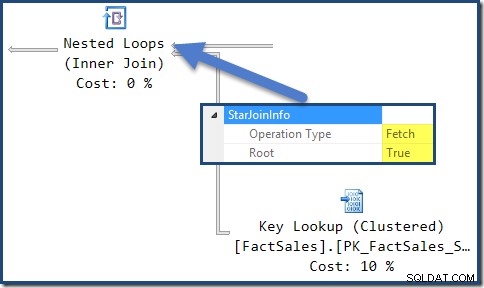
Fra tid til anden vil du måske bemærke, at en eller flere joinforbindelser i en eksekveringsplan er kommenteret med en StarJoinInfo struktur. Det officielle showplan-skema har følgende at sige om dette planelement (klik for at forstørre):
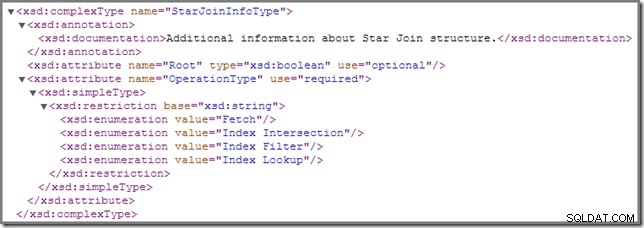
Den in-line-dokumentation, der vises der ("yderligere information om Star Join-struktur ") er ikke så oplysende, selvom de andre detaljer er ret spændende – vi vil se nærmere på disse.
Hvis du konsulterer din yndlingssøgemaskine for at få mere information ved hjælp af udtryk som "SQL Server star join optimization", vil du sandsynligvis se resultater, der beskriver optimerede bitmapfiltre. Dette er en separat Enterprise-only-funktion introduceret i SQL Server 2008 og ikke relateret til StarJoinInfo struktur overhovedet.
Optimeringer til selektive stjerneforespørgsler
Tilstedeværelsen af StarJoinInfo angiver, at SQL Server anvendte en af et sæt optimeringer målrettet mod selektive stjerneskemaforespørgsler. Disse optimeringer er tilgængelige fra SQL Server 2005 i alle udgaver (ikke kun Enterprise). Bemærk, at selektiv refererer her til antallet af rækker hentet fra faktatabellen. Kombinationen af dimensionelle prædikater i en forespørgsel kan stadig være selektiv, selv hvor dens individuelle prædikater kvalificerer et stort antal rækker.
Almindelig indekskryds
Forespørgselsoptimeringsværktøjet kan overveje at kombinere flere ikke-klyngede indekser, hvor et passende enkelt indeks ikke findes, som følgende AdventureWorks-forespørgsel viser:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Optimizeren bestemmer, at kombination af to ikke-klyngede indekser (et på SalesPersonID og den anden på CustomerID ) er den billigste måde at tilfredsstille denne forespørgsel på (der er intet indeks på begge kolonner):
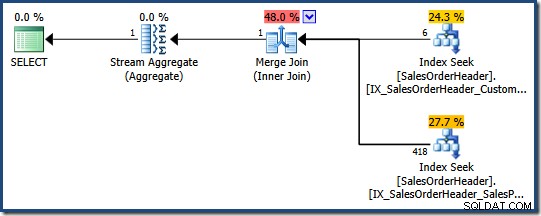
Hver indekssøgning returnerer den klyngede indeksnøgle for rækker, der passerer prædikatet. Sammenkædningen matcher de returnerede nøgler for at sikre, at kun rækker, der matcher begge prædikater videregives.
Hvis tabellen var en heap, ville hver søgning returnere heap row identifiers (RID'er) i stedet for klyngede indeksnøgler, men den overordnede strategi er den samme:find rækkeidentifikatorer for hvert prædikat, og match dem derefter.
Manuel Star Join Index Intersection
Den samme idé kan udvides til forespørgsler, der vælger rækker fra en faktatabel ved hjælp af prædikater anvendt på dimensionstabeller. For at se, hvordan dette fungerer, skal du overveje følgende forespørgsel (ved hjælp af Contoso BI-eksempeldatabasen) for at finde det samlede salgsbeløb for MP3-afspillere, der sælges i Contoso-butikker med præcis 50 ansatte:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Til sammenligning med senere bestræbelser producerer denne (meget selektive) forespørgsel en forespørgselsplan som den følgende (klik for at udvide):
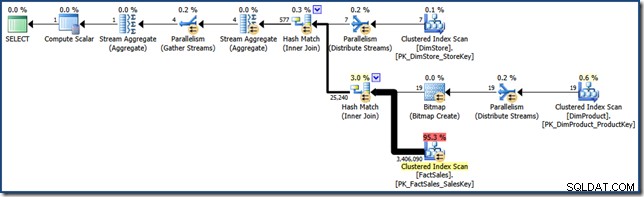
Den udførelsesplan har en anslået pris på lidt over 15,6 enheder . Den har parallel udførelse med en fuld scanning af faktatabellen (omend med et bitmapfilter anvendt).
