Tidligere i denne serie (Del 1 | Del 2) talte vi om at generere en række tal ved hjælp af forskellige teknikker. Selvom det er interessant og nyttigt i nogle scenarier, er en mere praktisk anvendelse at generere en række sammenhængende datoer; for eksempel en rapport, der kræver, at alle dage i en måned vises, selvom nogle dage ikke havde nogen transaktioner.
I et tidligere indlæg nævnte jeg, at det er nemt at udlede en række dage fra en række tal. Da vi allerede har etableret flere måder at udlede en række tal på, lad os se på, hvordan det næste trin ser ud. Lad os starte meget enkelt og lade som om, vi vil køre en rapport i tre dage, fra 1. januar til 3. januar, og inkludere en række for hver dag. Den gammeldags måde ville være at oprette en #temp-tabel, oprette en løkke, have en variabel, der holder den aktuelle dag, inden i løkken indsætte en række i #temp-tabellen indtil slutningen af området, og derefter bruge # temp tabel til ydre joinforbindelse til vores kildedata. Det er mere kode, end jeg selv ønsker at præsentere her, ligegyldigt at sætte i produktion, vedligeholde og få kolleger til at lære af.
Simpelt at starte
Med en etableret talrække (uanset hvilken metode du vælger), bliver denne opgave meget lettere. Til dette eksempel kan jeg erstatte komplekse sekvensgeneratorer med en meget simpel forening, da jeg kun har brug for tre dage. Jeg har tænkt mig at få dette sæt til at indeholde fire rækker, så det også er nemt at demonstrere, hvordan man klipper af til lige præcis den serie, man har brug for.
For det første har vi et par variable til at holde starten og slutningen af det interval, vi er interesseret i:
DECLARE @s DATE = '2012-01-01', @e DATE = '2012-01-03';
Nu, hvis vi starter med bare den simple seriegenerator, kan det se sådan ud. Jeg vil tilføje en ORDER BY også her, for en sikkerheds skyld, da vi aldrig kan stole på antagelser, vi gør os om orden.
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT n FROM n ORDER BY n; -- result: n ---- 1 2 3 4
For at konvertere det til en række datoer, kan vi blot anvende DATEADD() fra startdatoen:
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n, @s) FROM n ORDER BY n; -- result: ---- 2012-01-02 2012-01-03 2012-01-04 2012-01-05
Dette er stadig ikke helt rigtigt, da vores sortiment starter den 2. i stedet for den 1. Så for at bruge vores startdato som basis, skal vi konvertere vores sæt fra 1-baseret til 0-baseret. Det kan vi gøre ved at trække 1:
fra;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03 2012-01-04
Er der næsten! Vi skal bare begrænse resultatet fra vores større seriekilde, hvilket vi kan gøre ved at tilføre DATEDIFF , i dage, mellem begyndelsen og slutningen af området, til en TOP operator – og derefter tilføje 1 (siden DATEDIFF rapporterer i det væsentlige et åbent område).
;WITH n(n) AS (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4) SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n; -- result: ---- 2012-01-01 2012-01-02 2012-01-03
Tilføjelse af rigtige data
For nu at se, hvordan vi ville slutte os til en anden tabel for at udlede en rapport, kan vi bare bruge vores nye forespørgsel og ydre joinforbindelse mod kildedataene.
;WITH n(n) AS ( SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ), d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM n ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(o.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeader AS o ON o.OrderDate >= d.OrderDate AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate) GROUP BY d.OrderDate ORDER BY d.OrderDate;
(Bemærk, at vi ikke længere kan sige COUNT(*) , da dette vil tælle venstre side, som altid vil være 1.)
