Introduktion
Udviklere bliver ofte bedt om at bruge lagrede procedurer for at undgå de såkaldte ad hoc-forespørgsler hvilket kan resultere i unødvendig oppustning af planens cache. Du kan se, når tilbagevendende SQL-kode er skrevet inkonsekvent, eller når der er kode, der genererer dynamisk SQL på farten, har SQL Server en tendens til at oprette en eksekveringsplan for hver enkelt eksekvering. Dette kan reducere den samlede ydeevne med:
Kræver en kompileringsfase for hver kodeudførelse.
Blæser plancachen med for mange planhåndtag, som muligvis ikke kan genbruges.
Optimer til ad hoc-arbejdsbelastninger
En måde, dette problem tidligere blev håndteret på, er at optimere instansen til ad hoc-arbejdsbelastninger. Det kan kun være nyttigt at gøre dette, hvis de fleste databaser eller væsentligste databaser i instansen overvejende udfører Ad Hoc SQL.
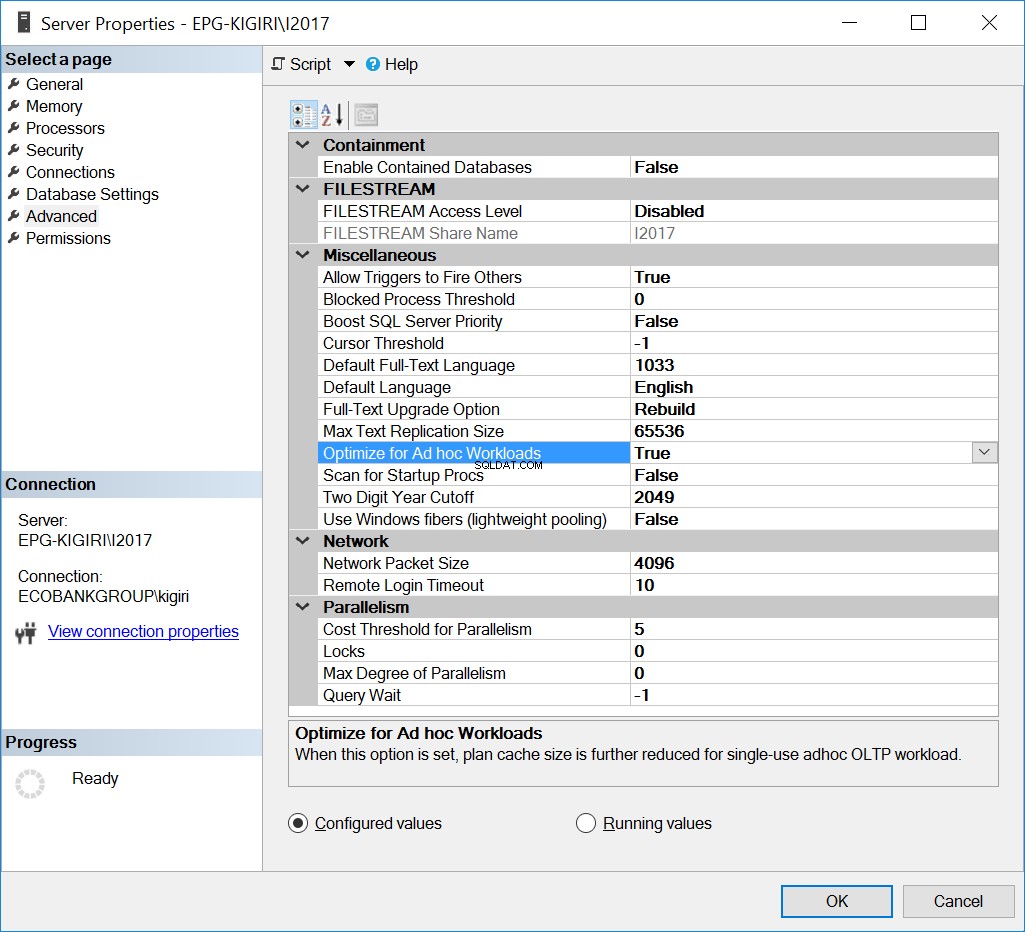
Fig. 1 Optimer til ad hoc-arbejdsbelastninger
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
I bund og grund fortæller denne mulighed SQL Server om at gemme en delvis version af planen kendt som den kompilerede planstub. Stubben fylder meget mindre end hele planen.