Faktatabellerne i denne eksempeldatabase inkluderer ikke ikke-klyngede indekser på faktatabellens fremmednøgler som standard, så vi skal tilføje et par:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Med disse indekser på plads kan vi begynde at se, hvordan indekskryds kan bruges til at forbedre effektiviteten. Det første trin er at finde faktatabelrækkeidentifikatorer for hvert særskilt prædikat. Følgende forespørgsler anvender et enkelt dimensionsprædikat, og kom derefter tilbage til faktatabellen for at finde rækkeidentifikatorer (klyngede indeksnøgler i faktatabel):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Forespørgselsplanerne viser en scanning af tabellen med små dimensioner, efterfulgt af opslag ved hjælp af faktatabellens ikke-klyngede indeks for at finde rækkeidentifikatorer (husk ikke-klyngede indekser altid inkluderer basistabellens klyngenøgle eller heap RID):
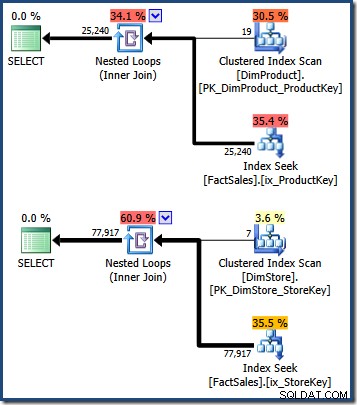
Skæringspunktet mellem disse to sæt faktatabel-klyngede indeksnøgler identificerer de rækker, der skal returneres af den oprindelige forespørgsel. Når vi har disse række-id'er, skal vi blot slå salgsbeløbet op i hver faktatabelrække og beregne summen.
Manuel indekskrydsningsforespørgsel
At sætte alt det sammen i en forespørgsel giver følgende:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK tip er der for at sikre, at vi får punktopslag til faktatabellen. Uden dette vælger optimizeren at scanne faktatabellen, hvilket er præcis det, vi søger at undgå. MAXDOP 1 tip hjælper bare med at holde den endelige plan i en rimelig størrelse til visningsformål (klik for at se den i fuld størrelse):
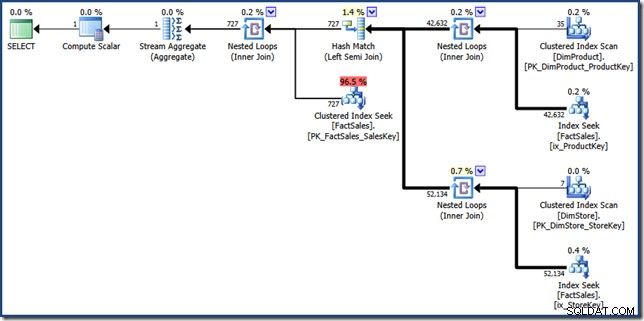
Komponentdelene af den manuelle indekskrydsningsplan er ret lette at identificere. De to faktatabel-ikke-klyngede indeksopslag på højre side producerer de to sæt faktatabelrække-id'er. Hash-sammenføjningen finder skæringspunktet mellem disse to sæt. Den grupperede indekssøgning i faktatabellen finder salgsbeløbene for disse række-id'er. Til sidst beregner Stream Aggregate det samlede beløb.
Denne forespørgselsplan udfører relativt få opslag i faktatabellen ikke-klyngede og klyngede indekser. Hvis forespørgslen er selektiv nok, kan dette meget vel være en billigere eksekveringsstrategi end at scanne faktatabellen fuldstændigt. Contoso BI-eksempeldatabasen er relativt lille med kun 3,4 millioner rækker i salgsfaktatabellen. For større faktatabeller kan forskellen mellem en fuld scanning og et par hundrede opslag være meget betydelig. Desværre introducerer den manuelle omskrivning nogle alvorlige kardinalitetsfejl, hvilket resulterer i en plan med en anslået pris på 46,5 enheder .
