For et par uger siden var SQLskills-teamet i Tampa til vores Performance Tuning Immersion Event (IE2), og jeg dækkede baselines. Grundlinjer er et emne, der ligger mig nært og kært, fordi de er så værdifulde af mange grunde. To af disse grunde, som jeg altid nævner, uanset om jeg underviser eller arbejder med klienter, er at bruge basislinjer til at fejlfinde ydeevne, og så også tendenser til brug og give kapacitetsplanlægningsestimater. Men de er også vigtige, når du foretager justering eller test af ydeevnen – uanset om du tænker på dine eksisterende præstationsmålinger som basislinjer eller ej.
I løbet af modulet gennemgik jeg forskellige kilder til data såsom Performance Monitor, DMV'erne og sporings- eller XE-data, og der dukkede et spørgsmål op relateret til databelastninger. Specifikt var spørgsmålet, om det er bedre at indlæse data i en tabel uden indekser og så oprette dem, når de er færdige, i forhold til at have indekserne på plads under dataindlæsningen. Mit svar var:"Typisk, ja". Min personlige erfaring har været, at dette altid er tilfældet, men man ved aldrig, hvilken advarsel eller enkeltstående scenarie nogen kan løbe ind i, hvor præstationsændringen ikke er, hvad der var forventet, og som med alle præstationsspørgsmål, du ved ikke med sikkerhed, før du tester den. Indtil du etablerer en baseline for én metode og derefter ser, om den anden metode forbedrer den baseline, gætter du kun. Jeg tænkte, det ville være sjovt at teste dette scenarie, ikke bare for at bevise, hvad jeg forventer er sandt, men også for at vise, hvilke metrics jeg ville undersøge, hvorfor og hvordan man fanger dem. Hvis du har lavet præstationstest tidligere, er dette sandsynligvis gammeldags. Men for dem af jer, der er nye i praksis, vil jeg træde gennem den proces, jeg følger for at hjælpe jer i gang. Indse, at der er mange måder at udlede svaret på, "Hvilken metode er bedre?" Jeg forventer, at du vil tage denne proces, justere den og gøre den til din over tid.
Hvad prøver du at bevise?
Det første skridt er at beslutte præcis, hvad du tester. I vores tilfælde er det ligetil:er det hurtigere at indlæse data i en tom tabel og derefter tilføje indekserne, eller er det hurtigere at have indekserne på tabellen under dataindlæsningen? Men vi kan tilføje nogle variationer her, hvis vi vil. Overvej den tid, det tager at indlæse data i en hob, og opret derefter de klyngede og ikke-klyngede indekser i forhold til den tid, det tager at indlæse data i et klynget indeks, og opret derefter de ikke-klyngede indekser. Er der forskel på ydeevnen? Ville klyngingsnøglen være en faktor? Jeg forventer, at databelastningen vil få eksisterende ikke-klyngede indekser til at fragmentere, så måske vil jeg se, hvilken indflydelse genopbygningen af indekserne efter belastningen har på den samlede varighed. Det er vigtigt at rækkevidde dette trin så meget som muligt og være meget specifik omkring, hvad du vil måle, da dette vil afgøre, hvilke data du fanger. For vores eksempel vil vores fire tests være:
Test 1: Indlæs data i en heap, opret det klyngede indeks, opret de ikke-klyngede indekser
Test 2: Indlæs data i et klynget indeks, opret de ikke-klyngede indekser
Test 3: Opret det klyngede indeks og ikke-klyngede indekser, indlæs dataene
Test 4: Opret det klyngede indeks og ikke-klyngede indekser, indlæs dataene, genopbyg de ikke-klyngede indekser
Hvad har du brug for at vide?
I vores scenarie er vores primære spørgsmål "hvilken metode er hurtigst"? Derfor ønsker vi at måle varighed, og for at gøre det skal vi fange et starttidspunkt og et sluttidspunkt. Vi kunne lade det ligge, men vi ønsker måske at forstå, hvordan ressourceudnyttelsen ser ud for hver metode, eller måske vil vi vide de højeste ventetider eller antallet af transaktioner eller antallet af deadlocks. De data, der er mest interessante og relevante, vil afhænge af, hvilke processer du sammenligner. At fange antallet af transaktioner er ikke så interessant for vores databelastning; men for en kodeændring kan det være. Fordi vi opretter indekser og genopbygger dem, er jeg interesseret i, hvor meget IO hver metode genererer. Selvom den overordnede varighed sandsynligvis er den afgørende faktor i sidste ende, kan det være nyttigt at se på IO for ikke kun at forstå, hvilken mulighed der genererer mest IO, men også om databaselagringen fungerer som forventet.
