Et almindeligt scenarie i mange klient-server-applikationer er at tillade slutbrugeren at diktere sorteringsrækkefølgen af resultater. Nogle mennesker ønsker at se de laveste varer først, nogle ønsker at se de nyeste varer først, og nogle ønsker at se dem alfabetisk. Dette er en kompleks ting at opnå i Transact-SQL, fordi du ikke bare kan sige:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN ... ORDER BY @SortColumn; -- eller ... BESTIL EFTER @SortColumn @SortDirection;ENDGO
Dette skyldes, at T-SQL ikke tillader variabler på disse steder. Hvis du bare bruger @SortColumn, modtager du:
Meddelelse 1008, niveau 16, tilstand 1, linje xVÆLG-elementet identificeret med ORDER BY-nummeret 1 indeholder en variabel som en del af udtrykket, der identificerer en kolonneposition. Variabler er kun tilladt, når der bestilles efter et udtryk, der refererer til et kolonnenavn.
(Og når fejlmeddelelsen siger "et udtryk, der refererer til et kolonnenavn," kan du finde det tvetydigt, og jeg er enig. Men jeg kan forsikre dig om, at det ikke betyder, at en variabel er et passende udtryk.)
Hvis du prøver at tilføje @SortDirection, er fejlmeddelelsen lidt mere uigennemsigtig:
Msg 102, Level 15, State 1, Line xForkert syntaks nær '@SortDirection'.
Der er et par måder at undgå dette på, og dit første instinkt kan være at bruge dynamisk SQL eller at introducere CASE-udtrykket. Men som med de fleste ting, er der komplikationer, der kan tvinge dig ned ad den ene eller anden vej. Så hvilken skal du bruge? Lad os undersøge, hvordan disse løsninger kan fungere, og sammenligne virkningerne på ydeevnen for et par forskellige tilgange.
Eksempel på data
Ved at bruge en katalogvisning, som vi sikkert alle forstår ganske godt, sys.all_objects, oprettede jeg følgende tabel baseret på en krydssammenføjning, hvilket begrænsede tabellen til 100.000 rækker (jeg ville have data, der fyldte mange sider, men det tog ikke lang tid at forespørge på og test):
CREATE DATABASE OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- en BIGINT med klynget indeks s1.[object_id], -- en INT uden et indeksnavn =s1.name -- en NVARCHAR med et understøttende indeks COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- en NVARCHAR(60) uden et indeks COLLATE SQL_Latin1_General_CP1_CI_AS, s1.index_modify_date an FTOINob_times. sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2ORDER BY s1.[object_id];
(SAMLING-tricket er, fordi mange katalogvisninger har forskellige kolonner med forskellige sorteringer, og dette sikrer, at de to kolonner vil matche til formålet med denne demo.)
Derefter oprettede jeg et typisk klynget / ikke-klynget indekspar, der kunne eksistere på sådan en tabel, før optimering (jeg kan ikke bruge object_id for nøglen, fordi krydsforbindelsen skaber dubletter):
OPRET UNIKT KLUSTERET INDEKS key_col PÅ dbo.sys_objects(key_col); OPRET INDEX-navn PÅ dbo.sys_objects(name);
Use Cases
Som nævnt ovenfor vil brugere måske se disse data sorteret på en række forskellige måder, så lad os angive nogle typiske use cases, vi ønsker at understøtte (og med support mener jeg at demonstrere):
- Ordet efter key_col stigende ** standard, hvis brugeren er ligeglad
- Ordet efter object_id (stigende/faldende)
- Sorteret efter navn (stigende/faldende)
- Ordet efter type_desc (stigende/faldende)
- Ordet efter modify_date (stigende/faldende)
Vi lader key_col-rækkefølgen være standard, fordi den burde være den mest effektive, hvis brugeren ikke har en præference; da key_col er et vilkårligt surrogat, der ikke burde betyde noget for brugeren (og måske ikke engang bliver udsat for dem), er der ingen grund til at tillade omvendt sortering på den kolonne.
