I del 1 af denne serie importerede vi SuiteCRM-databasestrukturen til vores online-databasemodelleringsværktøj. Det var da vi så, at modellen indeholder 201 tabeller uden relationer mellem dem. Vi fik en vild flok borde, der så virkelig rodet ud. I denne artikel vil jeg vise dig, hvordan du kan organisere en så stor model.
Lige efter import til Vertabelo ser SuiteCRM-databasemodellen ud som følger:
Modellen virker – men ikke effektivt. Vi bliver nødt til at ændre det for at gøre det virkelig nyttigt. Da vi ønsker at analysere SuiteCRM-databasen efter handlinger udføres på dens GUI, vi skal forstå tabeldefinitioner og relationerne mellem tabeller. Lad os starte med at gruppere tabeller i emneområder og etablere de vigtigste relationer.
Vertabelo tilbyder tre hovedværktøjer til at hjælpe dig med at organisere store diagrammer:
- Fagområder
- Tabeller og visningsgenveje
- Referencegenveje
Jeg vil beskrive dem senere i denne artikel, men du kan også lære mere ved at se denne video.
Trin 1. Deaktiver den automatiske generering af fremmednøgler
Først og fremmest deaktiverer vi den automatiske generering af fremmednøgler. Som standard genererer Vertabelo fremmednøgleattributter, når vi trækker relationer fra en primær tabel til en refereret tabel. Det er normalt en god ting, men ikke her. Vi har allerede attributter, der repræsenterer fremmednøgler. Det, vi mangler, er "rigtige" relationer mellem tabeller. Klik på "Min konto" for at slå denne indstilling fra i topmenuen og find "Personlige præferencer" afsnit.
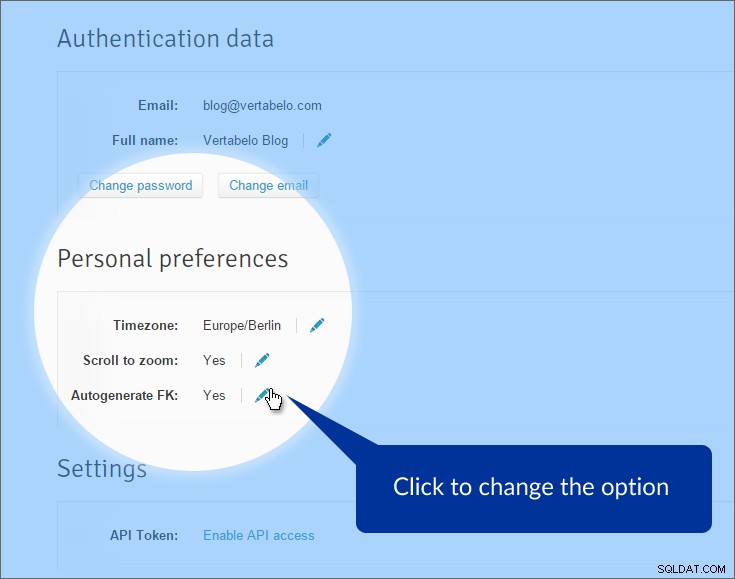
Indstillingen er slået fra. Når vi nu tegner en referencelinje mellem tabeller, oprettes linjen – men vi bliver nødt til at angive, hvilke attributter der bruges, både på den primære og fremmede side.