Hvor er de data, du har brug for?
Når du har fundet ud af, hvilke data du har brug for, skal du beslutte, hvorfra de vil blive fanget. Vi er interesserede i varighed, så vi ønsker at registrere det tidspunkt, hver databelastningstest starter, og hvornår den slutter. Vi er også interesserede i IO, og vi kan trække disse data fra flere steder – Performance Monitor-tællere og sys.dm_io_virtual_file_stats DMV kommer til at tænke på.
Forstå, at vi kunne få disse data manuelt. Før vi kører en test, kan vi vælge mod sys.dm_io_virtual_file_stats og gemme de aktuelle værdier i en fil. Vi kan notere tidspunktet og derefter starte testen. Når den er færdig, noterer vi tiden igen, forespørger sys.dm_io_virtual_file_stats igen og beregner forskelle mellem værdier for at måle IO.
Der er adskillige fejl i denne metodologi, nemlig at den giver betydelig plads til fejl; hvad hvis du glemmer at notere starttidspunktet, eller glemmer at fange filstatistik, før du starter? En meget bedre løsning er at automatisere ikke kun udførelsen af scriptet, men også datafangsten. For eksempel kan vi oprette en tabel, der indeholder vores testinformation – en beskrivelse af, hvad testen er, hvornår den startede, og hvornår den afsluttedes. Vi kan inkludere filstatistikken i den samme tabel. Hvis vi indsamler andre metrics, kan vi tilføje dem til tabellen. Eller det kan være nemmere at oprette en separat tabel for hvert sæt data, vi fanger. For eksempel, hvis vi gemmer filstatistikdata i en anden tabel, skal vi give hver test et unikt id, så vi kan matche vores test med de rigtige filstatistikdata. Når vi fanger filstatistik, skal vi fange værdierne for vores database, før vi starter, og derefter efter, og beregne forskellen. Vi kan derefter gemme disse oplysninger i sin egen tabel sammen med det unikke test-id.
En prøveøvelse
Til denne test oprettede jeg en tom kopi af Sales.SalesOrderHeader-tabellen ved navn Sales.Big_SalesOrderHeader, og jeg brugte en variation af et script, jeg brugte i mit partitioneringsindlæg til at indlæse data i tabellen i batches på cirka 25.000 rækker. Du kan downloade scriptet til dataindlæsningen her. Jeg kørte det fire gange for hver variation, og jeg varierede også det samlede antal indsatte rækker. Til det første sæt af tests indsatte jeg 20 millioner rækker, og til det andet sæt indsatte jeg 60 millioner rækker. Varighedsdataene er ikke overraskende:
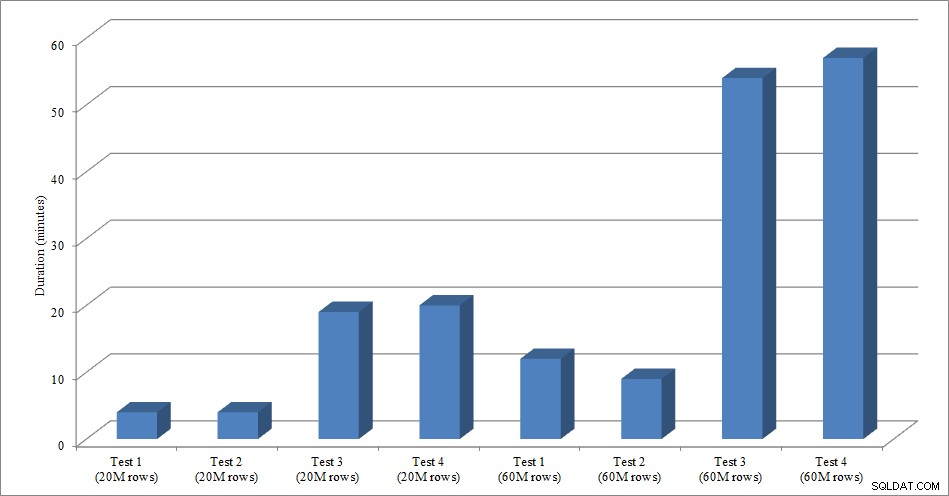
Dataindlæsningsvarighed
Indlæsning af data uden de ikke-klyngede indekser er meget hurtigere end at indlæse dem med de ikke-klyngede indekser, der allerede er på plads. Det, jeg fandt interessant, er, at for belastningen på 20 millioner rækker, var den samlede varighed omtrent den samme mellem test 1 og test 2, men test 2 var hurtigere, når man læste 60 millioner rækker. I vores test var vores klyngenøgle SalesOrderID, som er en identitet og derfor en god klyngenøgle til vores belastning, da den er stigende. Hvis vi havde en klyngenøgle, der i stedet var en GUID, kan indlæsningstiden være højere på grund af tilfældige indsættelser og sideopdelinger (en anden variant, som vi kunne teste).
