I vores sidste artikel om markører i PostgreSQL talte vi om ommonable xpressions (CTE). I dag fortsætter vi med at opdage nye alternativer til markører ved at bruge en mindre kendt funktion i PostgreSQL.
Vi bruger de data, som vi importerede i den forrige artikel (linket ovenfor). Jeg venter et øjeblik på, at du følger proceduren der.
Forstået? Okay.
Dataene er et taksonomidiagram over den naturlige verden. Som en påmindelse fra grundlæggende gymnasiebiologi er disse data organiseret af Carl Linnaeus i Rige, Fylum, Klasse, Orden, Familie, Slægt og Art. Naturligvis har videnskaben bevæget sig lidt fremad i de sidste 250 år, så det taksonomiske diagram er 21 niveauer dybt. Vi finder hierarkitræet i en tabel, der (ikke overraskende) kaldes itis.hierarchy .
Emnet for denne artikel er, hvordan man bruger ltrees i PostgreSQL. Specifikt, hvordan man bruger dem til at krydse et komplekst postsæt meget effektivt. I den forstand kan vi betragte dem som et andet surrogat for markører.
Dataene er ikke kureret (desværre for os) i et ltree-format, så vi vil transformere det lidt for artiklens skyld.
Først skal du installere ltree i den database, du bruger for at følge denne artikel. Selvfølgelig skal du være superbruger for at installere udvidelser.
OPRET UDVIDELSE HVIS IKKE FINDER ltree;
Nu vil vi bruge denne udvidelse til at give nogle meget effektive opslag. Vi bliver nødt til at transformere dataene til en opslagstabel. For at udføre denne transformation vil vi bruge CTE-teknikken, som vi dækkede i den sidste artikel. Undervejs skal vi tilføje de latinske navne og de engelske navne til taksonomitræet. Dette vil hjælpe os med at slå varer op efter nummer, latinske navne eller engelske navne.
-- Vi har brug for en lille hjælpefunktion til at fjerne ulovlige etiketnavne. CREATE OR REPLACE FUNCTION strip_label(thelabel text)RETURNERER TEXTAS $$ -- sørg for, at alle tegnene i etiketten er lovlige SELECT SELECT regexp_replace( regexp_erstat( regexp_erstat( regexp_erstat) ( regexp_replace( -- fjern alt andet end alnum (ja, det kunne være meget mere præcist) etiketten, '[^[:alnum:]]', '_','g'), -- konsolider understregninger '_+', '_', 'g'), -- strimler foran/efter understregninger '^_*', '', 'g'), '_*$', '', 'g'); $$LANGUAGE sql;CREATE MATERIALISED VIEW itis.world_view ASWITH RECURSIVE world AS ( -- Start med de grundlæggende kongeriger VÆLG h1.tsn, h1.parent_tsn, h1.tsn::text numeric_taxonomy, -- Der er ingen garanti for, at der vil være et tekstnavn COALESCE(l1.completename,h1.tsn::text,'')::text latin_taksonomi, -- og igen ingen garanti for et almindeligt engelsk navn COALESCE(v1.vernacular_name, lower(l1.completename),h1. tsn::text,'unk')::text english_taxonomy FRA itis.hierarchy h1 VENSTRE JOIN itis.longnames l1 PÅ h1.tsn =l1.tsn VENSTRE JOIN itis.vernaculars v1 TIL (h1.tsn, 'Engelsk') =( v1.tsn, v1.language) HVOR h1.parent_tsn =0 UNION ALL SELECT h1.tsn, h1.parent_tsn, w1.numeric_taxonomy || '.' || h1.tsn, w1.latin_taxonomy || '.' || COALESCE (strip_label(l1.completename), h1.tsn::text,'unk'), w1.english_taxonomy || '.' || strip_label(COALESCE(v1.vernacular_name, lower(l1.completename), h1.tsn::tekst, 'unk')) FRA itis.hie rarchy h1 JOIN verden w1 PÅ h1.parent_tsn =w1.tsn VENSTRE JOIN itis.longnames l1 PÅ h1.tsn =l1.tsn VENSTRE JOIN -- bare skift dette til "itis.vernaculars v1" for at tillade multipler og alle sprog. (Millioner af poster.) (SELECT tsn, min(vernacular_name) vernacular_name FROM itis.vernaculars WHERE language ='Engelsk' GRUPPE EFTER tsn) v1 ON (h1.tsn) =(v1.tsn) )SELECT w2.tsn, w2. parent_tsn, w2.numeric_taxonomy::ltree, w2.latin_taxonomy::ltree latin_taxonomy, w2.english_taxonomy::ltree english_taxonomyFROM world w2ORDER BY w2.numeric_taxonomyWITH NO DATA;
Lad os stoppe et øjeblik og dufte til blomsterne i denne forespørgsel. Til at begynde med oprettede vi det uden at udfylde nogen data. Dette giver os en chance for at tage os af eventuelle syntaktiske problemer, før vi genererer en masse ubrugelige data. Vi bruger den iterative karakter af det fælles tabeludtryk til at sammensætte en ret dyb struktur her, og vi kunne nemt udvide den til at dække flere sprog ved at tilføje data til sprogtabellen. Den materialiserede visning har også nogle interessante præstationskarakteristika. Det vil afkorte og genopbygge tabellen, hver gang en OPPDATER MATERIALISERET VISNING kaldes.
Det, vi skal gøre, er at genopfriske vores verdensbillede. Mest fordi det er sundt at gøre det fra tid til anden. Men i dette tilfælde, hvad det faktisk gør, er at udfylde den materialiserede visning med data fra itis skema.
