Det er meget nemt at bevise, at følgende to udtryk giver nøjagtig samme resultat:den første dag i den aktuelle måned.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); Og de tager omtrent samme tid at beregne:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
På mit system tog begge batches omkring 175 sekunder at fuldføre.
Så hvorfor ville du foretrække den ene metode frem for den anden? Når en af dem virkelig roder med kardinalitetsestimater .
Lad os som en hurtig primer sammenligne disse to værdier:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Bemærk, at de faktiske værdier repræsenteret her vil ændre sig, afhængigt af hvornår du læser dette indlæg – "i dag" refereret til i kommentaren er den 5. september 2013, den dag dette indlæg blev skrevet. I oktober 2013 vil outputtet f.eks. være 2013-10-01 og 1786-04-01 .)
Med det af vejen, lad mig vise dig, hvad jeg mener...
En repro
Lad os oprette en meget simpel tabel med kun en klynget DATE kolonne, og indlæs 15.000 rækker med værdien 1786-05-01 og 50 rækker med værdien 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
Og lad os så se på de faktiske planer for disse to forespørgsler:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
De grafiske planer ser rigtige ud:
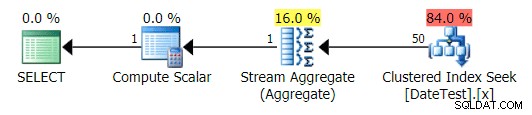
Grafisk plan for DATEDIFF(MONTH, 0, GETDATE()) forespørgsel
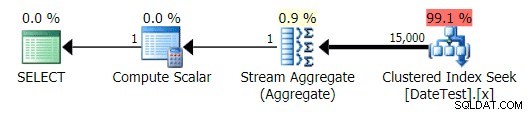
Grafisk plan for DATEDIFF(MONTH, GETDATE(), 0) forespørgsel
Men de estimerede omkostninger er ude af skyggen – bemærk hvor meget højere de estimerede omkostninger er for den første forespørgsel, som kun returnerer 50 rækker, sammenlignet med den anden forespørgsel, som returnerer 15.000 rækker!

Opgørelsesgitter, der viser estimerede omkostninger
Og fanen Top Operations viser, at den første forespørgsel (leder efter 2013-09-01 ) anslået, at den ville finde 15.000 rækker, mens den i virkeligheden kun fandt 50; den anden forespørgsel viser det modsatte:den forventede at finde 50 rækker, der matcher 1786-05-01 , men fandt 15.000. Baseret på ukorrekte kardinalitetsestimater som dette, er jeg sikker på, at du kan forestille dig, hvilken slags drastisk effekt dette kunne have på mere komplekse forespørgsler mod meget større datasæt.
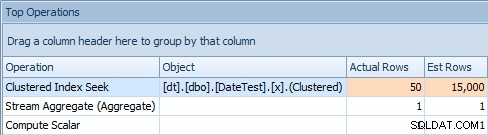
Top Operations-fane for første forespørgsel [DATEDIFF(MONTH, 0, GETDATE())]
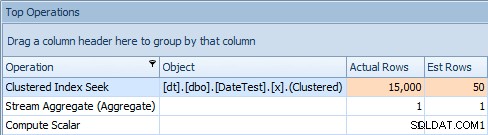
Top Operations-fane for anden forespørgsel [DATEDIFF(MONTH, 0, GETDATE())]
En lidt anderledes variation af forespørgslen, der bruger et andet udtryk til at beregne begyndelsen af måneden (antydet i begyndelsen af indlægget), udviser ikke dette symptom:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Planen ligner meget forespørgsel 1 ovenfor, og hvis du ikke kiggede nærmere efter, ville du tro, at disse planer er ækvivalente:
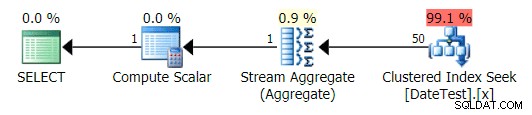
Grafisk plan for ikke-DATEDIFF-forespørgsler
Når du ser på fanen Top Operations her, ser du dog, at estimatet er bange på:
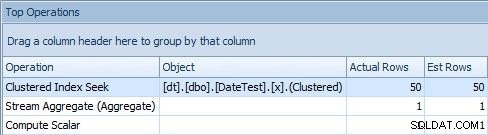
Top Operations-fane, der viser nøjagtige estimater
På denne særlige datastørrelse og forespørgsel er nettoydelsespåvirkningen (især varighed og læsninger) stort set irrelevant. Og det er vigtigt at bemærke, at selve forespørgslerne stadig returnerer korrekte data; det er bare, at estimaterne er forkerte (og kan føre til en værre plan, end jeg har vist her). Når det er sagt, hvis du udleder konstanter ved hjælp af DATEDIFF i dine forespørgsler på denne måde, bør du virkelig teste denne påvirkning i dit miljø.