Efterligner IO-dataene tendensen i varighedsdata? Ja, med forskellene, hvis indekserne allerede er på plads, eller ej, endnu mere overdrevne:
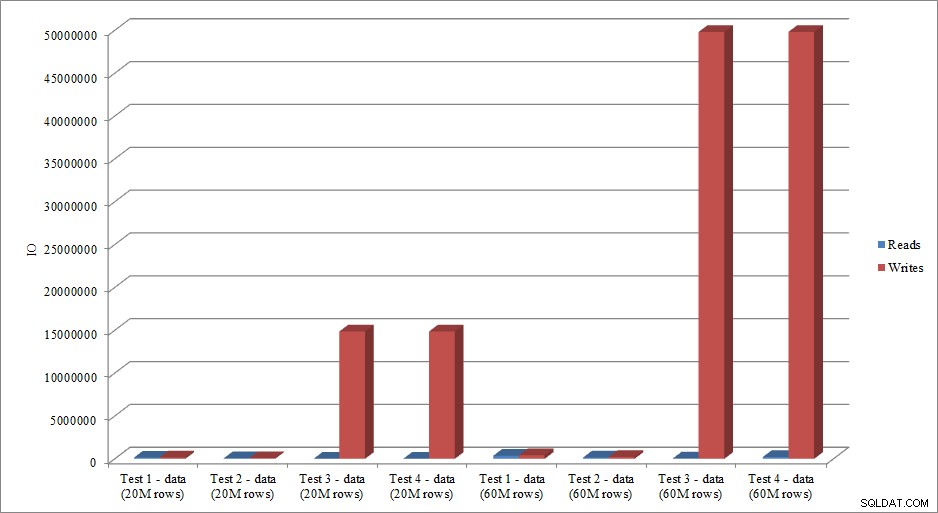
Dataindlæsning læser og skriver
Metoden, som jeg har præsenteret her til præstationstest, eller måling af ændringer i ydeevne baseret på ændringer af kode, design osv., er blot en mulighed for at fange basislinjeinformation. I nogle scenarier kan dette være overdrevent. Hvis du har en forespørgsel, du forsøger at justere, kan det tage længere tid at konfigurere denne proces til at fange data, end det ville tage at foretage justeringer af forespørgslen! Hvis du har foretaget en mængde forespørgselsjusteringer, har du sandsynligvis for vane at fange STATISTICS IO og STATISTICS TIME data sammen med forespørgselsplanen og derefter sammenligne outputtet, mens du foretager ændringer. Jeg har gjort dette i årevis, men jeg har for nylig opdaget en bedre måde ... SQL Sentry Plan Explorer PRO. Faktisk, efter at jeg havde fuldført alle de belastningstest, jeg beskrev ovenfor, gik jeg igennem og kørte mine tests igen gennem PE og fandt ud af, at jeg kunne fange de oplysninger, jeg ønskede, uden at skulle opsætte mine dataindsamlingstabeller.
Indenfor Plan Explorer PRO har du mulighed for at få den faktiske plan – PE vil køre forespørgslen mod den valgte instans og database og returnere planen. Og med den får du alle de andre gode data, som PE leverer (tidsstatistik, læsning og skrivning, IO for tabel), samt ventestatistikken, hvilket er en fin fordel. Ved at bruge vores eksempel startede jeg med den første test - oprettelse af heapen, indlæsning af data og derefter tilføjelse