Der er meget at huske på, når du designer en database, og meget få af os kan huske alle de værdifulde tip og tricks, vi har lært. Så lad os tage et kig på nogle online ressourcer, der indeholder tips til databasedesign og bedste praksis. Mens vi går, vil jeg dele mine egne meninger om de præsenterede ideer baseret på min erfaring med databasedesign.
Denne artikel er naturligvis ikke en udtømmende liste, men jeg har forsøgt at gennemgå og kommentere et tværsnit af kilder. Forhåbentlig finder du den information, der passer bedst til dine behov og mål.
Som en sidebemærkning var jeg overrasket over at opdage, at mange artikler relateret til databasedesignpraksis havde meget få eksempler; de onlineressourcer, som jeg gennemgik til artiklen om fejl og fejl, havde en højere procentdel af dem. Denne mangel er en ulempe, fordi eksempler er ekstremt vigtige for at få pointen igennem.
Databasetip til erfarne designere
Lad os først starte med kilder, der byder på avancerede databasedesigntips og bedste praksis. Disse er for designere, der allerede arbejder med datamodellering og har været det i nogen tid. Nogle artikler er rettet mod et mere mellemniveau, men hvis de diskuterer avancerede koncepter, har jeg inkluderet dem på denne liste.
Database retningslinjer (RDBMS/SQL)
af Steve Djajasaputra | SOA, Java, Softwareudvikling – BlogSpot | 16. januar 2013
Denne artikel fra Mr. Djajasaputra er ret imponerende:han lister adskillige tips til skemaet, indekser og synspunkter; han giver også en ret detaljeret navnekonvention. Og hans tips fortsætter (og fortsætter). Bredden er imponerende, men der er næsten ingen eksempler. Nogle af hans pointer kan betragtes som diskutable, men overordnet set er dette en meget solid præsentation.
Især var jeg imponeret over, at han giver en præcis regel om at bruge naturlige versus kunstige (dvs. surrogat eller genererede) primærnøgler. Han holder dette pænt og enkelt og angiver, at vi skal foretrække en naturlig nøgle, fordi den er meningsfuld. Han giver også retningslinjer for den bedste brug af en kunstig nøgle – specifikt når den naturlige nøgle ikke er unik, eller når du skal ændre værdien af den naturlige nøgle. Med hans egne ord:
Foretrækker først at bruge den naturlige nøgle, da den er mere meningsfuld og for at undgå duplikationer (genbrug eksisterende kolonne). Men der er tilfælde, hvor du har brug for en kunstig nøgle:når den naturlige nøgle ikke er unik (f.eks. navne), eller hvis du skal ændre værdien.Da hans liste med tips er så lang, kan jeg ikke forestille mig at huske dem alle. Men der kan refereres til hver sektion, når du arbejder med databasedesign, ydeevne, lagrede procedurer og versionering. Der er også et afsnit om Oracle-specifikke punkter, som ville være nyttigt, hvis du arbejder med eller planlægger at støtte Oracle.
Alt i alt er dette en meget værdifuld og omfattende ressource.
9 tips til bedre databasedesign
af Jeffrey Edison | Vertabelo Blog | 22. september 2015
Jeg vil hengive mig til lidt selvpromovering her.
Denne artikel med 9 tips til bedre databasedesign er baseret på min erfaring som designer og arkitekt. Jeg fandt også yderligere indsigt ved at undersøge andres bedste praksis for databasedesign.
Min liste repræsenterer nogle af de vigtigste problemer, der kan ske, når man arbejder med datamodeller. Jeg organiserede tipsene i den rækkefølge, de forekommer i løbet af projektets livscyklus (i stedet for efter vigtighed eller hvor ofte de opstår), da det ville være mest nyttigt, i det mindste efter min mening. Læsere kan følge denne tjekliste over bedste praksis gennem et projekts livscyklus.
