SQL Server giver os forskellige løsninger til at replikere eller arkivere en databasetabel eller tabeller til en anden database eller den samme database med forskellige navne. Som SQL Server-udvikler eller databaseadministrator kan du komme i situationer, hvor du skal kontrollere, at dataene i disse to tabeller er identiske, og hvis dataene ved en fejltagelse ikke replikeres mellem disse to tabeller, skal du synkronisere dataene. mellem bordene. Derudover, hvis du modtager en fejlmeddelelse, der bryder datasynkroniseringen eller replikeringsprocessen på grund af skemaforskelle mellem kilde- og destinationstabellerne, skal du finde en nem og hurtig måde at identificere skemaforskellene på, ÆNDRE tabellerne for at lave skemaet er identisk på begge sider og genoptag datasynkroniseringsprocessen.
I andre situationer har du brug for en nem måde at få svaret JA eller NEJ, hvis data og skema for to tabeller er identiske eller ej. I denne artikel vil vi gennemgå de forskellige måder at sammenligne data og skema mellem to tabeller på. De angivne metoder i denne artikel vil sammenligne tabeller, der er hostet i forskellige databaser, hvilket er det mere komplicerede scenarie, og kan også nemt bruges til at sammenligne tabeller, der er placeret i den samme database med forskellige navne.
Før vi beskriver de forskellige metoder og værktøjer, der kan bruges til at sammenligne tabellernes data og skemaer, vil vi forberede vores demomiljø ved at oprette to nye databaser og oprette en tabel i hver database, med en lille datatypeforskel mellem disse to tabeller, som vist i CREATE DATABASE og CREATE TABLE T-SQL-sætningerne nedenfor:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Efter at have oprettet databaserne og tabellerne, udfylder vi de to tabeller med fem identiske rækker, og indsætter derefter endnu en ny post kun i den første tabel, som vist i INSERT INTO T-SQL-sætningerne nedenfor:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Nu er testmiljøet klar til at begynde at beskrive metoderne til sammenligning af data og skemaer.
Sammenlign tabeldata ved hjælp af en LEFT JOIN
LEFT JOIN T-SQL nøgleordet bruges til at hente data fra to tabeller, ved at returnere alle poster fra venstre tabel og kun de matchede poster fra højre tabel og NULL værdier fra højre tabel, når der ikke er match mellem de to tabeller.
Til datasammenligningsformål kan LEFT JOIN søgeordet bruges til at sammenligne to tabeller baseret på den fælles unikke kolonne, såsom ID-kolonnen i vores tilfælde, som i SELECT-sætningen nedenfor:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
Den forrige forespørgsel vil returnere de fælles fem rækker, der findes i de to tabeller, ud over den række, der findes i den første tabel og mangler fra den anden, ved at vise NULL-værdier i højre side af resultatet, som vist nedenfor:
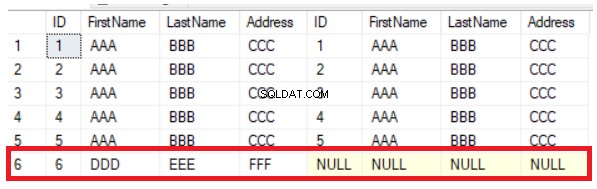
Du kan nemt udlede af det forrige resultat, at den sjette kolonne, der findes i den første tabel, savnes fra den anden tabel. For at synkronisere rækkerne mellem tabellerne skal du indsætte den nye post i den anden tabel manuelt. LEFT JOIN-metoden er nyttig til at verificere de nye rækker, men hjælper ikke i tilfælde af opdatering af kolonneværdierne. Hvis du ændrer værdien for adressekolonnen i den 5. række, vil LEFT JOIN-metoden ikke registrere denne ændring som vist tydeligt nedenfor:
Sammenlign tabeller data ved hjælp af UNDTAGELSE Klausul
EXCEPT-sætningen returnerer rækkerne fra den første forespørgsel (venstre forespørgsel), som ikke returneres fra den anden forespørgsel (højre forespørgsel). Med andre ord vil EXCEPT-sætningen returnere forskellen mellem to SELECT-sætninger eller tabeller, hvilket hjælper os med nemt at sammenligne dataene i disse tabeller.
EXCEPT-sætningen kan bruges til at sammenligne dataene i de tidligere oprettede tabeller, ved at tage forskellen mellem SELECT *-forespørgslen fra den første tabel og SELECT *-forespørgslen fra den anden tabel ved at bruge T-SQL-sætningerne nedenfor:
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Resultatet af den forrige forespørgsel vil være den række, der er tilgængelig i den første tabel og ikke tilgængelig i den anden, som vist nedenfor:
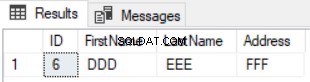
Brug af EXCEPT-sætningen til at sammenligne to tabeller er bedre end LEFT JOIN-sætning, idet de opdaterede poster vil blive fanget i dataforskelleresultatet. Antag, at vi opdaterede adressen på række nummer 5 i den anden tabel, og kontrollerede forskellen ved at bruge EXCEPT-sætningen igen, vil du se, at række nummer 5 vil blive returneret med forskelsresultatet som vist nedenfor:
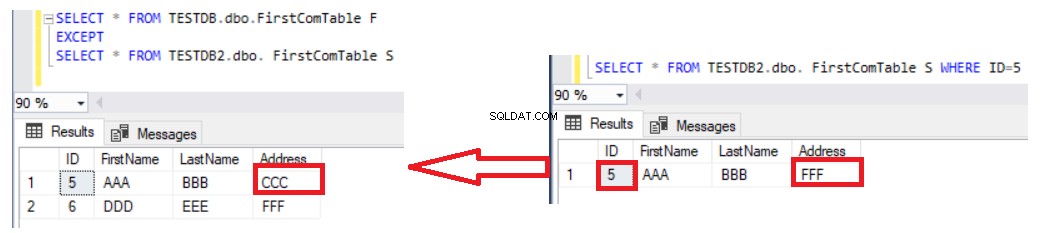
Den eneste ulempe ved at bruge EXCEPT-sætningen til at sammenligne dataene i to tabeller er, at du skal synkronisere dataene manuelt ved at skrive en INSERT-sætning for de manglende poster i den anden tabel. Tag i betragtning, at de to tabeller, der sammenlignes, er nøgletabeller for at få det korrekte resultat, med en unik nøgle, der bruges til sammenligning. Hvis vi fjerner den unikke ID-kolonne fra SELECT-sætningen i begge EXCEPT-sætningssider og viser resten af ikke-nøglekolonner, som i sætningen nedenfor:
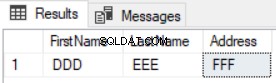
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
Resultatet vil vise, at kun de nye poster returneres, og de opdaterede vil ikke blive vist, som vist i resultatet nedenfor:
Sammenlign tabeldata ved hjælp af en UNION ALL … GROUP BY
UNION ALL-sætningen kan også bruges til at sammenligne dataene i to tabeller baseret på en unik nøglekolonne. For at bruge UNION ALL-sætningen til at returnere forskellen mellem to tabeller, skal du angive de kolonner, der skal sammenlignes, i SELECT-sætningen og bruge disse kolonner i GROUP BY-sætningen, som vist i T-SQL-forespørgslen nedenfor:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
GROUP BY ID,FirstName, LastName, Address
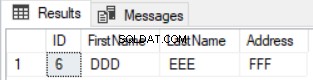
HAVING COUNT(*)<2) Diff Og kun den række, der findes i den første tabel og savnet fra den anden tabel, vil blive returneret som vist nedenfor:
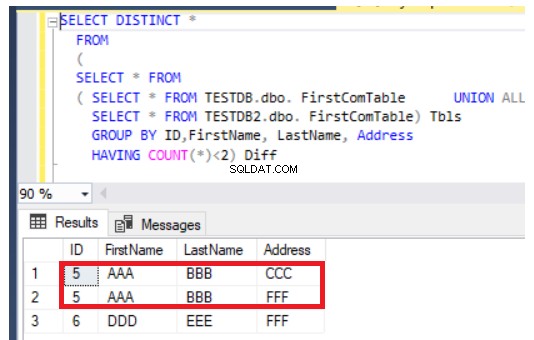
