Bemærk:Denne artikel viser migreringen af en relationsdatabasemodel (RDB) til stjerneskema ved hjælp af Eclipse IDE for Voracity (og dets inkluderede produkter), IRI Workbench, efter en introduktion til begge arkitekturer. Hvis du er interesseret i at migrere din RDB eller data til en Data Vault 2.0-model, vil en ny Workbench-guide debutere på World Wide Data Vault Consortium i maj 2019; abonner på IRI-bloggen for at få disse trin-for-trin instruktioner, så snart de udgives!
Et datavarehus (DW) er en samling af data, der er udtrukket fra det operationelle eller transaktionsmæssige system i en virksomhed, transformeret for at rydde op i uoverensstemmelser og derefter arrangeret til at understøtte hurtig analyse og/eller rapportering. DW'en kræver et skema eller en logisk beskrivelse og grafisk repræsentation af dens operationelle database. Denne artikel berører disse emner og giver samtidig en vejledning i at flytte fra et konventionelt relationsdatabaseskema til et populært DW-skema kaldet stjerneskema.
Stjerneskema vs. Relationelt
De fleste relationelle datastrukturer er illustreret i entity-relationship (ER) diagrammer. Et ER-diagram bruges i udviklingen af konceptuelle modeller for et OLTP-databaseadministrationssystem (online transaktionsbehandling). Det er kilden, hvorfra tabelstrukturen er oversat.
Stjerneskemaet er imidlertid den bredt accepterede standard for den underliggende tabelstruktur i et datavarehus. Dens simple stjerneform (når ER-diagrammet) viser faktatabellen (indeholder transaktionsværdier eller mål) i midten, og dimensionstabeller (indeholder beskrivende eller attributive værdier), der udstråler fra den. Normalt er faktatabellen i tredje-normal form (3NF), mens dimensionelle tabeller er denormaliserede.
De grundlæggende forskelle mellem en enhedsrelationel (ER) model og en stjernemodel er at:
- ER-modeller bruger logiske og fysiske strukturer til normaliseret databasedesign
- Dimensionsmodeller bruger en fysisk struktur til denormaliseret databasedesign
Klik her for at se, hvordan IRI-software kan de/normalisere data gennem række-kolonne pivotering.
Baggrund for konverteringsproces
I denne artikel demonstrerer jeg, hvordan man konverterer data fra en relationsmodel til stjerne ved hjælp af job, som du burde definere mere eller mindre manuelt, men som du kan oprette og køre automatisk og nemt ændre.
Det, du vil se her, er IRIs 4GL-data og jobspecifikationer - udtrykt i "SortCL"-scripts[1] - der kortlægger data til dimensionstabeller og samler data til den centrale faktatabel. SortCL er kerneprogrammet til datamanipulation og kortlægning i IRI Voracity dataadministration og ETL-platformen. Men at forstå metodikken og kortlægningerne i mine SortCL jobs er nøglen her, ikke scriptsyntaksen.
Den gratis Eclipse GUI, IRI Workbench, leverer en syntaks-bevidst SortCL-editor samt grafiske konturer og dialogbokse, workflow- og kortlægningsdiagrammer og intuitive jobguider til automatisk at bygge eller ændre disse scripts, hvis du ikke ønsker at gøre det med hånden. FYI, IRI bruger de samme metadata og GUI til profilering og diagrammer af DB'er, generering af testdata, udførelse af ETL, formatering af rapporter, maskering af PII, indsamling af ændrede data, migrering og replikering af data, rensning og validering af data osv.
Workbench bruger en forbedret version af Data Tools Platform (DTP) plug-in til Eclipse til at oprette forbindelse til databaser over JDBC og for at aktivere SQL-operationer og IRI-metadataudveksling i Data Source Explorer-visningen (DSE). I dette tilfælde understøtter Workbench:
- oprettelse og population af begrænsede Oracle-testtabeller (kilde) via SortCL (eller IRI RowGen jobs, ifølge denne artikel)
- tilknytningen af entitetstabeldata til dimensionstabeller via SortCL
- kortlægningen af faktaelementer som en nær relation til at associere principdimensionstabellen; dvs. at udføre en multi-table join i SortCL for at skabe faktatabellen
- population af alle måltabeller (stjerneskema)
- ER-diagrammer over kilde- og målskemaerne
Entitetstyperne i min oprindelige relationsmodel er:Afdeling, Emp, Projekt, Kategori, Vare, Vare_Brug og Salg:
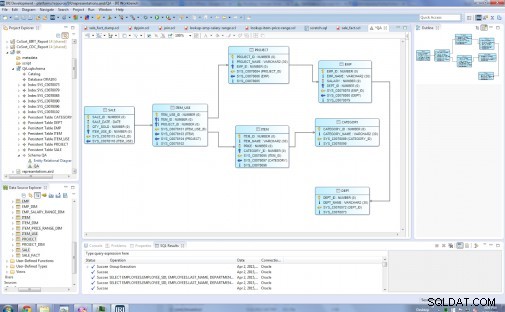
Før …
Det næste diagram viser den endelige stjernemodel med otte dimensionstabeller og en faktatabel. Dimensionstabellerne er: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Faktatabellen i midten er Sale_Fact, som indeholder nøgler til alle dimensionstabellerne.

... Efter
Konverteringstrin
- Definer og opret faktatabellen
Strukturen for Sale_Fact-tabellen er vist i dette dokument. Den primære nøgle er sale_id, og resten af attributterne er fremmednøgler, der er nedarvet fra dimensionstabellerne. Jeg bruger en Oracle-database (selvom enhver RDB virker) forbundet til Workbench DSE (via JDBC) og SortCL til datatransformation og mapping ( via ODBC). Jeg oprettede mine tabeller i SQL-scripts redigeret i DSE's SQL scrapbog og udført i Workbench.