Fra artiklen:
For at parafrasere Al Capone (eller John Van Buren, søn af den 8. amerikanske præsident), "test tidligt, test ofte". På denne måde følger du den kontinuerlige integrations vej. Test på et tidligt udviklingsstadium sparer tid og penge. Ved test af databasen bør målet være at simulere et produktionsmiljø:"A Day in the Life of the Database". Hvilke mængder kan forventes? Hvilke brugerinteraktioner er sandsynlige? Behandles grænsesager?Ved at være opmærksom på disse tips har jeg fundet ud af, at databaser bliver bedre designet og mere robuste. Selvom ingen af disse aktiviteter vil tage enormt lang tid, kan hver enkelt have en enorm indflydelse på kvaliteten af din datamodel.
Jeg håber, at min liste med tips er nyttig for mellemliggende og avancerede designere.
20 bedste praksis for databasedesign
af Cagdas Basaraner | Kodebalance – BlogSpot | 24. juli 2011
Mr. Basaraner præsenterer os for en interessant liste over 20 bedste praksisser for databasedesign. Jeg ville have foretrukket, hvis han havde grupperet nogle af disse; for eksempel kunne de første fire punkter alle være dækket under "Use Good Naming Conventions".
Derudover udtaler han, at det er en god praksis at bruge et syntetisk, genereret (heltals) ID som den primære nøgle for alle tabeller. Faktisk er dette stadig et omdiskuteret emne, med argumenter for og imod. Nogle af hans bedste praksisser er ret generiske, som "For … mission critic [sic] databasesystemer, brug disaster recovery and security service ..." Jeg er ikke uenig i dette punkt, men det er meget højt niveau.
På plussiden var denne artikel en af de få, der nævner brugen af en ORM-ramme (objektrelationel mapping). Nogle kommentatorer var uenige i, hvordan tippet blev formuleret, men i det mindste nævnes det at bruge en ORM-ramme:
Brug en ORM-ramme (object relational mapping) (dvs. Hibernate, iBatis ...), hvis applikationskoden er stor nok. Ydeevneproblemer for ORM-rammer kan håndteres af detaljerede konfigurationsparametre.Alligevel kunne denne liste være blevet forbedret. Det bør klart identificere punkter, der kun er specifikke for nogle databasestyringssystemer (f.eks. SQL Server). Præcis statistik vedrørende ydeevne, heuristik eller vigtigheden af at bruge tid på design snarere end på vedligeholdelse og re-design ville have været godt. Der var også brug for flere eksempler, men det er et problem for de fleste af disse artikler.
Hvis du arbejder med SQL Server, overvejer at bruge en ORM-ramme eller har brug for en punktliste med tips i stedet for en lang og detaljeret artikel, så er dette stykke noget for dig.
(Bemærk:denne artikel dukkede også op på flere andre websteder, herunder CodeBuild, Java Code Geeks og DZone.)
Vigtige databasedesign. 10 ting, du absolut skal gøre
af Michelle A. Poolet | SQL Server Pro | 1. marts 2011
En del af fru Poolets tips er ganske standard og kan findes i mange andre ressourcer, men der er også et par temmelig usædvanlige punkter. Blandt hendes generiske pointer fremmer hun brugen af undertyper og supertyper (hvilket jeg er meget enig i), da dette afspejler objektorienteret design og let kan forstås af udviklere. Fra hendes artikel:
Vær ikke bange for at inkludere supertype- og subtype-enheder i dit design i CDM og frem. Undertyperne repræsenterer klassifikationer eller kategorier af supertypen... Enheder er repræsenteret som undertyper, når det kræver mere end et enkelt ord eller en enkelt sætning at kategorisere enheden.
Hvis en kategori har sit eget liv med separate attributter, der beskriver, hvordan kategorien ser ud og opfører sig og adskiller relationer med andre entiteter, så er det tid til at påberåbe sig supertype-/undertypestrukturen . Undladelse af at gøre det vil hæmme en fuldstændig forståelse af de data og de forretningsregler, der driver dataindsamlingen.
Nogle af hendes kommentarer henviser specifikt til MS SQL Server, selvom kommentarerne faktisk er generiske problemer. En hovedpointe, som fru Poolet gør, er meget SQL Server-specifik:"Butikskode, der berører en databases data som en lagret procedure".