Som et alternativ til denne metode, griber nogle mennesker an til problemet temmelig brutalt og tømmer plancachen i ny og næ. Eller, på en mere forsigtig måde, tøm "engangsplaner" ved at bruge DBCC FREESYSTEMCACHE. At skylle hele planens cache har sine ulemper, som du måske allerede ved.
Brug af lagrede procedurer og parametre
Ved at bruge lagrede procedurer kan man praktisk talt eliminere problemet forårsaget af Ad Hoc SQL. En lagret procedure kompileres kun én gang, og den samme plan genbruges til efterfølgende udførelse af den samme eller lignende SQL-forespørgsler. Når lagrede procedurer bruges til at implementere forretningslogik, ligger den vigtigste forskel i de SQL-forespørgsler, der i sidste ende vil blive eksekveret af SQL Server, i de parametre, der overføres på udførelsestidspunktet. Da planen allerede er på plads og klar til brug, vil SQL Server bruge den samme plan, uanset hvilken parameter der sendes.
Skæve data
I visse scenarier er de data, vi har med at gøre, ikke fordelt jævnt. Vi kan demonstrere dette – først skal vi oprette en tabel:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Vores tabel indeholder data om klubmedlemmer fra forskellige lande. Et stort antal klubmedlemmer er fra Ghana, mens to andre nationer har henholdsvis ti og to medlemmer. For at holde fokus på dagsordenen og for enkelhedens skyld brugte jeg kun tre lande og samme navn for medlemmer, der kommer fra det samme land. Jeg tilføjede også et klynget indeks i ID-kolonnen og et ikke-klynget indeks i CountryCode-kolonnen for at demonstrere effekten af forskellige eksekveringsplaner for forskellige værdier.
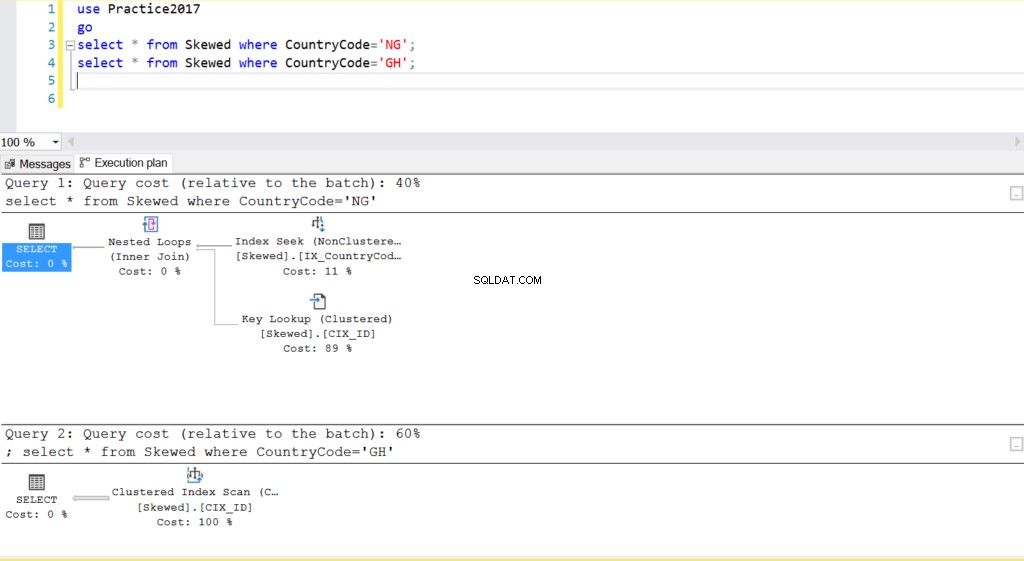
Fig. 2 Eksekveringsplaner for to forespørgsler
Når vi forespørger i tabellen for poster, hvor CountryCode er NG og GH, finder vi ud af, at SQL Server bruger to forskellige eksekveringsplaner i disse tilfælde. Dette sker, fordi det forventede antal rækker for CountryCode='NG' er 10, mens det for CountryCode='GH' er 10000. SQL Server bestemmer den foretrukne eksekveringsplan baseret på tabelstatistik. Hvis det forventede antal rækker er højt sammenlignet med det samlede antal rækker i tabellen, beslutter SQL Server, at det er bedre blot at lave en fuld tabelscanning i stedet for at henvise til et indeks. Med et meget mindre anslået antal rækker bliver indekset nyttigt.