Så hvorfor sker det?
For at sige det enkelt har SQL Server en DATEDIFF fejl, hvor den bytter andet og tredje argument ved evaluering af udtrykket for kardinalitetsestimat. Dette ser ud til at involvere konstant foldning, i det mindste perifert; der er mange flere detaljer om konstant foldning i denne Books Online-artikel, men desværre afslører artiklen ingen information om denne særlige fejl.
Der er en løsning – eller er der?
Der er en vidensbaseartikel (KB #2481274), der hævder at løse problemet, men den har et par egne problemer:
- KB-artiklen hævder, at problemet er blevet rettet i forskellige servicepakker eller kumulative opdateringer til SQL Server 2005, 2008 og 2008 R2. Symptomet er dog stadig til stede i grene, der ikke er eksplicit nævnt der, selvom de har set mange yderligere CU'er siden artiklen blev offentliggjort. Jeg kan stadig reproducere dette problem på SQL Server 2008 SP3 CU #8 (10.0.5828) og SQL Server 2012 SP1 CU #5 (11.0.3373).
- Den forsømmer at nævne, at for at drage fordel af rettelsen skal du aktivere sporingsflag 4199 (og "drage fordel" af alle de andre måder, som specifikt sporingsflag kan påvirke optimeringsværktøjet). Det faktum, at dette sporingsflag er påkrævet for rettelsen, er nævnt i et relateret Connect-element, #630583, men denne information er ikke kommet tilbage til KB-artiklen. Hverken KB-artiklen eller Connect-elementet giver nogen indsigt i årsagen (at argumenterne til
DATEDIFFer blevet byttet under evalueringen). På plussiden kører ovenstående forespørgsler med sporingsflaget på (ved hjælp afOPTION (QUERYTRACEON 4199)) giver planer, der ikke har det ukorrekte skøn.
- Det foreslår, at du bruger dynamisk SQL til at omgå problemet. I mine tests bruger jeg et andet udtryk (såsom det ovenfor, der ikke bruger
DATEDIFF) overvandt problemet i moderne builds af både SQL Server 2008 og SQL Server 2012. Anbefaling af dynamisk SQL her er unødvendigt komplekst og sandsynligvis overkill, givet at et andet udtryk kunne løse problemet. Men hvis du skulle bruge dynamisk SQL, ville jeg gøre det på denne måde i stedet for den måde, de anbefaler i KB-artiklen, vigtigst af alt for at minimere SQL-injektionsrisici:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(Og du kan tilføje
OPTION (RECOMPILE)der, afhængigt af hvordan du vil have SQL Server til at håndtere parametersniffing.)Dette fører til den samme plan som den tidligere forespørgsel, der ikke bruger
DATEDIFF, med korrekte skøn og 99,1 % af omkostningerne i den grupperede indekssøgning.En anden tilgang, der kan friste dig (og med dig, jeg mener mig, da jeg først begyndte at undersøge) er at bruge en variabel til at beregne værdien på forhånd:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Problemet med denne tilgang er, at du med en variabel vil ende med en stabil plan, men kardinaliteten vil være baseret på et gæt (og typen af gæt vil afhænge af tilstedeværelsen eller fraværet af statistikker) . I dette tilfælde er her de estimerede vs. faktiske:
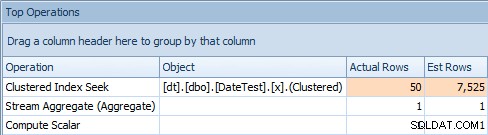
Top Operations-fane for forespørgsel, der bruger en variabelDette er tydeligvis ikke rigtigt; det ser ud til, at SQL Server har gættet, at variablen ville matche 50 % af rækkerne i tabellen.