Dette er fint, hvis du kun planlægger at understøtte et enkelt databasestyringssystem, såsom SQL Server. Men for bærbare implementeringer ville dette ikke være et godt råd. Generelt designer jeg med henblik på portabilitet til mindst to ledelsessystemer med understøttelse af forskellige lagrede proceduresprog. Derfor ville jeg undgå denne praksis.
Denne artikel er mest nyttig for folk, der udvikler til SQL Server og fokuserer på det amerikanske marked (i stedet for et internationalt system). Som amerikaner, der bor i udlandet, fandt jeg dog ud af, at nogle af hendes eksempler er lidt for "USA-centrerede". For eksempel kan en ikke-amerikaner måske ikke forstå, hvad en Zip+4 domæne er og ville derfor ikke have nogen forståelse af, hvorfor et dette domæne skulle have en IKKE NULL-karakteristik.
For at illustrere dette lavede jeg en datamodel for begge amerikanske ikke-amerikanske adresser. Vi antager, at vores datamodel muligvis kræver, at enheder er knyttet til mere end én adresse:for eksempel én til fakturering og én til forsendelse. Den første adresse vil være forbundet med en betalingsmetode; i dette tilfælde vil adressen blive brugt til at bekræfte din ret til at godkende denne betaling. Leveringsadressen er naturligvis, hvor ordren vil blive leveret.
Lad os oprette en amerikansk adresse som en del af en kundeordredatabasemodel. (Bemærk:dette er ikke en komplet model, men et eksempel på lagring af produktordrer.)
Wise Coders Solutions anbefaler at definere separate felter for husnumre og vejnavne og indstille disse felter som IKKE NULL; dette ville udelukke enhver adresse, der ikke har et husnummer og et vejnavn. Men hvad med folk, der bruger postbokse? Deres adresser er normalt skrevet som "Postboks 123". Skal vi tvinge dem til at sætte postboksnummeret som husnummer og "Postboks" som vejnavn? Det tror jeg ikke.
I stedet vil vi bruge en formular med "Adresselinje 1" og "Adresselinje 2". Flere personer har argumenteret imod at bruge tal i feltnavne, men for mig er det en ret oplagt løsning. Jeg har også defineret maksimale feltlængder (35 og 70 tegn), der er typiske ved internationale betalinger.
Bemærk, at de amerikanske og ikke-amerikanske designs begge har et felt for regioner i et land, men det amerikanske design kræver, at en statsforkortelse på 2 tegn er inkluderet. Bemærk også, at det amerikanske design ikke tillader adresser i andre lande.
Hvis du har bekymringer om den globale brug af din database, skal du tænke globalt i designfasen. Er vores databaser forberedt til multinational brug af vores applikationer?
Erfaringer fra dårligt datavarehusdesign
af Michelle A. Poolet | SQL Server Pro | 15. juni 2009
Denne artikel tager et kig på Data Warehouse (DWH) og nogle af dets design- og implementeringsproblemer. Der er et lille fokus på SQL Server, men det er en ret ortodoks oversigt over design til data warehousing og business intelligence. At have buy-in og skabe brugervenlige grænseflader er måske ikke de mest nyttige tips, men jeg er ikke uenig i dem – jeg tror bare ikke, de er en del af DWH-designet.
Ms. Poolet udtaler, at ETL-processen (extract-transform-load) bør udføre datakvalitetstjek og potentielt "rene" data, indtil der er en acceptabel standard for datakvalitet. Efter min mening risikerer dette at skabe et datavarehus, der ikke korrekt spejler informationen, der er udtrukket fra kildesystemet. Datarensning bør udføres i kildesystemerne. ETL bør kun transformere data, så de kan indlæses i datavarehuset.
Positivt er anbefalingen om genbrug eller oprettelse af genanvendelige ETL-rutiner yderst relevant. Derudover er jeg enig med fru Poolet om skalerbarhed. Hendes kommentarer om risikostyring og overholdelse, især Sarbanes-Oxley Act, virker ret specifikke; Jeg går ud fra, at disse kommer fra hendes forretningsområde.
