbenlyse) ulempe ved at bruge genkompileringsforespørgselstip er, at det kræver en fuld kompilering ved hver udførelse. I dette tilfælde er overheaden ret lille – omkring 1 ms CPU-tid og 272 KB hukommelse. Alligevel er der en måde at justere forespørgslen på, så vi får fordelene ved en Top N Sort uden at bruge nogen tip og uden at genkompilere.
Ideen kommer fra at erkende, at et maksimum to rækker kræves til den endelige medianberegning. Det kan være en række, eller det kan være to under kørsel, men det kan aldrig være mere. Denne indsigt betyder, at vi kan tilføje et logisk redundant Top (2) mellemtrin til forespørgslen som følger:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Den nye Top (med den altafgørende konstante bogstaver) betyder, at den endelige udførelsesplan indeholder den ønskede Top N Sort-operator uden omkompilering:

Ydeevnen af denne eksekveringsplan er uændret fra den genkompilerede version ved 3150ms og hukommelseskravet er det samme. Bemærk dog, at manglen på parameterindlejring betyder, at kardinalitetsestimaterne under sorteringen er 100-rækkers gæt (selvom det ikke påvirker ydeevnen her).
Det vigtigste på dette trin er, at hvis du ønsker en Top N Sort med lav hukommelse, skal du bruge en konstant literal eller aktivere optimeringsværktøjet til at se en literal via parameterindlejringsoptimering.
Beregningsskalaren
Fjernelse af 388 MB hukommelsesbevilling (samtidig med en forbedring på 100ms ydeevne) er bestemt umagen værd, men der er en meget større præstationsgevinst tilgængelig. Det usandsynlige mål for denne endelige forbedring er Compute Scalar lige over Clustered Index Scan.
Denne beregningsskalar relaterer sig til udtrykket (0E + f.val) indeholdt i AVG samlet i forespørgslen. Hvis det ser mærkeligt ud for dig, er dette et ret almindeligt trick til at skrive forespørgsler (som at gange med 1,0) for at undgå heltalsregning i gennemsnitsberegningen, men det har nogle meget vigtige bivirkninger.
Der er en bestemt række af begivenheder her, som vi skal følge trin for trin.
Først skal du bemærke, at 0E er et konstant bogstaveligt nul med en float datatype. For at tilføje dette til heltalskolonnen val, skal forespørgselsprocessoren konvertere kolonnen fra heltal til flydende (i overensstemmelse med datatypeforrangsreglerne). En lignende form for konvertering ville være nødvendig, hvis vi havde valgt at gange kolonnen med 1,0 (et bogstav med en implicit numerisk datatype). Det vigtige er, at dette rutinetrick introducerer et udtryk .
Nu forsøger SQL Server generelt at skubbe udtryk ned plantræet så vidt muligt under udarbejdelse og optimering. Dette gøres af flere grunde, herunder for at gøre det lettere at matche udtryk med beregnede kolonner og for at lette forenklinger ved hjælp af begrænsningsoplysninger. Denne push-down-politik forklarer, hvorfor Compute Scalar forekommer meget tættere på planens bladniveau, end den oprindelige tekstmæssige placering af udtrykket i forespørgslen antyder.
En risiko ved at udføre denne push-down er, at udtrykket kan ende med at blive beregnet flere gange end nødvendigt. De fleste planer har et reduceret antal rækker, når vi bevæger os op i plantræet, på grund af effekten af joinforbindelser, aggregering og filtre. At skubbe udtryk ned i træet risikerer derfor at evaluere disse udtryk flere gange (dvs. på flere rækker) end nødvendigt.
For at afbøde dette introducerede SQL Server 2005 en optimering, hvorved Compute Scalars simpelthen kan definere et udtryk, med arbejdet med faktisk at evaluere udtrykket udskudt indtil en senere operatør i planen kræver resultatet. Når denne optimering virker efter hensigten, er effekten at få alle fordelene ved at skubbe udtryk ned i træet, mens man stadig kun faktisk evaluerer udtrykket så mange gange, som det faktisk er nødvendigt.
Hvad alle disse Compute Scalar-ting betyder
I vores kørende eksempel er 0E + val udtryk var oprindeligt forbundet med AVG samlet, så vi kan forvente at se det ved (eller lidt efter) Stream Aggregate. Dette udtryk blev dog skubbet ned træet til at blive en ny Compute Scalar lige efter scanningen, med udtrykket mærket som [Expr1004].
Når vi ser på udførelsesplanen, kan vi se, at [Expr1004] er refereret af Stream Aggregate (Plan Explorer Expressions Fane-ekstrakt vist nedenfor):