Automatisk Star Join Index skæring med opslag
Heldigvis behøver vi ikke at beslutte, om den forespørgsel, vi skriver, er selektiv nok til at retfærdiggøre denne manuelle omskrivning. Stjernetilslutningsoptimeringerne til selektive forespørgsler betyder, at forespørgselsoptimeringsværktøjet kan udforske denne mulighed for os ved at bruge den mere brugervenlige originale forespørgselssyntaks:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
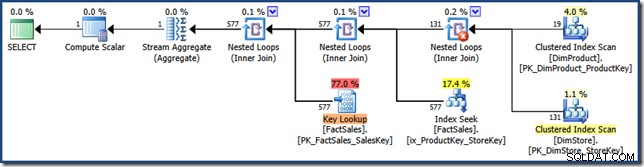
AND DP.ProductName LIKE N'%MP3%'; Optimizeren producerer følgende eksekveringsplan med en estimeret pris på 1,64 enheder (klik for at forstørre):
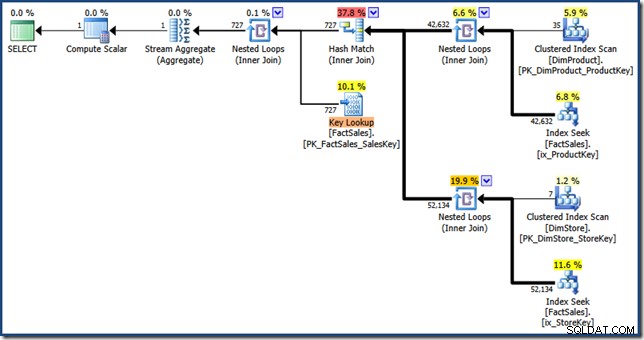
Forskellene mellem denne plan og den manuelle version er:indekskrydset er en indre sammenføjning i stedet for en semiforbindelse; og det klyngede indeksopslag vises som et nøgleopslag i stedet for et klynget indekssøgning. Med fare for at arbejde på pointen, hvis faktatabellen var en bunke, ville nøgleopslaget være et RID-opslag.
StarJoinInfo-egenskaberne
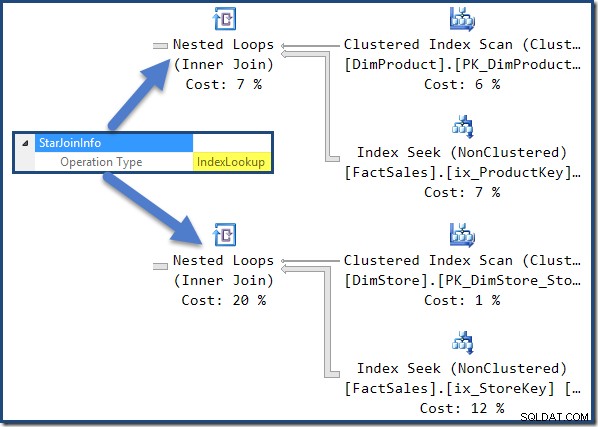
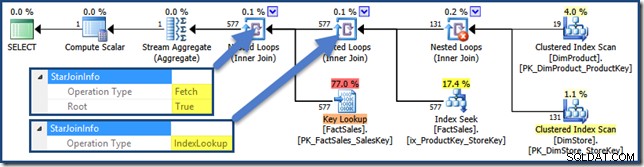
Deltagerne i denne plan har alle en StarJoinInfo struktur. For at se det skal du klikke på en join-iterator og se i vinduet SSMS-egenskaber. Klik på pilen til venstre for StarJoinInfo element for at udvide noden.
Den ikke-klyngede faktatabel forbindes til højre for planen er indeksopslag bygget af optimeringsværktøjet:
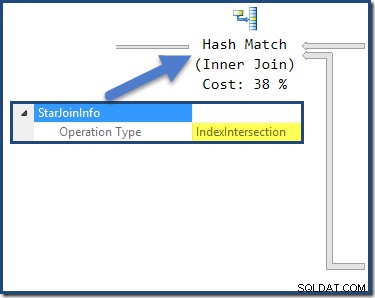
Hash-joinet har en StarJoinInfo struktur, der viser, at den udfører et indekskryds (igen, fremstillet af optimeringsværktøjet):
StarJoinInfo for den længst til venstre indlejrede løkker-sammenføjning viser, at den blev genereret for at hente faktatabelrækker efter række-id. Det er i roden af det optimizer-genererede stjerne join-undertræ:
Kartesiske produkter og indeksopslag med flere kolonner
De indekskrydsningsplaner, der betragtes som en del af stjernesammenføringsoptimeringerne, er nyttige til selektive faktatabelforespørgsler, hvor enkeltkolonne ikke-klyngede indekser findes på faktatabelfremmednøgler (en almindelig designpraksis).
Det giver nogle gange også mening at oprette indekser med flere kolonner på fremmednøgler i faktatabeller til hyppigt forespurgte kombinationer. De indbyggede selektive stjerneforespørgselsoptimeringer indeholder også en omskrivning for dette scenarie. For at se, hvordan dette fungerer, skal du tilføje følgende indeks med flere kolonner til faktatabellen:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Kompiler testforespørgslen igen:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Forespørgselsplanen har ikke længere indekskryds (klik for at forstørre):
Den strategi, der er valgt her, er at anvende hvert prædikat på dimensionstabellerne, tage det kartesiske produkt af resultaterne og bruge det til at søge ind i begge nøgler i multi-kolonneindekset. Forespørgselsplanen udfører derefter et nøgleopslag i faktatabellen ved hjælp af rækkeidentifikatorer nøjagtigt som set tidligere.