Den tidligere forespørgsel vil også fungere fint i tilfælde af opdatering af poster, men på en anden måde. Det vil returnere de nyligt indsatte poster ud over de opdaterede kolonner fra begge tabeller, som i tilfældet med række nummer 5, vist nedenfor:
Sammenlign tabeldata ved hjælp af SQL Server-dataværktøjer
SQL Server Data Tools, også kendt som SSDT, bygget over Microsoft Visual Studio kan nemt bruges til at sammenligne data i to tabeller med samme navn, baseret på en unik nøglekolonne, hostet i to forskellige databaser og synkronisere dataene i disse tabeller , eller generer et synkroniseringsscript, der skal bruges senere.
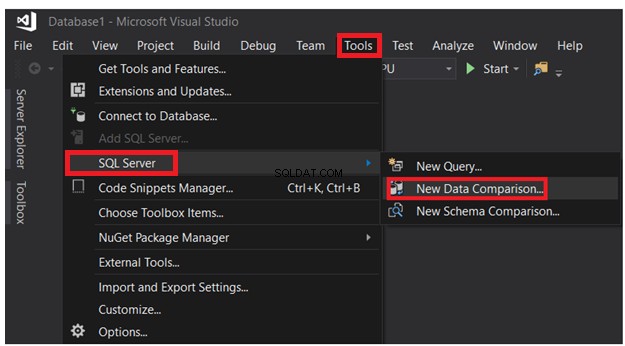
Fra det åbnede SSDT-vindue skal du klikke på menuen Værktøjer -> SQL Server-liste og vælgeNy datasammenligning mulighed, som vist nedenfor:
I det viste forbindelsesvindue kan du vælge mellem de tidligere tilsluttede sessioner eller udfylde vinduet Forbindelsesegenskaber med SQL Server-navnet, legitimationsoplysninger og databasenavnet, og derefter klikke på Forbind , som vist nedenfor:

I den viste guide til Ny datasammenligning skal du angive kilde- og måldatabasenavnene og de sammenligningsmuligheder, der bruges i tabellsammenligningsprocessen, og derefter klikke på Næste , som vist nedenfor:
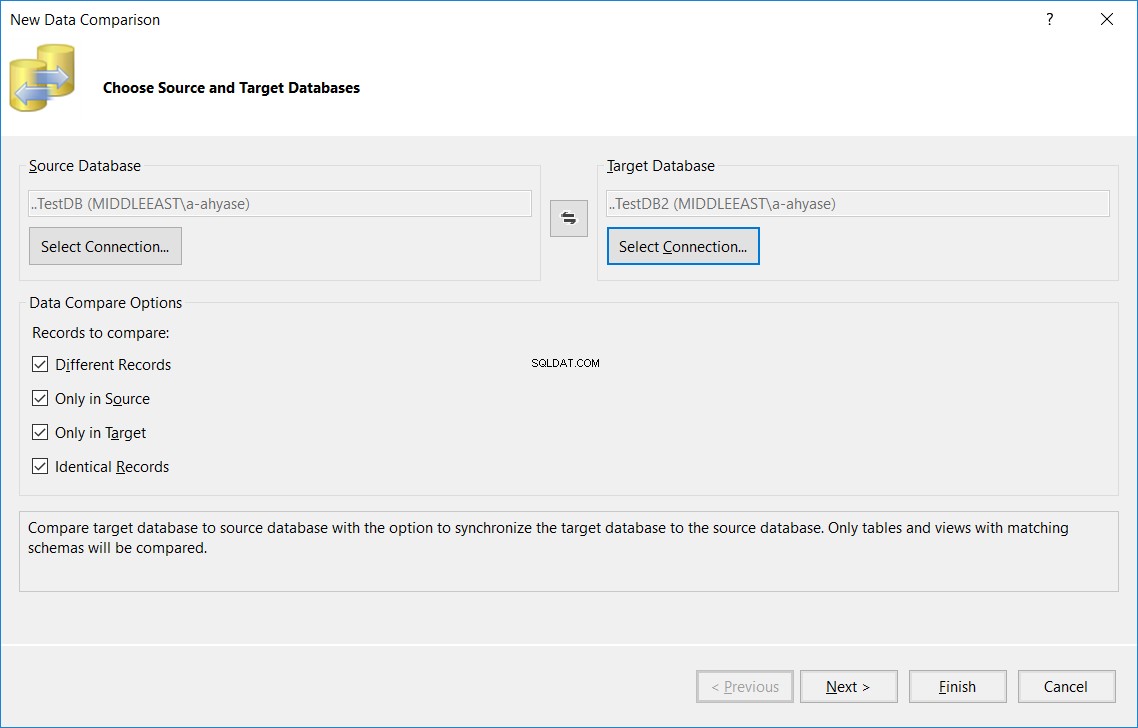
I det næste vindue skal du angive navnet på tabellen, som skal være det samme navn i kilde- og måldatabaserne, som vil blive sammenlignet i begge databaser, og klik påUdfør , som nedenfor:
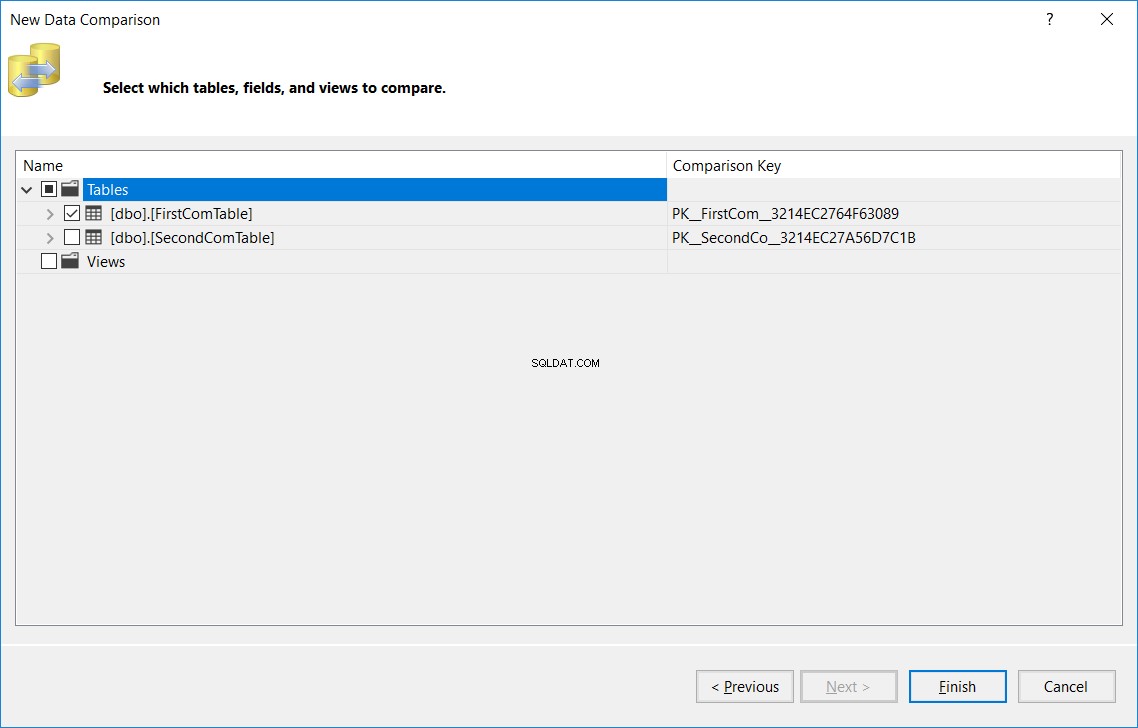
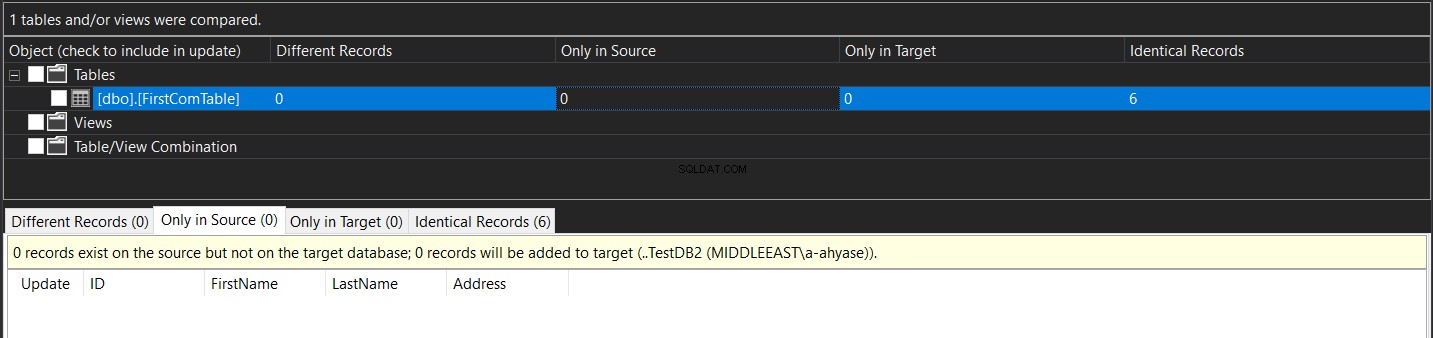
Det viste resultat vil vise dig antallet af poster, der er fundet i kilden og savnet fra målet, fundet i målet og savnet fra kilden, antallet af opdaterede poster med samme nøgle og forskellige kolonneværdier (forskellige poster) og endelig antallet af identiske poster fundet i begge tabeller, som vist nedenfor:
Klik på tabelnavnet i det forrige resultat, du vil finde en detaljeret visning af disse resultater, som vist nedenfor:

Du kan bruge det samme værktøj til at generere et script for at synkronisere kilde- og måltabellerne eller opdatere måltabellen direkte med de manglende eller forskellige ændringer, som nedenfor:
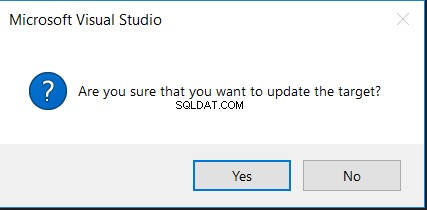
Hvis du klikker på muligheden Generer script, vil en INSERT-sætning med den manglende kolonne i måltabellen blive vist, som vist nedenfor:
BEGIN TRANSAKTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
Hvis du vælger indstillingen Update Target, bliver du først bedt om din bekræftelse for at udføre ændringen, som i meddelelsen nedenfor:
Efter synkroniseringen vil du se, at dataene i de to tabeller vil være identiske, som vist nedenfor:
Sammenlign tabeller data ved hjælp af "dbForge Studio for SQL Server" tredjepartsværktøj
I SQL Server-verdenen kan du finde et stort antal tredjepartsværktøjer, der gør livet nemt for databaseadministratorer og -udviklere. Et af disse værktøjer, der gør databaseadministrationsopgaverne til et stykke kage, er dbForge Studio til SQL Server, der giver os nemme måder at udføre databaseadministration og udviklingsopgaver på. Dette værktøj kan også hjælpe os med at sammenligne dataene i databasetabellerne og synkronisere disse tabeller.
