Kvaliteten af en eksekveringsplan er meget afhængig af nøjagtigheden af det estimerede antal rækker, som hver planoperatør udfører. Hvis det estimerede antal rækker er væsentligt skævt i forhold til det faktiske antal rækker, kan dette have en væsentlig indflydelse på kvaliteten af en forespørgsels eksekveringsplan. Dårlig plankvalitet kan være ansvarlig for overdreven I/O, oppustet CPU, hukommelsestryk, nedsat gennemløb og reduceret generel samtidighed.
Med "plankvalitet" - jeg taler om at få SQL Server til at generere en eksekveringsplan, der resulterer i fysiske operatørvalg, der afspejler den aktuelle tilstand af dataene. Ved at træffe sådanne beslutninger baseret på nøjagtige data er der større chance for, at forespørgslen vil fungere korrekt. Kardinalitetsestimatværdierne bruges som input til operatøromkostninger, og når værdierne er for langt væk fra virkeligheden, kan den negative indvirkning på udførelsesplanen blive udtalt. Disse estimater føres til de forskellige omkostningsmodeller, der er knyttet til selve forespørgslen, og dårlige rækkeestimater kan påvirke en række beslutninger, herunder indeksvalg, søge- og scanningsoperationer, parallel versus seriel udførelse, valg af joinalgoritme, indre vs. ydre fysisk joinforbindelse udvælgelse (f.eks. build vs. probe), spoolgenerering, bogmærkeopslag vs. fuld klynge- eller heap-tabeladgang, strøm- eller hash-samlet udvælgelse, og hvorvidt en dataændring bruger en bred eller snæver plan.
Lad os som et eksempel sige, at du har følgende SELECT forespørgsel (ved hjælp af kreditdatabasen):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
Baseret på forespørgselslogikken, er den følgende planform, hvad du ville forvente at se?
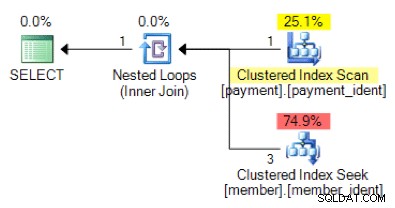
Og hvad med denne alternative plan, hvor vi i stedet for en indlejret løkke har et hash-match?
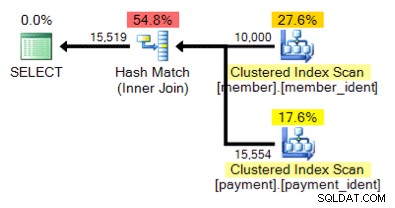
Det "rigtige" svar afhænger af nogle få andre faktorer - men en væsentlig faktor er antallet af rækker i hver af tabellerne. I nogle tilfælde er den ene fysiske join-algoritme mere passende end den anden – og hvis de oprindelige antagelser om kardinalitetsestimater ikke er korrekte, bruger din forespørgsel muligvis en ikke-optimal tilgang.
Identifikation problemer med kardinalitetsestimat er relativt ligetil. Hvis du har en faktisk udførelsesplan, kan du sammenligne de estimerede kontra faktiske rækketællingsværdier for operatører og se efter skævheder. SQL Sentry Plan Explorer forenkler denne opgave ved at give dig mulighed for at se faktiske versus estimerede rækker for alle operatorer i en enkelt plantræfane versus at skulle holde musemarkøren over de individuelle operatorer i den grafiske plan:

Nu resulterer skævheder ikke altid i planer af dårlig kvalitet, men hvis du har præstationsproblemer med en forespørgsel, og du ser sådanne skævheder i planen, er dette et område, der så er værd at undersøge nærmere.
Identifikation af problemer med kardinalitetsestimat er relativt ligetil, men løsningen er det ofte ikke. Der er en række grundlæggende årsager til, hvorfor der kan opstå problemer med kardinalitetsestimater, og jeg vil dække ti af de mere almindelige årsager i dette indlæg.
Manglende eller forældede statistikker
Af alle årsagerne til problemer med kardinalitetsestimater er dette den, du håber at se, da det ofte er nemmest at tage fat på. I dette scenarie mangler dine statistikker enten eller er forældede. Du kan have databaseindstillinger for automatisk statistikoprettelse og opdateringer deaktiveret, "ingen genberegnet" aktiveret for specifikke statistikker eller have store nok tabeller til, at dine automatiske statistikopdateringer simpelthen ikke sker ofte nok.
Sampleprøveproblemer
Det kan være, at præcisionen af statistikhistogrammet er utilstrækkelig – for eksempel hvis du har en meget stor tabel med betydelige og/eller hyppige dataskævheder. Du skal muligvis ændre din sampling fra standarden, eller hvis selv det ikke hjælper – undersøg ved hjælp af separate tabeller, filtreret statistik eller filtrerede indekser.
Skjulte kolonnekorrelationer
Forespørgselsoptimeringsværktøjet antager, at kolonner i den samme tabel er uafhængige. For eksempel, hvis du har en by og en stat kolonne, kan vi intuitivt vide, at disse to kolonner er korrelerede, men SQL Server forstår ikke dette, medmindre vi hjælper det med et tilknyttet multi-kolonne indeks eller med manuelt oprettet multi- kolonne statistik. Uden at hjælpe optimeringsværktøjet med korrelation, kan selektiviteten af dine prædikater være overdrevet.