Forespørgselsplanen er særlig interessant, fordi den kombinerer tre funktioner, der ofte betragtes som dårlige ting (fulde scanninger, kartesiske produkter og nøgleopslag) i en optimering af ydeevnen. . Dette er en gyldig strategi, når produktet af de to dimensioner forventes at være meget lille.
Der er ingen StarJoinInfo for det kartesiske produkt, men de andre joinforbindelser har oplysninger (klik for at forstørre):
Indeksfilter
Med henvisning tilbage til showplan-skemaet er der en anden StarJoinInfo operation, vi skal dække:
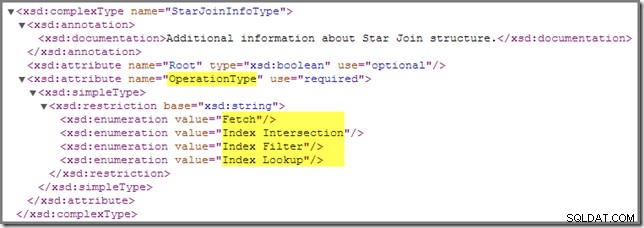
Index Filter værdi ses med joinforbindelser, der anses for at være selektive nok til at være værd at udføre, før faktatabellen hentes. Joins, der ikke er selektive nok, udføres efter hentning og vil ikke have en StarJoinInfo struktur.
For at se et indeksfilter ved hjælp af vores testforespørgsel skal vi tilføje en tredje jointabel til blandingen, fjerne de hidtil oprettede ikke-klyngede faktatabelindekser og tilføje en ny:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Forespørgselsplanen er nu (klik for at forstørre):
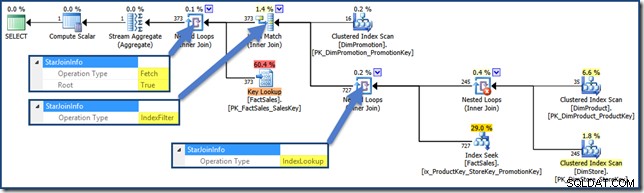
A Heap Index Intersection Query Plan
For fuldstændighedens skyld er her et script til at oprette en heap-kopi af faktatabellen med de to ikke-klyngede indekser, der er nødvendige for at aktivere omskrivning af indeksskæringsoptimeringsværktøjet:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Udførelsesplanen for denne forespørgsel har de samme funktioner som før, men indekskrydsningen udføres ved hjælp af RID'er i stedet for faktatabelklyngede indeksnøgler, og den endelige hentning er et RID-opslag (klik for at udvide):
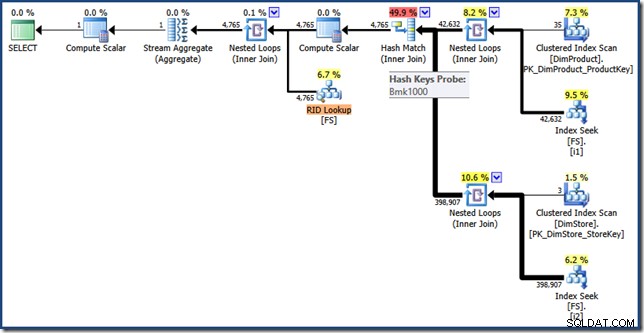
Sidste tanker
De her viste optimeringsomskrivninger er målrettet mod forespørgsler, der returnerer et relativt lille antal rækker fra en stor faktatabel. Disse omskrivninger har været tilgængelige i alle udgaver af SQL Server siden 2005.
Selvom det er beregnet til at fremskynde selektive stjerne- (og snefnug)-skemaforespørgsler i data warehousing, kan optimeringsværktøjet anvende disse teknikker, uanset hvor det registrerer et passende sæt tabeller og joinforbindelser. Heuristikken, der bruges til at detektere stjerneforespørgsler, er ret bred, så du kan støde på planformer med StarJoinInfo strukturer i stort set enhver type database. Enhver tabel af en rimelig størrelse (f.eks. 100 sider eller mere) med referencer til mindre (dimensionslignende) tabeller er en potentiel kandidat til disse optimeringer (bemærk, at eksplicitte fremmednøgler ikke er påkrævet).
For de af jer, der nyder sådanne ting, kaldes optimeringsreglen, der er ansvarlig for at generere selektive stjernesammenføjningsmønstre fra en logisk n-tabel joinforbindelse, StarJoinToIdxStrategy (stjerne join til indeks strategi).