Livsforsikring er noget, vi alle håber, vi ikke får brug for, men som vi ved, er livet uforudsigeligt. I denne artikel vil vi fokusere på at formulere en datamodel, som et livsforsikringsselskab kan bruge til at gemme sine oplysninger.
Livsforsikring som koncept
Før vi begynder at diskutere den faktiske datamodel for et livsforsikringsselskab, vil vi kort minde os selv om, hvad forsikring er, og hvordan det fungerer, så vi har en bedre idé om, hvad vi arbejder med.
Forsikring er et ret gammelt koncept, der går tilbage allerede før middelalderen, hvor mange laug tilbød policer for at beskytte deres medlemmer i uventede situationer. Selv den berømte astronom, matematiker, videnskabsmand og opfinder Edmund Halley beskæftigede sig med forsikring og arbejdede på statistik og dødelighedsrater, der dannede rygraden i moderne forsikringsmodeller.
Hvorfor skal du betale for forsikring? Ideen er ret simpel – du betaler et vist beløb (præmien) mod forsikringsselskabets garanti for, at du eller din familie vil blive kompenseret økonomisk, hvis der sker noget uventet med dig eller din ejendom. I tilfælde af en livsforsikring udpeger du en begunstiget, som vil modtage en sum penge (ydelsen) i tilfælde af din død. Tanken er, at disse penge vil hjælpe dem med at komme sig over deres tab, især hvis din død skaber økonomiske problemer.
Selvfølgelig udbetaler forsikringsselskaber typisk meget mindre i ydelser, end de tjener på præmier og ved at investere dine penge i f.eks. aktiemarkedet. Ellers ville de gå konkurs, og hele systemet ville falde fra hinanden!
Det er stort set kernen i det. Nu hvor vi har fået det af vejen, lad os gå videre og tage et kig på datamodellen for et typisk livsforsikringsselskab.
Datamodellen:Oversigt
Den datamodel, vi skal arbejde med, består af fem emneområder:
- Medarbejdere
- Produkter
- Kunder
- Tilbud
- Betalinger
Vi vil dække hvert af disse afsnit mere detaljeret i den rækkefølge, de er angivet ovenfor.
Fagområde #1:Medarbejdere
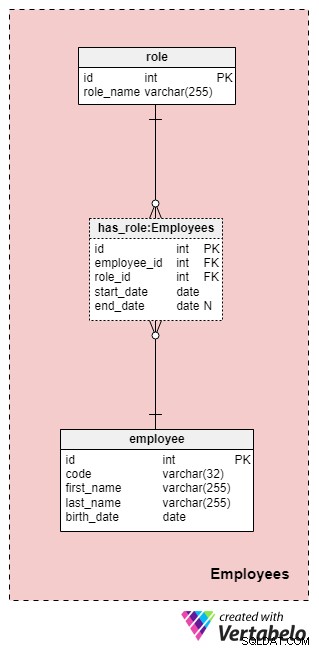
Dette område er ikke nødvendigvis specifikt for denne datamodel, men er stadig meget vigtigt, fordi tabellerne heri vil blive refereret af andre emneområder. I forbindelse med vores forsikringsselskabs datamodel skal vi naturligvis vide, hvem der udførte hvilken handling (f.eks. hvem repræsenterede vores virksomhed, når vi arbejdede med kunden/klienten, hvem der underskrev politikken osv.).
Listen over alle virksomhedens ansatte er gemt i employee bord. For hver medarbejder gemmer vi følgende oplysninger:
code— en unik nøgle, der identificerer en enkelt medarbejder. Da koden vil blive brugt som en attribut i andre tabeller, vil den fungere som en alternativ nøgle i denne tabel.first_nameoglast_name— medarbejderens henholdsvis for- og efternavn.birth_date— medarbejderens fødselsdato.
Selvfølgelig kunne vi helt sikkert inkludere mange andre medarbejder-relaterede egenskaber i denne tabel, men disse fire er mere end nok for nu. Vi følger dette mønster gennem artiklen og forsøger at holde tingene så enkle som muligt, men bemærk, at du helt sikkert kan udvide denne datamodel til at inkludere yderligere oplysninger.