Alt andet lige vil evaluering af udtryk [Expr1004] blive udskudt indtil aggregatet har brug for disse værdier til sumdelen af gennemsnitsberegningen. Da aggregatet kun kan støde på en eller to rækker, bør dette resultere i, at [Udtr1004] kun evalueres én eller to gange:
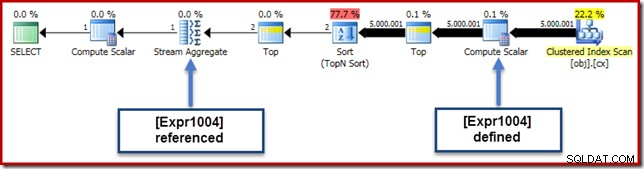
Desværre er det ikke helt sådan det fungerer herude. Problemet er den blokerende sorteringsoperator:
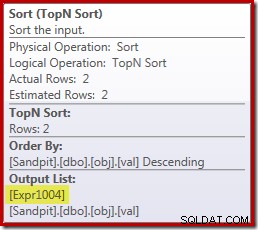
Dette fremtvinger evaluering af [Expr1004], så i stedet for at det kun evalueres en eller to gange ved Stream Aggregate, betyder sorteringen, at vi ender med at konvertere val kolonne til en flyder og tilføjelse af nul til den 5.000.001 gange!
En løsning
Ideelt set ville SQL Server være en smule klogere på alt dette, men sådan fungerer det ikke i dag. Der er ingen forespørgselstip til at forhindre udtryk i at blive skubbet ned i plantræet, og vi kan heller ikke tvinge Compute Scalars med en planguide. Der er uundgåeligt et udokumenteret sporflag, men det er ikke et, jeg ansvarligt kan tale om i den nuværende sammenhæng.
Så på godt og ondt efterlader dette os med at forsøge at finde en forespørgselsomskrivning, der sker for at forhindre, at SQL Server adskiller udtrykket fra aggregatet og skubber det ned forbi sorteringen uden at ændre resultatet af forespørgslen. Dette er ikke så let, som du måske tror, men den (ganske vist lidt mærkelige) modifikation nedenfor opnår dette ved at bruge en CASE udtryk på en ikke-deterministisk iboende funktion:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Udførelsesplanen for denne endelige form for forespørgslen er vist nedenfor:

Bemærk, at en Compute Scalar ikke længere vises mellem Clustered Index Scan og Top. 0E + val udtryk beregnes nu ved Stream Aggregate på maksimalt to rækker (i stedet for fem millioner!), og ydeevnen øges med yderligere 32 % fra 3150 ms til 2150 ms som et resultat.
Dette kan stadig ikke sammenlignes så godt med OFFSET's ydeevne under et sekund og dynamiske cursor median-beregningsløsninger, men det repræsenterer stadig en meget betydelig forbedring i forhold til de oprindelige 5800ms for denne metode på et stort enkelt-median problemsæt.
CASE-tricket er selvfølgelig ikke garanteret at virke i fremtiden. Takeaway handler ikke så meget om at bruge underlige kasusudtrykstricks, som det handler om de potentielle præstationsimplikationer af Compute Scalars. Når du først ved om denne slags ting, kan du tænke dig om to gange, før du multiplicerer med 1,0 eller tilføjer float nul i en gennemsnitsberegning.
Opdatering: se venligst den første kommentar for en god løsning af Robert Heinig, der ikke kræver noget udokumenteret trick. Noget at huske på, når du næste gang bliver fristet til at gange et heltal med decimal (eller flydende) en i et gennemsnitligt aggregat.
Grupperet median
For fuldstændighedens skyld, og for at binde denne analyse tættere tilbage til Robs originale artikel, vil vi slutte af med at anvende de samme forbedringer på en grupperet medianberegning. De mindre sætstørrelser (pr. gruppe) betyder selvfølgelig, at effekterne bliver mindre.
De grupperede medianprøvedata (igen som oprindeligt oprettet af Aaron Bertrand) omfatter ti tusinde rækker for hver af hundrede imaginære sælgere:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Anvendelse af Rob Farleys løsning direkte giver følgende kode, som udføres i 560ms på min maskine.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
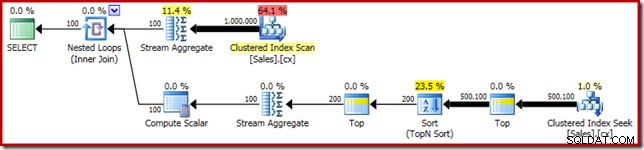
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Udførelsesplanen har åbenlyse ligheder med den enkelte median:
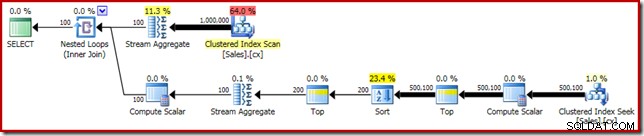
Vores første forbedring er at erstatte Sort med en Top N Sort ved at tilføje en eksplicit Top (2). Dette forbedrer udførelsestiden en smule fra 560 ms til 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Udførelsesplanen viser Top N Sort som forventet:
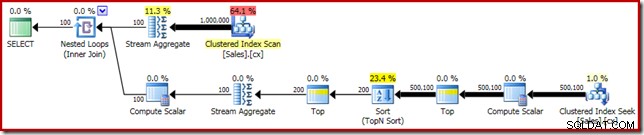
Til sidst implementerer vi det mærkeligt udseende CASE-udtryk for at fjerne det pushede Compute Scalar-udtryk. Dette forbedrer ydeevnen yderligere til 450 ms (en forbedring på 20 % i forhold til originalen):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den færdige udførelsesplan er som følger: