Hvert produkt har fejl, og SQL Server er ingen undtagelse. At bruge produktfunktioner på en lidt usædvanlig måde (eller at kombinere relativt nye funktioner sammen) er en fantastisk måde at finde dem på. Fejl kan være interessante og endda lærerige, men måske går nogle af glæderne tabt, når opdagelsen resulterer i, at din personsøger går i gang kl. 04.00, måske efter en særlig social aften med venner...
Fejlen, der er emnet for dette indlæg, er nok rimelig sjælden i naturen, men det er ikke en klassisk kantsag. Jeg kender til mindst én konsulent, der er stødt på det i et produktionssystem. Med hensyn til et helt ubeslægtet emne, bør jeg benytte lejligheden til at sige "hej" til Grumpy Old DBA (blog).
Jeg vil starte med noget relevant baggrund om merge joins. Hvis du er sikker på, at du allerede ved alt, hvad der er at vide om merge join, eller bare ønsker at komme til benet, er du velkommen til at rulle ned til afsnittet med titlen "The Bug."
Flet tilmelding
Merge join er ikke en særlig kompliceret ting og kan være meget effektiv under de rigtige omstændigheder. Det kræver, at dets input er sorteret på join-tasterne og fungerer bedst i en-til-mange-tilstand (hvor i det mindste af dets input er unikke på join-tasterne). For moderat størrelse en-til-mange joinforbindelser er seriel merge join overhovedet ikke et dårligt valg, forudsat at inputsorteringskravene kan opfyldes uden at udføre en eksplicit sortering.
At undgå en sortering opnås oftest ved at udnytte rækkefølgen fra et indeks. Merge join kan også drage fordel af bevaret sorteringsrækkefølge fra en tidligere, uundgåelig sortering. En cool ting ved merge join er, at den kan stoppe med at behandle inputrækker, så snart begge input løber tør for rækker. En sidste ting:Merge join er ligeglad med, om sorteringsrækkefølgen for input er stigende eller faldende (selvom begge input skal være ens). Følgende eksempel bruger en standard Numbers-tabel til at illustrere de fleste af punkterne ovenfor:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Bemærk, at de indekser, der håndhæver de primære nøgler på disse to tabeller, er defineret som faldende. Forespørgselsplanen for INSERT har en række interessante funktioner:
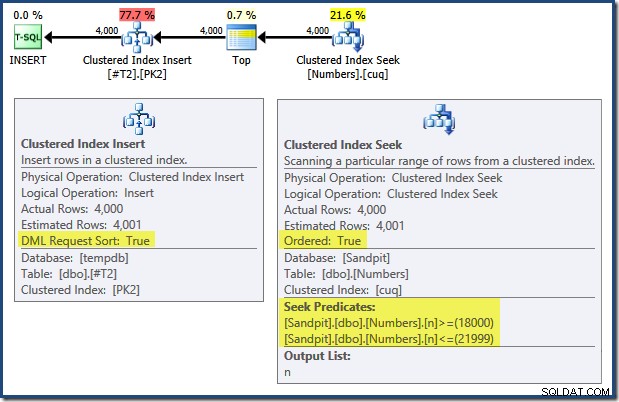
Læses fra venstre mod højre (som kun er fornuftigt!) har Clustered Index Insert egenskabssættet "DML Request Sort". Dette betyder, at operatøren kræver rækker i Clustered Index nøglerækkefølge. Det klyngede indeks (der håndhæver den primære nøgle i dette tilfælde) er defineret som DESC , så rækker med højere værdier skal ankomme først. Det klyngede indeks på min Numbers-tabel er ASC , så forespørgselsoptimeringsværktøjet undgår en eksplicit sortering ved først at søge efter det højeste match i taltabellen (21.999) og derefter scanne mod det laveste match (18.000) i omvendt indeksrækkefølge. "Plan Tree"-visningen i SQL Sentry Plan Explorer viser den omvendte (bagud) scanning tydeligt:
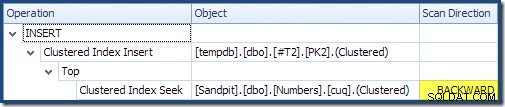
Baglæns scanning vender den naturlige rækkefølge af indekset. En baglæns scanning af en ASC indeksnøgle returnerer rækker i faldende nøglerækkefølge; en baglæns scanning af en DESC indeksnøgle returnerer rækker i stigende nøglerækkefølge. "Scanningsretningen" angiver ikke returneret nøglerækkefølge i sig selv – du skal vide, om indekset er ASC eller DESC at træffe den beslutning.