af det klyngede indeks og ikke-klyngede indekser - og kørte derefter indstillingen Få faktisk plan. Da den var fuldført, ændrede jeg min scripttest 2, kørte indstillingen Få faktisk plan igen. Jeg gentog dette til tredje og fjerde test, og da jeg var færdig, havde jeg dette:
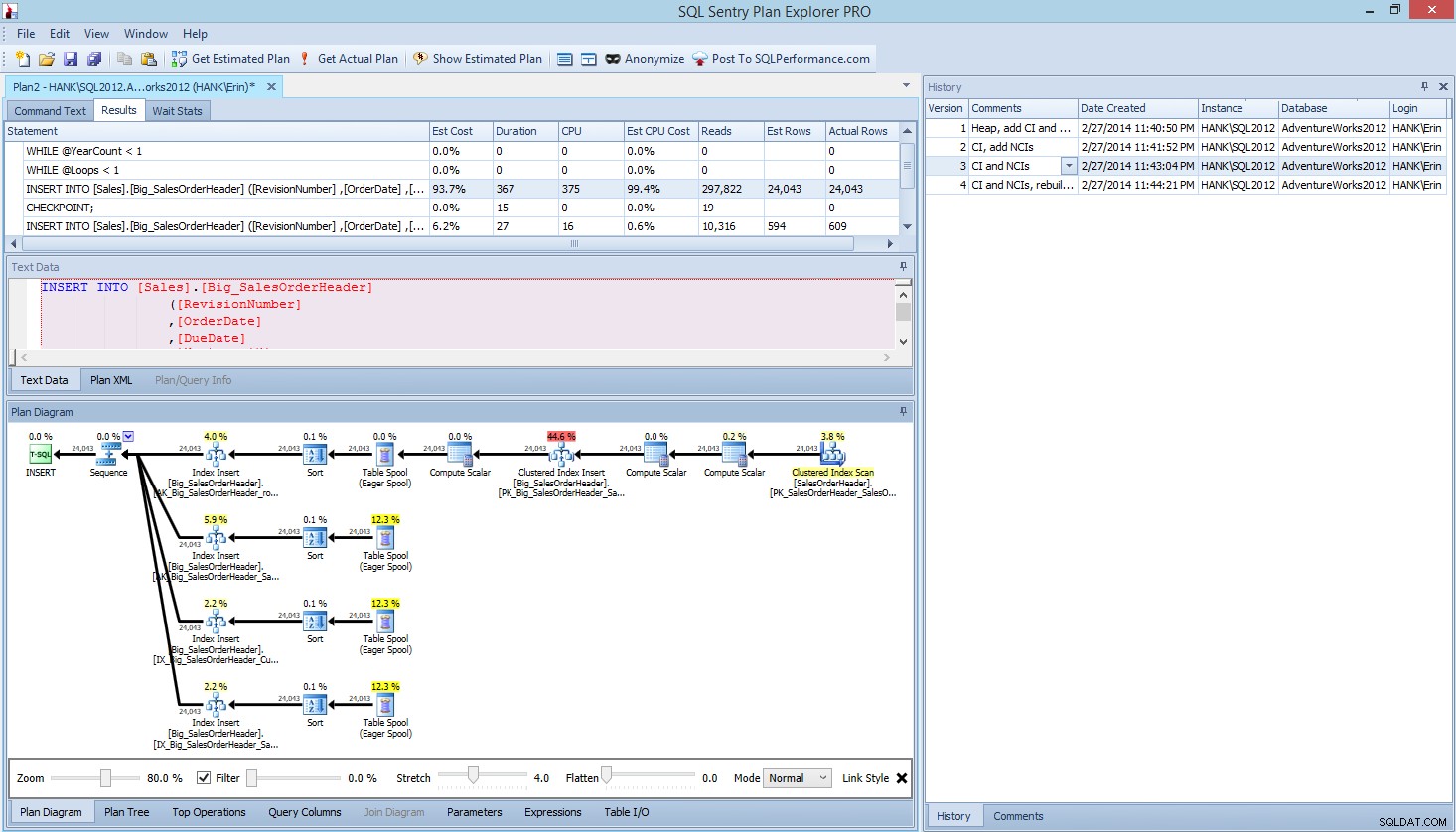
Plan Explorer PRO-visning efter at have kørt 4 test
Bemærk historikruden i højre side? Hver gang jeg ændrede min kode og genfangede den faktiske plan, gemte den et nyt sæt oplysninger. Jeg har mulighed for at gemme disse data som en .pesession-fil for at dele med et andet medlem af mit team, eller gå tilbage senere og rulle gennem de forskellige tests og bore i forskellige udsagn inden for batchen efter behov, og se på forskellige metrics, f.eks. som varighed, CPU og IO. I skærmbilledet ovenfor har jeg fremhævet INSERT fra Test 3, og forespørgselsplanen viser opdateringerne til alle fire ikke-klyngede indekser.
Oversigt
Som med så mange opgaver i SQL Server, er der mange måder at fange og gennemgå data på, når du kører ydeevnetest eller udfører tuning. Jo mindre manuel indsats du skal yde, jo bedre, da det giver mere tid til faktisk at foretage ændringer, forstå virkningen og derefter gå videre til din næste opgave. Uanset om du tilpasser et script til at fange data eller lader et tredjepartsværktøj gøre det for dig, er de trin, jeg har skitseret, stadig gyldige:
- Definer, hvad du vil forbedre
- Omfang din test
- Afgør, hvilke data der kan bruges til at måle forbedringer
- Beslut hvordan dataene skal indfanges
- Opsæt en automatiseret metode, når det er muligt, til test og registrering
- Test, evaluer og gentag efter behov
God test!