Da medarbejdere kan ændre deres roller i vores virksomhed til enhver tid, skal vi bruge en ordbogstabel til at repræsentere virksomhedens roller og en tabel til at gemme værdier. Listen over alle mulige roller, som medarbejdere kan påtage sig i vores livsforsikringsselskab, er gemt i role ordbog. Den har kun én egenskab ved navn role_name der indeholder unikt identificerende værdier.
Vi relaterer medarbejdere og roller ved hjælp af has_role bord. Ud over fremmednøglerne employee_id og role_id , gemmer vi to værdier:start_date og end_date . Disse to værdier angiver det interval, hvor denne virksomhedsrolle var aktiv for en bestemt medarbejder. end_date vil indeholde værdien null, indtil en slutdato for denne medarbejders rolle er blevet bestemt. Den alternative nøgle til denne tabel er kombinationen af employee_id , role_id og start_date . For at undgå at dublere den samme rolle for den samme medarbejder, skal vi kontrollere programmatisk for eventuelle overlapninger, hver gang vi tilføjer en ny post til tabellen eller opdaterer en eksisterende.
Emneområde #2:Produkter
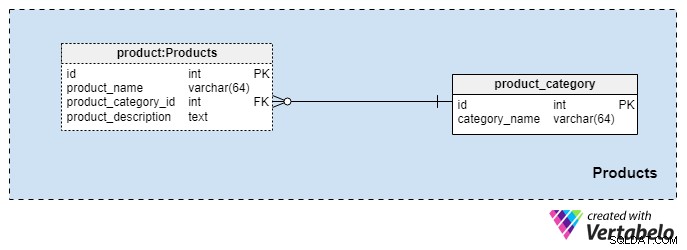
Dette emneområde er ret lille og indeholder kun to tabeller. Værdier fra disse tabeller er forudsætninger for vores øvrige fagområder, så vi vil diskutere disse kort.
product_category ordbog gemmer de mest generelle kategorier af produkter, som vi planlægger at tilbyde vores kunder. Den eneste værdi, vi gemmer i denne tabel, er den unikke category_name for at angive den type forsikring, vi tilbyder, som kunne være personlig livsforsikring, familielivsforsikring og så videre.
Vi vil kategorisere vores produkter endnu mere ved hjælp af product bord. Denne tabel repræsenterer de faktiske produkter, vi sælger, og ikke deres kategorier. Som du kan forestille dig, kan vi gruppere produkter efter varighed (f.eks. 10 eller 20 år, eller endda en levetid). Hvis vi vælger at gøre det, vil vi sandsynligvis have produkter med det samme product_category_id men forskellige navne og beskrivelser. For hvert produkt gemmer vi følgende grundlæggende oplysninger:
product_name— navnet på dette produkt. Den bruges som en alternativ nøgle til denne tabel i kombination medproduct_category_idattribut. Det er usandsynligt, at vi har to produkter med samme navn, der tilhører forskellige kategorier, men det er ikke desto mindre en mulighed.product_category_id— identificerer den kategori, som dette produkt tilhører.product_description— tekstbeskrivelse af dette produkt.
