Funktionerne OVER og PARTITION BY er begge funktioner, der bruges til at dele et resultatsæt efter specificerede kriterier.
Denne artikel forklarer, hvordan disse to funktioner kan bruges sammen til at hente partitionerede data på meget specifikke måder.
Forberedelse af nogle prøvedata
For at udføre vores eksempelforespørgsler, lad os først oprette en database med navnet "studentdb".
Kør følgende kommando i dit forespørgselsvindue:
OPRET DATABASE schooldb;
Dernæst skal vi oprette "student"-tabellen i "studentdb"-databasen. Elevtabellen vil have fem kolonner:id, navn, alder, køn og total_score.
Som altid skal du sikre dig, at du er godt sikkerhedskopieret, før du eksperimenterer med en ny kode. Se denne artikel om sikkerhedskopiering af SQL Server-databaser, hvis du ikke er sikker.
Udfør følgende forespørgsel for at oprette elevtabellen.
BRUG schooldbCREATE TABLE elev( id INT PRIMÆR NØGLE IDENTITET, navn VARCHAR(50) IKKE NULL, køn VARCHAR(50) IKKE NULL, alder INT IKKE NULL, total_score INT IKKE NULL, )
Til sidst skal vi indsætte nogle dummy-data, som vi kan arbejde med i databasen.
BRUG schooldbINSERT I elevværdier ('Jolly', 'Female', 20, 500), ('Jon', 'Mand', 22, 545), ('Sara', 'Female', 25, 600), ('Laura', 'Female', 18, 400), ('Alan', 'Mand', 20, 500), ('Kate', 'Female', 22, 500), ('Joseph', 'Mand' , 18, 643), ('Mus', 'Mand', 23, 543), ('Klog', 'Mand', 21, 499), ('Elis', 'Kvinde', 27, 400);
Lige nu er vi klar til at arbejde på et problem og se, hvem vi kan bruge Over og Partition By til at løse det.
Problem
Vi har 10 poster i elevtabellen, og vi ønsker at vise navn, id og køn for alle eleverne, og derudover ønsker vi også at vise det samlede antal elever, der tilhører hvert køn, gennemsnitsalderen for de studerende. elever af hvert køn og summen af værdierne i kolonnen total_score for hvert køn.
Det resultatsæt, vi leder efter, er som nedenfor:
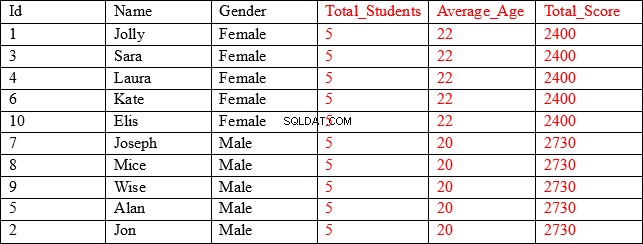
Som du kan se, indeholder de første tre kolonner (vist med sort) individuelle værdier for hver post, mens de sidste tre kolonner (vist med rødt) indeholder aggregerede værdier grupperet efter kønskolonnen. I kolonnen Average_Age viser de første fem rækker f.eks. gennemsnitsalderen og den samlede score for alle de poster, hvor køn er Kvinde.
Vores resultatsæt indeholder aggregerede resultater kombineret med ikke-aggregerede kolonner.
For at hente de aggregerede resultater, grupperet efter en bestemt kolonne, kan vi bruge GROUP BY-sætningen som normalt.
BRUG schooldbSELECT køn, tæl(køn) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM elevGROUP BY kön
Lad os se, hvordan vi kan hente Total_Students, Average_Age og Total_Score for eleverne grupperet efter køn.
Du vil se følgende resultater:

Lad os nu udvide dette og tilføje 'id' og 'navn' (de ikke-aggregerede kolonner i SELECT-sætningen) og se, om vi kan få vores ønskede resultat.
BRUG schooldbSELECT id, navn, køn, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM elevGROUP BY kön
Når du kører ovenstående forespørgsel, vil du se en fejlmeddelelse:

Fejlen siger, at id-kolonnen i elevtabellen er ugyldig i SELECT-sætningen, da vi bruger GROUP BY-sætning i forespørgslen.
Det betyder, at vi bliver nødt til at anvende en aggregeret funktion på id-kolonnen, eller vi bliver nødt til at bruge den i GROUP BY-sætningen. Kort sagt løser denne ordning ikke vores problem.
Løsning ved hjælp af JOIN-erklæring
En løsning på dette ville være at bruge JOIN-sætningen til at forbinde kolonnerne med aggregerede resultater til kolonner, der indeholder ikke-aggregerede resultater.
For at gøre det skal du bruge en underforespørgsel, der henter køn, Total_Students, Average_Age og Total_Score for eleverne grupperet efter køn. Disse resultater kan derefter føjes til resultaterne opnået fra underforespørgslen med den ydre SELECT-sætning. Dette vil blive anvendt på kønskolonnen i underforespørgslen, der indeholder det aggregerede resultat og kønskolonnen i elevtabellen. Den ydre SELECT-sætning vil inkludere ikke-aggregerede kolonner, dvs. "id" og "navn", som nedenfor.
BRUG schooldbSELECT id, navn, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_ScoreFROM studentINNER JOIN(VÆLG køn, antal(køn) AS Total_studerende, AVG(alder) AS Average_Age_ScoreROM, SUM(total) elevGRUPPE EFTER køn) AS Aggregationon Aggregation.gender =student.gender
Ovenstående forespørgsel vil give dig det ønskede resultat, men er ikke den optimale løsning. Vi skulle bruge en JOIN-sætning og en underforespørgsel, som øger scriptets kompleksitet. Dette er ikke en elegant eller effektiv løsning.
En bedre tilgang er at bruge OVER- og PARTITION BY-sætningerne sammen.
Løsning ved hjælp af OVER og PARTITION BY
For at bruge OVER- og PARTITION BY-klausulerne skal du blot angive den kolonne, som du vil opdele dine aggregerede resultater efter. Dette forklares bedst ved hjælp af et eksempel.
Lad os se på, hvordan vi opnår vores resultat ved at bruge OVER og PARTITION BY.
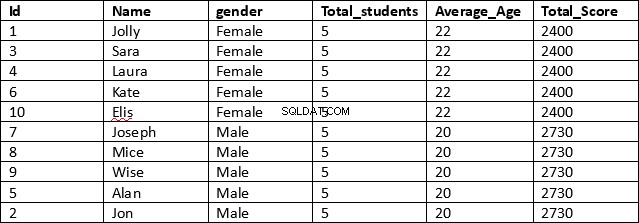
BRUG schooldbSELECT id, navn, køn,ANTAL(køn) OVER (OPDELING EFTER køn) AS Total_studerende,AVG(alder) OVER (OPDELING EFTER køn) AS Average_Age,SUM(total_score) OVER (OPDELING EFTER køn) AS Total_ScoreFROM elev
Dette er et meget mere effektivt resultat. I den første linje af scriptet hentes kolonnerne id, navn og køn. Disse kolonner indeholder ingen samlede resultater.
Dernæst, for de kolonner, der indeholder aggregerede resultater, angiver vi simpelthen den aggregerede funktion, efterfulgt af OVER-klausulen, og inden for parentesen angiver vi PARTITION BY-klausulen efterfulgt af navnet på den kolonne, som vi ønsker, at vores resultater skal partitioneres som vist. nedenfor.
Referencer
- Microsoft – Forståelse af OVER-klausulen
- Midnight DBA – Introduktion til OVER og PARTITION BY
- StackOverflow – Forskellen mellem PARTITION BY og GROUP BY