I menuen Sammenligning skal du vælge Ny datasammenligning mulighed, som vist nedenfor:
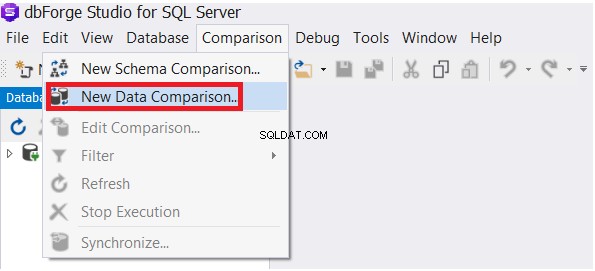
Angiv kilde- og måldatabasen i guiden Ny datasammenligning, og klik derefter på Næste :
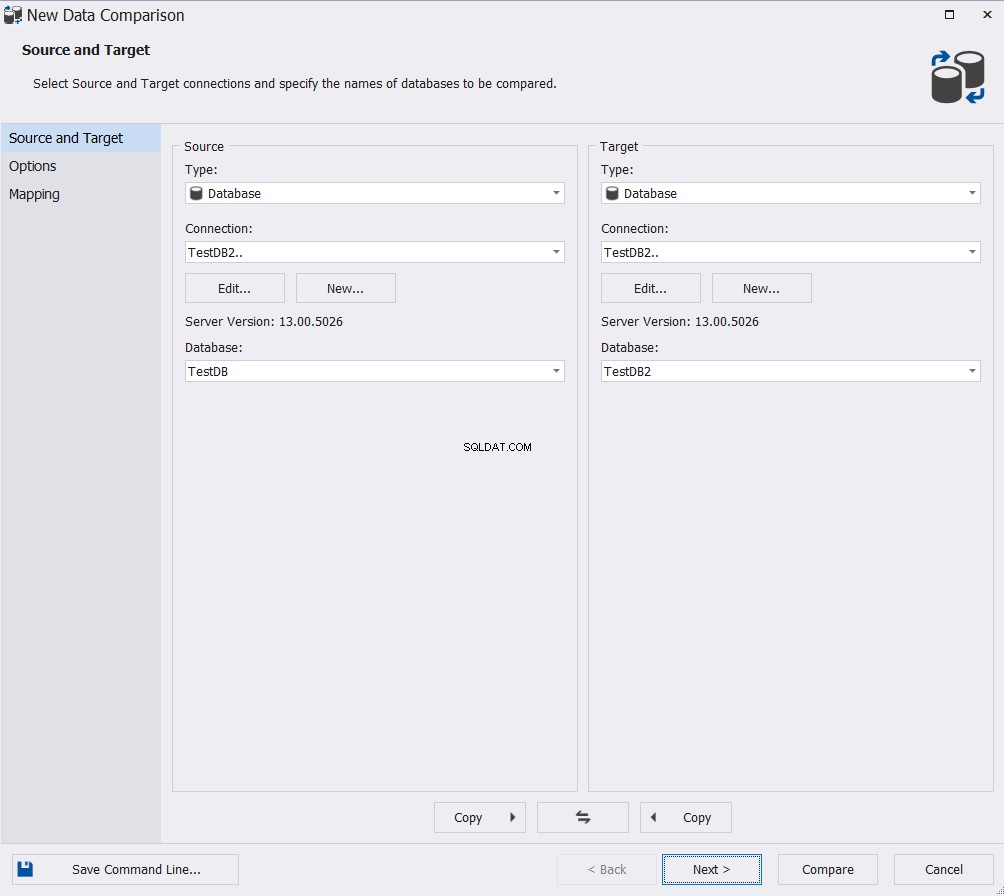
Vælg de passende muligheder fra det brede udvalg af tilgængelige kort- og sammenligningsmuligheder, og klik på Næste :
Angiv navnet på den eller de tabeller, der skal deltage i datasammenligningsprocessen. Guiden viser en advarselsmeddelelse, hvis der er skemaforskelle mellem kilde- og måldatabasetabellerne. Klik på Sammenlign for at fortsætte:
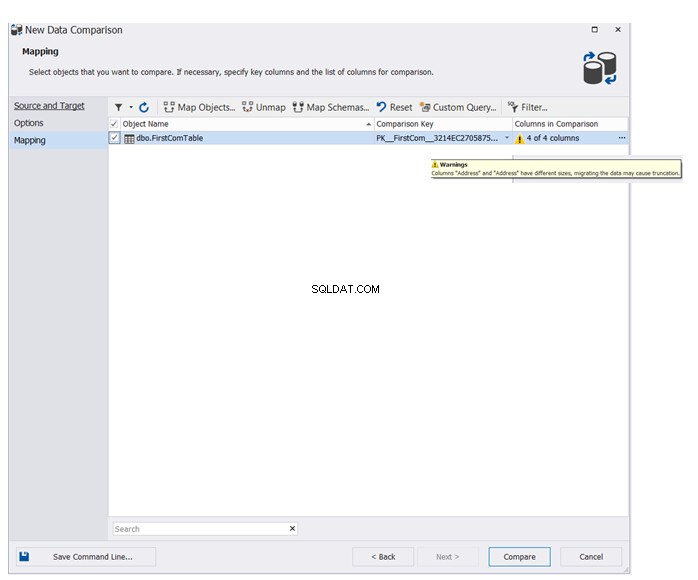
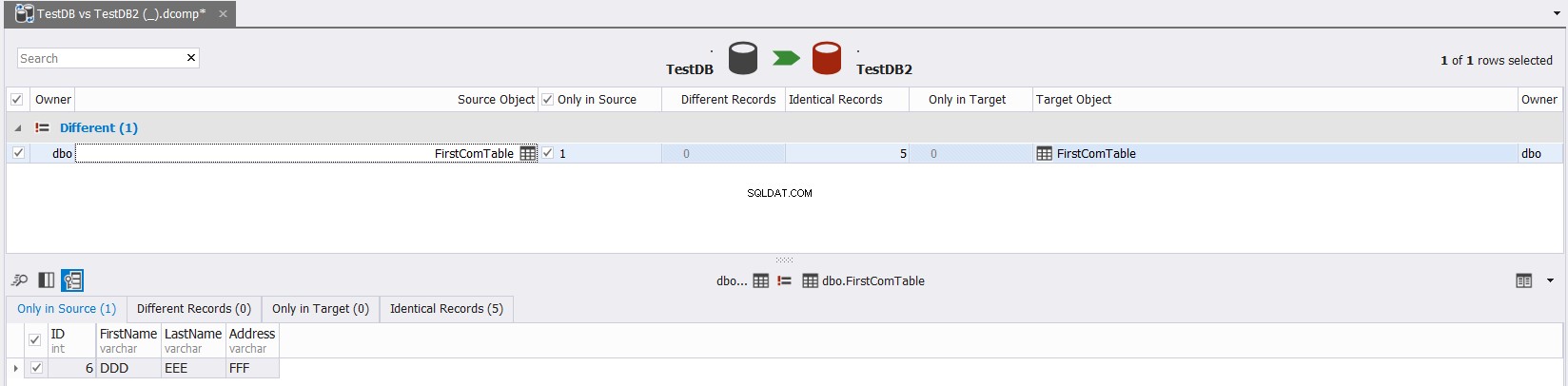
Det endelige resultat vil vise dig i detaljer dataforskellene mellem kilde- og måltabellerne med mulighed for at klikke  for at synkronisere kilde- og destinationstabellerne, som vist nedenfor:
for at synkronisere kilde- og destinationstabellerne, som vist nedenfor:
Sammenlign tabelskema ved hjælp af sys.columns
Som nævnt i begyndelsen af denne artikel skal du for at replikere eller arkivere en tabel sørge for, at skemaet for kilde- og måltabellerne er identisk. SQL Server giver os forskellige måder at sammenligne skemaet for tabellerne i den samme database eller forskellige databaser. Den første metode er at forespørge på systemkatalogvisningen sys.columns, der returnerer én række for hver kolonne i et objekt, der har en kolonne, med egenskaberne for hver kolonne.