Tilgange, der ikke virker
Den mest almindelige tilgang, jeg ser, når nogen først begynder at tackle dette problem, er at introducere kontrol-af-flow-logik til forespørgslen. De forventer at kunne gøre dette:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objectsORDER BY IF @SortColumn ='key_col' key_colIF @SortColumn ='object_id' [object_id]IF @SortColumn ='navn' navn...IF @SortDirection ='ASC' ASCELSE DESC;
Dette virker åbenbart ikke. Dernæst ser jeg CASE blive introduceret forkert, ved hjælp af lignende syntaks:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objectsORDER BY CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] WHEN 'name' THEN name ... END CASE WHEN @SortDirection 'ASC' SÅ ASC ELSE DESC END;
Dette er tættere på, men det mislykkes af to grunde. Den ene er, at CASE er et udtryk, der returnerer præcis én værdi af en bestemt datatype; dette fletter datatyper, der er inkompatible, og vil derfor bryde CASE-udtrykket. Den anden er, at der ikke er nogen måde at betinget anvende sorteringsretningen på denne måde uden at bruge dynamisk SQL.
Tilgange, der virker
De tre primære tilgange, jeg har set, er som følger:
Grupper kompatible typer og rutevejledninger sammen
For at bruge CASE med ORDER BY skal der være et særskilt udtryk for hver kombination af kompatible typer og retninger. I dette tilfælde skal vi bruge noget som dette:
CREATE PROCEDURE dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'AS BEGIN SET NOCOUNT ON; VÆLG key_col, [object_id], name, type_desc, modify_date FRA dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' SÅ CASE @SortColumn NÅR 'key_col' SÅ key_col NÅR 'object_id' SÅ [object_id' SÅ [object_id' SÅ END @EN, CASE] . SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] END END DESC, CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn NÅR 'navn' SÅ navn NÅR' 'type type_desc END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'name' THEN name WHEN 'type_desc' SÅ type_desc END END DESC, CASE WHEN @SortColumn ='modify_date' OG @SortDirection THEN END ='ASCdate' , CASE NÅR @SortColumn ='modify_date' OG @SortDirection ='DESC' SÅ modify_date END DESC;END
Du kan sige, wow, det er en grim smule kode, og jeg er enig med dig. Jeg tror, det er grunden til, at mange mennesker cacher deres data på frontend og lader præsentationsniveauet beskæftige sig med at jonglere rundt i forskellige rækkefølger. :-)
Du kan kollapse denne logik en lille smule yderligere ved at konvertere alle ikke-strengtyper til strenge, der sorterer korrekt, f.eks.
OPRET PROCEDURE dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'AS BEGIN SET NOCOUNT ON; VÆLG key_col, [object_id], name, type_desc, modify_date FRA dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' SÅ HØJRE('0000000000000)_col('000000)' + RTRIM(key), '12key' objekt_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([objekt_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([objekt_id]), 24) NÅR 'navn' THEN name WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT(' 000000000000' + RTRIM(key_col), 12) WHEN 'object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23 ) + RTRIM([objekt_id]), 24) WHEN 'navn' THEN name WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END END DESC;END Alligevel er det et ret grimt rod, og man skal gentage udtrykkene to gange for at håndtere de forskellige sorteringsretninger. Jeg vil også formoder, at brug af OPTION RECOMPILE på den forespørgsel ville forhindre dig i at blive stukket af parametersniffing. Bortset fra i standardtilfældet er det ikke sådan, at størstedelen af det arbejde, der udføres her, vil være kompilering.
Anvend en rangering ved hjælp af vinduesfunktioner
Jeg opdagede dette smarte trick fra AndriyM, selvom det er mest nyttigt i tilfælde, hvor alle de potentielle rækkefølgekolonner er af kompatible typer, ellers er udtrykket brugt for ROW_NUMBER() lige så komplekst. Den mest smarte del er, at for at skifte mellem stigende og faldende rækkefølge, multiplicerer vi simpelthen ROW_NUMBER() med 1 eller -1. Vi kan anvende det i denne situation som følger:
OPRET PROCEDURE dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON;;WITH x AS ( SELECT key_col, [object_id], name, type_desc, modify_date, rn =ROW_NUMBER() OVER ( ORDER BY CASE @SortColumn NÅR 'key_col' SÅ HØJRE('000000000000' + RTRIM(key_WHEN), '12) objekt_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([objekt_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([objekt_id]), 24) NÅR 'navn' THEN name WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END ) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END FROM key dbo.sys_objects_col ) SELECT , [object_id], navn, type_desc, modify_date FROM x BESTILLING AF rn;ENDGO Igen, OPTION RECOMPILE kan hjælpe her. Du kan også i nogle af disse tilfælde bemærke, at bånd håndteres forskelligt af de forskellige planer - når du for eksempel bestiller efter navn, vil du normalt se, at key_col kommer igennem i stigende rækkefølge inden for hvert sæt af duplikerede navne, men du kan også se værdierne blandet sammen. For at give mere forudsigelig adfærd i tilfælde af uafgjorte forhold, kan du altid tilføje en ekstra ORDER BY-klausul. Bemærk, at hvis du skulle tilføje key_col til det første eksempel, skal du gøre det til et udtryk, så key_col ikke er opført i ORDER BY to gange (du kan f.eks. gøre dette ved at bruge key_col + 0).