En anden måde at skrive dette på ville være:
;WITH d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s)
FROM
(
SELECT 1 UNION ALL SELECT 2 UNION ALL
SELECT 3 UNION ALL SELECT 4
) AS n(n) ORDER BY n
)
SELECT
d.OrderDate,
OrderCount = COUNT(o.SalesOrderID)
FROM d
LEFT OUTER JOIN Sales.SalesOrderHeader AS o
ON o.OrderDate >= d.OrderDate
AND o.OrderDate < DATEADD(DAY, 1, d.OrderDate)
GROUP BY d.OrderDate
ORDER BY d.OrderDate;
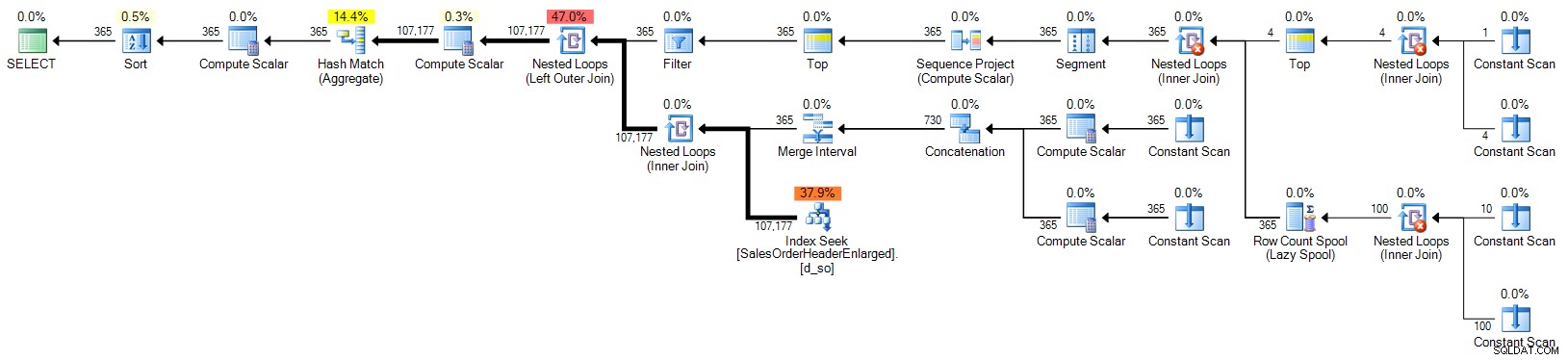
Dette skulle gøre det lettere at forestille sig, hvordan du ville erstatte den førende CTE med generering af en datosekvens fra enhver kilde, du vælger. Vi gennemgår dem (med undtagelse af den rekursive CTE-tilgang, som kun tjente til at skæve grafer) ved hjælp af AdventureWorks2012, men vi bruger SalesOrderHeaderEnlarged tabel, jeg lavede ud fra dette script af Jonathan Kehayias. Jeg tilføjede et indeks for at hjælpe med denne specifikke forespørgsel:
CREATE INDEX d_so ON Sales.SalesOrderHeaderEnlarged(OrderDate);
Bemærk også, at jeg vælger et vilkårligt datointerval, som jeg ved findes i tabellen.
Taltabellen
;WITH d(OrderDate) AS ( SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) DATEADD(DAY, n-1, @s) FROM dbo.Numbers ORDER BY n ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik for at forstørre):
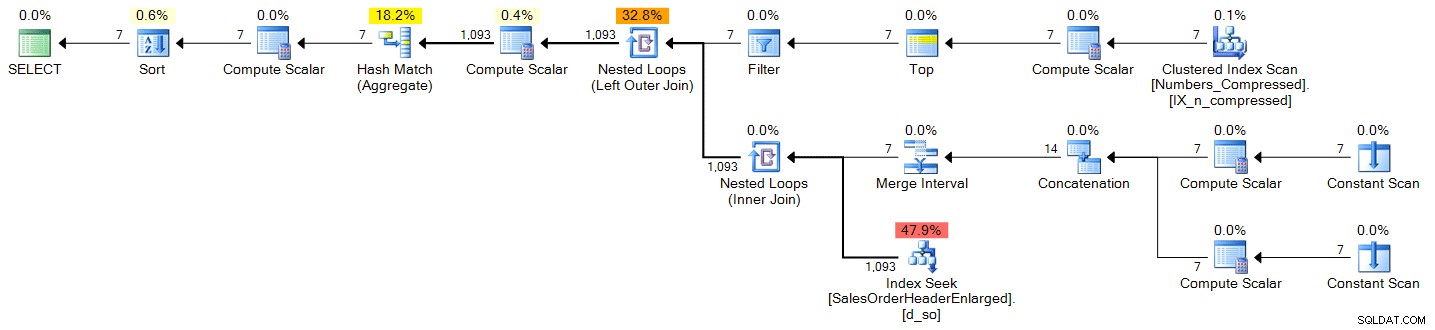
spt_values
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY Number) FROM master..spt_values) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik for at forstørre):
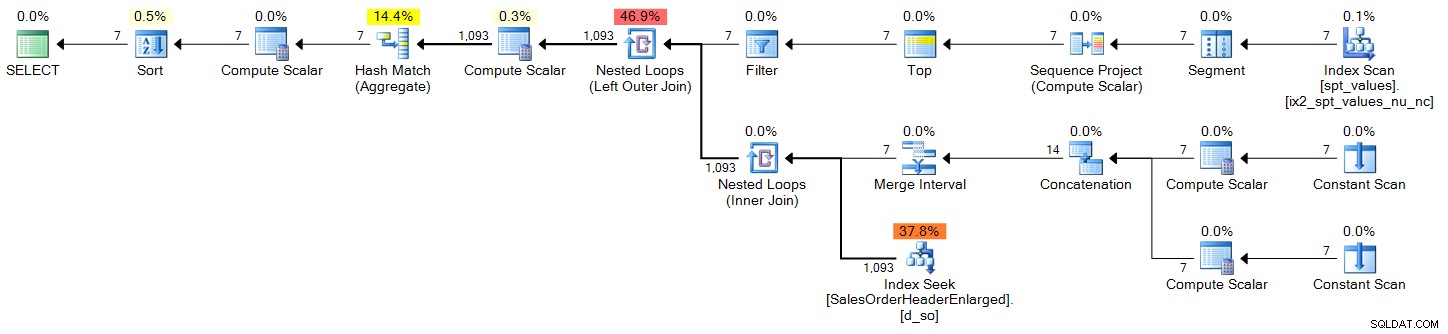
sys.all_objects
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; ;WITH d(OrderDate) AS ( SELECT DATEADD(DAY, n-1, @s) FROM (SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects) AS x(n) ) SELECT d.OrderDate, OrderCount = COUNT(s.SalesOrderID) FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND CONVERT(DATE, s.OrderDate) = d.OrderDate WHERE d.OrderDate >= @s AND d.OrderDate <= @e GROUP BY d.OrderDate ORDER BY d.OrderDate;
