En investering i viden betaler den bedste interesse.
Benjamin Franklin
I den moderne verden er uddannelse allestedsnærværende. Nu mere end nogensinde før spiller det en vigtig rolle i vores samfund. Det er faktisk så vigtigt, at mange af os fortsætter vores uddannelse godt efter at have afsluttet skolen eller college.
Vi har alle hørt om livslang læring, ikke-formel uddannelse og workshops for alle aldre. Disse metoder adskiller sig fra formel uddannelse på mange måder, men de har også ting til fælles. Der er klasser, lektioner, lærere og elever. Og ligesom i et traditionelt miljø vil vi gerne holde styr på klassens tidsplan, fremmødedata og instruktør- eller elevpræstationer. Hvordan kan vi designe en database til at opfylde disse behov? Det er, hvad vi vil dække i denne artikel.
Introduktion af vores uddannelsesdatabasemodel
Modellen præsenteret i denne artikel gør det muligt for os at gemme data om:
- klasser/forelæsninger
- instruktører/undervisere
- studerende
- forelæsningsdeltagelse
- studerendes/undervisernes præstationer
Vi kunne også bruge denne model som en skoleskema, til andre gruppeaktiviteter (svømmeundervisning, danseworkshops) eller endda til en-til-en aktiviteter som vejledning. Der er stadig meget plads til forbedringer, såsom lagring af klasselokalitetsdata eller workshops varighed; vi vil dække disse i kommende artikler.
Lad os komme i gang med vores grundlæggende Education-databaseelementer:tabellerne.
De tre store:elev-, instruktør- og klasseborde
student , instructor og class tabeller udgør kernen i vores database.
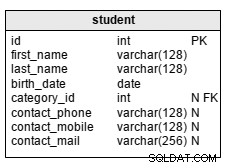
student tabel, vist ovenfor, bruges til at gemme grundlæggende data om elever, men den kan udvides efter specifikke behov. Med undtagelse af de tre kontaktattributter er alle attributter i tabellen obligatoriske:
first_name– elevens navnlast_name– elevens efternavnbirth_date– elevens fødselsdatocontact_phone– elevens telefonnummercontact_mobile– elevens mobiltelefonnummercontact_mail– elevens e-mailadressecategory_id– er en reference tilcategorykatalog. Med denne struktur er vi begrænset til kun én kategori pr. elev. Det virker i de fleste tilfælde, men i nogle situationer kan vi have brug for plads til at angive flere kategorier. Som du kan se, tilføjer du en mange-til-mange-relation, der forbinderstudenttabel medcategoryordbog løser dette problem. I dette scenarie bliver vi dog nødt til at skrive mere komplekse forespørgsler for at håndtere vores data.
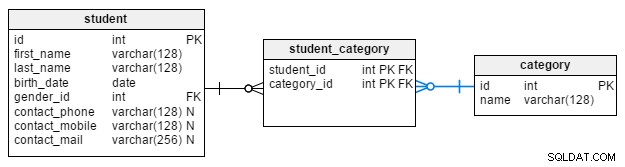
Siden vi har nævnt det, lad os gå videre og diskutere category tabel her.