Trin 2. Gruppér præfikserede tabeller med emneområder
Lad os derefter gruppere nogle tabeller. Vi gør dette ved at bruge Emneområdet værktøj, der gør det muligt at tilknytte tabeller baseret på udvalgte kriterier. I vores tilfælde forsøger vi at identificere tabeller, der enten er relaterede eller en del af den samme proces. Dette vil resultere i grupper som "Opkald", "Møde" og "Kampagner".
Vi kan oprette et emneområde ved at klikke på "Tilføj nyt område" ikon i værktøjskassen:
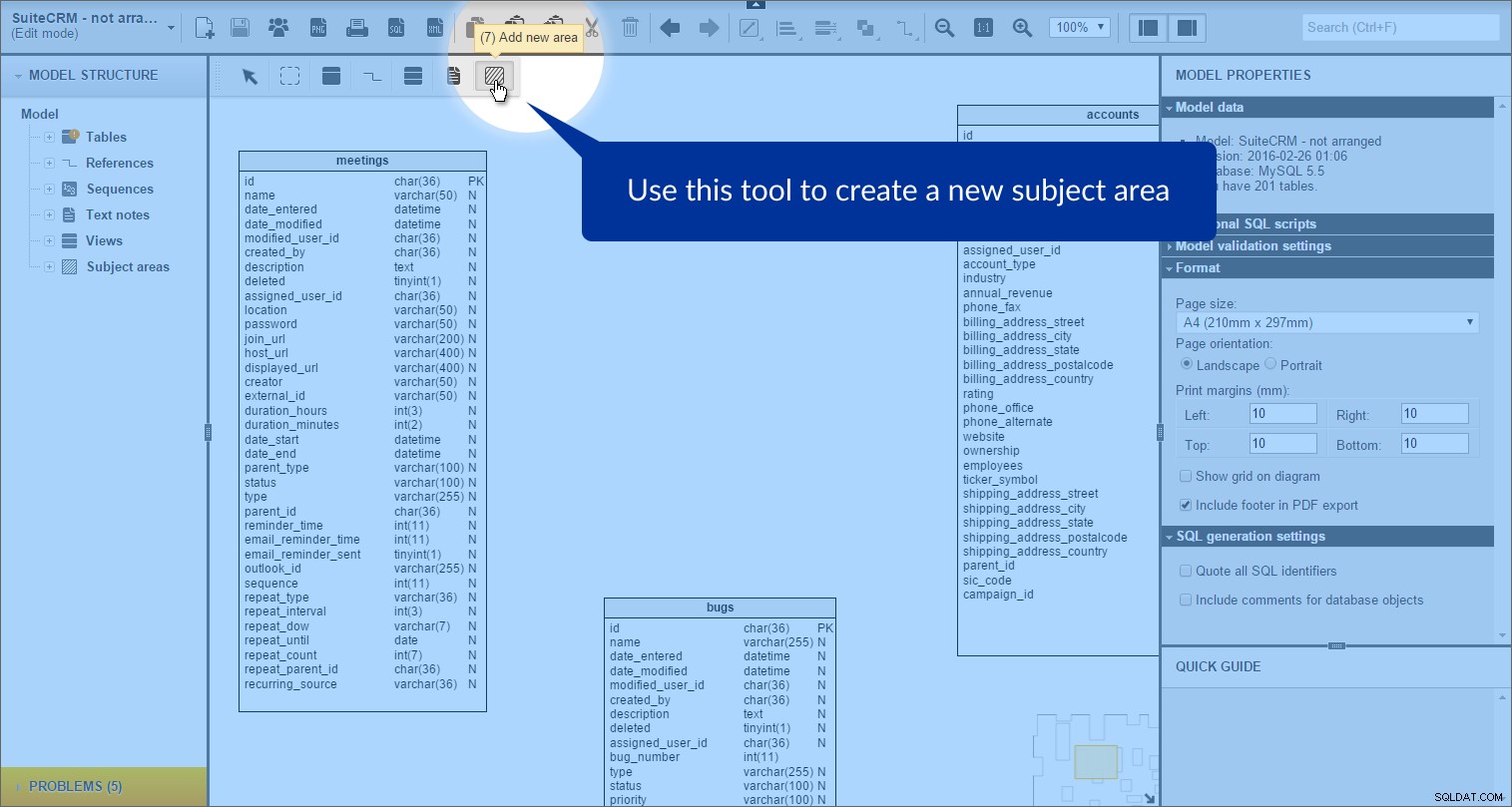
og derefter tegne et rektangel på vores model:
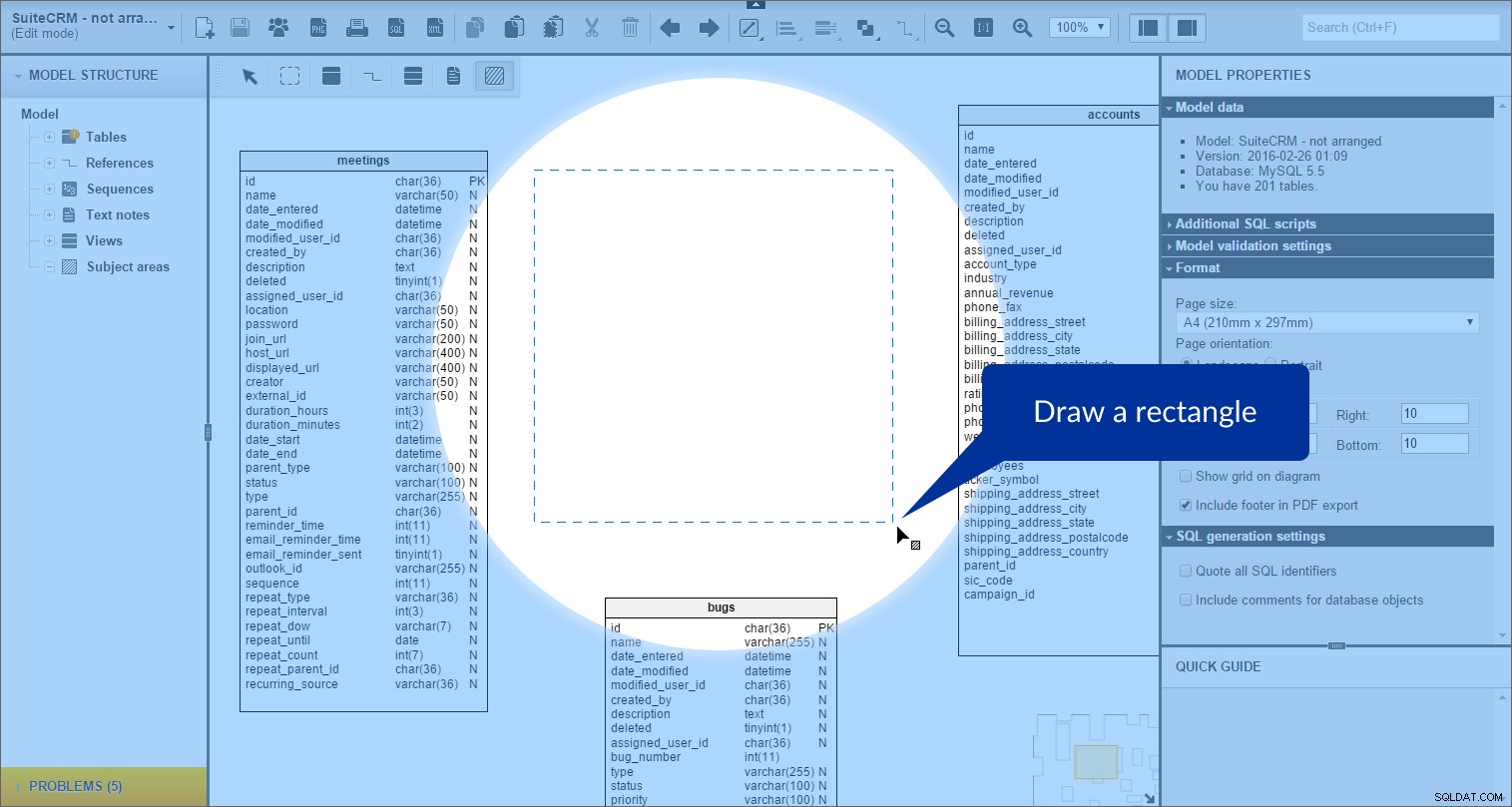
Fagområdet oprettes. Vi kan se det i "Modelstruktur" panel til venstre:
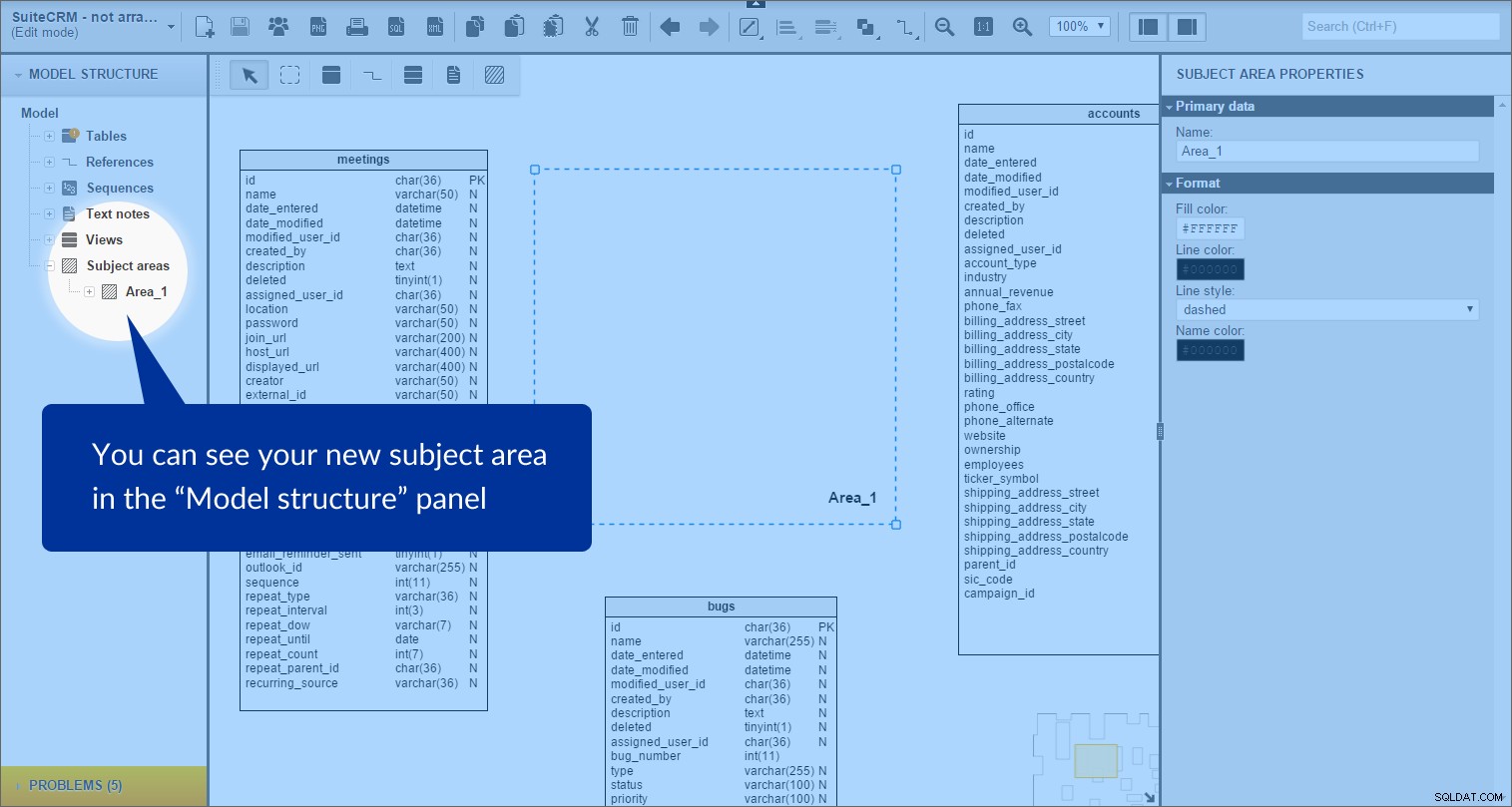
Hvert emneområde indeholder en liste over alle de objekter, der er inden for dets grænser; i dette tilfælde er disse tabeller og referencetyper.