Emneområde #3:Klienter
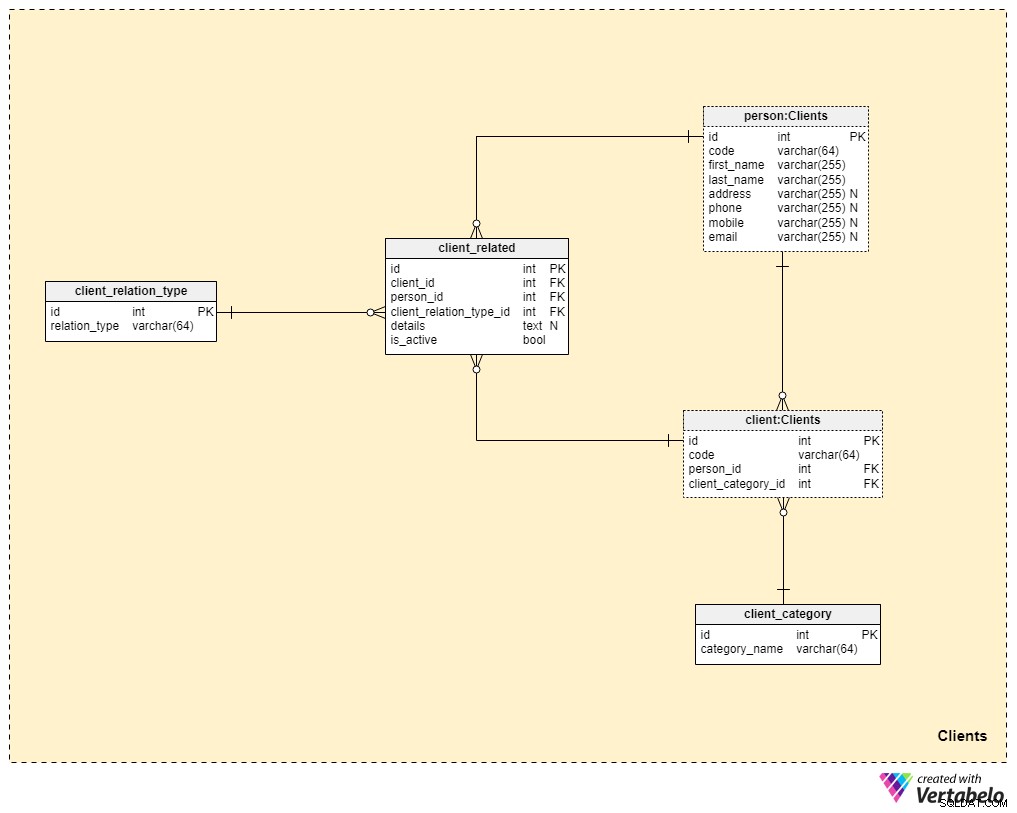
Vi kommer nu meget tættere på kernen af vores datamodel, men vi er ikke helt der endnu. Livsforsikring er unik, fordi en police kan overføres til et familiemedlem eller en anden, hvorimod policer for andre former for forsikring (såsom sygeforsikring eller bilforsikring) tilhører en enkelt kunde og ikke kan overdrages. Af denne grund skal vi ikke kun gemme oplysninger om den klient, som policen tilhører, men også oplysninger om eventuelle relaterede personer og deres forhold til klienten.
Vi starter med client bord. For hver klient gemmer vi den unikke kode, der er genereret eller manuelt indsat for den pågældende klient, såvel som fremmednøglerne, der refererer til tabellen med deres personlige data (person_id ) og tabellen, der indeholder vores interne kategorisering (client_category_id ).
client_category ordbog giver os mulighed for at gruppere kunder baseret på deres demografiske og økonomiske detaljer. Kundekategorierne vil derefter blive brugt til at bestemme den forsikring, vi er klar til at tilbyde til en bestemt kunde. Her gemmer vi kun en liste over unikke værdier, som vi derefter tildeler til kunder.
Da vi taler om livsforsikring, så vil vi antage, at en klient er et enkelt individ. Men som vi nævnte før, kan der være andre personer relateret til klienten, som policen kan overføres til, eller som kan modtage policeydelsen ved klientens død. Af denne grund har vi oprettet en separat person bord. For hver post i denne tabel gemmer vi følgende oplysninger:
code— en automatisk genereret eller manuelt indsat værdi, der bruges til entydigt at identificere den relaterede person.first_nameoglast_name— personens henholdsvis for- og efternavn.address,phone,mobileogemail— kontaktoplysninger for denne person, som alle indeholder vilkårlige værdier.
De resterende to tabeller i dette emneområde er nødvendige for at beskrive karakteren af forholdet mellem klienter og andre mennesker.
Listen over alle mulige relationstyper er gemt i client_relation_type ordbog. Som med andre ordbøger vil dette indeholde en liste over unikke navne, som vi senere vil bruge, når vi beskriver forholdet mellem en bestemt klient og en anden person.
