Typen og antallet af låse, der erhverves og frigives under udførelse af forespørgsler, kan have en overraskende effekt på ydeevnen (når du bruger et låseisolationsniveau som standard læse-committed), selv hvor der ikke forekommer ventetid eller blokering. Der er ingen oplysninger i udførelsesplaner, der angiver mængden af låseaktivitet under udførelsen, hvilket gør det sværere at få øje på, hvornår overdreven låsning forårsager et præstationsproblem.
For at udforske nogle mindre kendte låseadfærd i SQL Server, vil jeg genbruge forespørgslerne og prøvedataene fra mit sidste indlæg om beregning af medianer. I det indlæg nævnte jeg, at OFFSET grupperet medianløsning havde brug for en eksplicit PAGLOCK låsetip for at undgå at miste dårligt til den indlejrede markør løsning, så lad os starte med at se nærmere på årsagerne til det.
Den OFFSET Grouped Median Solution
Den grupperede mediantest genbrugte prøvedataene fra Aaron Bertrands tidligere artikel. Scriptet nedenfor genskaber denne millionrække-opsætning, bestående af ti tusinde poster for hver af hundrede imaginære sælgere:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (og senere) OFFSET løsningen skabt af Peter Larsson er som følger (uden nogen låsende hints):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); De vigtige dele af efterudførelsesplanen er vist nedenfor:

Med alle nødvendige data i hukommelsen udføres denne forespørgsel på 580 ms i gennemsnit på min bærbare computer (kører SQL Server 2014 Service Pack 1). Ydeevnen af denne forespørgsel kan forbedres til 320 ms simpelthen ved at tilføje et hint til låsning af sidegranularitet til salgstabellen i underforespørgslen til at anvende:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Udførelsesplanen er uændret (godt, bortset fra låsehintteksten i showplan XML selvfølgelig):
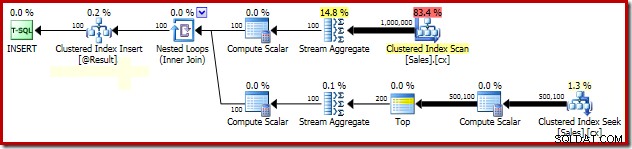
Grupper medianlåsningsanalyse
Forklaringen på den dramatiske forbedring af ydeevnen på grund af PAGLOCK tip er ret simpelt, i hvert fald i begyndelsen.
Hvis vi manuelt overvåger låseaktivitet, mens denne forespørgsel udføres, ser vi, at uden tippet om sidelåsning af granularitet anskaffer og frigiver SQL Server over en halv million rækkeniveaulåse mens du søger det klyngede indeks. Der er ingen blokering at bebrejde; blot at erhverve og frigive så mange låse tilføjer en betydelig overhead til denne forespørgsels udførelse. Anmodning om låse på sideniveau reducerer låseaktiviteten betydeligt, hvilket resulterer i meget forbedret ydeevne.
Denne særlige plans låseydelsesproblem er begrænset til den grupperede indekssøgning i planen ovenfor. Den fulde scanning af det grupperede indeks (bruges til at beregne antallet af tilstedeværende rækker for hver sælger) bruger automatisk sideniveaulåse. Dette er en interessant pointe. Den detaljerede låseadfærd for SQL Server-motoren er ikke dokumenteret i Books Online i særlig grad, men forskellige medlemmer af SQL Server-teamet har fremsat et par generelle bemærkninger gennem årene, herunder det faktum, at de ubegrænsede scanninger har en tendens til at begynde at tage side låse, hvorimod mindre operationer har en tendens til at starte med rækkelåse.
Forespørgselsoptimeringsværktøjet stiller nogle oplysninger til rådighed for lagermotoren, inklusive kardinalitetsestimater, interne tip til isolationsniveau og låsegranularitet, hvilke interne optimeringer der kan anvendes sikkert og så videre. Igen, disse detaljer er ikke dokumenteret i Books Online. I sidste ende bruger lagringsmotoren en række informationer til at beslutte, hvilke låse der kræves ved kørsel, og med hvilken granularitet de skal tages.
Som en sidebemærkning, og husk, at vi taler om en forespørgsel, der udføres under standardlåsningsniveauet for læst forpligtet transaktionsisolation, bemærk, at rækkelåsene, der tages uden granularitetstip, ikke vil eskalere til en tabellås i dette tilfælde. Dette skyldes, at den normale adfærd under begået læsning er at frigive den forrige lås lige før erhvervelse af den næste lås, hvilket betyder, at kun en enkelt delt rækkelås (med dens tilknyttede højere-niveau hensigtsdelte låse) vil blive holdt på et bestemt tidspunkt. Da antallet af samtidig holdte rækkelåse aldrig når tærsklen, forsøges der ingen låseeskalering.
OFFSET Single Median Solution
Ydeevnetesten for en enkelt medianberegning bruger et andet sæt prøvedata, igen gengivet fra Aarons tidligere artikel. Scriptet nedenfor opretter en tabel med ti millioner rækker af pseudo-tilfældige data:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET løsningen er:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Efterudførelsesplanen er:

Denne forespørgsel udføres på 910 ms i gennemsnit på min testmaskine. Ydeevnen er uændret, hvis en PAGLOCK tip er tilføjet, men grunden til det er ikke, hvad du måske tænker...
Enkelt median låseanalyse
Du forventer måske, at lagermotoren alligevel vælger delte låse på sideniveau på grund af den klyngede indeksscanning, der forklarer hvorfor en PAGLOCK tip har ingen effekt. Faktisk afslører overvågning af de låse, der tages, mens denne forespørgsel udføres, at ingen delte låse (S) tages overhovedet, uanset granularitet . De eneste låse, der tages, er hensigtsdelte (IS) på objekt- og sideniveau.
Forklaringen på denne adfærd findes i to dele. Den første ting at bemærke er, at Clustered Index Scan er under en Top-operatør i udførelsesplanen. Dette har en vigtig effekt på kardinalitetsestimater, som vist i den forudgående (estimerede) plan:

OFFSET og FETCH klausuler i forespørgslen refererer til et udtryk og en variabel, så forespørgselsoptimeringsværktøjet gætter på antallet af rækker, der skal bruges ved kørsel. Standardgætningen for Top er hundrede rækker. Dette er selvfølgelig et frygteligt gæt, men det er nok til at overbevise lagermotoren om at låse ved rækkegranularitet i stedet for på sideniveau.
Hvis vi deaktiverer "rækkemål"-effekten af Top-operatøren ved hjælp af dokumenteret sporingsflag 4138, ændres det estimerede antal rækker ved scanningen til ti millioner (hvilket stadig er forkert, men i den anden retning). Dette er nok til at ændre storage-motorens låsegranularitetsbeslutning, så delte låse på sideniveau (bemærk, ikke hensigtsdelte låse) tages:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Den estimerede udførelsesplan produceret under sporingsflag 4138 er:

For at vende tilbage til hovedeksemplet, betyder hundredrække-estimatet på grund af det gættede rækkemål, at lagermotoren vælger at låse på rækkeniveau. Vi observerer dog kun hensigtsdelte (IS) låse på tabel- og sideniveau. Disse låse på højere niveau ville være helt normale, hvis vi så delte (S) låse på rækkeniveau, så hvor blev de af?
Svaret er, at lagermotoren indeholder en anden optimering, som kan springe de delte låse på rækkeniveau over under visse omstændigheder. Når denne optimering anvendes, erhverves de overordnede hensigtsdelte låse stadig.
For at opsummere, for enkeltmedian-forespørgslen:
- Brugen af en variabel og et udtryk i
OFFSETklausul betyder, at optimeringsværktøjet gætter kardinalitet. - Det lave estimat betyder, at lagermotoren beslutter sig for en låsestrategi på rækkeniveau.
- En intern optimering betyder, at S-låsene på rækkeniveau springes over under kørsel, og kun efterlader IS-låsene på side- og objektniveau.
Den enkelte medianforespørgsel ville have haft det samme rækkelåsende ydeevneproblem som den grupperede median (på grund af forespørgselsoptimeringsværktøjets unøjagtige estimat), men den blev gemt af en separat lagermaskineoptimering, der resulterede i, at der kun blev taget hensigtsdelte side- og tabellåse ved kørsel.
Den grupperede mediantest genbesøgt
Du undrer dig måske over, hvorfor Clustered Index Seek i den grupperede mediantest ikke udnyttede den samme lagringsmotoroptimering til at springe delte låse over på rækkeniveau. Hvorfor blev der brugt så mange delte rækkelåse, hvilket gjorde PAGLOCK tip nødvendigt?
Det korte svar er, at denne optimering ikke er tilgængelig for INSERT...SELECT forespørgsler. Hvis vi kører SELECT alene (dvs. uden at skrive resultaterne til en tabel) og uden en PAGLOCK tip, optimeringen af rækkelåsen er anvendt:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Kun tabel- og side-niveau hensigtsdelte (IS) låse bruges, og ydeevnen øges til samme niveau, som når vi bruger PAGLOCK antydning. Du vil naturligvis ikke finde denne adfærd i dokumentationen, og den kan ændre sig til enhver tid. Alligevel er det godt at være opmærksom på.
Desuden, hvis du undrede dig, har sporingsflag 4138 ingen effekt på lagermotorens valg af låsende granularitet i dette tilfælde, fordi det estimerede antal rækker ved søgningen er for lavt (pr. appliceret iteration), selv med rækkemålet deaktiveret.
Før du drager konklusioner om udførelsen af en forespørgsel, skal du sørge for at kontrollere antallet og typen af låse, den tager under udførelsen. Selvom SQL Server normalt vælger den 'rigtige' granularitet, er der tidspunkter, hvor det kan gå galt, nogle gange med dramatiske effekter på ydeevnen.