I mit sidste indlæg så vi, hvordan en forespørgsel med et skalært aggregat kunne transformeres af optimeringsværktøjet til en mere effektiv form. Som en påmindelse, her er skemaet igen:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Planvalg
Med 10.000 rækker i hver af basistabellerne kommer optimeringsværktøjet med en simpel plan, der beregner det maksimale ved at læse alle 30.000 rækker til et samlet:
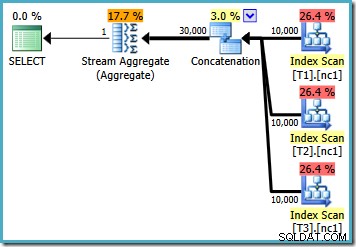
Med 50.000 rækker i hver tabel bruger optimeringsværktøjet lidt mere tid på problemet og finder en smartere plan. Den læser kun den øverste række (i faldende rækkefølge) fra hvert indeks og beregner derefter maksimum fra kun disse 3 rækker:
En optimeringsfejl
Du kan måske bemærke noget lidt mærkeligt ved det estimerede plan. Sammenkædningsoperatoren læser en række fra tre tabeller og producerer på en eller anden måde tolv rækker! Dette er en fejl, der er forårsaget af en fejl i kardinalitetsestimater, som jeg rapporterede i maj 2011. Den er stadig ikke rettet fra SQL Server 2014 CTP 1 (selvom den nye kardinalitetsestimator bruges), men jeg håber, at den vil blive rettet til endelig udgivelse.
For at se, hvordan fejlen opstår, skal du huske, at et af planalternativerne, som optimeringsværktøjet overvejer for sagen på 50.000 rækker, har delvise aggregater under Sammenkædningsoperatoren:
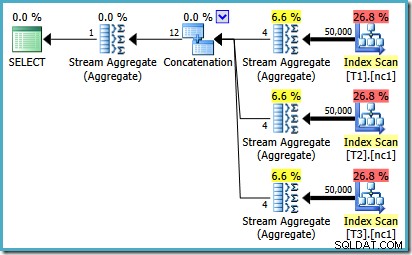
Det er kardinalitetsestimatet for disse delvise MAX aggregater, der er skyld i. De anslår fire rækker, hvor resultatet med garanti bliver én række. Du kan muligvis se et andet tal end fire – det afhænger af, hvor mange logiske processorer der er tilgængelige for optimeringsværktøjet på det tidspunkt, planen kompileres (se fejllinket ovenfor for flere detaljer).
Optimeringsværktøjet erstatter senere de delvise aggregater med Top (1) operatorer, som genberegner kardinalitetsestimatet korrekt. Desværre afspejler sammenkædningsoperatoren stadig estimaterne for de erstattede partielle aggregater (3 * 4 =12). Som et resultat ender vi med en sammenkædning, der læser 3 rækker og producerer 12.
Brug af TOP i stedet for MAX
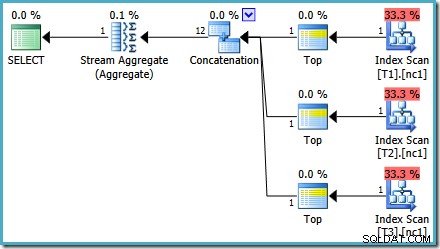
Ser man igen på 50.000 rækker planen, ser det ud til, at den største forbedring fundet af optimizeren er at bruge Top (1) operatorer i stedet for at læse alle rækker og beregne den maksimale værdi ved hjælp af brute force. Hvad sker der, hvis vi prøver noget lignende og omskriver forespørgslen ved at bruge Top eksplicit?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Udførelsesplanen for den nye forespørgsel er:
Denne plan er helt anderledes end den, der er valgt af optimeringsværktøjet til MAX forespørgsel. Den har tre ordnede indeksscanninger, to Merge Joins, der kører i sammenkædningstilstand, og en enkelt Top-operatør. Denne nye forespørgselsplan har nogle interessante funktioner, som er værd at undersøge lidt detaljeret.
