Partitionering er en SQL Server-funktion, der ofte implementeres for at afhjælpe udfordringer relateret til administration, vedligeholdelsesopgaver eller låsning og blokering. Administration af store tabeller kan blive lettere med partitionering, og det kan forbedre skalerbarhed og tilgængelighed. Derudover kan et biprodukt af partitionering være forbedret forespørgselsydeevne. Det er ikke en garanti eller givet, og det er ikke den drivende årsag til at implementere partitionering, men det er noget, der er værd at gennemgå, når du opdeler et stort bord.
Baggrund
Som en hurtig gennemgang er SQL Server-partitioneringsfunktionen kun tilgængelig i Enterprise og Developer Editions. Partitionering kan implementeres under indledende databasedesign, eller den kan sættes på plads, efter at en tabel allerede har data i sig. Forstå, at det ikke altid er hurtigt og enkelt at ændre en eksisterende tabel med data til en opdelt tabel, men det er ganske muligt med god planlægning, og fordelene kan hurtigt realiseres.
En partitioneret tabel er en, hvor dataene er adskilt i mindre fysiske strukturer baseret på værdien for en specifik kolonne (kaldet partitioneringskolonnen, som er defineret i partitionsfunktionen). Hvis du vil adskille data efter år, kan du bruge en kolonne kaldet DateSold som partitioneringskolonnen, og alle data for 2013 vil ligge i én struktur, alle data for 2012 vil ligge i en anden struktur osv. Disse separate datasæt tillade fokuseret vedligeholdelse (du kan kun genopbygge en partition af et indeks i stedet for hele indekset) og tillade, at data hurtigt tilføjes og fjernes, fordi de kan iscenesættes, før de faktisk tilføjes til eller fjernes fra tabellen.
Opsætningen
For at undersøge forskellene i forespørgselsydeevne for en opdelt kontra en ikke-opdelt tabel, oprettede jeg to kopier af tabellen Sales.SalesOrderHeader fra AdventureWorks2012-databasen. Den ikke-opdelte tabel blev oprettet med kun et klynget indeks på SalesOrderID, den traditionelle primære nøgle til tabellen. Den anden tabel var opdelt på OrderDate med OrderDate og SalesOrderID som klyngenøgle og havde ingen yderligere indekser. Bemærk, at der er adskillige faktorer, du skal overveje, når du skal beslutte, hvilken kolonne der skal bruges til partitionering. Partitionering bruger ofte, men bestemt ikke altid, et datofelt til at definere partitionsgrænserne. Som sådan blev OrderDate valgt til dette eksempel, og eksempelforespørgsler blev brugt til at simulere typisk aktivitet mod SalesOrderHeader-tabellen. Udsagn til at oprette og udfylde begge tabeller kan downloades her.
Efter at have oprettet tabellerne og tilføjet data, blev de eksisterende indekser verificeret, og statistikkerne blev derefter opdateret med FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Derudover har begge tabeller nøjagtig samme fordeling af data og minimal fragmentering.
Ydeevne for en simpel forespørgsel
Før der blev tilføjet yderligere indekser, blev der udført en grundlæggende forespørgsel mod begge tabeller for at beregne totaler optjent af sælger for ordrer afgivet i december 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTIK IO OUTPUT
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Big_SalesOrderHeader'. Scanningsantal 9, logisk læser 2710440, fysisk læser 2226, read-ahead læser 2658769, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Part_SalesOrderHeader'. Scanningsantal 9, logisk læser 248128, fysisk læser 3, read-ahead læser 245030, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.

Totaler efter sælger for december – ikke-opdelt tabel em>
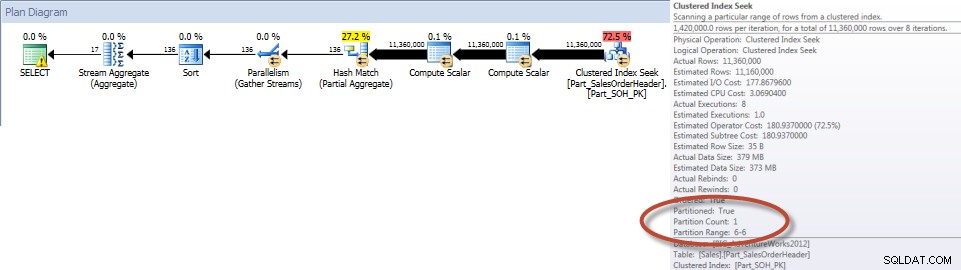
Totaler efter sælger for december – opdelt tabel
Som forventet skulle forespørgslen mod den ikke-opdelte tabel udføre en fuld scanning af tabellen, da der ikke var noget indeks til at understøtte det. I modsætning hertil behøvede forespørgslen mod den partitionerede tabel kun for at få adgang til én partition af tabellen.