Nedenfor er et eksempel på to korrelerede prædikater:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Jeg ved tilfældigvis, at 10 % af vores 10.000 række member tabel kvalificerer til denne kombination, men forespørgselsoptimeringsværktøjet gætter på, at det er 1 % af de 10.000 rækker:
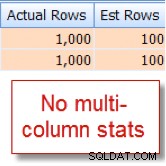
Kontrast nu dette med det passende skøn, som jeg ser efter at have tilføjet statistikker med flere kolonner:
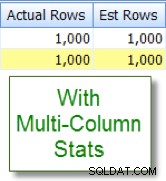
Sammenligning af kolonner inden for tabel
Kardinalitetsestimatproblemer kan opstå, når kolonner i samme tabel sammenlignes. Dette er et kendt problem. Hvis du er nødt til at gøre det, kan du forbedre kardinalitetsestimaterne for kolonnesammenligningerne ved at bruge beregnede kolonner i stedet for eller ved at omskrive forespørgslen for at bruge selvforbindelser eller almindelige tabeludtryk.
Tabel Variabel Brug
Bruger du tabelvariabler meget? Tabelvariabler viser et kardinalitetsestimat på "1" – hvilket for blot et lille antal rækker måske ikke er et problem, men for store eller flygtige resultatsæt kan det have en væsentlig indvirkning på forespørgselsplanens kvalitet. Nedenfor er et skærmbillede af en operatørs estimat på 1 række i forhold til de faktiske 1.600.000 rækker fra @charge tabelvariabel:

Hvis dette er din rodårsag, vil du være klogt i at udforske alternativer som midlertidige tabeller og eller permanente iscenesættelsestabeller, hvor det er muligt.
Scalar og MSTV UDF'er
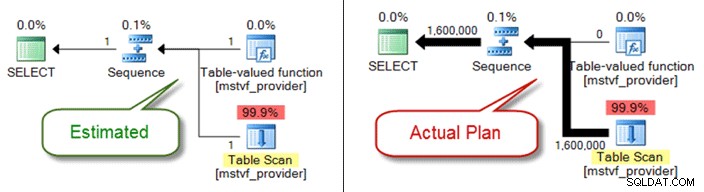
I lighed med tabelvariable er tabelværdi- og skalarfunktioner med flere sætninger en sort boks fra et kardinalitetsestimateringsperspektiv. Hvis du støder på problemer med plankvalitet på grund af dem, kan du overveje inline-tabelfunktioner som et alternativ – eller endda trække funktionsreferencen helt ud og blot henvise direkte til objekter.
Nedenfor viser en estimeret kontra faktisk plan, når du bruger en funktion med flere sætninger i tabelværdien:
Problem med datatype
Implicitte datatypeproblemer i forbindelse med søge- og joinbetingelser kan forårsage problemer med kardinalitetsestimater. De kan også i det skjulte tære på ressourcer på serverniveau (CPU, I/O, hukommelse), så det er vigtigt at tage fat på dem, når det er muligt.
Komplekse prædikater
Du har sikkert set dette mønster før – en forespørgsel med en WHERE klausul, der har hver tabelkolonnereference pakket ind i forskellige funktioner, sammenkædningsoperationer, matematiske operationer og mere. Og selvom ikke al funktionsindpakning udelukker korrekte kardinalitetsestimater (såsom for LOWER , UPPER og GETDATE ) der er masser af måder at begrave dit prædikat til det punkt, at forespørgselsoptimeringsværktøjet ikke længere kan foretage nøjagtige estimater.
Forespørgselskompleksitet
I lighed med begravede prædikater, er dine forespørgsler ekstraordinært komplekse? Jeg er klar over, at "kompleks" er et subjektivt udtryk, og din vurdering kan variere, men de fleste kan være enige om, at indlejring af visninger i visninger i visninger, der refererer til overlappende tabeller, sandsynligvis ikke er optimal - især når det kombineres med 10+ tabelsammenføjninger, funktionsreferencer og begravede prædikater. Selvom forespørgselsoptimeringsværktøjet gør et beundringsværdigt stykke arbejde, er det ikke magi, og hvis du har betydelige skævheder, kan forespørgselskompleksitet (schweizerkniv-forespørgsler) helt sikkert gøre det næsten umuligt at udlede nøjagtige rækkeestimater for operatører.
Distribuerede forespørgsler
Bruger du distribuerede forespørgsler med linkede servere, og du ser betydelige problemer med kardinalitetsestimater? Hvis det er tilfældet, skal du sørge for at kontrollere de tilladelser, der er knyttet til den linkede server-principal, der bruges til at få adgang til dataene. Uden minimum db_ddladmin fast databaserolle for den linkede serverkonto, denne mangel på synlighed for fjernstatistikker på grund af utilstrækkelige tilladelser kan være kilden til dine problemer med estimering af kardinalitet.
Og der er andre...
Der er andre grunde til, at kardinalitetsestimater kan være skæve, men jeg tror, jeg har dækket de mest almindelige. Nøglepunktet er at være opmærksom på skævhederne i forbindelse med kendte, dårligt ydende forespørgsler. Antag ikke, at planen blev genereret baseret på nøjagtige rækkeoptællingsbetingelser. Hvis disse tal er skæve, skal du prøve at fejlfinde dette først.