Plananalyse
Den første række (i faldende indeksrækkefølge) læses fra hver tabels ikke-klyngede indeks, og en Merge Join, der fungerer i sammenkædningstilstand, bruges. Selvom Merge Join-operatøren ikke udfører en joinforbindelse i normal forstand, er denne operatørs behandlingsalgoritme let tilpasset til at sammenkæde sine input i stedet for at anvende join-kriterier.
Fordelen ved at bruge denne operatør i den nye plan er, at Merge Concatenation bevarer sorteringsrækkefølgen på tværs af sine input. Derimod læser en almindelig sammenkædningsoperator fra sine input i rækkefølge. Diagrammet nedenfor illustrerer forskellen (klik for at udvide):
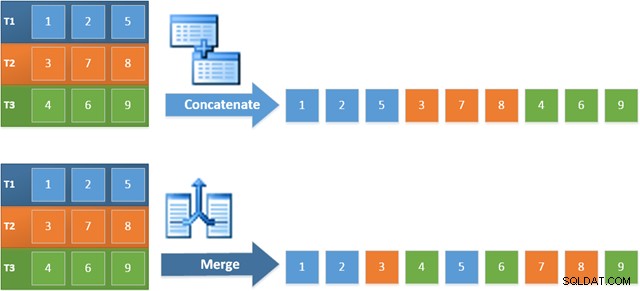
Den rækkefølgebevarende adfærd i Merge Concatenation betyder, at den første række produceret af fletoperatoren længst til venstre i den nye plan er garanteret rækken med den højeste værdi i kolonne c1 på tværs af alle tre tabeller. Mere specifikt fungerer planen som følger:
- Én række læses fra hver tabel (i indeks faldende rækkefølge); og
- Hver fletning udfører én test for at se, hvilken af dens inputrækker der har den højeste værdi
Dette virker som en meget effektiv strategi, så det kan virke mærkeligt, at optimeringsværktøjets MAX planen har en anslået pris på mindre end halvdelen af den nye plan. Grunden er i høj grad, at ordrebevarende Merge Concatenation antages at være dyrere end en simpel Sammenkædning. Optimeringsværktøjet er ikke klar over, at hver fletning kun kan se maksimalt én række, og overvurderer omkostningerne som følge heraf.
Flere omkostningsproblemer
Strengt taget sammenligner vi ikke æbler med æbler her, fordi de to planer er til forskellige forespørgsler. At sammenligne omkostninger som det er generelt ikke en gyldig ting at gøre, selvom SSMS gør præcis det ved at vise omkostningsprocenter for forskellige udsagn i en batch. Men jeg afviger.
Hvis du ser på den nye plan i SSMS i stedet for SQL Sentry Plan Explorer, vil du se noget som dette:
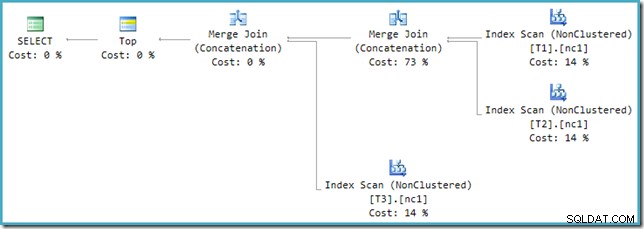
En af Merge Join Concatenation-operatørerne har en estimeret pris på 73%, mens den anden (der opererer på nøjagtigt det samme antal rækker) er vist som at det ikke koster noget overhovedet. Et andet tegn på, at der er noget galt her, er, at operatøromkostningsprocenterne i denne plan ikke er 100 %.
Optimering versus Execution Engine
Problemet ligger i en inkompatibilitet mellem optimerings- og udførelsesmotoren. I optimizeren kan Union og Union All have 2 eller flere input. I udførelsesmotoren er det kun sammenkædningsoperatøren, der kan acceptere 2 eller flere input; Merge Join kræver præcis to indgange, selv når de er konfigureret til at udføre en sammenkædning i stedet for en joinforbindelse.