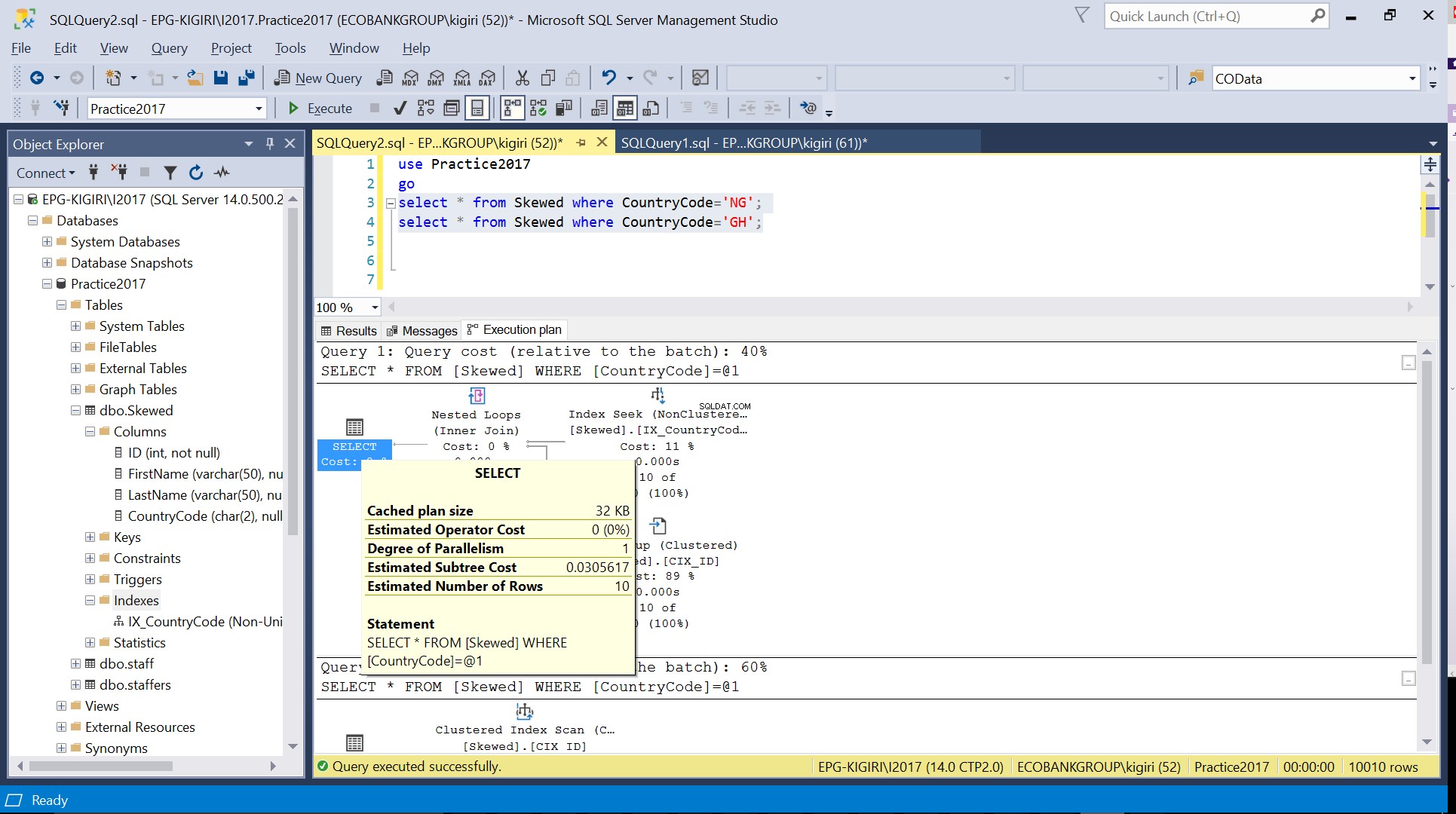
Fig. 3 Estimeret antal rækker for CountryCode=’NG’
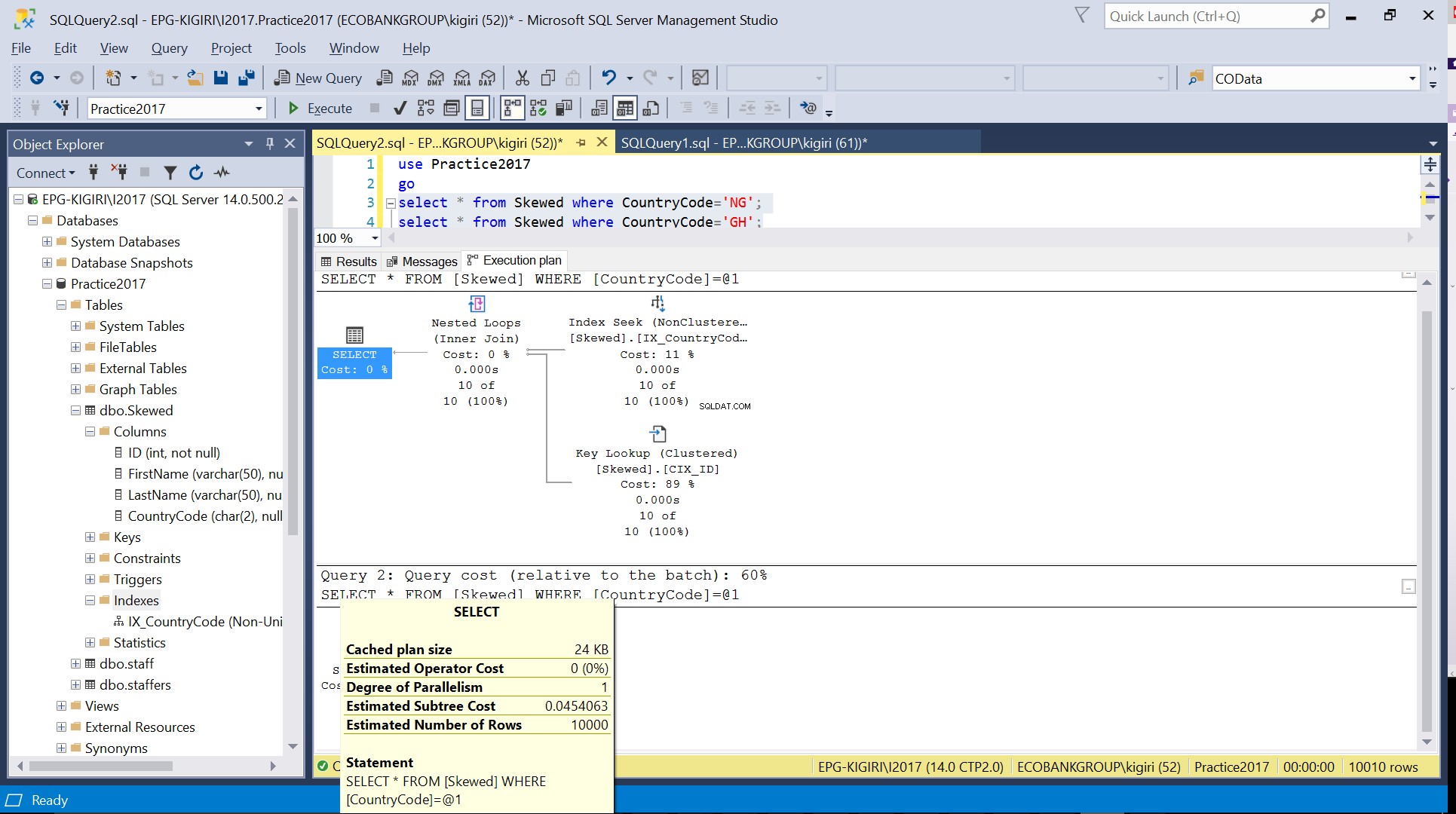
Fig. 4 Estimeret antal rækker for CountryCode='GH'
Indtast lagrede procedurer
Vi kan oprette en lagret procedure til at hente de poster, vi ønsker, ved at bruge den samme forespørgsel. Den eneste forskel denne gang er, at vi sender CountryCode som en parameter (se liste 3). Når vi gør dette, opdager vi, at udførelsesplanen er den samme, uanset hvilken parameter vi