Du arbejder med en udvikler, der rapporterer langsom ydeevne for følgende lagrede procedurekald:
EXEC [dbo].[charge_by_date] '2/28/2013';
Du spørger, hvilket problem udvikleren ser, men den eneste yderligere information, du hører tilbage, er, at den "kører langsomt." Så du hopper på SQL Server-instansen og tager et kig på den faktiske udførelsesplan. Du gør dette, fordi du ikke kun er interesseret i, hvordan udførelsesplanen ser ud, men også hvad det estimerede kontra faktiske antal rækker er for planen:
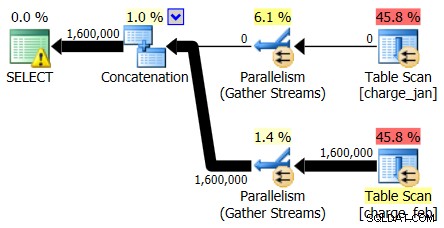
Hvis du først ser på planoperatørerne, kan du se et par bemærkelsesværdige detaljer:
- Der er en advarsel i root-operatoren
- Der er en tabelscanning for begge tabeller, der refereres til på bladniveau (charge_jan og charge_feb), og du undrer dig over, hvorfor disse begge stadig er dynger og ikke har klyngede indekser
- Du kan se, at der kun er rækker, der flyder gennem charge_feb-tabellen og ikke charge_jan-tabellen
- Du ser parallelle zoner i planen
Med hensyn til advarslen i rod-iteratoren, svæver du over den og ser, at der mangler indeksadvarsler med en anbefaling til følgende indekser:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Du spørger den oprindelige databaseudvikler, hvorfor der ikke er et klynget indeks, og svaret er "Jeg ved det ikke."
Hvis du fortsætter undersøgelsen, før du foretager nogen ændringer, ser du på fanen Plan Tree i SQL Sentry Plan Explorer, og du ser faktisk, at der er betydelige skævheder mellem de estimerede kontra faktiske rækker for en af tabellerne:

Der lader til at være to problemer:
- Et underestimat for rækker i charge_jan-tabelscanningen
- Et overestimat for rækker i charge_feb-tabelscanningen
Så kardinalitetsestimaterne er skævt, og du spekulerer på, om dette er relateret til parametersniffing. Du beslutter dig for at kontrollere parameterens kompilerede værdi og sammenligne den med parameterens runtime-værdi, som du kan se på fanen Parameters:

Der er faktisk forskelle mellem runtime-værdien og den kompilerede værdi. Du kopierer databasen over til et prod-lignende testmiljø og tester derefter udførelsen af den lagrede procedure med runtime-værdien 28.2.2013 først og derefter 31.1.2013 bagefter.
Planerne 28.2.2013 og 31.1.2013 har identiske former, men forskellige faktiske datastrømme. Planen 28/2/2013 og kardinalitetsestimaterne var som følger:
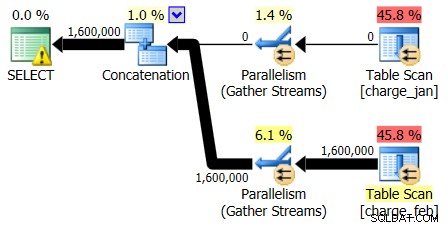

Og selvom planen 28/2/2013 ikke viser noget problem med kardinalitetsestimat, gør planen 1/31/2013:
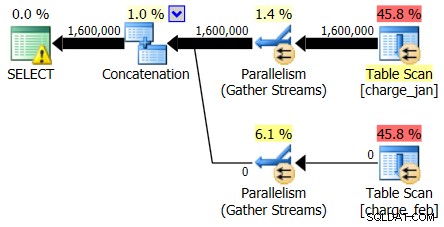

Så den anden plan viser de samme over- og undervurderinger, bare vendt fra den oprindelige plan, du så på.
Du beslutter dig for at tilføje de foreslåede indekser til det prod-lignende testmiljø for både charge_jan og charge_feb tabellerne og se, om det overhovedet hjælper. Når du udfører de lagrede procedurer i januar/februar-rækkefølgen, ser du følgende nye planformer og tilhørende kardinalitetsestimater:
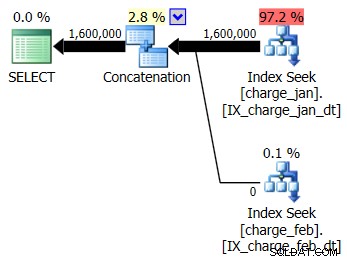