- Definer og opret dimensionstabellerne
Brug samme teknik og metadata, der er linket ovenfor til at oprette disse dimensionstabeller, der vil modtage de relationelle data, der er kortlagt fra SortCL-jobs i det næste trin:Category_Dim-tabel, Dept to Dept_Dim, Project to Project_Dim, Item to Item_Dim og Emp to Emp_Dim. Du kan køre det .SQL-program med hele CREATE-logikken på én gang for at bygge tabellerne.
- Flyt de originale enhedstabeldata til dimensionstabellerne
Definer og kør de SortCL-job, der vises her, for at kortlægge (RowGen-oprettede test) data fra relationsskemaet til dimensionstabeller for Star-skemaet. Specifikt indlæser disse scripts data fra kategoritabellen til kategorien Kategori_Dim, Dept til Afd._Dim, Projekt til Project_Dim, Item til Item_Dim og Emp til Emp_Dim.
- Udfyld faktatabellen
Brug SortCL til at samle data fra originale Salg, Emp, Project, Item_Use, Item, Category entitetstabeller for at forberede data til den nye Sale_Fact-tabel. Brug det andet (deltag job) script her.
For at forbedre vores eksempel vil vi også bruge SortCL til at introducere nye dimensionelle data i Star-skemaet, som min faktatabel også vil stole på. Du kan se disse yderligere tabeller i stjernediagrammet ovenfor, som ikke var i mit relationsskema:Emp_Salary_Range_Dim og Item_Price_Range_Dim. Disse tabeller oprettes i den samme .SQL-fil til faktatabellerne og andre dimensionstabeller.
Faktatabellen skal bruge dataene emp_salary_range_id og item_price_range_id fra disse tabeller for at repræsentere værdiintervallet i disse dimensionstabeller. Når jeg f.eks. indlæser de dimensionelle prisværdier i datavarehuset, vil jeg tildele dem til et prisinterval:
| Vare_pris | Range_Id | Range_Name | Range_End |
|---|---|---|---|
| 1 | Lav | 1 | 100 |
| 2 | Midt | 101 | 500 |
| 3 | Høj | 501 | 999 |
Den enkleste måde at tildele område-id'er i jobscriptet (det er at forberede data til min Sale_Fact-tabel) er at bruge en IF-THEN-ELSE-sætning i outputsektionen. Se denne artikel om bucketing-værdier for baggrund.
I hvert fald oprettede jeg hele dette job med CoSort New Join Job guiden i Workbench. Og da jeg kørte den, var min faktatabel udfyldt:
 Sale_Fact-tabelvisning i IRI Workbench DSE
Sale_Fact-tabelvisning i IRI Workbench DSE
Konklusion
Den største fordel ved dimensionel datarepræsentation er at reducere kompleksiteten af en databasestruktur. Dette gør databasen nemmere for folk at forstå og skrive forespørgsler imod ved at minimere antallet af tabeller og dermed antallet af krævede joinforbindelser. Som tidligere nævnt optimerer dimensionelle modeller også forespørgselsydeevne. Det har dog svaghed såvel som styrke. Stjerneskemaets faste struktur begrænser forespørgslerne. Så da det gør de mest almindelige forespørgsler nemme at skrive, begrænser det også måden, dataene kan analyseres på.
IRI Workbench GUI for Voracity har et kraftigt og omfattende sæt værktøjer, der forenkler dataintegration, herunder oprettelse, vedligeholdelse og udvidelse af datavarehuse. Med denne intuitive, brugervenlige grænseflade gør Voracity faciliterer hurtig, fleksibel, end-to-end ETL (ekstrahere, transformere, indlæse) procesoprettelse, der involverer datastrukturer på tværs af forskellige platforme.
I ETL-operationer udtrækkes data fra forskellige kilder, transformeres separat og indlæses i et datavarehus og muligvis andre mål. Opbygning af ETL-processen er potentielt en af de største opgaver ved at bygge et lager; det er komplekst og tidskrævende. IRIs ETL-tilgang understøtter denne proces på en yderst effektiv og databaseuafhængig måde ved at udføre al dataintegration og iscenesættelse i filsystemet.
[1] Hvis du er en syntakshund, skal du være opmærksom på, at SortCL-scripts, der bruges i IRI CoSort-produktet eller IRI Voracity-platformen, understøtter den samme syntaks og datadefinitioner som IRI RowGen til generering af testdata, IRI NextForm til datamigrering og IRI FieldShield til datamaskering. Alle disse værktøjer er alle understøttet i IRI Workbench GUI, og deres metadata kan også deles og teamadministreres til versionskontrol, job/datalinje og sikkerhed i skyen.
[2] Sådan viser du E-R-diagrammer i IRI Workbench:
- Vælg Nyt IRI-projekt, og opret en ny mappe
- Vælg den mappe, og fremhæv alle de relevante databasetabeller i Data Source Explorer; højreklik derefter på IRI, New ER-Diagram
- En fil (Schema.QA) vil blive oprettet
- Højreklik på den fil, og vælg Ny repræsentation, nyt enhedsrelationsdiagram.
[3] De elementer i ER-diagrammet, der illustrerer sådanne modeller, omfatter:
- definerede enhedstyper
- definerede attributter
- forholdet mellem enhedstyperne
- overordnet billede eller konceptuelt diagram
[4] IRI FACT og SQL*Loader er henholdsvis masseudtræk og indlæsningsmuligheder.