Der var mange kommentarer efter mit indlæg i sidste uge om snordeling. Jeg tror, at pointen med artiklen ikke var så indlysende, som den kunne have været:At bruge en masse tid og kræfter på at prøve at "perfektere" en iboende langsom opdelingsfunktion baseret på T-SQL ville ikke være gavnligt. Jeg har siden samlet den seneste version af Jeff Modens strengopdelingsfunktion og sat den op imod de andre:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (De eneste ændringer, jeg har lavet:Jeg har formateret det til visning, og jeg har fjernet kommentarerne. Du kan hente den originale kilde her.)
Jeg var nødt til at foretage et par justeringer af mine tests for retfærdigt at repræsentere Jeffs funktion. Vigtigst af alt:Jeg var nødt til at kassere alle prøver, der involverede strenge> 4.000 tegn. Så jeg ændrede strengene på 5.000 tegn i tabellen dbo.strings til 4.000 tegn i stedet, og fokuserede kun på de første tre ikke-MAX-scenarier (beholdt de tidligere resultater for de første to og kørte de tredje test igen for de nye 4.000 tegn strenglængder). Jeg droppede også taltabellen fra alle testene undtagen én, fordi det var tydeligt, at ydeevnen der altid var dårligere med en faktor på mindst 10. Følgende diagram viser ydelsen af funktionerne i hver af de fire tests igen. i gennemsnit over 10 kørsler og altid med en kold cache og rene buffere.
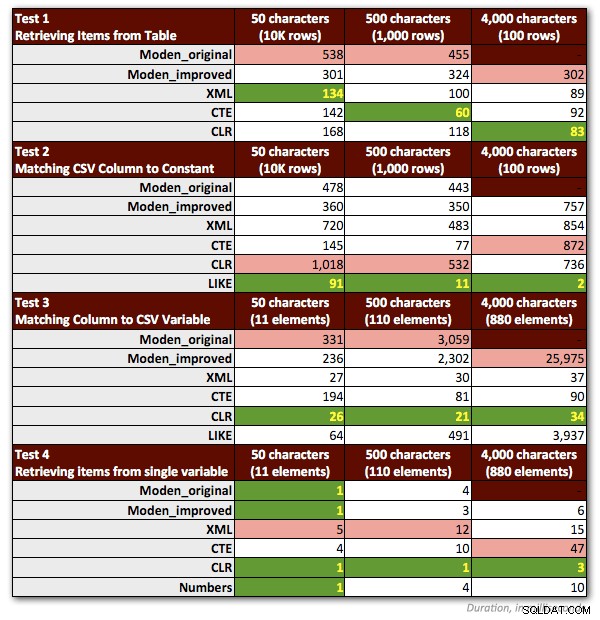
Så her er mine lidt reviderede foretrukne metoder til hver type opgave:
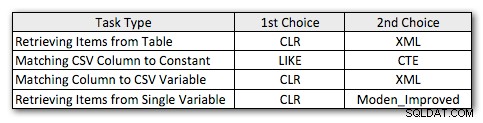
Du vil bemærke, at CLR er forblevet min foretrukne metode, undtagen i det ene tilfælde, hvor opdeling ikke giver mening. Og i tilfælde, hvor CLR ikke er en mulighed, er XML- og CTE-metoderne generelt mere effektive, undtagen i tilfælde af enkelt variabel opdeling, hvor Jeffs funktion meget vel kan være den bedste mulighed. Men i betragtning af at jeg muligvis skal understøtte mere end 4.000 tegn, kan Numbers-tabelløsningen måske komme tilbage på min liste i specifikke situationer, hvor jeg ikke må bruge CLR.
Jeg lover, at mit næste indlæg, der involverer lister, slet ikke vil tale om opdeling, via T-SQL eller CLR, og vil demonstrere, hvordan man forenkler dette problem uanset datatype.
Som en sidebemærkning bemærkede jeg denne kommentar i en af versionerne af Jeffs funktioner, der blev lagt ud i kommentarerne:Jeg takker også den, der skrev den første artikel, jeg nogensinde så om "taltabeller", som er placeret på følgende URL og til Adam Machanic for at have ført mig til det for mange år siden.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -hjælpe-numre-tabel.html
Denne artikel er skrevet af mig i 2004. Så den, der har tilføjet kommentaren til funktionen, er velkommen. :-)