I mit sidste indlæg viste jeg nogle effektive tilgange til grupperet sammenkædning. Denne gang ville jeg tale om et par yderligere facetter af dette problem, som vi nemt kan opnå med FOR XML PATH fremgangsmåde:bestilling af listen og fjernelse af dubletter.
Der er et par måder, hvorpå jeg har set folk ønsker, at den kommaseparerede liste skal bestilles. Nogle gange ønsker de, at varen på listen skal ordnes alfabetisk; Det viste jeg allerede i mit forrige indlæg. Men nogle gange vil de have det sorteret efter en anden egenskab, som faktisk ikke bliver introduceret i outputtet; for eksempel vil jeg måske bestille listen efter seneste vare først. Lad os tage et simpelt eksempel, hvor vi har et Medarbejderbord og et CoffeeOrders bord. Lad os bare udfylde én persons ordrer i et par dage:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Hvis vi bruger den eksisterende tilgang uden at angive en ORDER BY , får vi en vilkårlig rækkefølge (i dette tilfælde er det højst sandsynligt, at du vil se rækkerne i den rækkefølge, de blev indsat, men er ikke afhængig af det med større datasæt, flere indekser osv.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultater (husk, du kan få *forskellige* resultater, medmindre du angiver en ORDER BY ):
Jack | Stor dobbelt dobbelt, Medium dobbelt dobbelt, Stor Vanilla Latte, Medium dobbelt dobbelt
Hvis vi vil sortere listen alfabetisk, er det enkelt; vi tilføjer bare ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultater:
Navn | OrdrerJack | Stor dobbelt dobbelt, Stor Vanilla Latte, Medium dobbelt dobbelt, Medium dobbelt dobbelt
Vi kan også sortere efter en kolonne, der ikke vises i resultatsættet; for eksempel kan vi bestille efter seneste kaffebestilling først:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultater:
Navn | OrdrerJack | Mellem dobbelt dobbelt, Stor Vanilla Latte, Mellem dobbelt dobbelt, Stor dobbelt dobbelt
En anden ting, vi ofte ønsker at gøre, er at fjerne dubletter; der er trods alt ringe grund til at se "Medium double double" to gange. Vi kan eliminere det ved at bruge GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Nu *skeder* dette for at ordne output alfabetisk, men igen kan du ikke stole på dette:
Navn | OrdrerJack | Stor dobbelt dobbelt, Stor Vanilla Latte, Medium dobbelt dobbelt
Hvis du vil garantere, at du bestiller på denne måde, kan du blot tilføje en BESTILLING AF igen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaterne er de samme (men jeg vil gentage, dette er kun en tilfældighed i dette tilfælde; hvis du vil have denne rækkefølge, så sig det altid):
Navn | OrdrerJack | Stor dobbelt dobbelt, Stor Vanilla Latte, Medium dobbelt dobbelt
Men hvad nu hvis vi vil fjerne dubletter *og* sortere listen efter den seneste kaffebestilling først? Din første tilbøjelighed kan være at beholde GROUP BY og skift bare ORDER BY , sådan her:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Det vil ikke virke, da OrderDate er ikke grupperet eller aggregeret som en del af forespørgslen:
Kolonne "dbo.CoffeeOrders.OrderDate" er ugyldig i ORDER BY-sætningen, fordi den ikke er indeholdt i hverken en aggregeret funktion eller GROUP BY-sætningen.
En løsning, som ganske vist gør forespørgslen lidt grimmere, er først at gruppere ordrerne separat og derefter kun tage rækkerne med maks. dato for den kaffeordre pr. medarbejder:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultater:
Navn | OrdrerJack | Mellem dobbelt dobbelt, Stor Vanilla Latte, Stor dobbelt dobbelt
Dette opnår begge vores mål:Vi har elimineret dubletter, og vi har sorteret listen efter noget, der faktisk ikke er på listen.