I SuiteCRM er der mange tabeller, der deler et fælles præfiks. Så jeg begyndte at gruppere de præfikserede tabeller sammen. Tag et kig på "acl"-tabellerne som et eksempel. I panelet "Modelstruktur" fandt jeg alle de tabeller, hvis navne startede med "acl_":
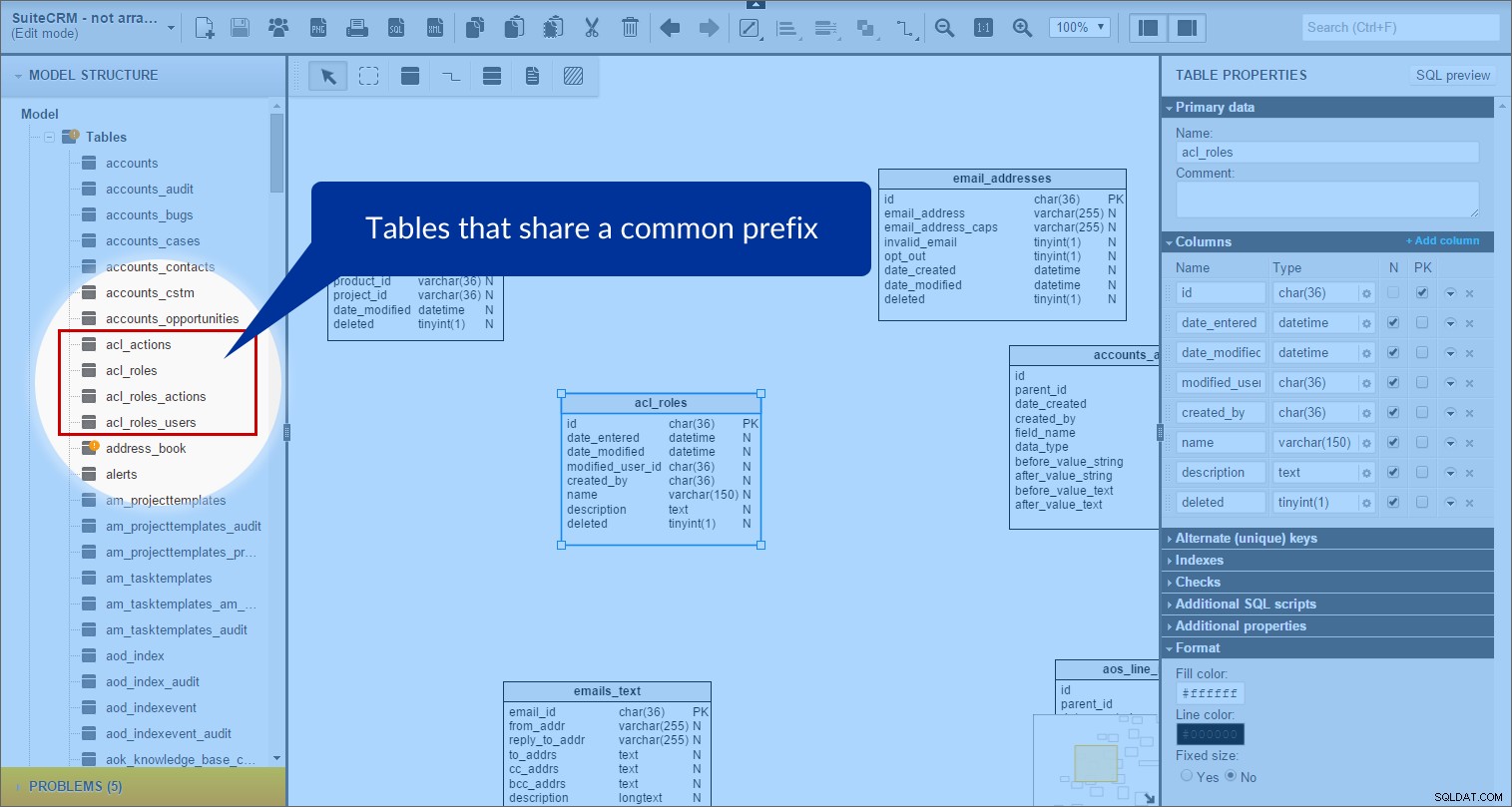
Derefter oprettede jeg "acl"-emneområdet i modellen og trak alle de relevante tabeller ind i det. (For bedre synlighed indstiller jeg baggrundsfarven til lilla.)