OPPDATER MATERIALISERET VISNING itis.world_view; Det vil tage et par minutter at oprette de 600K+ rækker fra dataene.
De første par rækker vil se sådan ud:
┌────────────┬─────────┬────────────────── ──── den appearats────eptarat ─── den appearat ─ ovearat ──── den appearats────eptarat ─── den appearat ──øre ─essenepladdende ─── den ommearateterarateterarat. .Holometabola.ants.Ans.Aculeata.Apoid_Wasps ... ││ │ │… .cicadakillers.crabroninae.Larrini.gastrosicina.gastrosicus.gastrosicus… ││ │ │… _xanthophilus ││ 768374 │ 1009038 │ dyrer .hexapods.insects.winged_in…││ │ │…sekter.moderne_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_hveps…││ │ │….cicadakillers.crabroninae.l Arrini.gastrosericina.gastrosicus.gastrosicus… ││ │ │… _zoyphion ││ 768374 │ 1009039 │ Animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.inscts.winged_in… ││ │ │ │ects.modern_wing_folding.insctsektioner .aculeata.apoid_wasps…││ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…││ │ │…_zyx ││ 768216 │ 768387 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in …││ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…││ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex ││ 768387 │ 1009040 │ animals.bilateria.protostomia.ecdysozoa.arthropods .hexapods.insects.winged_in…││ │ │…sekter.moderne_vingefoldende_insekter.holometabola.myrer.myrer.aculeata.apoid_hvepse…││ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex.holotachysph…t│└h ─ Hver ─────────────────────────────│
I en taksonomi ville grafen se nogenlunde sådan ud:
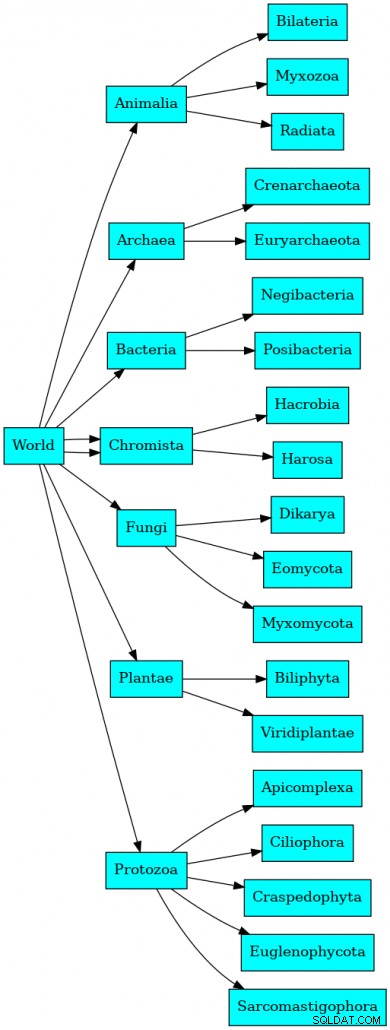
Selvfølgelig ville det faktisk være 21 niveauer dybt, og 600.000+ rekorder i alt.
Nu kommer vi til den sjove del! ltræer giver en måde at lave nogle meget komplekse forespørgsler på et hierarki. Hjælpen til det er i PostgreSQL-dokumentationen, så vi vil ikke gå ret dybt ind i det her. For en (meget hurtig) forståelse kaldes hvert segment af et ltræ en etiket. Så dette ltree kingdom.phylum.class.order.family.genus.species har 7 etiketter.
Forespørgsler mod et ltree bruger en speciel notation, der ligner regulære udtryk i en begrænset form.
Her er et simpelt eksempel:Animalia.*.Homo_sapiens
Så en forespørgsel om at finde menneskeheden i verden ville se sådan ud:
VÆLG tsn, parent_tsn, latin_taxonomy, english_taxonomy FROM itis.world_view WHERE latin_taxonomy ~ 'Animalia.*.Homo_sapiens';
Hvilket resulterer i det forventede:
┌────────┬────────────┬─────────────────── ─ Hver ─ ovearat ─ Hver ─ Hver ┤│ 180092 │ 180091 │ Animalia.Bilateria.Deuterostomia.Chordata.Vert…│ animals.bilateria.deuterostomia.chordates.v…││ │ │…ebrata.Gnathostomaata. pattedyr.…││ │ │….Eutheria.Primates.Haplorrhini.Simiiformes.Hom…│…theria.eutheria.primates.haplorrhini.simiif…││ │ │…inoidea.Hominidae_Homoienamesmoemin.Hominidae.Homoienames .Store_aber.African_aber.ho…││ │ │ │…minoider.Menneske │└────────┴────────────────────── ──────────── ──── den appearats────eptarat ──essen ──────────────────────┘
Selvfølgelig ville PostgreSQL aldrig lade det blive ved dette. Der er et omfattende sæt af operatorer, indekser, transformationer og eksempler.
Tag et kig på det store udvalg af muligheder, som denne teknik låser op.
Forestil dig nu, at denne teknik anvendes på andre komplekse datatyper såsom delnumre, køretøjsidentifikationsnumre, styklistestrukturer eller ethvert andet klassifikationssystem. Det er ikke nødvendigt at eksponere denne struktur for slutbrugeren på grund af den uoverkommelige komplekse indlæringskurve at bruge den direkte. Men det er fuldt ud muligt at bygge en "opslagsskærm" baseret på en struktur som denne, der er meget kraftfuld og skjuler kompleksiteten af implementeringen.
Til vores næste artikel i serien vil vi udforske brugen af plug in-sprog. I forbindelse med at finde alternativer til markører i PostgreSQL, vil vi bruge et sprog efter eget valg til at modellere dataene på den mest passende måde til vores behov. Vi ses næste gang!