passerer. Den eksekveringsplan, der vil blive brugt, bestemmes af den eksekveringsplan, der returneres ved første gang, den lagrede procedure aktiveres. For eksempel, hvis vi kører proceduren med CountryCode='GH' først, vil den bruge en fuld tabelscanning fra det tidspunkt. Hvis vi derefter rydder procedurecachen og kører proceduren med CountryCode='NG' først, vil den fremover bruge indeksbaserede scanninger.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
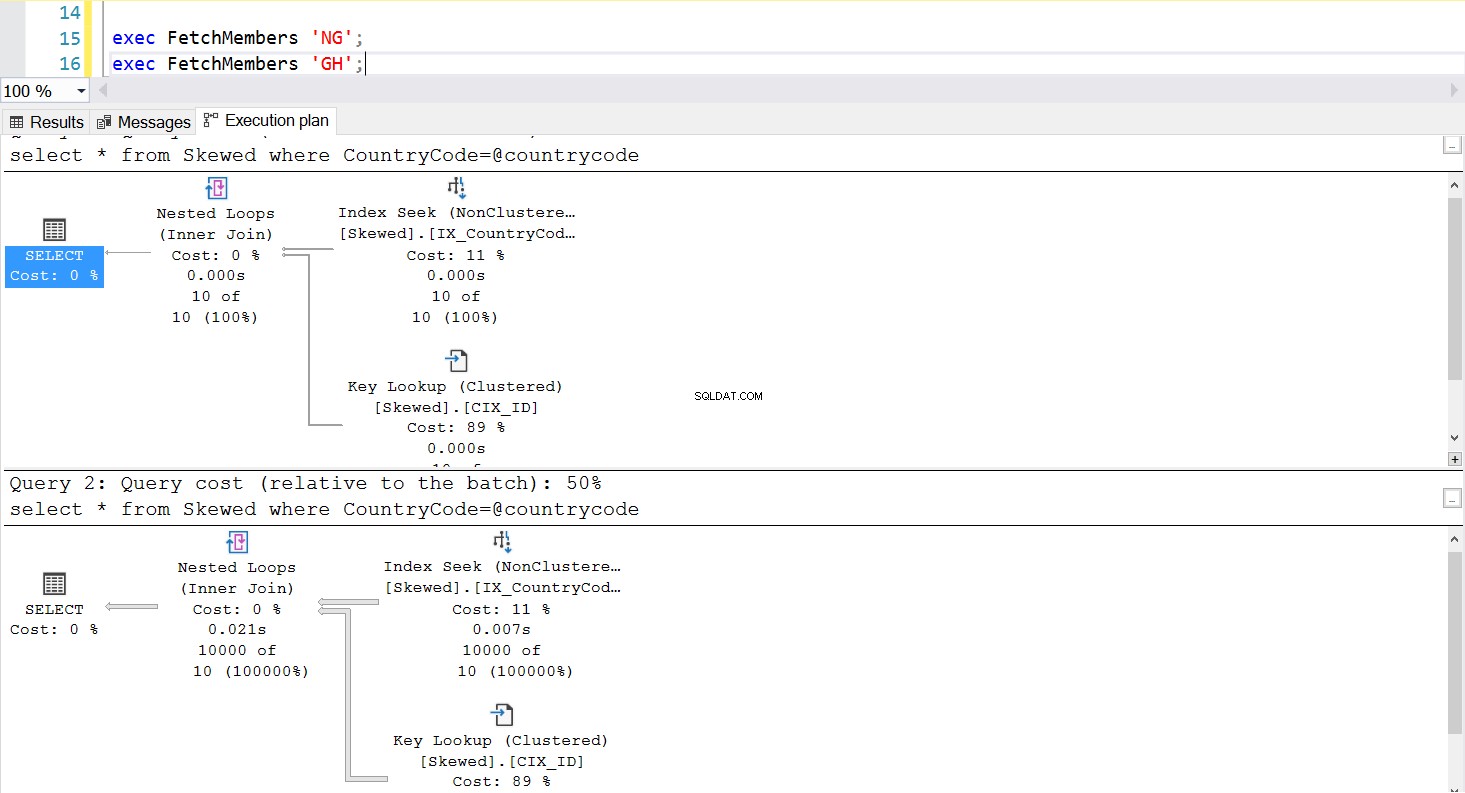