Faktiske relationsdata gemmes i client_related bord. For hver post i denne tabel gemmer vi referencer til klienten (client_id ), den relaterede person (person_id ), arten af denne relation (client_relation_type_id ), alle tilføjelsesdetaljer (details ), hvis nogen, og et flag, der angiver, om relationen i øjeblikket er aktiv (is_active ). Den alternative nøgle i denne tabel er defineret af kombinationen af client_id , person_id og client_relation_type_id .
Emneområde #4:Tilbud
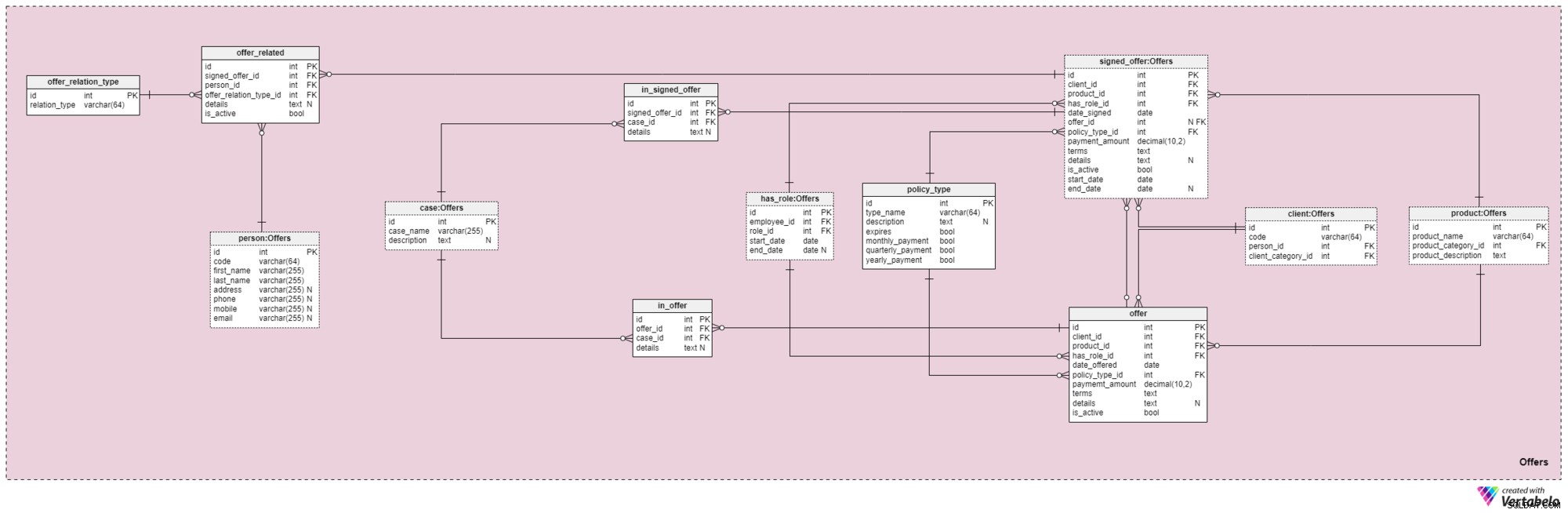
Dette emneområde og det der følger er kernen i denne datamodel. De dækker tilbud og underskrevne policer samt betalinger relateret til tilbud. Først vil vi beskrive emneområdet Tilbud. Det kan virke komplekst, fordi det indeholder 12 tabeller. Men fire af disse 12 (has_role , product , client og person ) blev beskrevet i tidligere emneområder, så vi vil ikke gentage vores diskussion her.