Brug af disse testtabeller og data (T1 har 10.000 rækker nummereret fra 10.000 til 19.999 inklusive; T2 har 4.000 rækker nummereret fra 18.000 til 21.999) følgende forespørgsel forbinder de to tabeller og returnerer resultater i faldende rækkefølge af begge nøgler:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Forespørgslen returnerer de korrekte matchende 2.000 rækker, som du ville forvente. Efterudførelsesplanen er som følger:
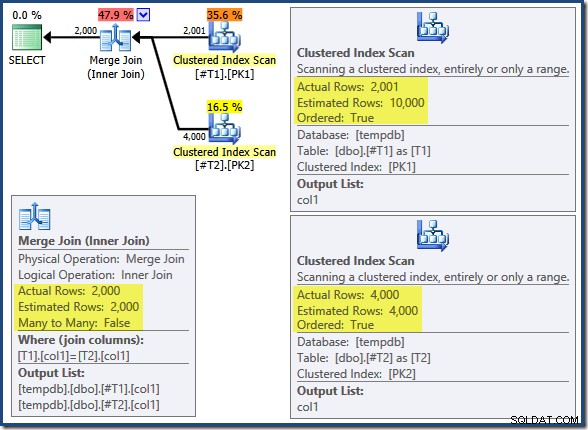
Merge Join kører ikke i mange-til-mange-tilstand (det øverste input er unikt på join-tasterne), og vurderingen af 2.000 rækkers kardinalitet er nøjagtigt korrekt. Clustered Index Scan af tabel T2 er bestilt (selvom vi skal vente et øjeblik for at finde ud af, om den rækkefølge er fremad eller bagud), og kardinalitetsestimatet på 4.000 rækker er også helt rigtigt. Clustered Index Scan af tabel T1 er også bestilt, men kun 2.001 rækker blev læst, hvorimod 10.000 blev anslået. Plantrævisningen viser, at begge Clustered Index Scans er bestilt frem:
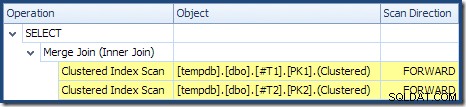
Husk at læse en DESC indeks FORWARD vil producere rækker i omvendt nøglerækkefølge. Det er præcis, hvad der kræves af ORDER BY T1.col DESC, T2.col1 DESC klausul, så ingen eksplicit sortering er nødvendig. Pseudo-kode for én-til-mange Merge Join (gengivet fra Craig Freedmans Merge Join-blog) er:

Den faldende rækkefølge scanning af T1 returnerer rækker, der starter ved 19.999 og arbejder ned mod 10.000. Den faldende rækkefølge scanning af T2 returnerer rækker, der starter ved 21.999 og arbejder ned mod 18.000. Alle 4.000 rækker i T2 læses til sidst, men den iterative fletteproces stopper, når nøgleværdi 17.999 læses fra T1 , fordi T2 løber tør for rækker. Sammenfletningsbehandling afsluttes derfor uden at læse T1 fuldstændigt . Den læser rækker fra 19.999 ned til 17.999 inklusive; i alt 2.001 rækker som vist i udførelsesplanen ovenfor.