SQL Server 2014
Jeg fandt et lidt anderledes problem i SQL Server 2014. De første to forespørgsler er rettet (ved ændringer af kardinalitetsberegningen eller andre rettelser), hvilket betyder, at DATEDIFF argumenter skiftes ikke længere. Yay!
En regression ser dog ud til at være blevet introduceret til løsningen af at bruge et andet udtryk - nu lider det af et unøjagtigt estimat (baseret på det samme 50% gæt som ved at bruge en variabel). Dette er de forespørgsler, jeg kørte:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Her er opgørelsesgitteret, der sammenligner de estimerede omkostninger og faktiske runtime-metrics:
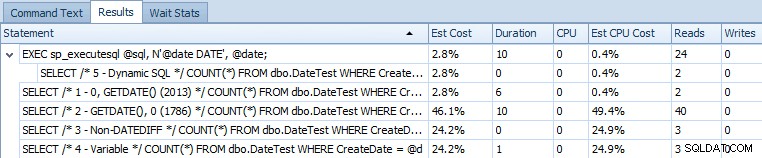
Estimerede omkostninger for de 5 prøveforespørgsler på SQL Server 2014
Og disse er deres estimerede og faktiske rækkeantal (samlet ved hjælp af Photoshop):

Estimeret og faktisk rækkeantal for de 5 forespørgsler på SQL Server 2014
Det fremgår tydeligt af dette output, at det udtryk, der tidligere løste problemet, nu har introduceret et andet. Jeg er ikke sikker på, om dette er et symptom på at køre i en CTP (f.eks. noget, der vil blive rettet), eller om dette virkelig er en regression.
I dette tilfælde har sporingsflag 4199 (i sig selv) ingen effekt; den nye kardinalitetsberegner gætter og er simpelthen ikke korrekt. Hvorvidt det fører til et faktisk præstationsproblem afhænger meget af mange andre faktorer ud over dette indlægs omfang.
Hvis du støder på dette problem, kan du – i det mindste i nuværende CTP'er – gendanne den gamle adfærd ved hjælp af OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Sporingsflag 9481 deaktiverer den nye kardinalitetsestimator, som beskrevet i disse udgivelsesbemærkninger (som helt sikkert vil forsvinde eller i det mindste flytte på et tidspunkt). Dette gendanner igen de korrekte estimater for ikke-DATEDIFF version af forespørgslen, men løser desværre stadig ikke problemet, hvor et gæt er baseret på en variabel (og ved at bruge TF9481 alene, uden TF4199, tvinger de to første forespørgsler til at gå tilbage til den gamle argument-swapping-adfærd).
Konklusion
Jeg vil indrømme, at dette var en kæmpe overraskelse for mig. Tak til Martin Smith og t-clausen.dk for at holde ud og overbevise mig om, at dette var et reelt og ikke indbildt problem. Også en stor tak til Paul White (@SQL_Kiwi), som hjalp mig med at bevare min fornuft og mindede mig om de ting, jeg ikke burde sige. :-)
Da jeg ikke var klar over denne fejl, var jeg stejlt på, at den bedre forespørgselsplan blev genereret simpelthen ved at ændre forespørgselsteksten overhovedet, ikke på grund af den specifikke ændring. Som det viser sig, nogle gange en ændring af en forespørgsel, som du ville antage vil ikke gøre nogen forskel, faktisk vil. Så jeg anbefaler, at hvis du har lignende forespørgselsmønstre i dit miljø, tester du dem og sikrer dig, at kardinalitetsestimaterne kommer rigtigt ud. Og noter dig for at teste dem igen, når du opgraderer.