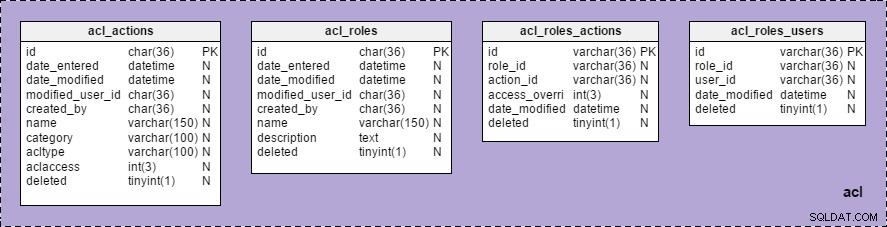
Nu kan vi nu se "acl"-gruppen med en liste over alle tabeller, der hører til den, under "Emneområder" i "Modelstruktur" :
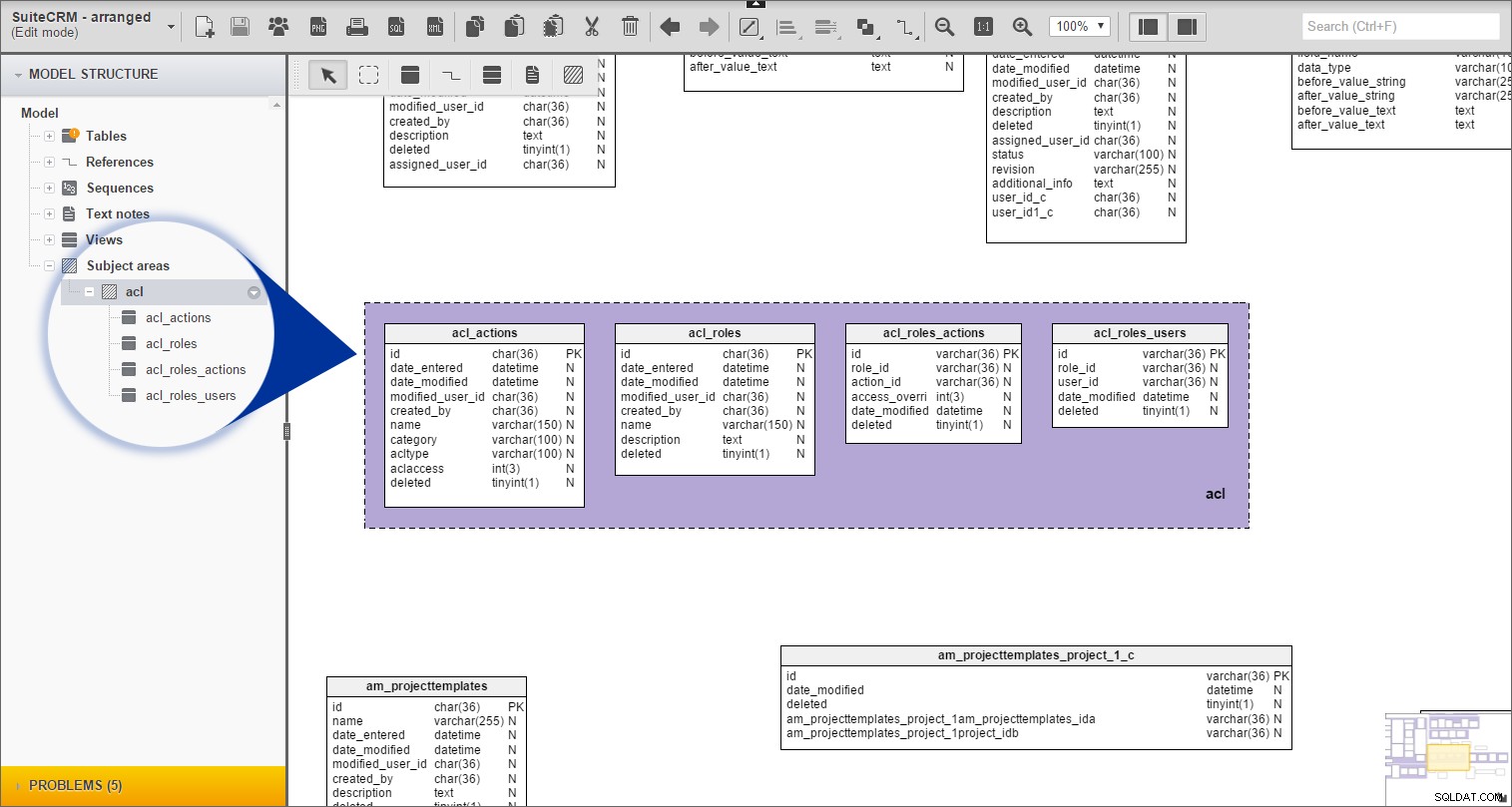
Jeg gentog den samme procedure for alle de resterende tabeller med præfiks.
Trin 3:Arranger de resterende borde.
Samme tabel to gange i diagrammet? Tabelgenveje!
Der er omkring 80 tabeller foran. Efter at have grupperet dem stod jeg tilbage med omkring 120 'vilde' borde. Disse er meningsfulde:De gemmer oplysninger om brugere, klienter, opkald, møder og andre CRM-ting. Det er en masse information, der skal forblive fri, så lad os få disse tabeller sorteret.
Den funktion, jeg fandt mest nyttig til at arrangere disse tabeller, kaldes bordgenveje . Nogle gange vil du bruge samme tabel mere end én gang i en model. (Hvorfor? For at udjævne modellen og undgå overlapning.) Vi kan nemt gøre dette ved at bruge "Kopier" og "Indsæt som genvej" knapper.