Endelig har hun en fin tjekliste med punkter, der vedrører dimensioner, faktatabeller og skemavalg under OLAP (online analytical processing) design. Disse ser ud til at være meget relevante under databasedesignprocessen. Jeg ville gerne have haft denne liste længere med flere detaljer eller eksempler, men jeg var glad for, at disse praktiske tips var inkluderet.
11 Vigtige regler for databasedesign, som jeg følger
af Shivprasad Koirala | Kodeprojekt | 25. februar 2014
Jeg kan rigtig godt lide de fornuftige og klare råd i starten af denne artikel. Begreber som 'overvej applikationens art' og 'bryd dine data op i logiske stykker' er spot on. Disse er vigtige hjælpemidler, når du opretter din datamodel. Som hr. Koirala siger:
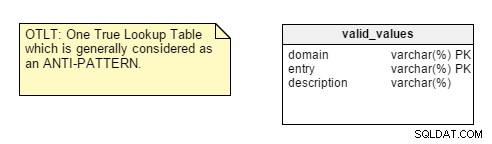
Når du starter dit databasedesign, er den første ting at analysere arten af den applikation, du designer til, er den Transaktionel eller Analytisk. Du vil finde mange udviklere, der som standard anvender normaliseringsregler uden at tænke på applikationens art og så senere komme ind på problemer med ydeevne og tilpasning.Der er dog et par punkter, der efterlader mig ikke overbevist. Tag f.eks. centralisering af navne-værdi-par i en enkelt tabel. Dette One True Lookup Table (OTLT) design er omdiskuteret, men det betragtes generelt som en dårlig praksis eller i det mindste anti-mønster i design. Jeg stiller mig på anti-OTLT-gruppen; disse tabeller introducerer adskillige problemer. Vi kan bruge softwareudviklingsanalogien med at bruge en enkelt tæller til at repræsentere alle mulige værdier af alle mulige konstanter som en ækvivalent til denne praksis.
For at minde dig om, ser OTLT-tabellen typisk sådan ud, med indgange fra flere domæner smidt ind i den samme tabel. Jeg er enig med anti-OTLT-gruppen; disse tabeller introducerer adskillige problemer.
Derudover virker nogle punkter lidt esoteriske, som "hold øje med data adskilt af separatorer". Selvom dette er et gyldigt punkt, er det ikke en, jeg normalt tænker på, når jeg opretter en ny datamodel.
Mr. Koirala har et par OLAP-designelementer, som generelt ikke er nævnt i andre best practice-lister. Hans medtagelse af en dimension og faktadesign kan være nyttig, men det kan også være farligt for nybegyndere designere.
Denne artikel er interessant, hvis du bevæger dig fra begyndelsen til mere avanceret datamodellering. Det vil hjælpe dig med at overveje den analytiske versus transaktionelle karakter af dine fremtidige modeller.
Big Data:Fem enkle råd til ydelse af databasedesign
af Dave Beulke | davebeulke.com | 19. marts 2013

Mr. Beulkes artikel ser på præstationsfokuserede designtips. Han viser, hvordan man kontrollerer for korrekt normalisering:hverken for meget eller for lidt. (Overnormalisering vil have en negativ indvirkning på databasens ydeevne.)
Brug af naturlige forretningsnøgler i stedet for genererede primære nøgler er også et godt råd, når du vil undgå at oversætte fra en forretningsnøgle til et genereret række-id for hver databaseadgang.