Kør gerne testen igen med ASC indekserer i stedet, og ændrer også ORDER BY klausul fra DESC til ASC . Den fremstillede udførelsesplan vil være meget ens, og der vil ikke være behov for sorteringer.
For at opsummere de punkter, der vil være vigtige om et øjeblik, kræver Merge Join join-nøglesorterede input, men det er lige meget, om tasterne er sorteret stigende eller faldende.
Bugen
For at reproducere fejlen skal mindst én af vores tabeller partitioneres. For at holde resultaterne håndterbare vil dette eksempel kun bruge et lille antal rækker, så partitioneringsfunktionen har også brug for små grænser:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Den første tabel indeholder to kolonner og er opdelt på den PRIMÆRE NØGLE:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Den anden tabel er ikke opdelt. Den indeholder en primær nøgle og en kolonne, der vil slutte sig til den første tabel:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Eksempeldataene
Den første tabel har 14 rækker, alle med samme værdi i SomeID kolonne. SQL Server tildeler IDENTITY kolonneværdier, nummereret 1 til 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Den anden tabel er simpelthen udfyldt med IDENTITY værdier fra tabel et:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Dataene i de to tabeller ser således ud:
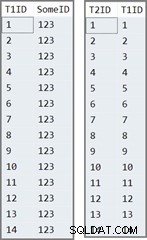
Testforespørgslen
Den første forespørgsel forbinder simpelthen begge tabeller ved at anvende et enkelt WHERE-sætningsprædikat (som tilfældigvis matcher alle rækker i dette meget forenklede eksempel):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Resultatet indeholder alle 14 rækker, som forventet:

På grund af det lille antal rækker vælger optimeringsværktøjet en indlejret sløjfer-sammenføjningsplan for denne forespørgsel:
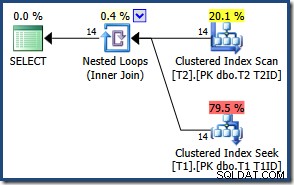
Resultaterne er de samme (og stadig korrekte), hvis vi tvinger en hash- eller flette-join:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
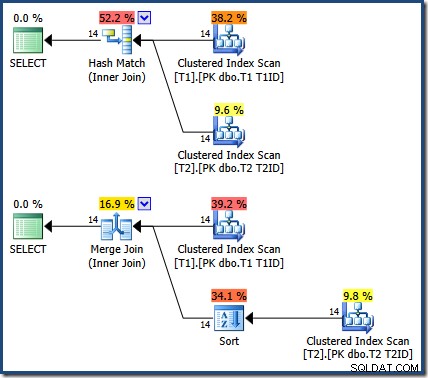
Merge Join der er én-til-mange, med en eksplicit sortering på T1ID påkrævet til tabel T2 .
Det faldende indeksproblem
Alt er godt, indtil en dag (af gode grunde, som ikke behøver at bekymre os her) en anden administrator tilføjer et faldende indeks på SomeID kolonne i tabel 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Vores forespørgsel fortsætter med at give korrekte resultater, når optimeringsværktøjet vælger en Nested Loops eller Hash Join, men det er en anden historie, når en Merge Join bruges. Det følgende bruger stadig et forespørgselstip til at tvinge sammenfletningen, men dette er kun en konsekvens af det lave antal rækker i eksemplet. Optimizeren ville naturligvis vælge den samme Merge Join-plan med forskellige tabeldata.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Udførelsesplanen er:
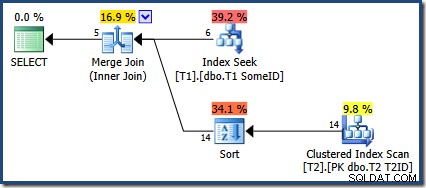
Optimizeren har valgt at bruge det nye indeks, men forespørgslen producerer nu kun fem rækker med output:

Hvad skete der med de andre 9 rækker? For at være klar, er dette resultat forkert. Dataene er ikke ændret, så alle 14 rækker skal returneres (som de stadig er med en Nested Loops eller Hash Join-plan).