Ydeevne
Du undrer dig måske over, hvor dårligt disse metoder klarer sig i forhold til et mere robust datasæt. Jeg vil udfylde vores tabel med 100.000 rækker, se, hvordan de klarer sig uden yderligere indekser, og derefter køre de samme forespørgsler igen med en lille smule indeksjustering for at understøtte vores forespørgsler. Så først, få 100.000 rækker fordelt på 1.000 medarbejdere:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Lad os nu bare køre hver af vores forespørgsler to gange og se, hvordan timingen er ved andet forsøg (vi tager et spring af tro her og antager, at vi – i en ideel verden – vil arbejde med en klar cache ). Jeg kørte disse i SQL Sentry Plan Explorer, da det er den nemmeste måde, jeg kender til at tidsindstille og sammenligne en masse individuelle forespørgsler:
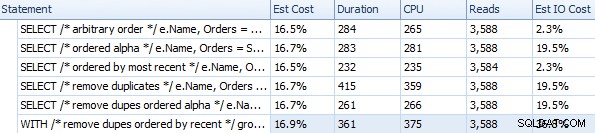 Varighed og andre runtime-metrics for forskellige FOR XML PATH-tilgange
Varighed og andre runtime-metrics for forskellige FOR XML PATH-tilgange
Disse timings (varigheden er i millisekunder) er virkelig ikke så dårlige overhovedet IMHO, når du tænker på, hvad der rent faktisk bliver gjort her. Den mest komplicerede plan, i det mindste visuelt, så ud til at være den, hvor vi fjernede dubletter og sorterede efter seneste rækkefølge:
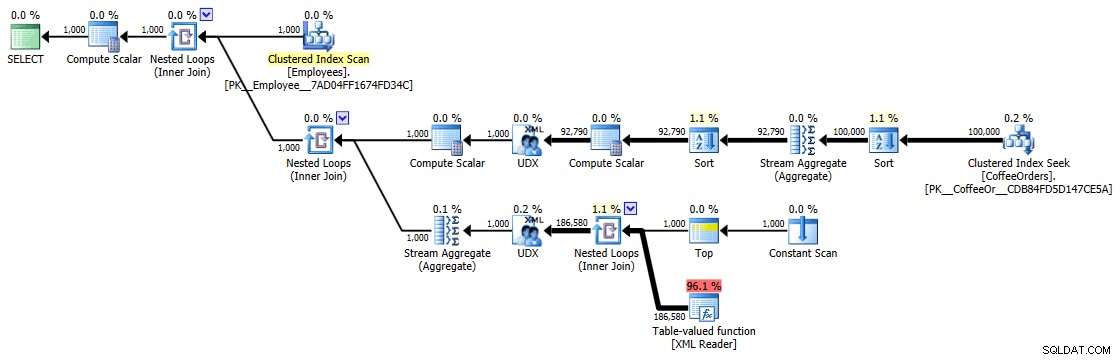 Udførelsesplan for grupperet og sorteret forespørgsel
Udførelsesplan for grupperet og sorteret forespørgsel
Men selv den dyreste operatør her – den XML-tabelvurderede funktion – ser ud til at være udelukkende CPU (selvom jeg frit vil indrømme, at jeg ikke er sikker på, hvor meget af det faktiske arbejde, der er afsløret i forespørgselsplanens detaljer):
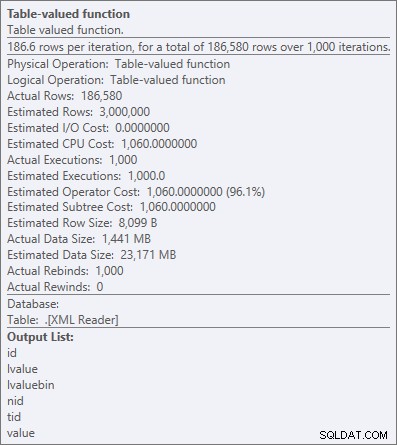 Operatoregenskaber for den XML-tabelvurderede funktion
Operatoregenskaber for den XML-tabelvurderede funktion
"All CPU" er typisk okay, da de fleste systemer er I/O-bundet og/eller hukommelsesbundet, ikke CPU-bundet. Som jeg siger ret ofte, vil jeg i de fleste systemer bytte noget af min CPU-hovedplads til hukommelse eller disk enhver dag i ugen (en af grundene til, at jeg kan lide OPTION (RECOMPILE) som en løsning på gennemgående parametersniffing-problemer).
Når det er sagt, opfordrer jeg dig kraftigt til at teste disse tilgange mod lignende resultater, du kan få fra GROUP_CONCAT CLR-tilgangen på CodePlex, samt at udføre aggregeringen og sorteringen på præsentationsniveauet (især hvis du holder de normaliserede data på en eller anden måde) af cachelag).