At bruge ordentlige navnestandarder og kolonnetyper er også et godt råd. Pointen med overforbrug af nullable kolonner er sund:At oprette alle kolonner som nullable er en fejl, men at definere en kolonne som nullable kan være påkrævet for en bestemt forretningsfunktion. Med forfatterens egne ord:
Er alle kolonnerne NULLable? Inden for databasekolonnernes definitioner bør gode datadomæner, intervaller og værdier analyseres, evalueres og prototypes til forretningsapplikationen. At have gode standardværdier, et begrænset omfang af værdier og altid en værdi er bedst for ydeevne og applikationslogik. NULL-kolonner er kun gode, når data er ukendte eller endnu ikke har en værdi. En persons dødsdatodata er det klassiske eksempel på en NULLbar kolonne, fordi den er ukendt, medmindre de allerede er døde. Sørg for, at dit databasedesign repræsenterer data, der er kendt og kun bruger et minimum af NULL-kolonner.Hr. Beulkes tips er alle meget solide, selvom de er noget uoriginale. Jeg ville gerne have haft flere Big Data-emner - det er trods alt artiklens titel. Til sidst følte jeg, at artiklen manglede både dybde og bredde, og havde ingen eksempler til at tydeliggøre pointerne. Han tilbyder dog værdifulde råd i forbindelse med normalisering og naturlige nøgler.
10 bedste praksis for databasedesign
af Ann All | Enterprise Apps i dag | 15. juli 2014
Ten Database Design Best Practices præsenteres faktisk som en række slides. Ms. Alt inkluderer oplysninger fra erfarne udviklere, såsom Michael Blaha. Han opfordrer til genbrug af dine bedste praksisser og mønstre. Disse er forstået og gennemprøvet, og i den henseende at foretrække frem for datamodeller, der skal skabes fra bunden. Fra Ms. Alls artikel:
For eksempel reverse engineer jeg ofte databaser - databaser for en applikation, der skal erstattes, såvel som databaser over relaterede applikationer. Disse eksisterende databaser har ofte ikke en tilgængelig datamodel. Men en datamodel er implicit i databaseskemaet og kan i det mindste delvist udtrækkes med database reverse engineering-teknikker. … Der er gennemprøvede datarepræsentationer, der ofte forekommer og ikke behøver at blive genskabt fra bunden.Dette er et kort diasshow, som designere af datamodeller hurtigt kan scanne igennem og samle de tips, der giver genlyd hos dem. For mig er genbrugstipset en af mine favoritter.
Bedste praksis for databaser
af Cunningham &Cunningham, Inc.
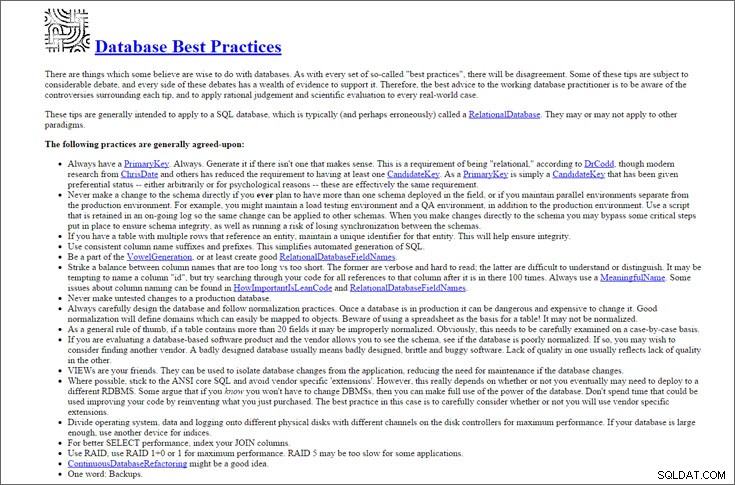
Disse bedste fremgangsmåder startede fint, men kom så ind i nogle klæbrige problemer. Jeg er ikke overbevist om, at de tilbudte råd altid er rigtige.
På den positive side er der meget fine beskrivelser af kontroversielle "best practices" som altid at bruge autogenererede surrogatnøgler og bruge eller undgå lagrede procedurer. Som et eksempel:
En tidligere forfatter skrev:"Generelt undgå primærnøgler, der har betydning. Navne er ikke unikke, og mange tilsyneladende unikke identifikatorer, såsom CPR-numre, er det faktisk ikke, på grund af problemer med datapålidelighed i den virkelige verden." Kort sagt er dette en anbefaling om altid at have en autogenereret (typisk numerisk) SurrogateKey i stedet for en domænebaseret LogicalKey. Dette er et temmelig pat svar på et komplekst problem, selvom det er et, der vil være tilstrækkeligt i en række tilfælde og i det mindste er at foretrække frem for at have ingen PrimaryKey overhovedet.(Forfatterens note:Jeg har ikke været i stand til at finde denne "tidligere forfatter", når jeg søgte efter disse to sætninger på Google.)