Årsag og forklaring
Det nye ikke-klyngede indeks på SomeID er ikke erklæret som unik, så den klyngede indeksnøgle føjes lydløst til alle ikke-klyngede indeksniveauer. SQL Server tilføjer T1ID kolonne (den klyngede nøgle) til det ikke-klyngede indeks, ligesom hvis vi havde oprettet indekset sådan her:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Bemærk manglen på en DESC qualifier på det lydløst tilføjede T1ID nøgle. Indeksnøgler er ASC som standard. Dette er ikke et problem i sig selv (selvom det bidrager). Den anden ting, der automatisk sker med vores indeks, er, at det er opdelt på samme måde som basistabellen. Så den fulde indeksspecifikation, hvis vi skulle skrive den eksplicit, ville være:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Dette er nu en ret kompleks struktur, med nøgler i alle mulige forskellige rækkefølger. Det er komplekst nok til, at forespørgselsoptimeringsværktøjet tager fejl, når det ræsonnerer om sorteringsrækkefølgen fra indekset. For at illustrere, overvej følgende enkle forespørgsel:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Den ekstra kolonne vil blot vise os, hvilken partition den aktuelle række hører hjemme i. Ellers er det blot en simpel forespørgsel, der returnerer T1ID værdier i stigende rækkefølge, WHERE SomeID = 123 . Desværre er resultaterne ikke det, der er angivet af forespørgslen:
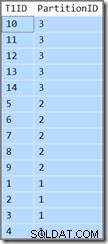
Forespørgslen kræver, at T1ID værdier skal returneres i stigende rækkefølge, men det er ikke det, vi får. Vi får værdier i stigende rækkefølge pr. partition , men selve partitionerne returneres i omvendt rækkefølge! Hvis partitionerne blev returneret i stigende rækkefølge (og T1ID værdier forblev sorteret inden for hver partition som vist), ville resultatet være korrekt.
Forespørgselsplanen viser, at optimeringsværktøjet blev forvirret af den førende DESC nøglen til indekset, og mente, at det var nødvendigt at læse partitionerne i omvendt rækkefølge for korrekte resultater:
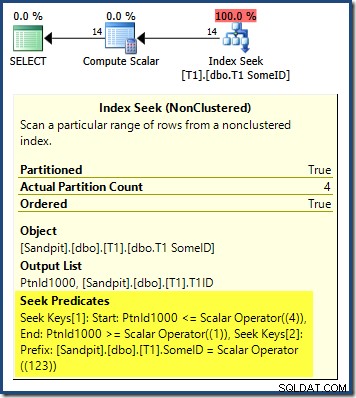
Partitionssøgningen starter ved partitionen længst til højre (4) og fortsætter baglæns til partition 1. Du tror måske, at vi kunne løse problemet ved eksplicit at sortere efter partitionsnummer ASC i ORDER BY klausul:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Denne forespørgsel giver de samme resultater (dette er ikke en trykfejl eller en copy/paste-fejl):
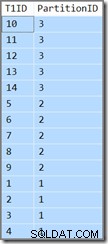
Partitions-id'et er stadig faldende rækkefølge (ikke stigende, som specificeret) og T1ID er kun sorteret stigende inden for hver partition. Sådan er optimizerens forvirring, den tror virkelig (tag en dyb indånding nu), at scanning af det partitionerede indeks for ledende-faldende nøgle i en fremadgående retning, men med omvendte partitioner, vil resultere i den rækkefølge, der er angivet af forespørgslen.
Jeg bebrejder det ikke for at være ærlig, de forskellige sorteringsrækkefølge-overvejelser gør også, at jeg får ondt i hovedet.