Denne tabel er en ordbog, der bruges til at gruppere elever ud fra bestemte kriterier. name attribut er de eneste data i tabellen (udover id , den primære nøgle), og det er obligatorisk. Et sæt værdier, der kunne gemmes her, er den studerendes beskæftigelsesstatus:"studerende", "beskæftiget", "arbejdsløs" og "pensioneret". Vi kunne også bruge andre sæt baseret på nogle meget specifikke kriterier, såsom "kan lide yoga", "kan lide at vandre", "kan lide at cykle" og "kan ikke lide noget".
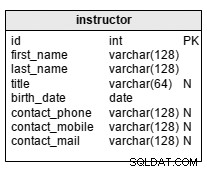
instructor tabel indeholder en liste over alle instruktører/undervisere i organisationen. Attributterne i tabellen er:
first_name– instruktørens navnlast_name– instruktørens efternavntitle– instruktørens titel (hvis nogen)birth_date– instruktørens fødselsdatocontact_phone– instruktørens telefonnummercontact_mobile– instruktørens mobiltelefonnummercontact_mail– instruktørens e-mailadresse
title og alle tre contact attributter er ikke obligatoriske.
student tabel og instructor tabel deler en lignende struktur, men der er en anden mulighed for at organisere denne information. En anden tilgang ville være at have en person tabel (der gemmer alle medarbejder- og elevdata) og har en mange-til-mange relation, der fortæller os alle de roller, der er tildelt den person. Den vigtigste fordel ved den anden tilgang er, at vi kun gemmer data én gang. Hvis nogen er instruktør i én klasse og elev i en anden, vises de kun én gang i databasen, men med begge roller defineret.
Hvorfor valgte vi to-tabel-tilgangen til vores uddannelsesdatabasemodel? Generelt opfører elever og instruktører sig forskelligt, både i det virkelige liv og i vores database. Derfor kunne det være klogt at gemme deres data separat. Vi kan finde andre måder at flette alle samme personoplysninger, der vises i begge tabeller (f.eks. et par indsættelses-/opdateringsforespørgsler baseret på et eksternt id, såsom et cpr-nummer eller et momsnummer).
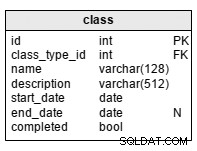
class table er et katalog, der indeholder detaljer om alle klasser. Vi kan have flere forekomster af hver klassetype. Attributterne i tabellen er som følger (alle er obligatoriske undtagen end_date). ):
class_type_id– er en reference tilclass_typeordbog.name– er et kort navn på klassen.description– denne beskrivelse er mere specifik end den iclass_typetabel.start_date– klassens startdato.end_date– slutdatoen for klassen. Det er ikke obligatorisk, fordi vi måske ikke altid kender den nøjagtige slutdato for hvert hold på forhånd.completed– er en boolsk værdi, der angiver, om alle planlagte klasseaktiviteter er afsluttet. Dette er praktisk, når vi har nået det planlagteend_timefor en klasse, men andre klasseaktiviteter mangler endnu at blive gennemført.

class_type table er et simpelt katalog, beregnet til at gemme grundlæggende oplysninger om de forelæsninger eller klasser, der tilbydes studerende. Det kan indeholde værdier som "engelsk sprog (gruppe)", "polsk sprog (gruppe)", "kroatisk sprog (gruppe)", "engelsk sprog (personligt)" eller "Danseundervisning". Den har kun to obligatoriske attributter – name og description , som begge ikke behøver yderligere forklaring.

class_schedule tabel indeholder specifikke tidspunkter for forelæsninger og undervisning. Alle attributter i tabellen er obligatoriske. class_id attribut er en reference til class tabel, mens start_time og end_time er start- og sluttidspunkterne for den specifikke forelæsning.
Hvem er her? Fremmøde-relaterede tabeller

attend tabel gemmer information om, hvilken elev der deltog i hvilken klasse og det endelige resultat. Attributterne i tabellen er:
student_id– er en reference tilstudenttabelclass_id– er en reference tilclasstabelclass_enrollment_date– er den dato, hvor eleven begyndte at deltage i den pågældende klasseclass_drop_date– datoen, hvor eleven forlod undervisningen. Denne egenskab skal kun have værdi, hvis eleven droppede klassen før klassens slutdato. I så fald erdrop_class_reason_idattributværdi skal også indstilles.drop_class_reason_id– er en reference tildrop_class_reasontabelattendance_outcome_id– er en reference tilattendance_outcometabel
Alle data undtagen class_drop_date og drop_class_reason_id er påkrævet. Disse to vil blive udfyldt, hvis og kun hvis en elev dropper klassen.

drop_attendance_reason tabel er en ordbog, der indeholder de forskellige årsager til, at en studerende kan droppe et kursus. Den har kun én attribut, reason_text , og det er obligatorisk. Et eksempel på værdisæt kan omfatte:"sygdom", "mistet interesse", "har ikke tid nok" og "andre årsager".