Og et link til en opsummerende artikel om hovedargumenterne på hver side af Auto Keys versus Domain Keys debatten er tilvejebragt.
På den anden side fandt jeg tipsene til at "dele operativsystem, data og logning på forskellige fysiske diske" og "bruge RAID" lidt mystiske. Misforstå mig ikke - dette er sandsynligvis et godt råd under nogle omstændigheder, men jeg vil ikke inkludere det på min Top 20-liste.
Tip til databasedesign
af Wise Coders
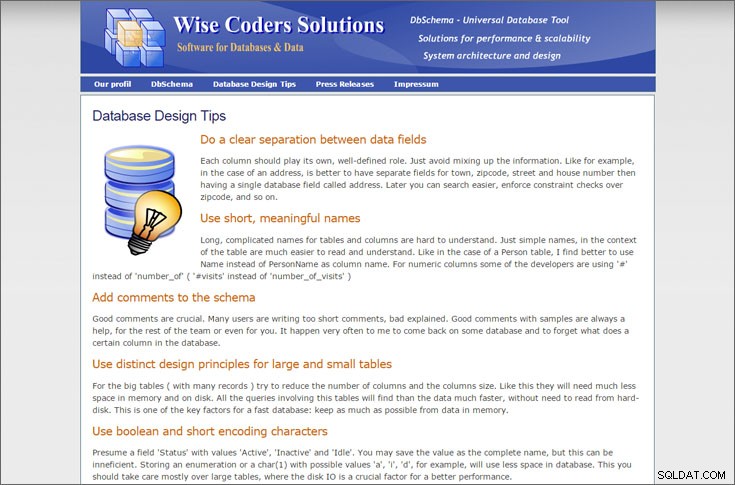
Der er et par unikke og interessante tips i denne samling, såsom en anbefaling om at lukke transaktioner så hurtigt som muligt.
Jeg er dog ikke helt enig i alle designtipsene her. For eksempel:
Antag et felt 'Status' med værdierne 'Aktiv', 'Inaktiv' og 'Idle'. Du kan gemme værdien som det fulde navn, men det kan være ineffektivt. Lagring af en opregning eller et tegn(1) med mulige værdier 'a', 'i', 'd' vil f.eks. bruge mindre plads i databasen.Dette er mildest talt kontroversielt - andre kilder fraråder at bruge "hemmelige koder" som denne. Brug i stedet en separat tabel til at gemme disse statuskoder.
Derudover er statistikken forbundet med præstationstip tvivlsom, og der er ingen eksempler i artiklen.
På en positiv bemærkning er dette en god kort liste over tips, som bør være tilgængelige for mellemliggende databasemodellere.
Ressourcer til begyndende databasedesignere
Lad os nu undersøge et par artikler for dem, der lige er begyndt i databasedesign.
Det grundlæggende i godt databasedesign i webudvikling
af Kayla Knight | Onextrapixel.com | 17. marts 2011
Her bliver vi lidt mere avancerede, med rådgivning lige fra funktionalitet til modelleringsværktøjer.
Ms. Knight leder os gennem en introduktion til databasedesign. Hendes artikel er interessant, fordi den lægger vægt på databaser til webudvikling. Alligevel er hendes pointer ret universelle og kan anvendes til databasedesign i mange situationer.
Artiklen starter med at bede os om at tænke bredt over funktionalitet, ikke kun databasen:
Tænk uden for databasen. Prøv at tænke over, hvad hjemmesiden skal gøre. For eksempel, hvis der er behov for et medlemswebsted, kan det første instinkt være at begynde at tænke på alle de data, hver bruger skal gemme. Glem det, det er til senere. Skriv hellere ned, at brugere og deres oplysninger skal gemmes i databasen, og hvad ellers? Hvad skal disse medlemmer gøre på webstedet? Vil de lave indlæg, uploade filer eller billeder eller sende beskeder? Så skal databasen have et sted til filer/billeder, indlæg og beskeder.Derfra tager Ms. Knight læseren ind i databasedesignværktøjer og de trin, der er involveret i processen. Hendes artikel giver eksempler og links til andre ressourcer.