offer og signed_offer tabeller har lignende strukturer, fordi de vil blive brugt til at gemme meget lignende data i vores model. Men mens offer vil hovedsageligt blive brugt til at gemme alle politikker (og deres detaljer), som vi har tilbudt vores kunder, signed_offer tabellen vil strengt taget blive brugt til at gemme oplysninger om kunder, der faktisk har underskrevet politikker med vores virksomhed. Vi vil dække disse tabeller sammen og bemærke eventuelle forskelle, hvor de vises. Attributterne i disse to tabeller er som følger:
client_id— reference til den unikke identifikator for den klient, der underskrev et bestemt tilbud.product_id— reference til den unikke identifikator for produktet, der var inkluderet i det underskrevne tilbud.has_role_id— reference til medarbejderens id og den rolle, de tjente på det tidspunkt, hvor tilbuddet blev præsenteret/underskrevet.date_offeredogdate_signed— faktiske datoer, der angiver, hvornår dette tilbud blev præsenteret for kunden, og hvornår det blev underskrevet, henholdsvis.offer_id— en henvisning til det tidligere tilbud til denne kunde. Dette kan indeholde en værdi på null, fordi klienten kunne have underskrevet en politik uden at have noget tidligere tilbud fra virksomheden, f.eks. hvis de henvendte sig til os på egen hånd. Denne egenskab hører udelukkende tilsigned_offertabel.policy_type_id— henvisning til ordbogen af politiktype, der angiver den type police, vi tilbød kunden eller fik dem til at underskrive.payment_amount— det beløb, kunden skal betale for policen på regelmæssig basis.terms— alle vilkår i aftalen i tekstformat (XML). Ideen er at gemme alle vigtige detaljer vedrørende den økonomiske del af politikken i denne attribut. Eksempler på tekst, vi kunne gemme, er det samlede policebeløb, antallet af betalinger, kunden skal foretage, og så videre.details— eventuelle yderligere detaljer i tekstformat.is_active— flag, der angiver, om posten stadig er aktiv.start_dateogend_date— angiv det tidsinterval, hvor denne politik er/var aktiv. Hvis politikken blev underskrevet for en levetid, vil end_date indeholde værdien null.
Der er også policy_type ordbog, som vi kort nævnte før. Vi har brug for en vis grad af fleksibilitet i, hvordan vi tilbyder det samme produkt til forskellige kunder, baseret på faktorer som alder, helbred, civilstand, kreditrisiko og så videre. For hver politiktype gemmer vi et type_name identifikator, en yderligere tekstlig description , et flag navngivet udløber, der angiver, om policen kan udløbe, og et andet flag, der angiver, om denne policetypes præmier skal betales månedligt, kvartalsvis eller årligt. Nogle forventede policetyper er:Term Life, Whole Life, Universal Life, Guaranteed Universal Life, Variable Life, Variable Universal Life og Livsforsikring efter pensionering.
For at komme videre, er vi nu nødt til at definere alle sager og situationer, som en bestemt politik kan dække. Vi skal relatere disse sager til konkrete tilbud og underskrevne tilbud.
Listen over alle mulige sager, som vores policer dækker, gemmes i case ordbog. Hver post i denne tabel kan identificeres entydigt ved dens case_name og har en ekstra description , hvis der er behov for en.
in_offer og in_signed_offer tabeller deler den samme struktur, fordi de gemmer de samme data. Den eneste forskel mellem de to er, at den første opbevarer sager omfattet af policen, som blot blev tilbudt kunden, mens den anden opbevarer sager i den police, som kunden har underskrevet. For hver post i disse to tabeller gemmer vi det unikke par offer_id /signed_offer_id og case_id , hvoraf sidstnævnte betegner den sag eller hændelse, der er omfattet af policen. Alle andre detaljer vil blive gemt i en tekstattribut, hvis det er nødvendigt.
Som vi nævnte før, er livsforsikringer næsten altid relateret ikke kun til kunder, men også til deres familiemedlemmer eller slægtninge. Vi skal også opbevare disse relationer på dette område. De vil blive defineret på det tidspunkt, hvor en politik underskrives, men de kan også ændres i hele politikkens varighed.
Det første, vi skal gøre, er at lave en ordbog, der indeholder alle mulige værdier, der kan tildeles en relation. I vores model er dette offer_relation_type ordbog. Bortset fra den primære nøgle indeholder denne tabel kun én attribut - relation_type – der kun kan indeholde unikke værdier.
Vi er der næsten! Den sidste tabel i dette emneområde har titlen offer_related . Det vedrører et underskrevet tilbud til enhver, der er relateret til kunden. Derfor bliver vi nødt til at gemme referencer til den signerede politik (signed_offer_id ) og den relaterede person (person_id ) og angiv også arten af denne relation (offer_relation_type_id ). Derudover skal vi gemme details relateret til denne post og opret et flag for at kontrollere, om det stadig er gyldigt i vores system.