For at være retfærdig, hvis dette var en forespørgsel, der gentagne gange blev udført med forskellige datointervaller, ville det passende ikke-klyngede indeks eksistere. For eksempel:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Med dette indeks oprettet, når forespørgslen udføres igen, falder I/O-statistikken, og planen ændres til at bruge det ikke-klyngede indeks:
STATISTIK IO OUTPUT
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Big_SalesOrderHeader'. Scanningsantal 9, logisk læser 42901, fysisk læser 3, read-ahead læser 42346, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.

Totaler efter salgsperson for december – NCI på ikke-opdelt tabel
Med et understøttende indeks kræver forespørgslen mod Sales.Big_SalesOrderHeader betydeligt færre læsninger end den clusterede indeksscanning mod Sales.Part_SalesOrderHeader, hvilket ikke er uventet, da det clusterede indeks er meget bredere. Hvis vi opretter et sammenligneligt ikke-klynget indeks for Sales.Part_SalesOrderHeader, ser vi lignende I/O-numre:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIK IO OUTPUT
Tabel 'Part_SalesOrderHeader'. Scanningsantal 9, logisk læser 42894, fysisk læser 1, read-ahead læser 42378, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
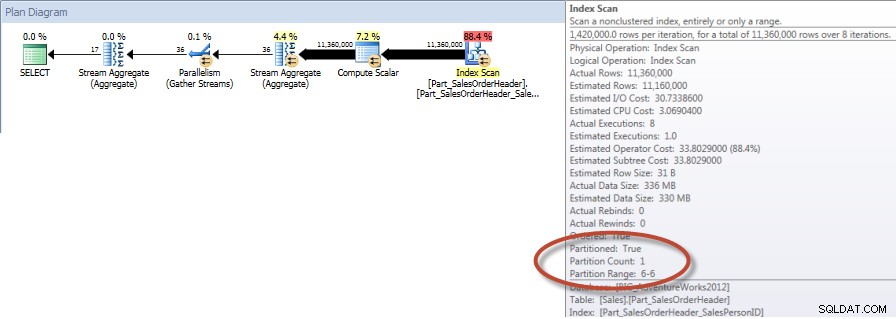
Totaler efter sælger for december – NCI på opdelt tabel med eliminering
Og hvis vi ser på egenskaberne for den ikke-klyngede Index Scan, kan vi bekræfte, at motoren kun har adgang til én partition (6).
Som anført oprindeligt implementeres partitionering typisk ikke for at forbedre ydeevnen. I eksemplet vist ovenfor fungerer forespørgslen mod den partitionerede tabel ikke væsentligt bedre, så længe det relevante ikke-klyngede indeks eksisterer.