Dynamisk SQL
Mange mennesker har forbehold over for dynamisk SQL – det er umuligt at læse, det er grobund for SQL-injektion, det fører til plan cache-bloat, det besejrer formålet med at bruge lagrede procedurer... Nogle af disse er simpelthen usande, og nogle af dem er nemme at afbøde. Jeg har tilføjet noget validering her, som lige så nemt kunne tilføjes til enhver af ovenstående procedurer:
OPRET PROCEDURE dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'AS BEGIN SET NOCOUNT ON; -- afvis enhver ugyldig sorteringsvejledning:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Ugyldig parameter for @SortDirection:%s', 11, 1, @SortDirection); RETURNERING -1; END -- afvis eventuelle uventede kolonnenavne:HVIS LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Ugyldig parameter for @SortColumn:%s', 11, 1, @SortColumn); RETURNERING -1; END SET @SortColumn =QUOTENAME(@SortColumn); DECLARE @sql NVARCHAR(MAX); SET @sql =N'SELECT key_col, [object_id], name, type_desc, modify_date FRA dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Sammenligning af ydeevne
Jeg oprettede en indpakning lagret procedure for hver procedure ovenfor, så jeg nemt kunne teste alle scenarier. De fire indpakningsprocedurer ser sådan ud, med procedurenavnet varierende naturligvis:
OPRET PROCEDURE dbo.Test_Sort_CaseExpandedASBEGIN INDSTILL INGEN TÆLLING TIL; EXEC dbo.Sort_CaseExpanded; -- standard EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
Og så ved at bruge SQL Sentry Plan Explorer genererede jeg faktiske udførelsesplaner (og de målinger, der skal følge med dem) med følgende forespørgsler og gentog processen 10 gange for at opsummere den samlede varighed:
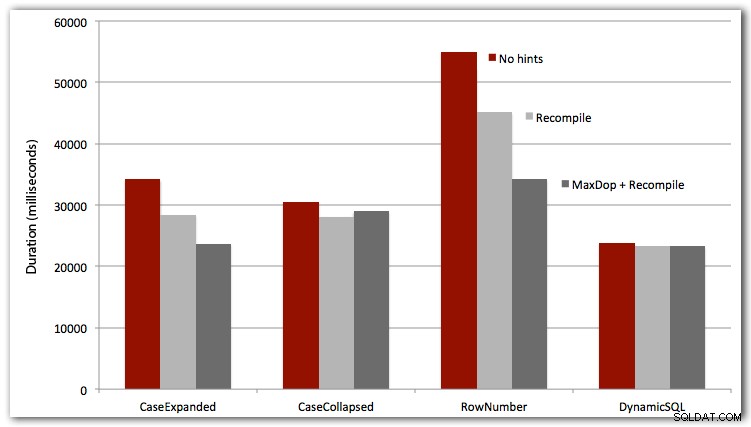
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber;--EXEC dbo.Test_Sort_Dyna;Jeg testede også de første tre cases med OPTION RECOMPILE (giver ikke meget mening for den dynamiske SQL-case, da vi ved, at det vil være en ny plan hver gang), og alle fire cases med MAXDOP 1 for at eliminere parallelismeinterferens. Her er resultaterne:
Konklusion
For direkte ydeevne vinder dynamisk SQL hver gang (dog kun med en lille margen på dette datasæt). ROW_NUMBER()-tilgangen var, selvom den var smart, taberen i hver test (undskyld AndriyM).
Det bliver endnu sjovere, når du vil introducere en WHERE-klausul, pyt med personsøgning. Disse tre er som den perfekte storm til at introducere kompleksitet til, hvad der starter som en simpel søgeforespørgsel. Jo flere permutationer din forespørgsel har, jo mere sandsynligt vil du kaste læsbarheden ud af vinduet og bruge dynamisk SQL i kombination med indstillingen "optimer til ad hoc-arbejdsbelastninger" for at minimere virkningen af engangsplaner i din plans cache.