attendance_outcome tabel indeholder beskrivelser af elevaktivitet i et givet kursus. outcome_text er den eneste attribut i tabellen, og den er påkrævet. Et sæt mulige værdier er:"i gang", "fuldført med succes", "fuldført delvist" og "har ikke gennemført klasse".
Hvem har ansvaret? Undervisningsrelaterede tabeller
teach , drop_teach_reason og teach_outcome tabeller bruger den samme logik som attend , drop_attendance_reason og attendance_outcome tabeller. Alle disse tabeller gemmer data om instruktørers kursusrelaterede aktiviteter.
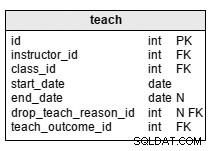
teach tabel bruges til at gemme information om, hvilken instruktør der underviser i hvilken klasse. Attributterne i tabellen er:
instructor_id– er en reference tilinstructortabel.class_id– er en reference tilclasstabel.start_date– er den dato, hvor instruktøren begyndte at arbejde på den pågældende klasse.end_date– er den dato, hvor instruktøren stoppede med at arbejde på den pågældende klasse. Det er ikke obligatorisk, fordi vi ikke på forhånd kan vide, om instruktøren vil undervise til klassens slutdato.drop_teach_reason_id– er en reference tildrop_teach_reasonbord. Det er ikke obligatorisk, fordi instruktøren muligvis ikke dropper klassen.teach_outcome_id– er en reference tilteach_outcome_reasontabel.

drop_teach_reason tabel er en simpel ordbog. Den indeholder et sæt mulige forklaringer på, hvorfor instruktøren afsluttede undervisningen før slutdatoen. Der er kun én obligatorisk attribut:reason_text . Dette kan være "sygdom", "flyttet til andet projekt/job", "ophør" eller "anden årsag".

teach_outcome tabel beskriver instruktørens succes på et bestemt kursus. outcome_text er tabellens eneste egenskab, og det er påkrævet. Mulige værdier for denne tabel kunne være:"i gang", "fuldført med succes", "fuldført delvist" og "har ikke gennemført undervisningstime".

student_presence tabel bruges til at gemme data om studerendes tilstedeværelse for en specifik forelæsning. Vi kan antage, at underviseren for hver forelæsning noterer tilstedeværelse og/eller fravær for alle elever. Attributterne i tabellen er:
student_id– er en reference tilstudenttabelclass_schedule_id– er en reference tilclass_scheduletabelpresent– er en boolesk markering, om eleven er til stede på forelæsningen eller ej
Vi kunne overvåge elevernes tilstedeværelse på en bestemt klasse med en forespørgsel som den, der følger (forudsat at @id_class indeholder det klasse-id, vi ønsker).
SELECT a.id, CONCAT(a.first_name, ' ', a.last_name) AS student_name, a.number_total, CONCAT(CONVERT(a.number_present / a.number_total * 100, DECIMAL(5,2)), '%') AS procent, a.attendance_outcomeFROM(SELECT student.id, student.first_name, student.last_name, SUM(CASE WHEN student_presence.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS number_total, attendance_outcome.outcome_text AS attendance_outcomeFROM class INNER JOIN deltag PÅ class.id =attend.class_id INNER JOIN elev PÅ attend.student_id =student.id VENSTRE JOIN class_schedule PÅ class_schedule.class_id =student_presenceIN student_presenceON =student_presenceIN .id OG student_presence.class_schedule_id =class_schedule.id VENSTRE JOIN attendance_outcome ON attendance_outcome.id =attend.attendance_outcome_idWHERE class.id =@id_classGROUP BY student.id, student.first_name, student.come_outcome, attendanceout_come_come.