Ydeevne for en ad hoc-forespørgsel
En forespørgsel mod den partitionerede tabel kan udkonkurrere den samme forespørgsel mod den ikke-opdelte tabel i nogle tilfælde, for eksempel når forespørgslen skal bruge det klyngede indeks. Selvom det er ideelt at have de fleste forespørgsler understøttet af ikke-klyngede indekser, tillader nogle systemer ad hoc-forespørgsler fra brugere, og andre har forespørgsler, der kan køre så sjældent, at de ikke berettiger understøttende indekser. Mod SalesOrderHeader-tabellen kan en bruger køre følgende forespørgsel for at finde ordrer fra december 2012, som skulle sendes ved udgangen af året, men som ikke blev sendt, for et bestemt sæt kunder og med en TotalDue større end $1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTIK IO OUTPUT
Tabel 'Big_SalesOrderHeader'. Scanningsantal 9, logisk læser 2711220, fysisk læser 8386, read-ahead læser 2662400, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Part_SalesOrderHeader'. Scanningsantal 9, logisk læser 248128, fysisk læser 0, read-ahead læser 243792, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
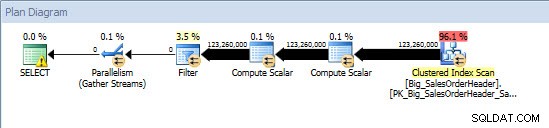
Ad-Hoc-forespørgsel – ikke-partitioneret tabel
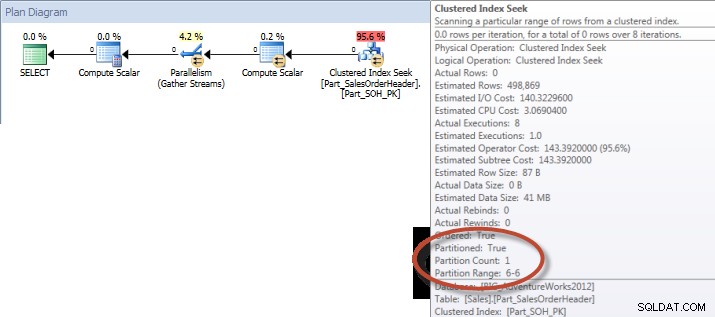
Ad-Hoc-forespørgsel – opdelt tabel
Mod den ikke-opdelte tabel krævede forespørgslen en fuld scanning mod det klyngede indeks, men mod den opdelte tabel udførte forespørgslen en indekssøgning af det klyngede indeks, da motoren brugte partitionseliminering og kun læste de data, den absolut havde brug for. I dette eksempel er det en væsentlig forskel med hensyn til I/O, og afhængigt af hardwaren kan det være en dramatisk forskel i udførelsestid. Forespørgslen kunne optimeres ved at tilføje det relevante indeks, men det er typisk ikke muligt at indeksere for hver enkelt forespørgsel. Især for løsninger, der tillader ad-hoc-forespørgsler, er det rimeligt at sige, at du aldrig ved, hvad brugerne vil gøre. En forespørgsel kan køre én gang og aldrig køre igen, og det er nyttesløst at oprette et indeks efter kendsgerningen. Derfor, når du skifter fra en ikke-opdelt tabel til en opdelt tabel, er det vigtigt at anvende den samme indsats og tilgang som almindelig indeksjustering; du vil verificere, at de relevante indekser findes til at understøtte de fleste forespørgsler.
Ydeevne og indeksjustering
En yderligere faktor at overveje, når du opretter indekser til en opdelt tabel, er, om indekset skal justeres eller ej. Indekser skal justeres efter tabellen, hvis du planlægger at skifte data ind og ud af partitioner. Oprettelse af et ikke-klynget indeks på en inddelt tabel opretter som standard et justeret indeks, hvor inddelingskolonnen tilføjes som en inkluderet kolonne til indekset.
Et ikke-justeret indeks oprettes ved at angive et andet partitionsskema eller en anden filgruppe. Partitioneringskolonnen kan være en del af indekset som en nøglekolonne eller en inkluderet kolonne, men hvis tabellens partitionsskema ikke bruges, eller der bruges en anden filgruppe, vil indekset ikke blive justeret.