Fig. 5 Indekssøgningsudførelsesplan, når 'NG' bruges først
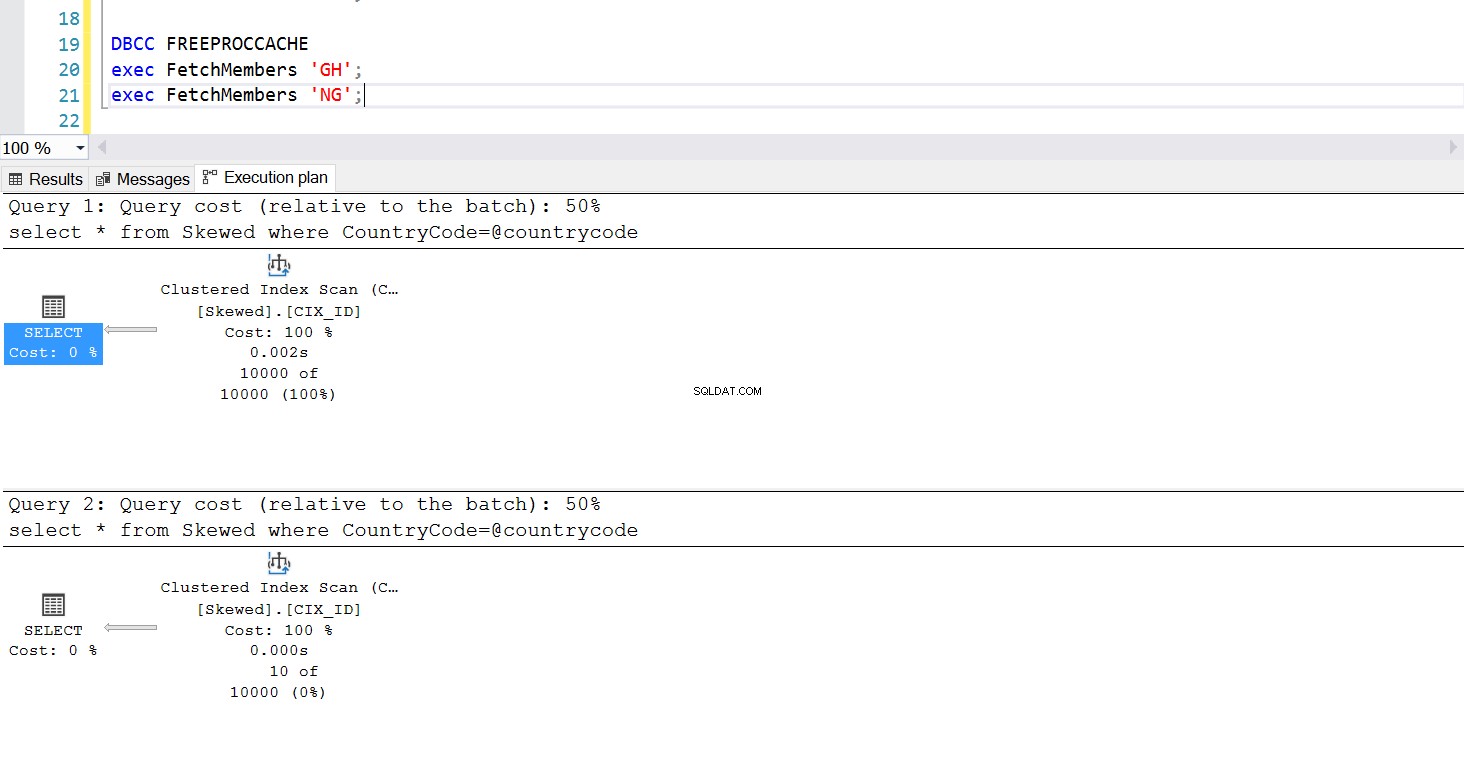
Fig. 6 Klyngede indeksscanningsudførelsesplan, når 'GH' bruges først
Udførelsen af den lagrede procedure opfører sig som designet – den påkrævede udførelsesplan bruges konsekvent. Dette kan dog være et problem, fordi én eksekveringsplan ikke er egnet til alle forespørgsler, hvis dataene er skæve. Det er ikke effektivt at bruge et indeks til at hente en række rækker, der er næsten lige så store som hele tabellen – heller ikke at bruge en fuld scanning til kun at hente et lille antal rækker. Dette er Parameter Sniffing-problemet.
Mulige løsninger
En almindelig måde at håndtere Parameter Sniffing-problemet på er bevidst at påkalde rekompilering, når den lagrede procedure udføres. Dette er meget bedre end at tømme Plan-cachen – undtagen hvis du vil tømme cachen for denne specifikke SQL-forespørgsel, hvilket er fuldt ud muligt. Tag et kig på en opdateret version af den lagrede procedure. Denne gang bruger den OPTION (RECOMPILE) til at håndtere problemet. Fig.6 viser os, at når den nye lagrede procedure udføres, bruger den en plan, der passer til den parameter, vi sender.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
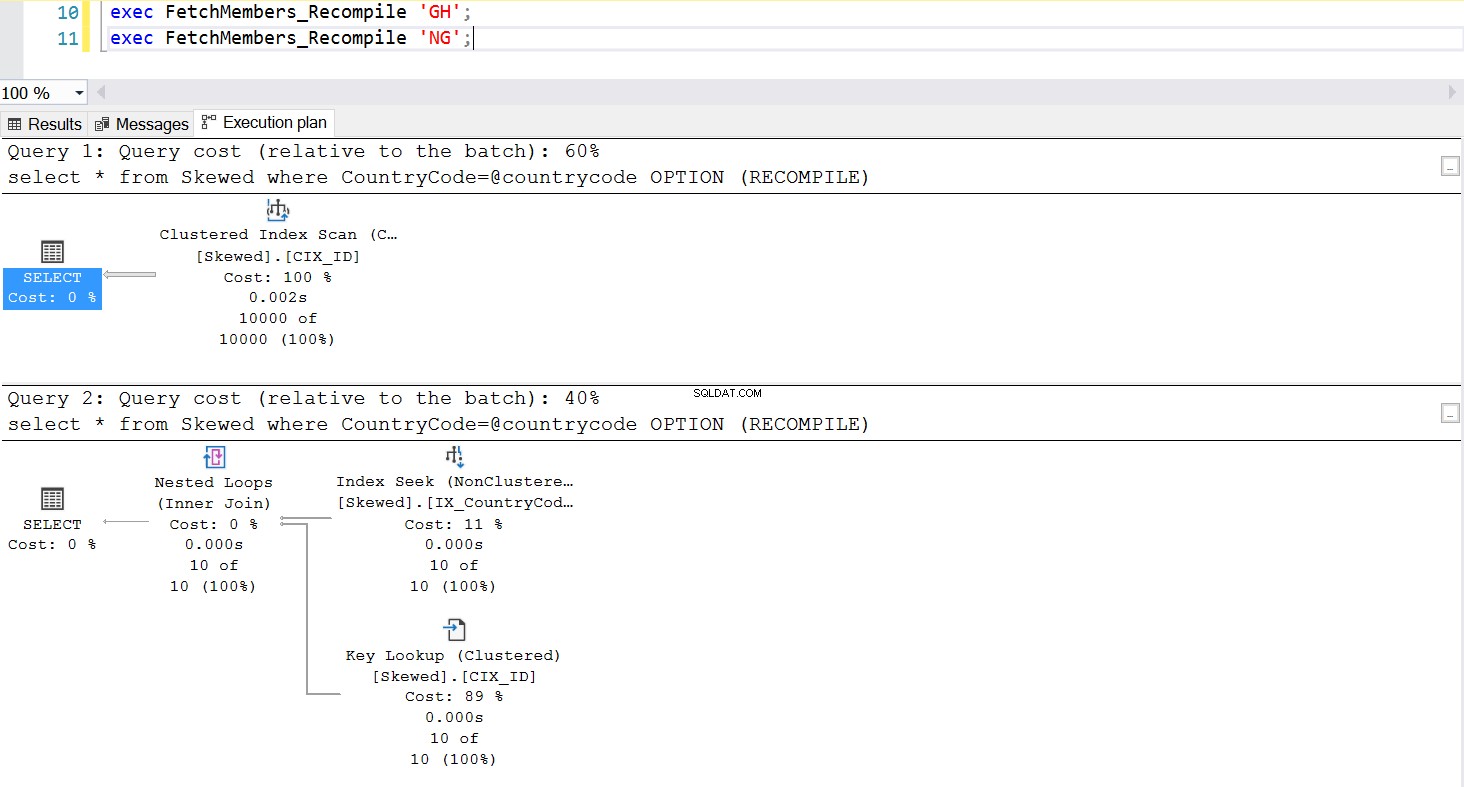
Fig. 7 Opførsel af den lagrede procedure med OPTION (RECOMPILE)
Konklusion
I denne artikel har vi set på, hvordan konsekvente eksekveringsplaner for lagrede procedurer kan blive et problem, når de data, vi har med at gøre, er skæve. Det har vi også demonstreret i praksis og lært om en fælles løsning på problemet. Jeg tør godt sige, at denne viden er uvurderlig for udviklere, der bruger SQL Server. Der er en række andre løsninger på dette problem – Brent Ozar gik dybere ind i emnet og fremhævede nogle mere dybtgående detaljer og løsninger på SQLDay Poland 2017. Jeg har angivet det tilsvarende link i referencesektionen.
Referencer
Planlæg cache og optimering til adhoc-arbejdsbelastninger
Identifikation og rettelse af parametersniffingsproblemer