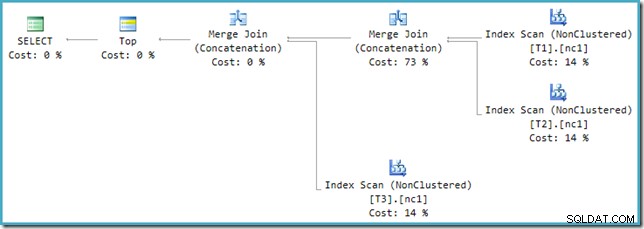
For at løse denne inkompatibilitet anvendes en efter-optimerings-omskrivning for at oversætte optimizerens outputtræ til en form, som eksekveringsmotoren kan håndtere. Hvor en Union eller Union All med mere end to input implementeres ved hjælp af Merge, er der behov for en kæde af operatører. Med tre input til Union All i denne sag er der behov for to Merge Unions:
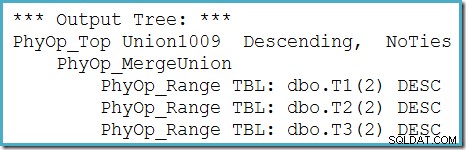
Vi kan se optimizerens output-træ (med tre input til en fysisk fletteunion) ved hjælp af sporingsflag 8607:
En ufuldstændig rettelse
Desværre er omskrivningen efter optimering ikke perfekt implementeret. Det gør lidt rod i omkostningstallene. Når man afrunder problemer til side, lægger planomkostningerne sig op til 114 %, mens de ekstra 14 % kommer fra input til den ekstra Merge Join-sammenkædning, der genereres af omskrivningen:
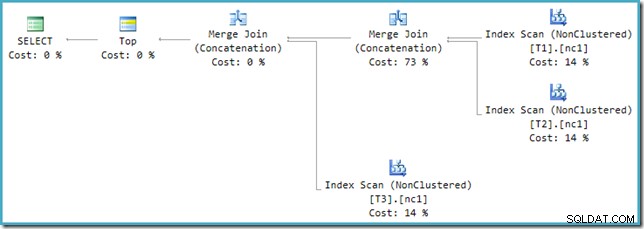
Fletning længst til højre i denne plan er den oprindelige operatør i optimeringsværktøjets outputtræ. Det er tildelt de fulde omkostninger ved Union All-operationen. Den anden fletning tilføjes ved omskrivningen og modtager en pris på nul.
Uanset hvilken måde vi vælger at se på det (og der er forskellige problemer, der påvirker almindelig sammenkædning), ser tallene mærkelige ud. Plan Explorer gør sit bedste for at omgå de ødelagte oplysninger i XML-planen ved i det mindste at sikre, at tallene summer op til 100 %:
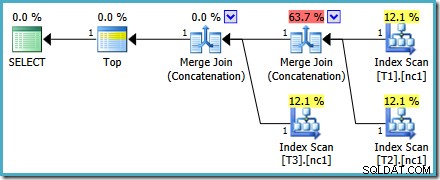
Dette særlige omkostningsproblem er løst i SQL Server 2014 CTP 1:
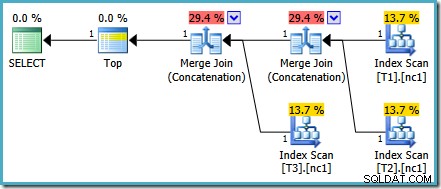
Omkostningerne ved Merge Concatenation er nu ligeligt fordelt mellem de to operatører, og procenterne summerer til 100%. Fordi den underliggende XML er blevet rettet, formår SSMS også at vise de samme tal.
Hvilken plan er bedre?