Emneområde #5:Betalinger
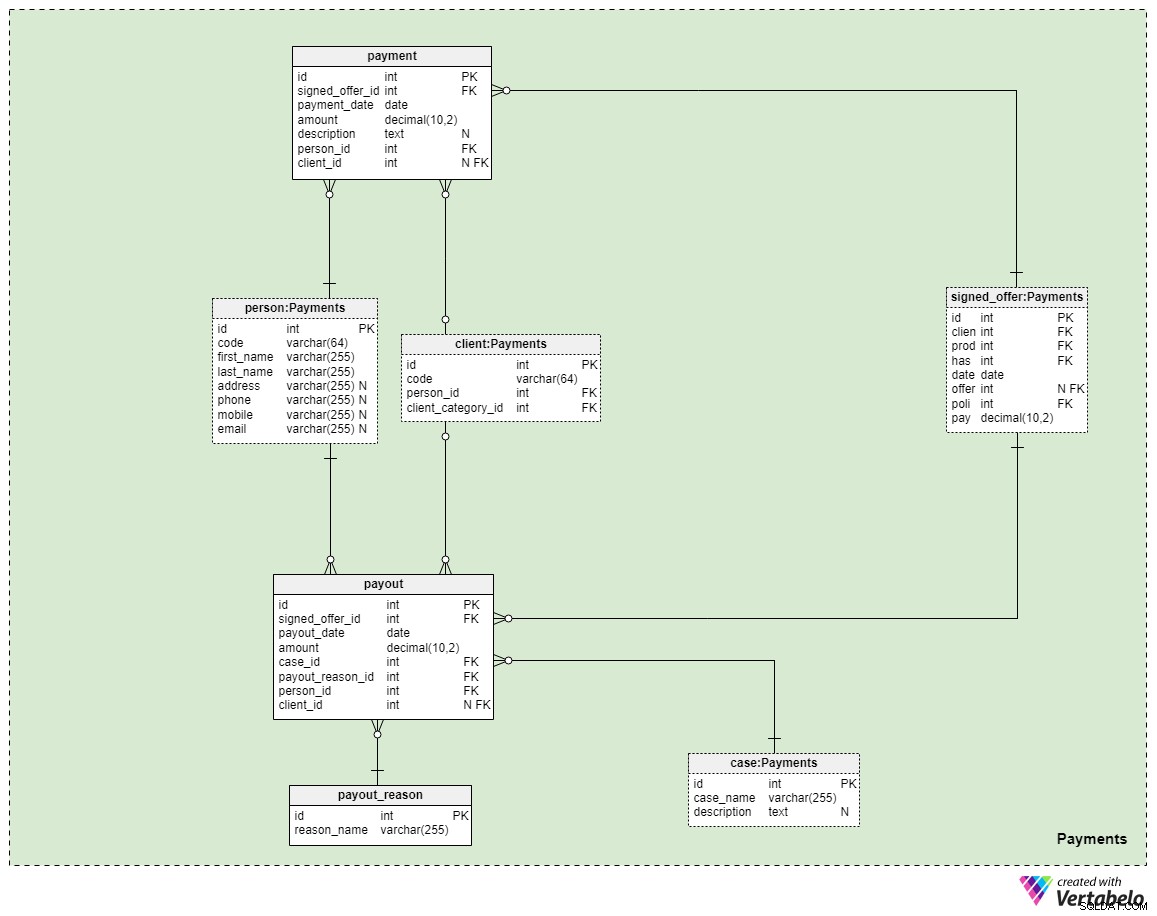
Det sidste emneområde i vores model omhandler betalinger. Her introducerer vi kun tre nye tabeller:payment , payout_reason , og payout .