For at sammenligne skemaet for tabeller, der er placeret i forskellige databaser, skal du give sys.columns tabelnavnet under den aktuelle database uden at være i stand til at levere en tabel, der er hostet i en anden database. For at opnå det, vil vi forespørge sys.columns to gange, gemme resultatet af hver forespørgsel i en midlertidig tabel og til sidst sammenligne resultatet af disse to forespørgsler ved hjælp af kommandoen EXCEPT T-SQL, som vist tydeligt nedenfor:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Resultatet vil vise os, at definitionen af adressekolonnen er forskellig i disse to tabeller uden specifik information om den nøjagtige forskel, som vist nedenfor:

Sammenlign tabelskema ved hjælp af INFORMATION_SCHEMA.COLUMNS
Systemvisningen INFORMATION_SCHEMA.COLUMNS kan også bruges til at sammenligne skemaet for forskellige tabeller ved at angive tabelnavnet. Igen, for at sammenligne to tabeller hostet i forskellige databaser, vil vi forespørge INFORMATION_SCHEMA.COLUMNS to gange, opbevare resultatet af hver forespørgsel i en midlertidig tabel og til sidst sammenligne resultatet af disse to forespørgsler ved hjælp af kommandoen EXCEPT T-SQL, som vist klart nedenfor:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Og resultatet vil på en eller anden måde ligne den forrige, hvilket viser, at adressekolonnens definition er forskellig i disse to tabeller, uden nogen specifik information om den nøjagtige forskel, som vist nedenfor:

Sammenlign tabelskema ved hjælp af dm_exec_describe_first_result_set
Tabellernes skemaer kan også sammenlignes ved at forespørge på den dynamiske administrationsfunktion dm_exec_describe_first_result_set, der tager en Transact-SQL-sætning som en parameter og beskriver metadataene for det første resultatsæt for sætningen.