Plan (klik for at forstørre):
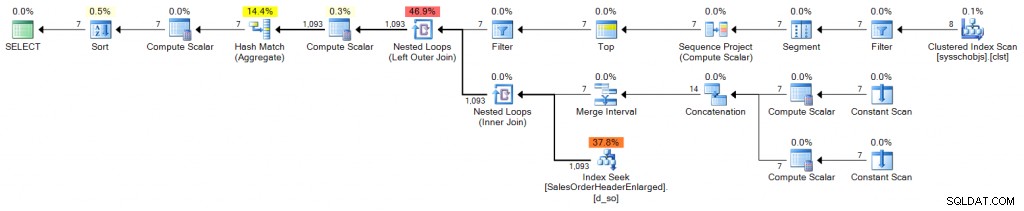
Stablede CTE'er
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY n)-1, @s)
FROM e2
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plan (klik for at forstørre):
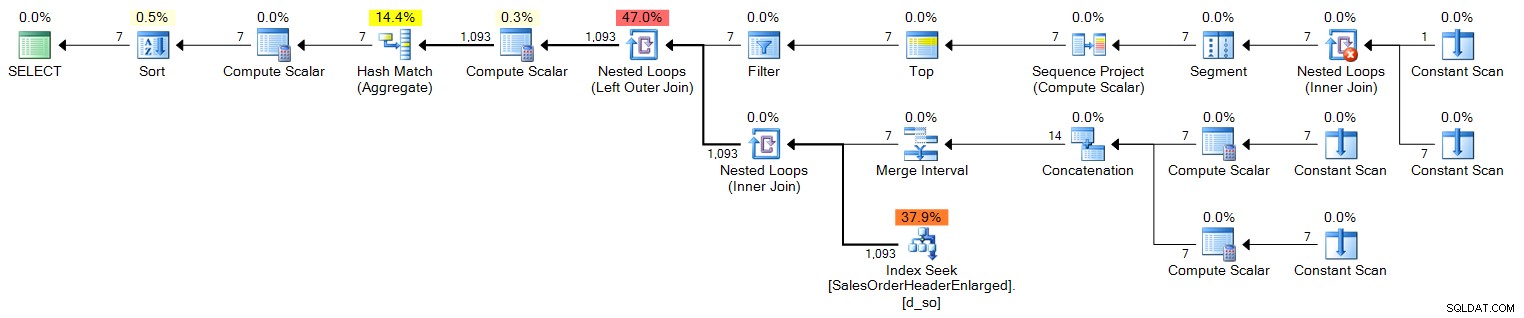
Nu, for et år lang rækkevidde, vil dette ikke skære det, da det kun producerer 100 rækker. I et år skulle vi dække 366 rækker (for at tage højde for potentielle skudår), så det ville se sådan ud:
DECLARE @s DATE = '2006-10-23', @e DATE = '2007-10-22';
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b),
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN (SELECT TOP (37) n FROM e2) AS b),
d(OrderDate) AS
(
SELECT TOP (DATEDIFF(DAY, @s, @e) + 1)
d = DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY N)-1, @s)
FROM e3
)
SELECT
d.OrderDate,
OrderCount = COUNT(s.SalesOrderID)
FROM d LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s
ON s.OrderDate >= @s AND s.OrderDate <= @e
AND d.OrderDate = CONVERT(DATE, s.OrderDate)
WHERE d.OrderDate >= @s AND d.OrderDate <= @e
GROUP BY d.OrderDate
ORDER BY d.OrderDate; Plan (klik for at forstørre):
Kalendertabel
Dette er en ny, som vi ikke talte meget om i de to foregående indlæg. Hvis du bruger datoserier til mange forespørgsler, bør du overveje at have både en taltabel og en kalendertabel. Det samme argument gælder om, hvor meget plads der virkelig kræves, og hvor hurtig adgang vil være, når bordet ofte bliver forespurgt. For for eksempel at gemme 30 års datoer kræver det mindre end 11.000 rækker (det nøjagtige antal afhænger af, hvor mange skudår du spænder over), og fylder kun 200 KB. Ja, du læste rigtigt:200 kilobyte . (Og komprimeret er den kun 136 KB.)