Alle betalinger relateret til politikker gemmes i payment bord. Vi inkluderede kun de vigtigste egenskaber her:
signed_offer_id— reference til den unikke identifikator for det underskrevne tilbud (politik).payment_date— datoen for denne betaling.amount— det faktiske beløb, der blev betalt.description— en valgfri beskrivelse af betalingen i tekstformat.person_id— henvisning til den entydige identifikator for den person, der foretog betalingen. Bemærk, at kunden, der har underskrevet tilbuddet, ikke nødvendigvis er den eneste person, der kan foretage en betaling.client_id— reference til den unikke identifikator for den klient, der har foretaget betalingen. Denne attribut vil kun indeholde en værdi, hvis klienten selv har foretaget betalingen.
De resterende to tabeller repræsenterer måske den vigtigste grund til, at vi betaler for livsforsikring - at hvis der skulle ske os noget, vil udbetalinger blive foretaget til vores familiemedlemmer eller livs-/forretningspartnere. Hvordan dette sker afhænger alt af din situation og vilkårene for den specifikke politik, du har underskrevet. Vi bruger to simple tabeller til at dække disse tilfælde.
Den første er en ordbog med titlen payout_reason og har en klassisk ordbogsstruktur. Bortset fra den primære nøgleattribut har vi kun én egenskab – reason_name – der gemmer en liste over unikke værdier, der angiver, hvorfor denne udbetaling blev foretaget.
Den sidste tabel i modellen er payout bord. Det minder meget om payment tabel, men de vigtigste forskelle er noteret nedenfor:
payout_date— datoen for udbetalingen.case_id— reference til den unikke identifikator for den relaterede sag eller hændelse, der udløste betalingen. Dette bør matche et af de id'er, der er inkluderet i politikken.payout_reason_id— henvisning til ordbogen, der beskriver årsagen til udbetalingen mere detaljeret. Selvom udbetalingssagen er kortere og mere generel, vil udbetalingsårsagen give mere specifikke detaljer om, hvad der skete.person_idogclient_id— refererer til den person og den klient, der er relateret til henholdsvis udbetalingen.
Oversigt
Fantastisk! Vi har med succes bygget vores livsforsikringsdatamodel. Før vi afslutter vores diskussion, er det værd at bemærke, at der er meget mere, der kan dækkes i denne model. I denne artikel ønskede vi hovedsageligt at dække det grundlæggende i modellen for at give dig en idé om, hvordan den ser ud og fungerer. Her er nogle flere detaljer, som man kunne inkorporere i sådan en datamodel:
- Yderligere politikopgraderinger er ikke dækket af vores nuværende model (hvis du f.eks. vil give årlige tilbud på eksisterende policer, vil du ikke være i stand til at gøre det med denne struktur). Vi bør tilføje et par flere tabeller for at gemme alle politikændringer for præsenterede/signerede tilbud.
- Alt papirarbejde er bevidst udeladt. Selvfølgelig vil der være en del papirarbejde forbundet med en bestemt livsforsikring, især for underskriftsprocessen og udbetalinger. Vi kunne vedhæfte dokumenter, der beskriver klientens status på det tidspunkt, hvor policen blev underskrevet, og eventuelle ændringer undervejs, samt alle dokumenter relateret til udbetalinger.
- Denne model inkorporerer ikke den struktur, der er nødvendig til beregning af politikrisiko. Vi bør have alle parametre, som vi skal teste, og eventuelle intervaller, der bestemmer, hvordan en klients værdi påvirker den overordnede beregning. Resultaterne af disse beregninger skal gemmes for hvert tilbud og underskrevet politik.
- Fakturastrukturen er i virkeligheden langt mere kompleks, end hvad vi dækkede inden for emneområdet betalinger. Vi nævnte ikke engang finansielle konti nogen steder i vores model.
Det er klart, at forsikringsbranchen er ret kompleks. Vi diskuterede kun en datamodel for livsforsikring i denne artikel - kan du forestille dig, hvordan denne datamodel ville udvikle sig, hvis vi skulle drive et selskab, der tilbyder en række forskellige forsikringstyper? Det ville helt sikkert kræve en masse planlægning og omtanke at præsentere en organiseret datamodel for sådan en virksomhed.
Hvis du har forslag eller ideer til at forbedre vores datamodel, er du velkommen til at fortælle os det i kommentarerne nedenfor!