Hvis vi skriver forespørgslen ved hjælp af MAX , er vi nødt til at stole på, at optimizeren vælger at udføre det ekstra arbejde, der er nødvendigt for at finde en effektiv plan. Hvis optimeringsværktøjet finder en tilsyneladende god nok plan tidligt, kan den producere en relativt ineffektiv plan, der læser hver række fra hver af basistabellerne:
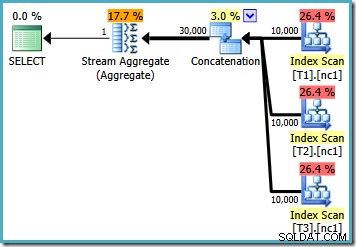
Hvis du kører SQL Server 2008 eller SQL Server 2008 R2, vil optimeringsværktøjet stadig vælge en ineffektiv plan uanset antallet af rækker i basistabellerne. Følgende plan blev produceret på SQL Server 2008 R2 med 50.000 rækker:
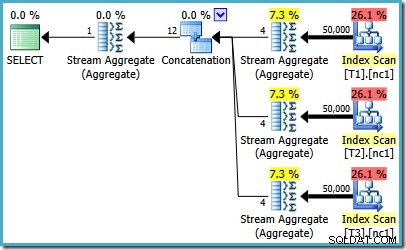
Selv med 50 millioner rækker i hver tabel tilføjer 2008 og 2008 R2 optimizeren bare parallelitet, den introducerer ikke de bedste operatører:
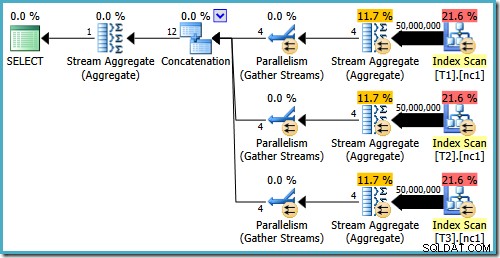
Som nævnt i mit tidligere indlæg kræves sporingsflag 4199 for at få SQL Server 2008 og 2008 R2 til at producere planen med Top-operatører. SQL Server 2005 og 2012 og fremefter kræver ikke sporingsflaget:
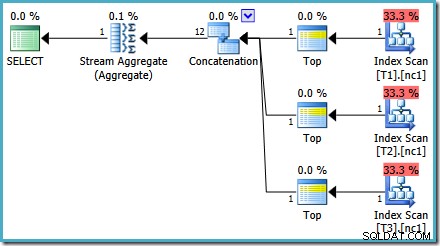
TOP med BESTIL AF
Når vi forstår, hvad der foregår i de tidligere eksekveringsplaner, kan vi træffe et bevidst (og informeret) valg om at omskrive forespørgslen ved at bruge en eksplicit TOP med BESTIL EFTER:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Den resulterende eksekveringsplan kan have omkostningsprocenter, der ser mærkelige ud i nogle versioner af SQL Server, men den underliggende plan er sund. Omskrivningen efter optimering, der får tallene til at se ulige ud, anvendes efter forespørgselsoptimering er fuldført, så vi kan være sikre på, at optimeringsprogrammets planvalg ikke blev påvirket af dette problem.
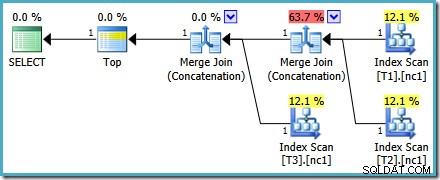
Denne plan ændres ikke afhængigt af antallet af rækker i basistabellen og kræver ingen sporingsflag for at generere. En lille ekstra fordel er, at denne plan findes af optimeringsværktøjet under den første fase af omkostningsbaseret optimering (søgning 0):
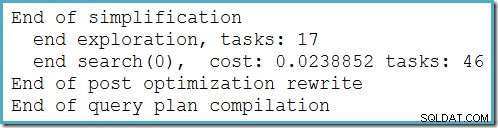
Den bedste plan valgt af optimeringsværktøjet til MAX forespørgsel påkrævet, kører to faser af omkostningsbaseret optimering (søg 0 og søg 1).