For at sammenligne skemaet for to tabeller skal du forbinde dm_exec_describe_first_result_set DMF med sig selv, og give SELECT-sætningen fra hver tabel som en parameter, som i T-SQL-forespørgslen nedenfor:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Resultatet vil være tydeligere denne gang, da du kan sammenligne forskellen mellem de to tabeller, dvs. størrelsen og typen af adressekolonnen, som vist nedenfor:

Sammenlign tabelskema ved hjælp af SQL Server-dataværktøjer
SQL Server Data Tools kan også bruges til at sammenligne skemaet for tabeller placeret i forskellige databaser. Under menuen Værktøjer skal du vælge Ny skemasammenligning indstilling fra SQL Server-indstillingslisten, som vist nedenfor:
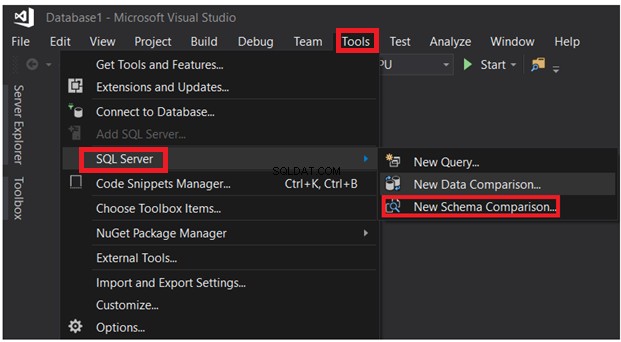
Når du har angivet forbindelsesparametrene, skal du klikke på knappen Sammenlign:

Sammenligningsresultatet viser dig specifikt skemaforskellen mellem de to tabeller i form af CREATE TABLE T-SQL-kommandoer, skraveret som i snapshotet nedenfor:
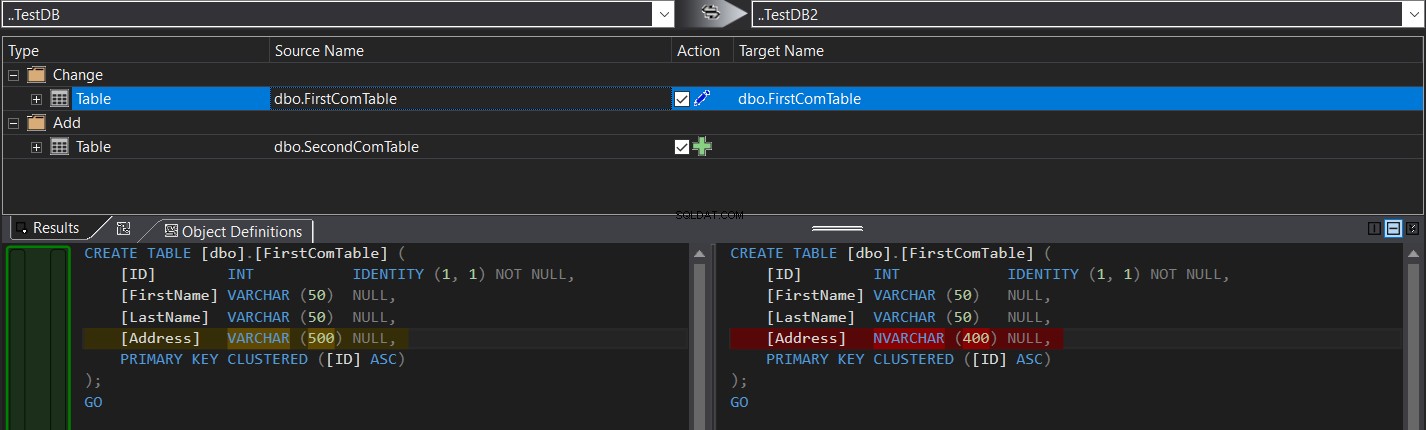
Du kan nemt klikke  for at synkronisere tabelskemaet eller klik
