Introduktion
For nogle år siden fik vi til opgave at stille et forretningskrav til kortdata i et bestemt format med henblik på noget, der kaldes "afstemning". Ideen var at præsentere dataene i en tabel til en applikation, som ville forbruge og behandle dataene, som ville have en opbevaringsperiode på seks måneder. Vi var nødt til at oprette en ny database til dette forretningsbehov og derefter oprette kernetabellen som en opdelt tabel. Processen beskrevet her er den proces, vi bruger til at sikre, at data, der er ældre end seks måneder, flyttes ud af bordet på en ren måde.
Lidt om partitionering
Tabelpartitionering er en databaseteknologi, der giver dig mulighed for at gemme data, der tilhører én logisk enhed (tabellen), som et sæt af partitioner, der vil sidde på en separat fysisk struktur - datafiler - gennem et abstraktionslag kaldet Filgrupper i SQL Server. Processen med at skabe denne opdelte tabel involverer to nøgleobjekter:
En partitionsfunktion :En partitionsfunktion definerer, hvordan rækkerne i en opdelt tabel afbildes baseret på værdierne i en specificeret kolonne (afsnitskolonnen). En opdelt tabel kan være baseret på enten en liste eller en rækkevidde. Til formålet med vores use case (bevarer kun seks måneders data) brugte vi en Range Partition . En partitionsfunktion kan defineres som enten RANGE RIGHT eller RANGE LEFT. Vi brugte RANGE RIGHT som vist i koden i liste 1, hvilket betyder, at grænseværdien vil tilhøre højre side af grænseværdiintervallet, når værdierne er sorteret i stigende rækkefølge fra venstre mod højre.
-- Liste 1:Opret en partitionsfunktionBrug [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime)SOM OMRÅDE RIGHTFOR VALUES ('20190201','20190301','2019014019','052'091','092','052','091','091','091','091','091','01'09','091','01'01','05 '20190801','20190901','20191001','20191101','20191201')GO Et partitionsskema :Et partitionsskema er baseret på partitionsfunktionen og bestemmer, på hvilke fysiske strukturer rækker tilhørende hver partition vil blive placeret. Dette opnås ved at tilknytte sådanne rækker til filgrupper. Liste 2 viser koden til oprettelse af et partitionsskema. Inden partitionsskemaet oprettes, skal de filgrupper, som det refererer til, eksistere.
-- Liste 2:Opret partitionsskema ---- Trin 1:Opret filgrupper --BRUG [master]GOALTER DATABASE [post_office_history] TILFØJ FILGROUP [JAN]ÆNDRE DATABASE [post_office_history] TILFØJ FILGRUPPE [FEB]ÆNDRE DATABASE [post_office_history] ] TILFØJ FILGRUPPE [MAR]ÆNDRE DATABASE [post_office_history] TILFØJ FILGROUP [APR]ÆNDRE DATABASE [post_office_history] TILFØJ FILGROUP [MAJ]ÆNDRE DATABASE [post_office_history] TILFØJ FILGROUP [JUN]ALTER DATABASE [post_office_GROUP] ] TILFØJ FILGRUPPE [AUG]ÆNDRE DATABASE [post_kontorhistorie] TILFØJ FILGRUPPE [SEP]ÆNDRE DATABASE [post_kontorhistorie] TILFØJ FILGRUPPE [OKT]ÆNDRE DATABASE [post_kontorhistorie] TILFØJ FILGRUPPE [NOV]OPSLAG ADDATABASE [NOV]HISTORIE]INDLÆG_ADATABASE [NOV]INDlæg_kontor-DATABASE 2:Tilføj datafiler til hver filgruppe --BRUG [master]GOALTER DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE =52K, TH, SIZE=1048576KB) TIL FILGRUPPE [JAN]ÆNDRE DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_office_history_part_02', FILENAME =N'E:\MSSQL\DATA\post_office_SISTORY_part_02.ndf', 5TH FIZE =5 FI 2 02.ndf') FEB]ÆNDRE DATABASE [post_office_history] TILFØJ FIL (NAVN =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB, FILEGROWATAB8TH =6097152KB, FILEGROWATAB8TH) [FILEGRO4ATAB8TH 7] FILEGRO4ATAB histo5] ] TILFØJ FIL (NAVN =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', STØRRELSE =2097152KB, FILEGROWTH =1048576KB) [DATAFIATERASELEHISTORY_GROUP]DATAFIATERASELEhistory_GROUP N'post_office_history_part_05', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', STØRRELSE =2097152KB, FILEGROWTH =1048576KB) TIL FILEGROUP [MATA_BESTILLING_NAVN AATA_NAVN AATA_BILAG_NAVN [MATA_NAVN AATA_DATA_FILE_NAVN AATA_FILE_NAVN [MATA_NAVN_AATA_0] =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', STØRRELSE =2097152KB, FILEGROWTH =1048576KB) TIL FILGRUPPE [JUN]ÆNDRE DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_office_history_part_07', FILETAMShistory\n_07_07, FILEMShistory =n_2, FILEMShistory =n_2, FILEMShistory =N_1_0, FILETAMS_07_07:\DATAMS history =n_2, 5 , FILEGROWTH =1048576KB) TIL FILEGROUP [JUL]ÆNDRING DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_5, 7B_08.ZEndfGRO_1, 7B, 7B, 7K, 7B, 7B, 7B, 7B, 7B, 7B, 1, 5 FILEGROUP [AUG]ÆNDRE DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =2097152KATED] =2097152KATERIEL TO 7FILEBATAW, 1FILEBATAW, 1097152K1. [post_office_history] TILFØJ FIL (NAVN =N'post_office_history_part_10', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', STØRRELSE =2097152KB, FILEGROWTH =10B485]post_office_history_TOTA NAME =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', STØRRELSE =2097152KB, FILEGROWTH =1048576KB) TIL FILGRUPPE [NOV]ÆNDRE DATABASE [post_office_history] TILFØJ FIL (NAME =N'post_part_office_0ATA:N_post_FILE_0.AFT\LIST_OFFICE_NAME:N'post_FILE_0TA\\\\\DATA\DATA_OFFICE_1' ndf', STØRRELSE =2097152KB, FILEGROWTH =1048576KB) TIL FILGRUPPE [DEC]GO-- Trin 3:Opret partitionsskema --PRINT 'opretter partitionsskema ...'GOUSE [post_office_history]GOCREATE PARTITIONSSCHEME TOTPNcFunart ,FEB,MAR,APR,MAJ,JUN,JUL,AUG,SEP,OKT,NOV,DEC)GO
Bemærk, at for N partitioner, vil der altid være N-1 grænser. Der skal udvises forsigtighed, når den første filgruppe i partitionsskemaet defineres. Den første grænse, der er angivet i partitionsfunktionen, vil ligge mellem den første og anden filgruppe, så denne grænseværdi (20190201) vil sidde i den anden partition (FEB). Derudover er det faktisk muligt at placere alle partitioner i en enkelt filgruppe, men vi har valgt separate filgrupper i dette tilfælde.
Beskidte hænder
Så lad os dykke ned i opgaven med at skifte partitioner ud!
Den første ting, vi skal gøre, er at bestemme præcis, hvordan vores data er fordelt mellem partitionerne, så vi kan vide, hvilken partition vi gerne vil skifte ud. Typisk vil vi skifte den ældste partition ud.
-- Liste 3:Tjek datadistribution i partitioner --BRUG POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) SOM [PARTITIONSNUMMER] , MIN(DATETIME_TRAN_LOCAL) SOM [MIN DATO] , MAX(DATETIME_TRAN_LOCAL) AS, [MAXLOCALDATE] TÆL(*) SOM [RÆKKER I PARTITION]FRA DBO.POST_TRAN_TAB -- OPDELT TABELGRUPPE AF $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL)ORDER AF [PARTITIONSNUMMER]GO
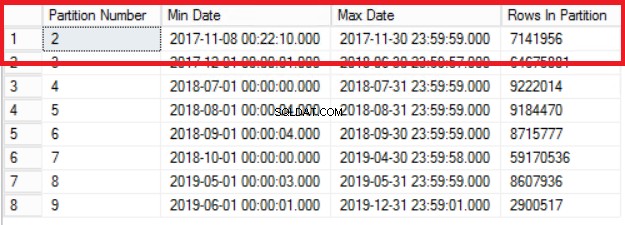
Fig. 1 Output af liste 3
Fig. 1 viser os outputtet af forespørgslen i Listing 3. Den ældste partition er Partition 2, som indeholder rækker fra år 2017. Vi bekræfter dette med forespørgslen i Listing 4. Liste 4 viser os også, hvilken filgruppe der har dataene i Partition 2.