Et justeret indeks er opdelt ligesom tabellen – dataene vil eksistere i separate strukturer – og derfor kan partitioneliminering forekomme. Et ujusteret indeks eksisterer som én fysisk struktur og giver muligvis ikke den forventede fordel for en forespørgsel, afhængigt af prædikatet. Overvej en forespørgsel, der tæller salg efter kontonummer, grupperet efter måned:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Hvis du ikke er så fortrolig med partitionering, kan du oprette et indeks som dette for at understøtte forespørgslen (bemærk, at den PRIMÆRE filgruppe er angivet):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Dette indeks er ikke justeret, selvom det inkluderer OrderDate, fordi det er en del af den primære nøgle. Kolonnerne er også inkluderet, hvis vi opretter et justeret indeks, men bemærk forskellen i syntaks:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Vi kan verificere, hvilke kolonner der findes i indekset ved hjælp af Kimberly Tripps sp_helpindex:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
Når vi kører vores forespørgsel og tvinger den til at bruge det ikke-justerede indeks, scannes hele indekset. Selvom OrderDate er en del af indekset, er det ikke den førende kolonne, så motoren skal kontrollere OrderDate-værdien for hvert kontonummer for at se, om den falder mellem 1. januar 2013 og 31. juli 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Part_SalesOrderHeader'. Scanningsantal 9, logisk læser 786861, fysisk læser 1, read-ahead læser 770929, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
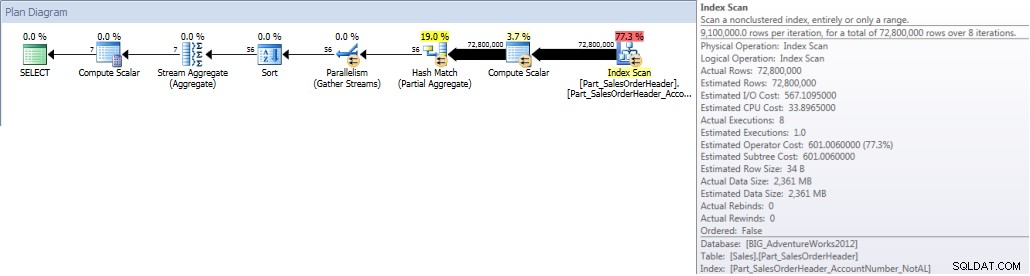
Kontototaler pr. måned (januar – juli 2013) ved brug af ikke- Justeret NCI (tvungen)
I modsætning hertil, når forespørgslen er tvunget til at bruge det justerede indeks, kan partitionseliminering bruges, og der kræves færre I/O'er, selvom OrderDate ikke er en ledende kolonne i indekset.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Tabel 'Arbejdsbord'. Scanningsantal 0, logisk læser 0, fysisk læser 0, read-ahead læser 0, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
Tabel 'Part_SalesOrderHeader'. Scanningsantal 9, logisk læser 456258, fysisk læser 16, read-ahead læser 453241, lob logisk læser 0, lob fysisk læser 0, lob read-ahead læser 0.
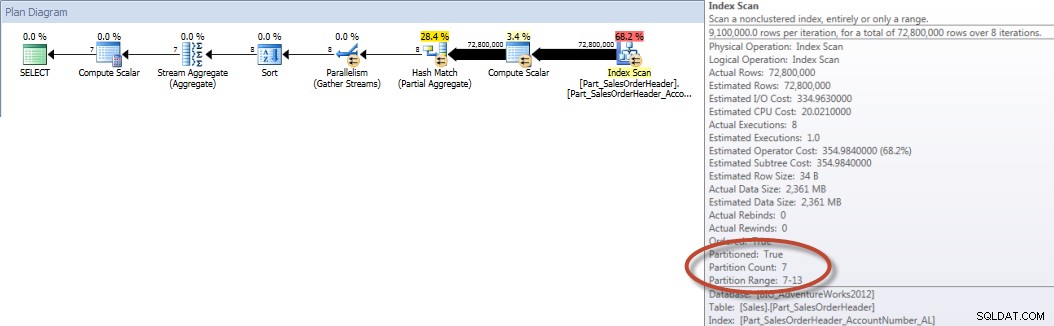
Kontototaler pr. måned (januar – juli 2013) ved hjælp af tilpasset NCI (tvunget)
Oversigt
Beslutningen om at implementere opdeling er en, der kræver behørig overvejelse og planlægning. Nem administration, forbedret skalerbarhed og tilgængelighed og en reduktion i blokering er almindelige årsager til at partitionere tabeller. Forbedring af forespørgselsydeevne er ikke en grund til at anvende partitionering, selvom det i nogle tilfælde kan være en gavnlig bivirkning. Med hensyn til ydeevne er det vigtigt at sikre, at din implementeringsplan indeholder en gennemgang af forespørgselsydeevne. Bekræft, at dine indekser fortsat understøtter dine forespørgsler korrekt efter tabellen er partitioneret, og kontroller, at forespørgsler, der bruger de klyngede og ikke-klyngede indekser, drager fordel af partitionseliminering, hvor det er relevant.