Vælg blot den tabel, som du vil oprette en genvej til, og klik på “Kopier” i den øverste værktøjslinje (eller tryk på Ctrl + C ):
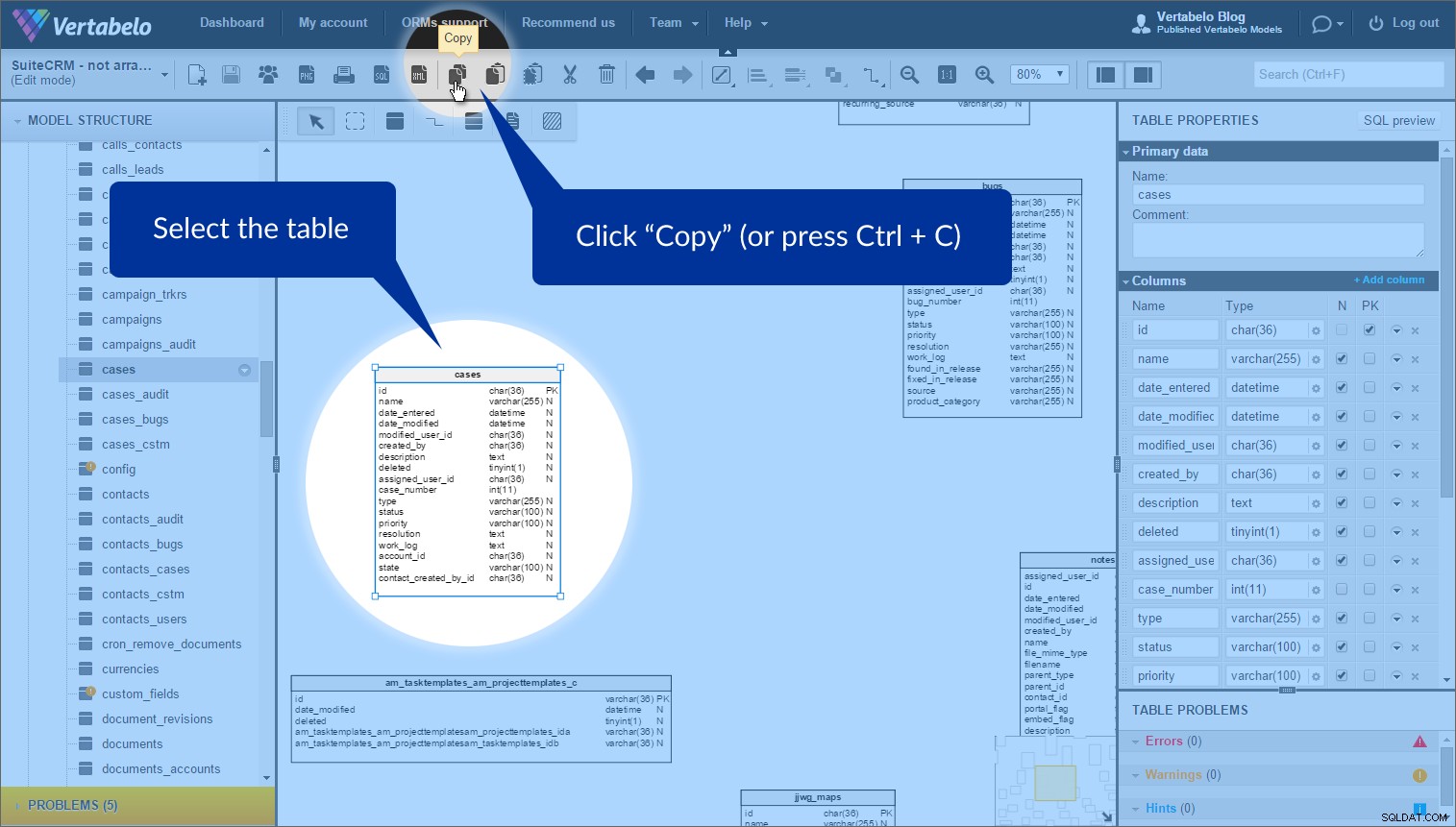
For at oprette en genvej skal du klikke på "Indsæt som genvej" (eller tryk på Ctrl + K ). Derefter vises en ny tabel med en stiplet omrids:
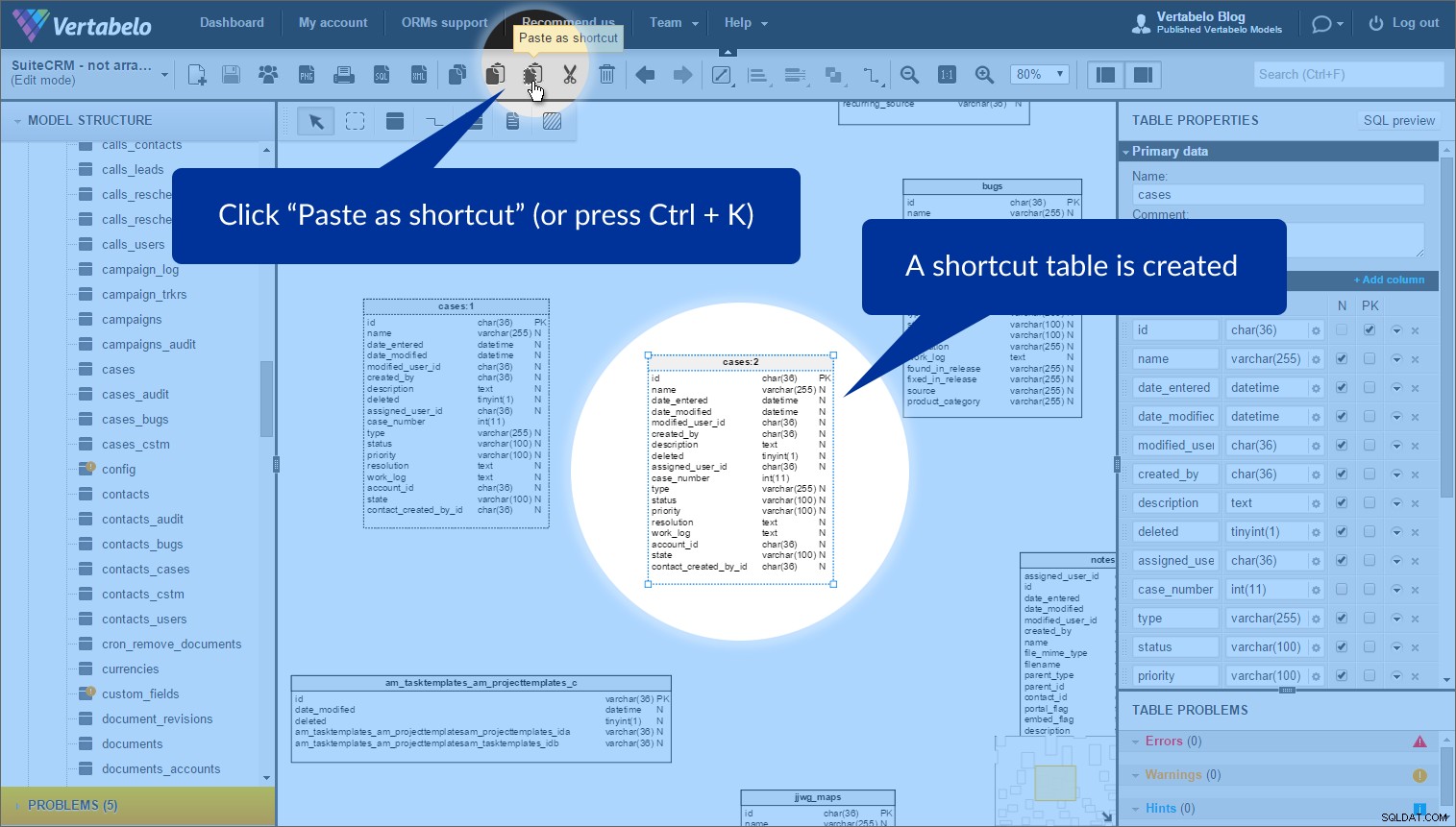
Dette er ikke en kopi af tabellen, men en anden forekomst af den originale tabel. Vi kan placere den hvor som helst i vores model. Jeg brugte forekomster af den samme tabel i forskellige emneområder for at undgå overlappende referencer. Det er værd at nævne, at hver tabelforekomst har et tildelt emneområdenavn (ved siden af navnet), mens det er inden for emneområdet.
Et godt eksempel på, hvordan dette fungerer, er users bord. Den kan findes i "Bruger og konti", "Roller", "Dokumenter" og andre fagområder. Det ser vi senere i modellen.