For at generere en kalendertabel med 30 års data, forudsat at du allerede er blevet overbevist om, at det er en god ting at have en taltabel, kan vi gøre dette:
DECLARE @s DATE = '2005-07-01'; -- earliest year in SalesOrderHeader DECLARE @e DATE = DATEADD(DAY, -1, DATEADD(YEAR, 30, @s)); SELECT TOP (DATEDIFF(DAY, @s, @e) + 1) d = CONVERT(DATE, DATEADD(DAY, n-1, @s)) INTO dbo.Calendar FROM dbo.Numbers ORDER BY n; CREATE UNIQUE CLUSTERED INDEX d ON dbo.Calendar(d);
For nu at bruge denne kalendertabel i vores salgsrapportforespørgsel, kan vi skrive en meget enklere forespørgsel:
DECLARE @s DATE = '2006-10-23', @e DATE = '2006-10-29'; SELECT OrderDate = c.d, OrderCount = COUNT(s.SalesOrderID) FROM dbo.Calendar AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS s ON s.OrderDate >= @s AND s.OrderDate <= @e AND c.d = CONVERT(DATE, s.OrderDate) WHERE c.d >= @s AND c.d <= @e GROUP BY c.d ORDER BY c.d;
Plan (klik for at forstørre):

Ydeevne
Jeg lavede både komprimerede og ukomprimerede kopier af tal- og kalendertabellerne og testede en uges interval, en måneds interval og et års interval. Jeg kørte også forespørgsler med kold cache og varm cache, men det viste sig at være stort set ligegyldigt.
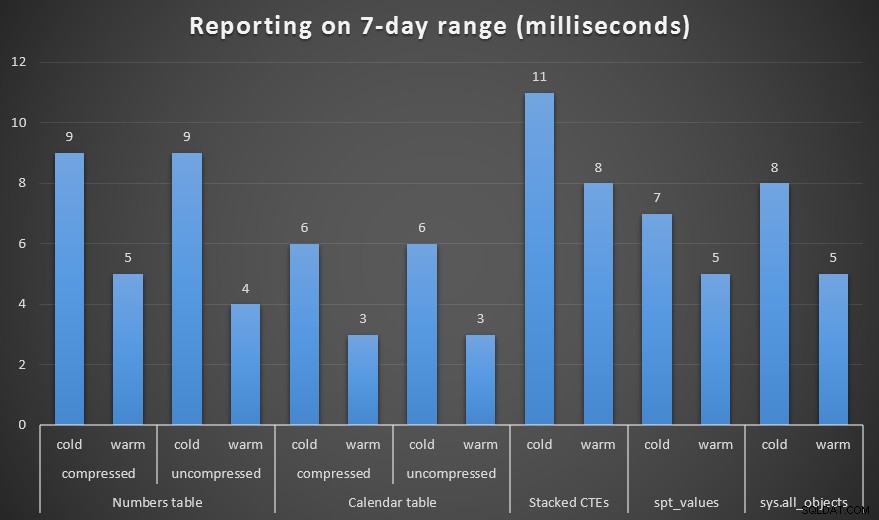
Varighed, i millisekunder, for at generere et ugelangt interval
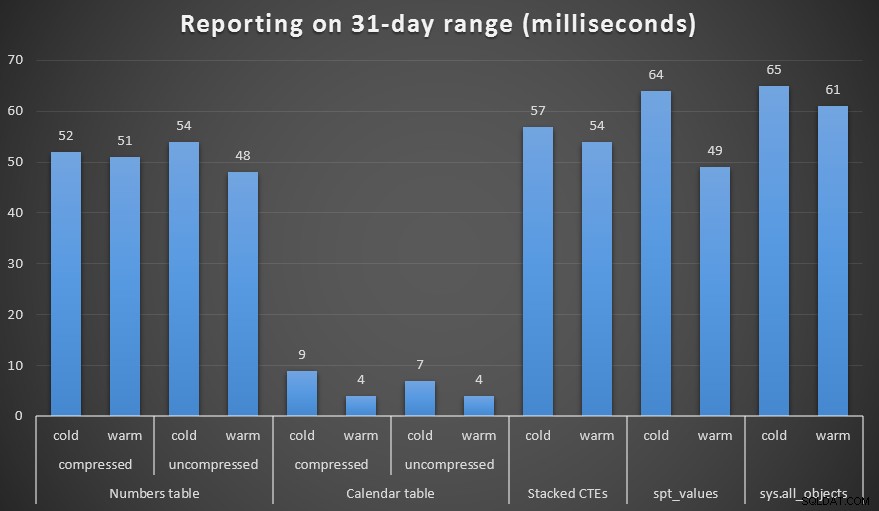
Varighed, i millisekunder, for at generere et måned langt interval
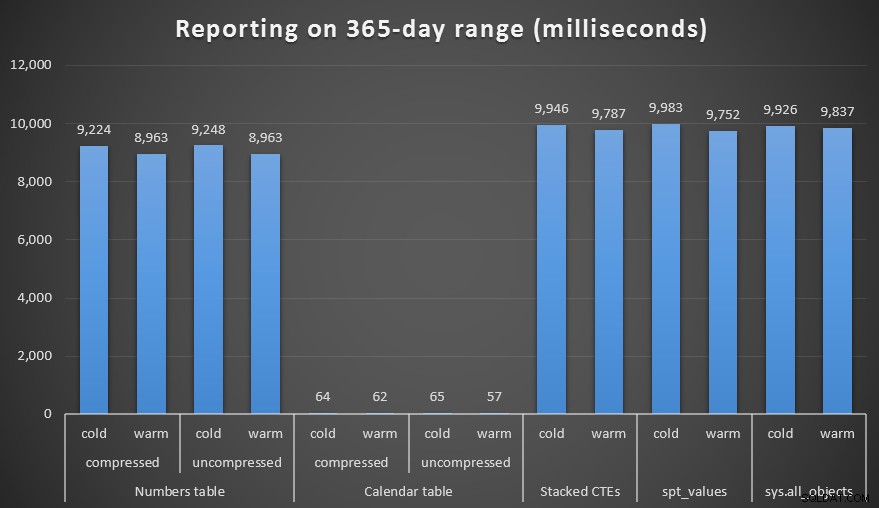
Varighed, i millisekunder, for at generere et år langt interval