-- Liste 4:Tjek filgruppe tilknyttet partition --BRUG POST_OFFICE_HISTORYGOSELECT PS.NAME SOM PS (T.OBJECT_ID =I.OBJECT_ID)) INNER JOIN SYS.PARTITION_SCHEMES AS PS ON (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) INNER JOIN SYS.DESTINATION_DATA_SPACES SOM DDS ON (PS.DATA_SPACE_PARTIID) DYS.SCHEM. FILEGROUPS AS FG ON DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') OG (I.INDEX_ID IN (0,1)) OG DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('201)711;>
Fig. 1 Output af liste 3
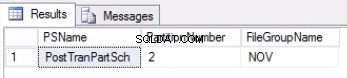
Fig. 2 Output af liste 4
Liste 4 viser os, at filgruppen forbundet med partition 2 er NOV . For at skifte partition 2 ud, har vi brug for en historietabel, som er en replika af live-tabellen, men som sidder på samme filgruppe som den partition, vi har til hensigt at skifte ud. Da vi allerede har denne tabel, er alt, hvad vi behøver, at genskabe den på den ønskede filgruppe. Du skal også genskabe det klyngede indeks. Bemærk, at dette klyngede indeks har samme definition som det klyngede indeks i tabellen post_tran_tab og sidder også i den samme filgruppe som post_tran_tab_hist tabel.
-- Liste 5:Genopret historietabellen -- Genopret historietabellen --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tabbo_hist] [post_tran_tabbo_hist.[ post_tran_tab_hist]( [tran_nr] [bigint] IKKE NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4) ) NULL, [kildenode_navn] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node]cur [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) IKKE NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) ) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [tran_cash_rsp] [tran_cash_rsp] [float_]mt ] [char](10) NULL, [købmandstype] [char](4) NULL, [pos_entry_mode] [char] (3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [ rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved ] [float] IKKE NULL, [tran_completed] [char](2) NULL) PÅ [NOV] GOSET ANSI_PADDING OFFGO-- Genopret det Clustered Index --USE [post_office_history]GO OPRET CLUSTERED INDEX [IX_Datetime_Local] PÅ [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) MED (PAD_INDEX =OFF, STATISTICS_DRORECOMPUTE =OFFLINE =OFFLINE =OFFLINE =OFF, SORT_IN__EX , ALLOW_ROW_LOCKS =TIL, ALLOW_PAGE_LOCKS =TIL) PÅ [NOV]GO
Udskiftning af den sidste partition er nu en kommando på én linje. At tage en optælling af begge tabeller før og efter udførelse af denne en-linje kommando vil give en forsikring om, at vi har alle de ønskede data.
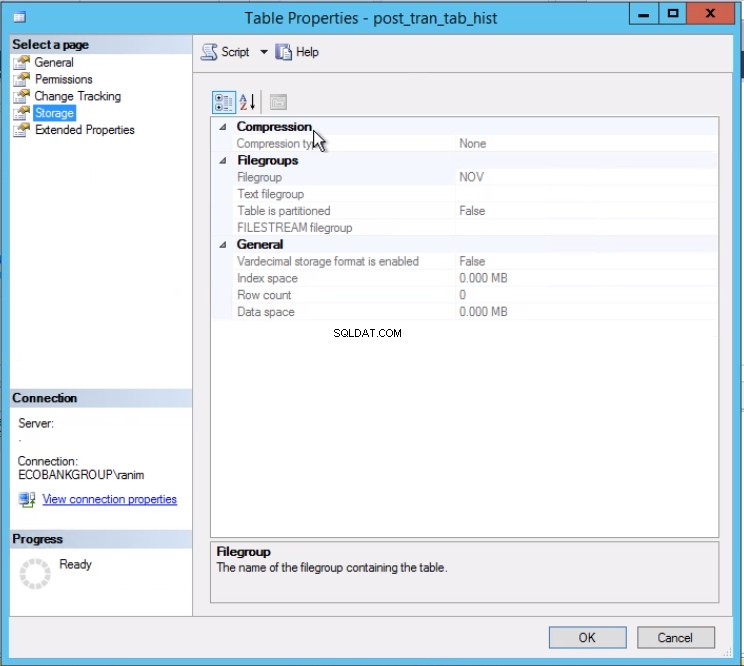
Fig. 3 Tabel post_tran_tab_hist sidder på NOV-filgruppen
-- Liste 6:Udskiftning af den sidste partitionSELECT COUNT(*) FROM 'POST_TRAN_TAB';SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';USE [POST_OFFICE_HISTORY]GOALTER TABEL POST_TRAN_TAB SWITCH COUNT_TRAN_TAB' POST_TRAN_TAB';VÆLG COUNT(*) FRA 'POST_TRAN_TAB_HIST';
Da vi har skiftet den sidste partition ud, har vi ikke længere brug for grænsen. Vi fletter de to områder, der tidligere var opdelt af denne grænse, ved hjælp af kommandoen i liste 7. Vi afkorter historiktabellen yderligere som vist i liste 8. Vi gør dette, fordi dette er hele pointen:at fjerne gamle data, som vi ikke længere har brug for.