Som et sidste eksempel kan du overveje:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Resultaterne er:

Igen, T1ID sorteringsrækkefølge inden for hver partition er korrekt faldende, men selve partitionerne er listet baglæns (de går fra 1 til 3 ned ad rækkerne). Hvis partitionerne blev returneret i omvendt rækkefølge, ville resultaterne korrekt være 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Tilbage til Merge Join
Årsagen til de forkerte resultater med Merge Join-forespørgslen er nu tydelig:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
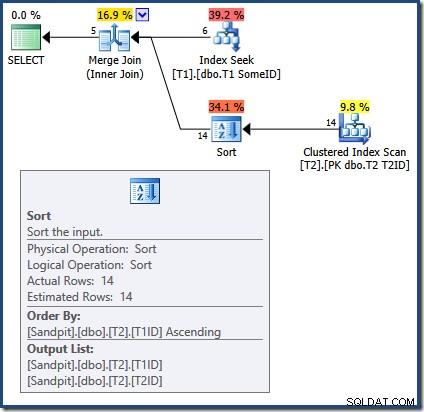
Merge Join kræver sorterede input. Inputtet fra T2 er eksplicit sorteret efter T1TD så det er ok. Optimizeren begrunder forkert, at indekset på T1 kan levere rækker i T1ID bestille. Som vi har set, er dette ikke tilfældet. Indekssøgningen producerer det samme output som en forespørgsel, vi allerede har set:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Kun de første 5 rækker er i T1ID bestille. Den næste værdi (5) er bestemt ikke i stigende rækkefølge, og Merge Join fortolker dette som end-of-stream snarere end at producere en fejl (personligt forventede jeg en detailpåstand her). Under alle omstændigheder er effekten, at Merge Join fejlagtigt afslutter behandlingen tidligt. Som en påmindelse er de (ufuldstændige) resultater:

Konklusion
Dette er en meget alvorlig fejl efter min mening. En simpel indekssøgning kan returnere resultater, der ikke respekterer ORDER BY klausul. Mere til sagen er optimizerens interne ræsonnement fuldstændig brudt for partitionerede ikke-unikke ikke-klyngede indekser med en faldende indledende nøgle.
Ja, dette er en lidt usædvanlige arrangement. Men som vi har set, kan korrekte resultater pludselig erstattes af forkerte resultater, bare fordi nogen tilføjede et faldende indeks. Husk det tilføjede indeks så uskyldigt nok ud:ingen eksplicit ASC/DESC nøglemismatch og ingen eksplicit partitionering.
Fejlen er ikke begrænset til Merge Joins. Potentielt kan enhver forespørgsel, der involverer en opdelt tabel, og som er afhængig af indekssorteringsrækkefølge (eksplicit eller implicit), blive ofre. Denne fejl findes i alle versioner af SQL Server fra 2008 til 2014 CTP 1 inklusive. Windows SQL Azure Database understøtter ikke partitionering, så problemet opstår ikke. SQL Server 2005 brugte en anden implementeringsmodel til partitionering (baseret på APPLY ) og lider heller ikke af dette problem.
Hvis du har et øjeblik, kan du overveje at stemme på mit Connect-emne for denne fejl.
Opløsning
Løsningen til dette problem er nu tilgængelig og dokumenteret i en Knowledge Base-artikel. Bemærk venligst, at rettelsen kræver en kodeopdatering og sporingsflag 4199 , som muliggør en række andre ændringer i forespørgselsprocessoren. Det er usædvanligt, at en fejl med ukorrekte resultater bliver rettet under 4199. Jeg bad om en forklaring på det, og svaret var:
Selvom dette problem involverer forkerte resultater som andre hotfixes, der involverer forespørgselsprocessoren, har vi kun aktiveret denne rettelse under sporingsflag 4199 for SQL Server 2008, 2008 R2 og 2012. Denne rettelse er dog "til" af standard uden sporingsflaget i SQL Server 2014 RTM.