for at synkronisere tabelskemaet eller klik  for at scripte ændringen og udføre den senere, som vist nedenfor:
for at scripte ændringen og udføre den senere, som vist nedenfor:
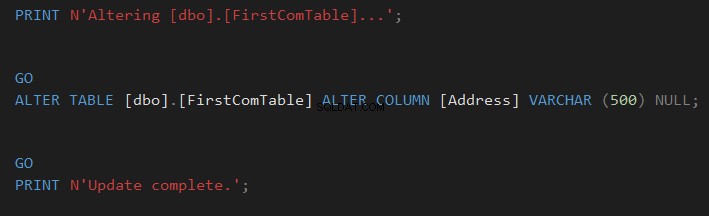
Sammenlign tabelskema ved hjælp af dbForge Studio til SQL Server-tredjepartsværktøj
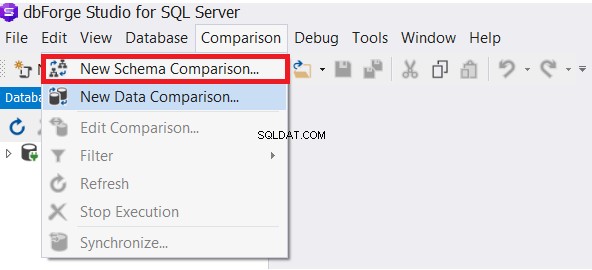
Værktøjet dbForge Studio til SQL Server giver os mulighed for at sammenligne skemaet for de forskellige databasetabeller. Fra sammenligningsmenuen skal du vælgeNy skemasammenligning mulighed som nedenfor:
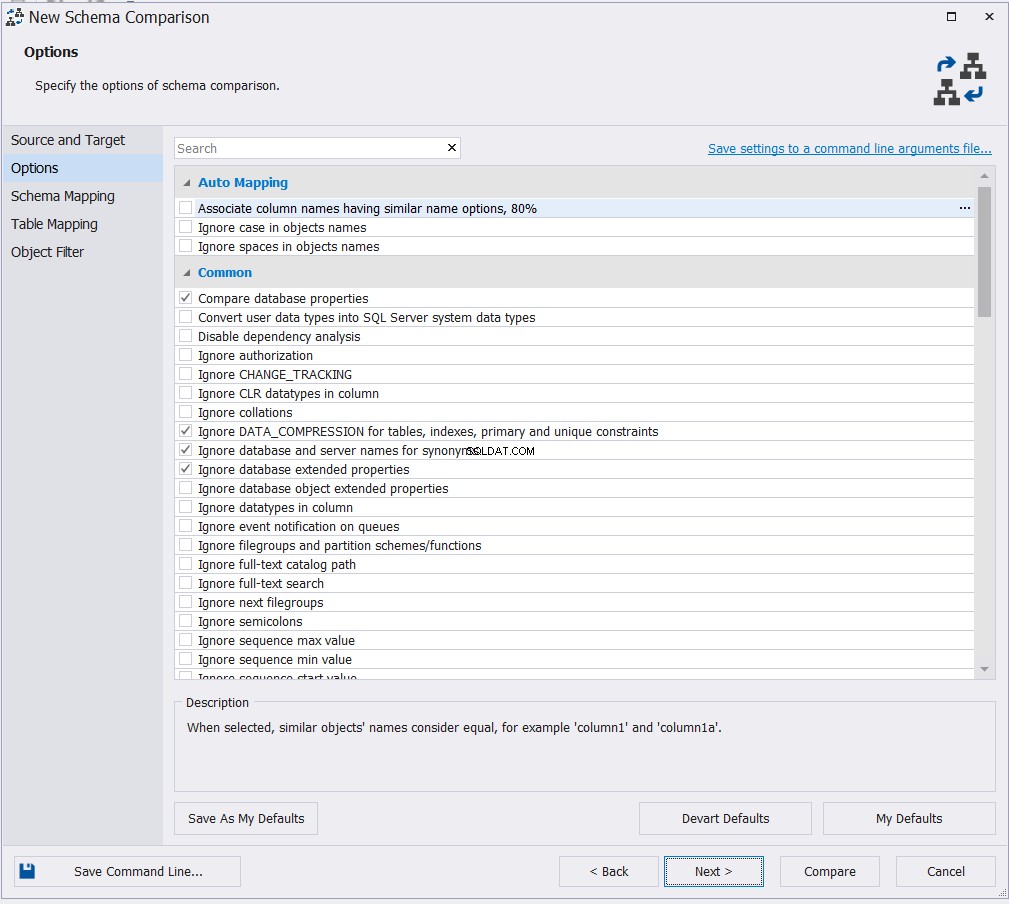
Når du har angivet forbindelsesegenskaberne for både kilde- og måldatabaserne, skal du vælge den passende kortlægningsmulighed blandt de tilgængelige valg og klikke på Næste :
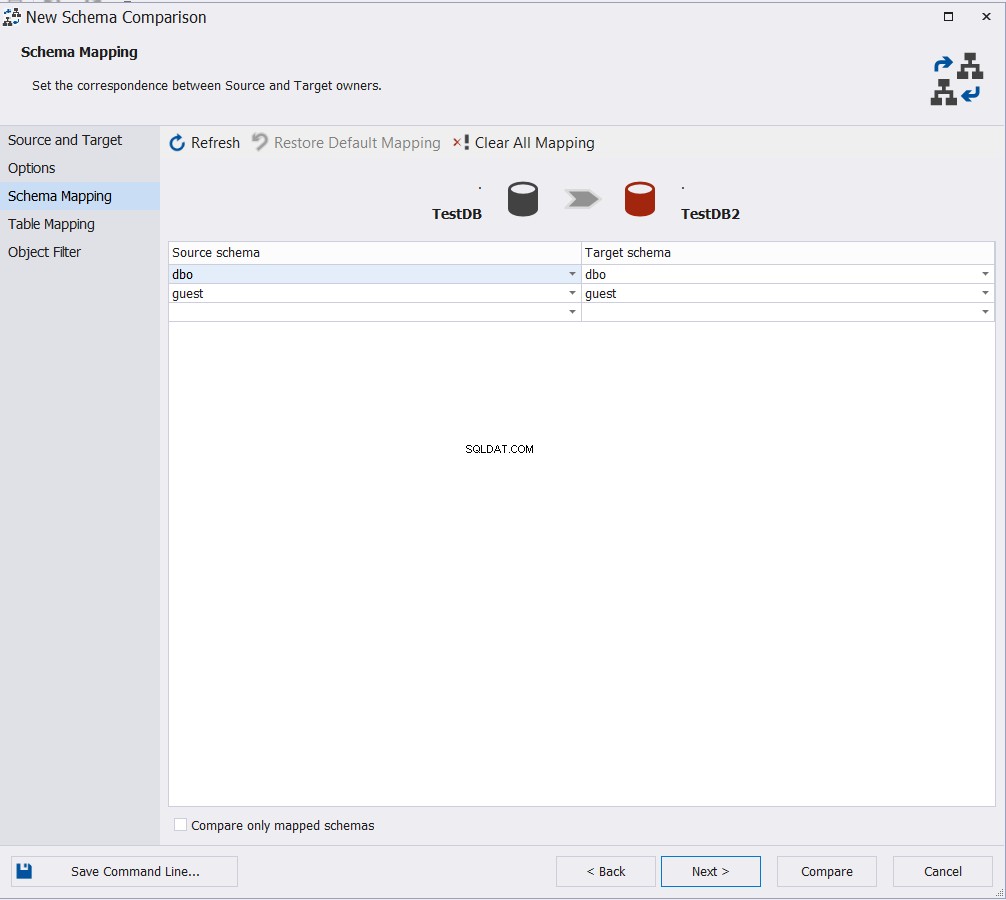
Vælg de skemaer, du vil sammenligne dets objekt med, og klik på Næste :
Angiv den eller de tabeller, der skal deltage i skemasammenligningsprocessen, og klik på Sammenlign , hvis du vil springe over at ændre standardindstillingerne i vinduet Objektfilter, som nedenfor:
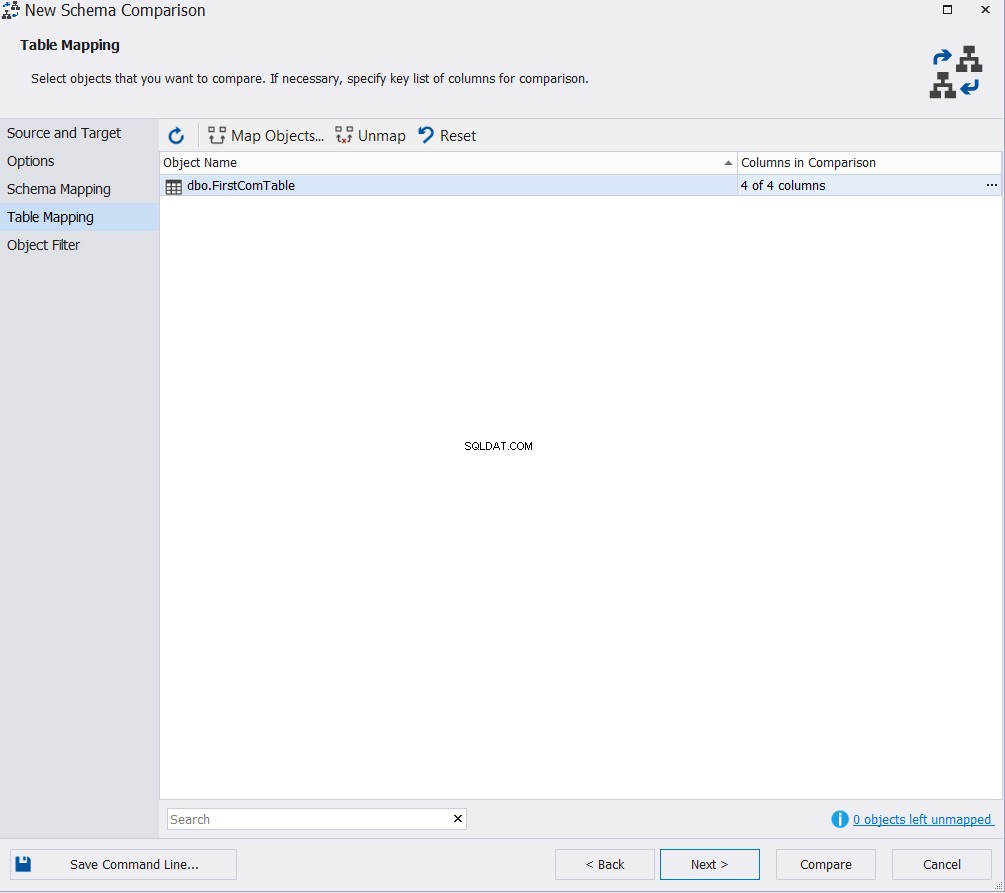