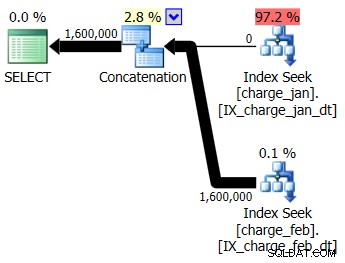

Den nye plan bruger en indekssøgningsoperation fra hver tabel, men du ser stadig nul rækker, der flyder fra den ene tabel og ikke den anden, og du ser stadig skævheder for kardinalitetsestimater baseret på parametersniffing, når runtime-værdien er i en anden måned end kompileringen tidsværdi.
Dit team har en politik om ikke at tilføje indekser uden bevis for tilstrækkelig fordel og tilhørende regressionstest. Du beslutter, indtil videre, at fjerne de ikke-klyngede indekser, du lige har oprettet. Selvom du ikke straks tager fat på de manglende grupperede indeks, beslutter du dig for at tage dig af det senere.
På dette tidspunkt indser du, at du skal se nærmere på definitionen af den lagrede procedure, som er som følger:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Dernæst ser du på charge_view objektdefinitionen:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Visningen refererer til gebyrdata, der er opdelt i forskellige tabeller efter dato. Og så spekulerer du på, om den anden skævhed for udførelse af forespørgsler kan forhindres ved at ændre definitionen af den lagrede procedure.
Hvis optimeringsværktøjet ved kørselstidspunktet, hvad værdien er, vil problemet med kardinalitetsestimat måske forsvinde og forbedre den samlede ydeevne?
Du går videre og redefinerer det lagrede procedurekald som følger, og tilføjer et RECOMPILE-tip (vel vidende at du også har hørt, at dette kan øge CPU-forbruget, men da dette er et testmiljø, føler du dig sikker på at prøve det):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Du udfører derefter den lagrede procedure igen med værdien 1/31/2013 og derefter 28/2/2013 værdien.
Planformen forbliver den samme, men nu er problemet med kardinalitetsestimat fjernet.
Kardinalitetsestimatdataene 1/31/2013 viser:

Og dataene for 28/2/2013 kardinalitetsestimat viser:

Det gør dig glad et øjeblik, men så indser du, at varigheden af den overordnede forespørgselsudførelse virker relativt den samme, som den var før. Du begynder at tvivle på, at udvikleren vil være tilfreds med dine resultater. Du har løst skævheden i kardinalitetsestimatet, men uden det forventede præstationsboost er du usikker på, om du har hjulpet på nogen meningsfuld måde.
Det er på dette tidspunkt, du indser, at planen for udførelse af forespørgsler kun er en delmængde af de oplysninger, du muligvis har brug for, og så udvider du din udforskning yderligere ved at se på fanen Tabel I/O. Du ser følgende output for 31/1/2013-udførelsen:

Og for udførelsen 28/2/2013 ser du lignende data:

Det er på det tidspunkt, du spekulerer på, om dataadgang fungerer for begge tabeller er nødvendige i hver plan. Hvis optimeringsværktøjet ved, at du kun har brug for januarrækker, hvorfor så overhovedet få adgang til februar og omvendt? Du husker også, at forespørgselsoptimeringsværktøjet ikke har nogen garantier for, at der ikke er faktiske rækker fra de andre måneder i den "forkerte" tabel, medmindre sådanne garantier blev givet eksplicit via begrænsninger på selve tabellen.
Du tjekker tabeldefinitionerne via sp_help for hver tabel, og du kan ikke se nogen begrænsninger defineret for nogen af tabellerne.
Så som en test tilføjer du følgende to begrænsninger:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Du genudfører de lagrede procedurer og ser følgende planformer og kardinalitetsestimater.
31/1/2013 udførelse:
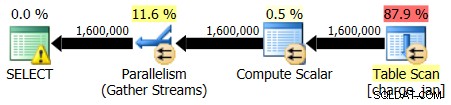

28-02-2013 udførelse:


Ser du på tabel I/O igen, ser du følgende output for 1/31/2013 eksekveringen:

Og for udførelsen 28/2/2013 ser du lignende data, men for charge_feb-tabellen:

Når du husker, at du stadig har RECOMPILE i definitionen af den lagrede procedure, prøver du at fjerne den og se, om du ser den samme effekt. Når du har gjort dette, ser du adgangen med to tabeller tilbage, men uden egentlige logiske læsninger for tabellen, der ikke har nogen rækker i sig (sammenlignet med den oprindelige plan uden begrænsningerne). For eksempel viste udførelse af 1/31/2013 følgende tabel I/O output:

Du beslutter dig for at gå videre med belastningstestning af de nye CHECK-begrænsninger og RECOMPILE-løsning, og fjerner tabeladgangen helt fra planen (og de tilknyttede planoperatører). Du forbereder dig også på en debat om den klyngede indeksnøgle og et passende understøttende ikke-klynget indeks, der vil rumme et bredere sæt af arbejdsbelastninger, der i øjeblikket har adgang til de tilknyttede tabeller.