Jeg tror, at denne artikel ville være en god introduktion for begyndere databasedesignere, og den burde fungere godt med Geek Girl's serie.
Udforskning af databasedesigntip
af Doug Lowe | For Dummies
Mr. Lowes "Dummies"-liste er en bred række af grundlæggende designtips. Du kan finde mange af disse andre steder, men det er nyttigt at have dem ét sted. Du vil ikke finde noget unikt eller meget kontroversielt, bortset fra en anbefaling om at bruge lagrede procedurer. Jeg sætter altid spørgsmålstegn ved denne stærke udtalelse, da jeg er meget bekymret over datamodelportabilitet for flere DBM-systemer.
Her er et af Mr. Lowes sunde fornuftsråd:
Undgå felter med navne som CustomerType, hvor værdien af feltet er en af flere konstanter, der ikke er defineret andre steder i databasen, såsom R for Retail eller W for Wholesale. Du har muligvis kun disse to typer kunder i dag, men applikationens behov kan ændre sig i fremtiden, hvilket kræver en tredje kundetype.Disse anbefalinger er mest passende, når du arbejder med SQL Server.
Fem enkle råd til databasedesign
af Lamont Adams | TechRepublic | 25. juni 2001
Nøgleordet for denne ressource er "simpelt". Du kan finde denne information med flere forklaringer og eksempler i andre artikler.
Men hr. Adams' råd om at "Take the user's keys away" er en interessant pointe, sjældent nævnt andre steder. Han fortsætter:
Når du beslutter, hvilket eller hvilke felter der skal bruges som nøgler i en tabel, skal du altid overveje de felter, som brugerne skal redigere. Det er normalt en dårlig idé at vælge et brugerredigerbart felt som nøgle.Mr. Adams' mening er, at du bør overveje brugerens potentielle krav om at redigere felter, når du beslutter, hvilke felter der skal bruges som nøgler. Jeg ville gerne have haft mere forklaring angående alternativer, såsom syntetiske/genererede nøgler, men konceptet er godt.
Jeg var uenig i det sidste punkt. Han anbefaler en "fudge-faktor" for hvert bord, du designer:
Ikke meget er værre end at opdage eller blive informeret om, at din "færdige" database mangler et felt til en vigtig information. Hos et firma, jeg arbejdede for, var dette en så almindelig hændelse, at vi begyndte at henvise til "databaser fryser" som "databaseslam".I mit sind er dette dybest set "at tilføje et par ekstra tekstfelter til slutningen." Dette lader til at modsige nogle af hr. Adams' andre tips, specielt dem om at forstå forretningsbehov og bruge meningsfulde navne. Disse ekstra fudge-felter ville bare blive kaldt noget i retning af "extra1" eller "extra2". Hvad er deres forretningsbehov? Og hvordan er disse meningsfulde navne? Selvom jeg godt kan lide de fleste af hans designtips, er denne "fudge-faktor" ikke noget, jeg overholder.
Databasedesign:hæderlige omtaler
Der er naturligvis andre artikler, der beskriver tips til databasedesign og bedste praksis. Du kan finde yderligere materiale på følgende links:
Relationel databasedesign:En primer om bedste praksis | af Digital Ethos | 24. december 2012
Bedste praksis for databaseskemadesign (begyndere) | af Jim Murphy | 28. marts 2011
IT Best Practices:Databasedesign | af University of Nebraska–Lincoln
Online databasedesignressourcer:Hvor ville du hen?
Som nævnt er denne liste bestemt ikke ment som en udtømmende undersøgelse af enhver databasedesignartikel på internettet. Vi har snarere identificeret adskillige artikler, som vi synes er nyttige, eller som har et særligt fokus, som du kan finde nyttige.
Du er velkommen til at anbefale yderligere artikler.