Der er en lille semantisk forskel mellem TOP forespørgsel og den originale MAX form, som jeg bør nævne. Hvis ingen af tabellerne indeholder en række, ville den oprindelige forespørgsel producere en enkelt NULL resultat. Erstatningen TOP (1) forespørgsel producerer intet output overhovedet under de samme omstændigheder. Denne forskel er ikke ofte vigtig i forespørgsler fra den virkelige verden, men det er noget, man skal være opmærksom på. Vi kan replikere adfærden for TOP ved hjælp af MAX i SQL Server 2008 og frem ved at tilføje et tomt sæt GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Denne ændring påvirker ikke de eksekveringsplaner, der er genereret for MAX forespørgsel på en måde, der er synlig for slutbrugere.
MAX med fletsammenkædning
I betragtning af succesen med Merge Join Concatenation i TOP (1) udførelsesplan, er det naturligt at spekulere på, om den samme optimale plan kunne genereres for den oprindelige MAX spørg, om vi tvinger optimeringsværktøjet til at bruge Merge Concatenation i stedet for almindelig Sammenkædning for UNION ALL operation.
Der er et forespørgselstip til dette formål – MERGE UNION – men desværre fungerer det kun korrekt i SQL Server 2012 og fremefter. I tidligere versioner er UNION tip påvirker kun UNION forespørgsler, ikke UNION ALL . I SQL Server 2012 og fremefter kan vi prøve dette:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
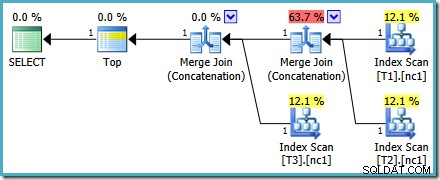
Vi belønnes med en plan, der indeholder Merge Concatenation. Desværre er det ikke helt alt, hvad vi kunne have håbet på:
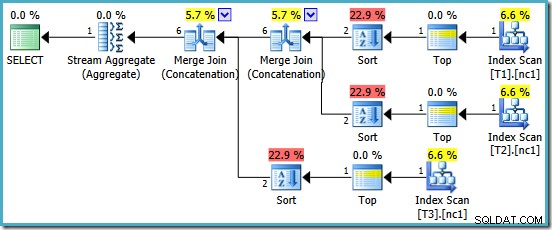
De interessante operatører i denne plan er den slags. Bemærk estimeringen af 1 række input kardinalitet og 4 række estimering på output. Årsagen burde være bekendt for dig nu:Det er den samme delvise aggregerede kardinalitetsvurderingsfejl, som vi diskuterede tidligere.
Tilstedeværelsen af slagsen afslører endnu et problem med de delvise aggregater. Ikke alene producerer de et ukorrekt kardinalitetsestimat, de bevarer heller ikke indeksrækkefølgen, der ville gøre sortering unødvendig (Merge Concatenation kræver sorterede input). De delvise aggregater er skalære MAX aggregater, garanteret at producere én række, så spørgsmålet om bestilling burde alligevel være uløst (der er kun én måde at sortere én række på!)
Det er en skam, for uden den slags ville dette være en anstændig udførelsesplan. Hvis de delvise aggregater blev implementeret korrekt, og MAX skrevet med en GROUP BY () klausul, kunne vi endda håbe, at optimeringsværktøjet kunne opdage, at de tre Tops og det endelige Stream Aggregate kunne erstattes af en enkelt sidste Top-operatør, hvilket giver nøjagtig den samme plan som den eksplicitte TOP (1) forespørgsel. Optimeringsværktøjet indeholder ikke denne transformation i dag, og jeg formoder ikke, at det ville være nyttigt nok ofte nok til at gøre det værd at inkludere det i fremtiden.
Afsluttende ord
Bruger TOP vil ikke altid være at foretrække frem for MIN eller MAX . I nogle tilfælde vil det give en væsentlig mindre optimal plan. Pointen med dette indlæg er, at forståelsen af de transformationer, der anvendes af optimeringsværktøjet, kan foreslå måder at omskrive den oprindelige forespørgsel på, som kan vise sig at være nyttig.