Tillæg
Paul White (blog | @SQL_Kiwi) påpegede, at du kan tvinge Numbers-tabellen til at lave en meget mere effektiv plan ved at bruge følgende forespørgsel:
SELECT OrderDate = DATEADD(DAY, n, 0), OrderCount = COUNT(s.SalesOrderID) FROM dbo.Numbers AS n LEFT OUTER JOIN Sales.SalesOrderHeader AS s ON s.OrderDate >= CONVERT(DATETIME, @s) AND s.OrderDate < DATEADD(DAY, 1, CONVERT(DATETIME, @e)) AND DATEDIFF(DAY, 0, OrderDate) = n WHERE n.n >= DATEDIFF(DAY, 0, @s) AND n.n <= DATEDIFF(DAY, 0, @e) GROUP BY n ORDER BY n;
På dette tidspunkt vil jeg ikke køre alle præstationstestene igen (øvelse for læseren!), men jeg vil antage, at det vil generere bedre eller lignende timings. Alligevel tror jeg, at en kalendertabel er en nyttig ting at have, selvom det ikke er strengt nødvendigt.
Konklusion
Resultaterne taler for sig selv. For at generere en række tal vinder taltabellen tilgangen, men kun marginalt - selv ved 1.000.000 rækker. Og for en række datoer, i den nederste ende, vil du ikke se den store forskel mellem de forskellige teknikker. Det er dog helt klart, at efterhånden som dit datointerval bliver større, især når du har at gøre med en stor kildetabel, viser kalendertabellen virkelig sit værd – især i betragtning af dens lave hukommelsesfodaftryk. Selv med Canadas skøre metriske system, er 60 millisekunder langt bedre end omkring 10 *sekunder*, når det kun medførte 200 KB på disken.
Jeg håber du har nydt denne lille serie; det er et emne, jeg har tænkt mig at gense i evigheder.
[ Del 1 | Del 2 | Del 3 ]