-- Liste 7:Fletning af partitionsintervaller-- Merge RangeUSE [POST_OFFICE_HISTORY]GOALTER PARTITION FUNCTION POSTTRANPARTFUNC() FLETNINGSOMRÅDE ('20171101');-- Bekræft, at området er fusioneretUSE [POST_OFFICE_HISTORY]SGOSELECT_PARTIGOROM *FANGERYS.>
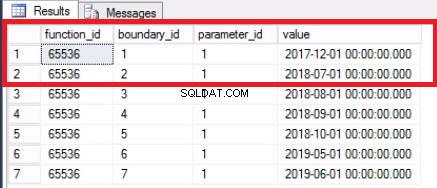
Fig. 4 Grænse sammenlagt
-- Liste 8:Truncate the History TableUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO
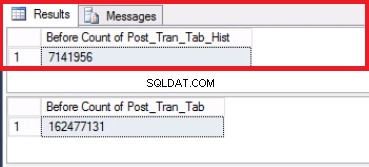
Fig. 5 Rækketælling for begge tabeller før trunkering
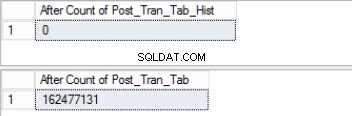
Bemærk, at antallet af rækker i historiktabellen er nøjagtigt det samme som antallet af rækker tidligere i partition 2 som vist i fig. 1. Du kan også gå den ekstra mil ved at genvinde den tomme plads i filgruppen, der hører til den sidste. skillevæg. Dette vil være nyttigt, hvis du har brug for denne plads til de nye data, der vil sidde på den tidligere partition. Dette trin er muligvis ikke nødvendigt, hvis du føler, at du har rigelig plads i dit miljø.
-- Liste 9:Gendan plads på operativsystemet-- Bestem, at filen er blevet tømtUSE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS PÅ DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;
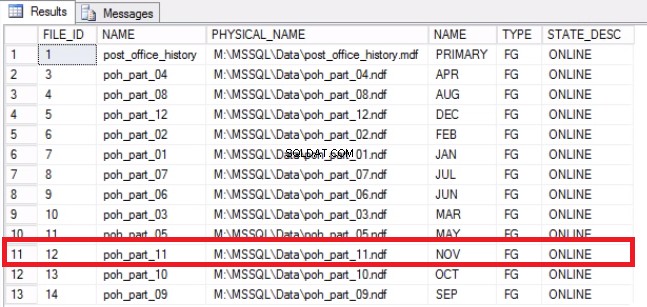
Fig. 7 Fil til filgruppetilknytning
-- Formindsk filen til 2GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- Fra OS bekræft ledig plads på diskeVÆLG DISTINCT DB_NAME (S.DATABASE_ID) AS DATA.DATA_BASE_NAME,SID. VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/104/24/1024/1024/1024 GB], VENSTRE ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) SOM PERCENT_FRIT FRA SYS.MASTER_FILES SOM FCROSS ANVENDELSE SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.DATABASE_ID, F.FILESWHEREID) (S.DATABASE_ID) ='POST_OFFICE_HISTORY';

Fig. 8 Ledig plads på operativsystemet
Konklusion
I denne artikel har vi lavet en gennemgang af processen for at skifte partitioner fra en opdelt tabel. Dette er en meget effektiv måde at administrere datavækst native i SQL Server. Mere avancerede teknologier såsom Stretch Database er tilgængelige i nuværende versioner af SQL Server.
Referencer
Isakov, V. (2018). Eksamen Ref 70-764 Administration af en SQL-databaseinfrastruktur. Pearson Education
Partitionerede tabeller og indekser i SQL Server