Tabellen "instructor_sence" bruger samme logik som "student_sence"-tabellen, men her vil vi fokusere på instruktørerne. Attributterne i tabellen er:
instructor_id– er en reference tilinstructortabelclass_schedule_id– er en reference tilclass_scheduletabelpresent– er en boolsk værdi, der repræsenterer, om instruktøren er til stede på forelæsningen eller ej
Vi kunne bruge forespørgslen nedenfor til at overvåge instruktørens aktivitet i klassen:
SELECT a.id, CONCAT(a.first_name, ' ', a.last_name) AS instructor_name, a.number_total, CONCAT(CONVERT(a.number_present / a.number_total * 100, DECIMAL(5,2)), '%') AS procent, a.teach_outcomeFROM(SELECT instructor.id, instructor.first_name, instructor.last_name, SUM(CASE WHEN instructor_presence.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS antal_total, teach_outcome.outcome_text AS teach_outcomeFROM class INNER JOIN teach ON class.id =teach.class_id INNER JOIN instruktør ON teach.instructor_id =instructor.id LEFT JOIN class_schedule ON class_schedule.class_id =JO-præferenceinstructorinstruct.instructor_instructorinstruct. .id OG instructor_presence.class_schedule_id =class_schedule.id VENSTRE JOIN teach_outcome ON teach_outcome.id =teach.teach_outcome_idWHERE class.id =@id_classGROUP BY instructor.id, instructor.first_name, instructor.com_last_name, instructor.com)Lad os nu afslutte med at diskutere kontaktpersontabellerne.
Hvem kan vi ringe til? Kontaktpersontabeller
I de fleste tilfælde behøver vi ikke gemme kontaktoplysninger for nødsituationer (dvs. kontakt denne person i nødstilfælde). Dette ændrer sig dog, når vi underviser børn. Ved lov eller sædvane skal vi have en kontaktperson for hvert barn, vi underviser. I vores modeltabeller –
contact_person,contact_person_typeogcontact_person_student– vi demonstrerer, hvordan dette kan gøres.
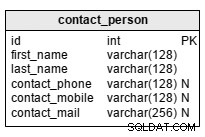
contact_persontabel er en liste over personer, der er relateret til elever. Vi behøver selvfølgelig ikke at liste alle pårørende; for det meste har vi en eller to kontakter pr. elev. Dette er en god måde at finde "hvem du vil ringe til", når eleven har brug for eller ønsker at gå tidligt. Attributterne i tabellen er:
first_name– er kontaktpersonens navnlast_name– er personens efternavncontact_phone– er personens telefonnummercontact_mobile– er personens mobiltelefonnummercontact_mail– er personens e-mailadresse
Kontaktoplysninger er ikke obligatoriske, selvom de er meget nyttige.
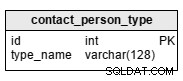
contact_person_type tabel er en ordbog med en enkelt, påkrævet attribut:type_name . Eksempler på værdier gemt i denne tabel er:"mor", "far", "bror", "søster" eller "onkel".

contact_person_student tabel er en mange-til-mange relation, der forbinder kontaktpersoner og deres type med studerende. Attributterne i tabellen er (alle er obligatoriske):
contact_person_id– er en reference tilcontact_persontabelstudent_id– er en reference tilstudenttabelcontact_person_type_id– er en reference tilcontact_person_typetabel
Det kan være værd at nævne, at denne mange-til-mange relation forbinder tre tabeller sammen. Attributparret contact_person_id og student_id bruges som alternativ (UNIQUE) tast. På den måde deaktiverer vi duplikerede poster, der forbinder individuelle studerende med den samme kontaktperson. Attributten contact_person_type_id er ikke en del af den alternative nøgle. Hvis det er tilfældet, kunne vi have flere relationer til den samme kontaktperson og den samme elev (ved at bruge forskellige typer forhold), og det giver ingen mening i virkelige situationer.
Modellen præsenteret i denne artikel burde kunne dække de fleste almindelige behov. Alligevel vil dele af modellen kunne udelukkes i nogle tilfælde, f.eks. vi ville nok ikke have brug for hele kontaktpersonsegmentet, hvis vores elever er voksne. Som jeg sagde før, vil vi tilføje forbedringer til dette med tiden. Tilføj gerne forslag og del dine erfaringer i diskussionssektionerne.