Det viste sammenligningsresultat vil vise dig forskellen mellem de to tabelskemaer ved nøjagtigt at fremhæve den del af datatypen, der adskiller sig mellem de to kolonner, med mulighed for at specificere, hvilken handling der skal gøres for at synkronisere de to tabeller, som vist nedenfor :
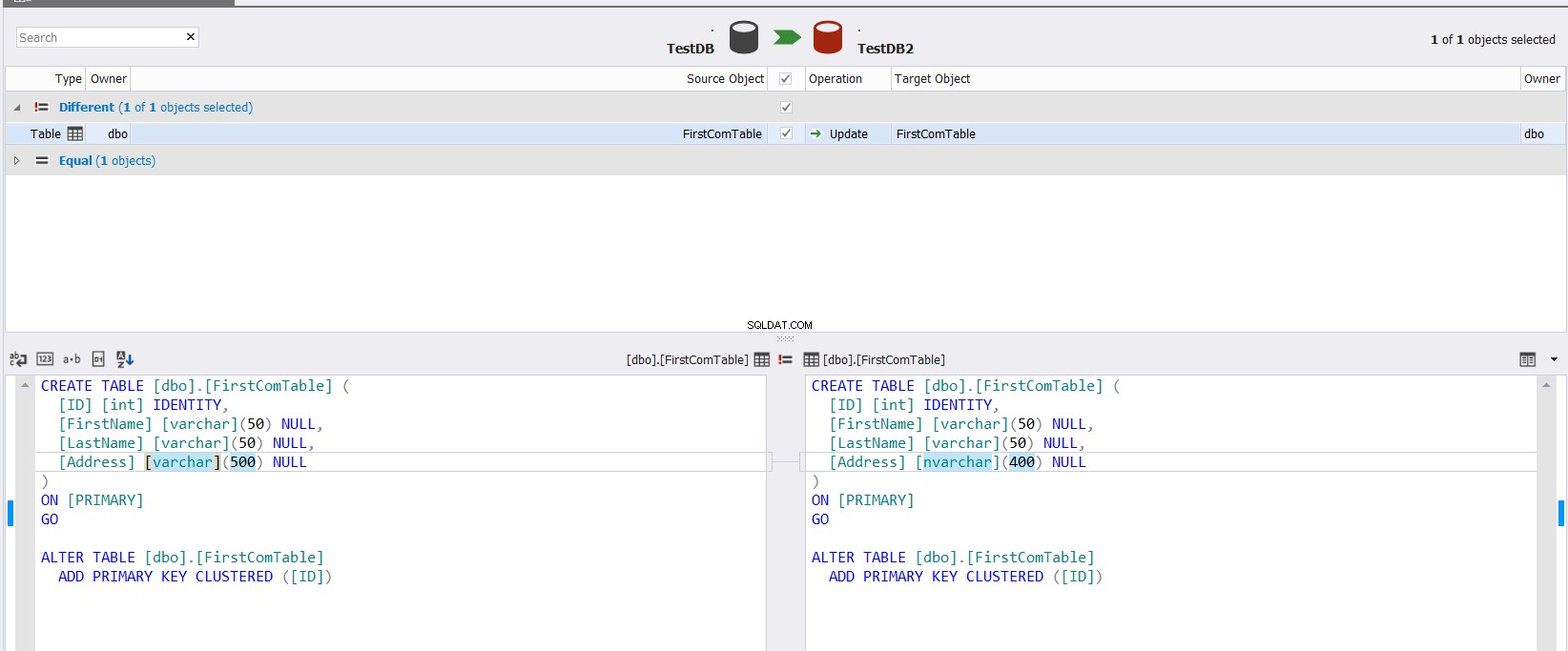
Hvis du arrangerer at synkronisere skemaet for de to tabeller, skal du klikke på knappen og angive i guiden Schema Synchronization, om du formår at udføre ændringen direkte på måltabellen, eller blot scripte den til at blive brugt i fremtiden, som nedenfor:
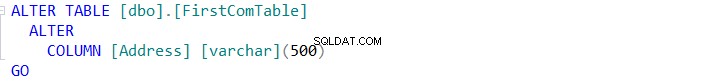
Nyttige links:
- Indstil operatører – EXCEPT og INTERSECT (Transact-SQL)
- Sæt operatører – UNION (Transact-SQL)
- Download SQL Server Data Tools (SSDT)
- Sammenlign og synkroniser data i en eller flere tabeller med data i en referencedatabase
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Systeminformationsskemavisninger (Transact-SQL)
Nyttige værktøjer:
dbForge Schema Compare til SQL Server – pålideligt værktøj, der sparer tid og kræfter, når du sammenligner og synkroniserer databaser på SQL Server.
dbForge Data Compare til SQL Server – kraftfuldt SQL-sammenligningsværktøj, der kan arbejde med big data.