Jeg bruger i vid udstrækning tabelgenveje, når jeg opretter emneområder med etablerede relationer mellem tabeller. For at se, hvordan dette fungerer, skal du se på emneområdet "Muligheder", som er kortlagt nedenfor. Bemærk, at alle tabeller inden for det pågældende emneområde er navngivet efter denne regel:{tabelnavn} :{emneområdenavn} .
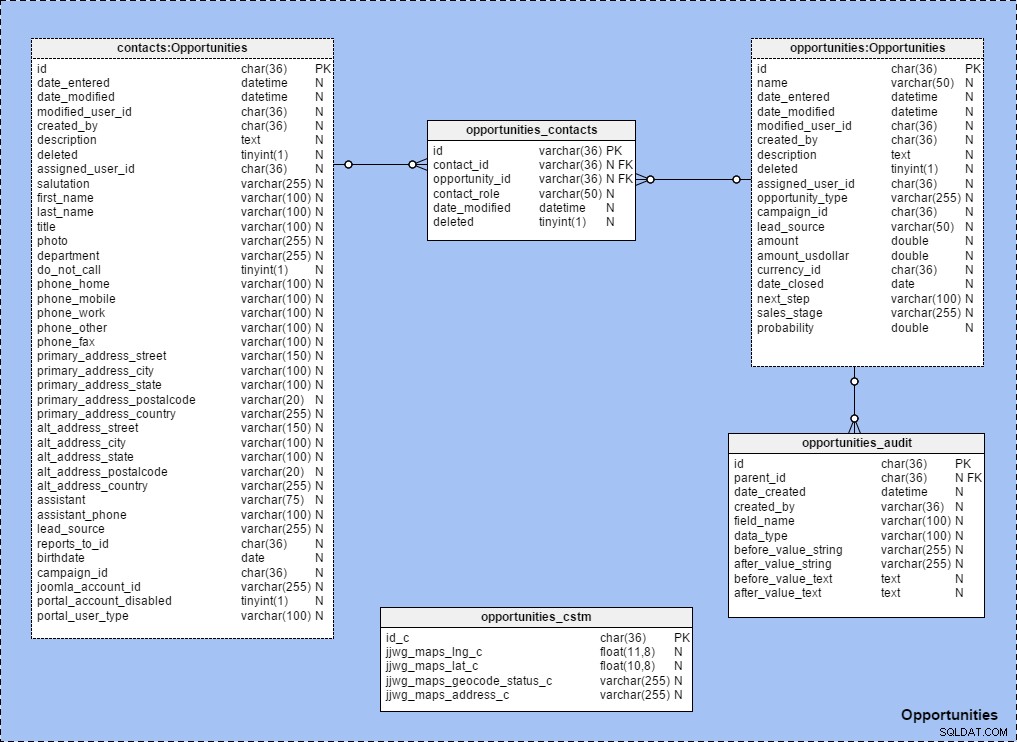
Når vi udvider {emneområdenavn i panelet "Modelstruktur" kan vi tydeligt se, at det indeholder tabeller og referencer:
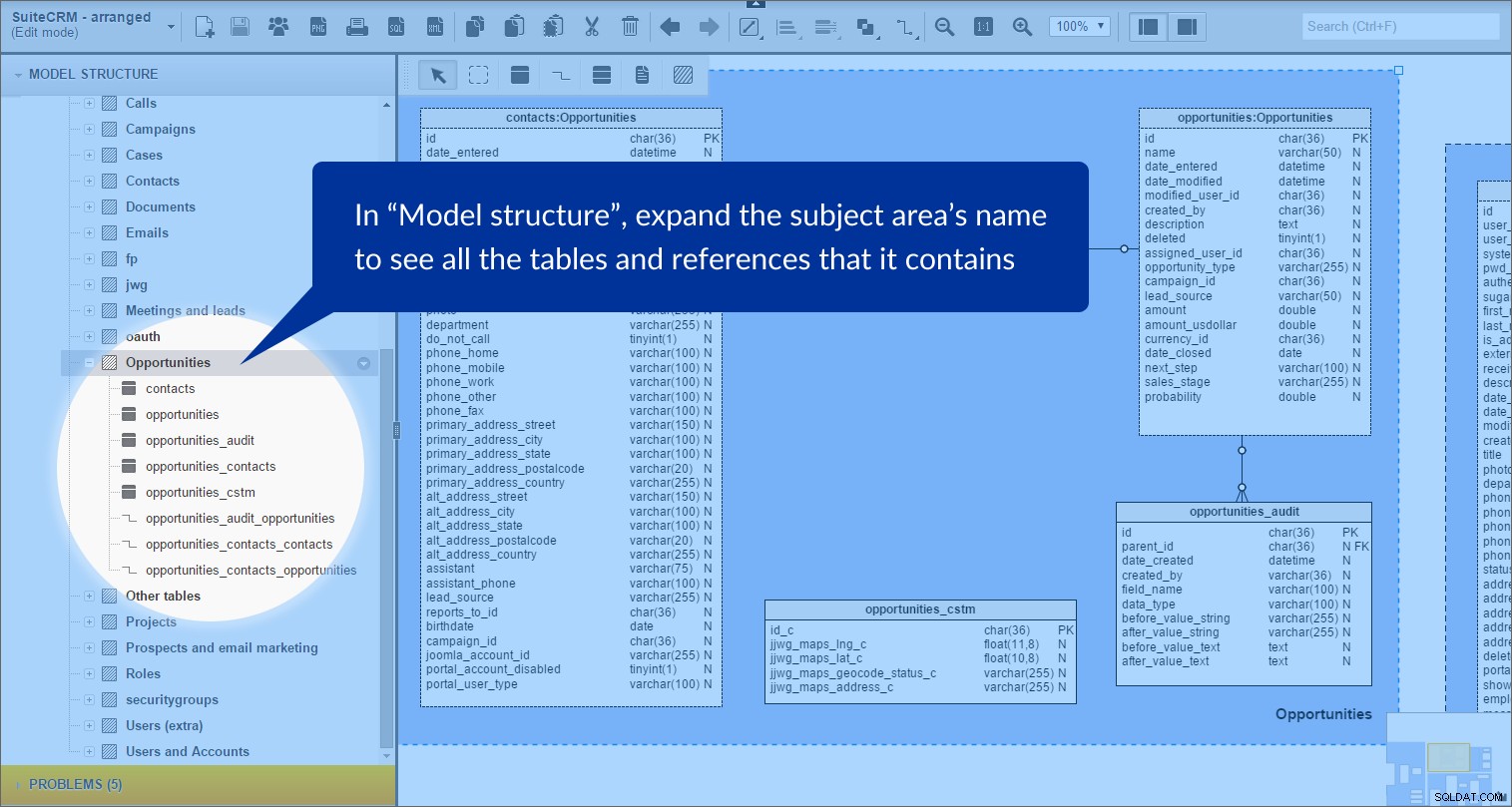
Jeg gjorde dette for følgende emneområder:"Opkald", "Sager", "Kampagne", "Kontakter", "Dokumenter", "Møde og kundeemner", "oauth", "Projekter", "Prospekter og e-mail marketing", "Roller" og "Brugere og konti". Alle disse områder deler en lyseblå baggrund.
De resterende tabeller er grupperet baseret på deres navn og formodede betydning:"E-mails", "Brugere (ekstra)" og "Andre tabeller". Disse grupper har deres baggrundsfarve indstillet til lys rød.
Når du dobbeltklikker på et tabelnavn i navigationstræet, vil visningen zoome til den tabel i modellen og vælge den. Når du zoomer ind ved at rulle med musehjulet, vil visningen zoome i retning af musemarkøren.Den arrangerede model
Jeg brugte de tidligere beskrevne muligheder til at udjævne modellen så meget som muligt, mens jeg grupperede tabeller logisk. Resultatet er 26 fagområder, hvoraf nogle kun indeholder tabeller, mens andre har tabeller og relationer. Lad os få en hurtig gennemgang af hver kategori:
Fagområder, der indeholder tabeller og relationer:
"Opkald", "Kampagner", "Sager", "Kontakter", "Dokumenter", "Møder og kundeemner", "Muligheder", "Projekter", "Prospekter og e-mailmarketing", "Roller", "Brugere og konti"
Alle relationer er sat som ikke-obligatoriske. Dette bevarer informationen om, at disse tabeller er relaterede og via hvilke attribut(er).
Fagområder, der kun indeholder tabeller:
"acl", "am", "aod", "aok", "aop", "aor", "aos", "aow", "E-mails", "fp", "jwg", "oauth", "security_groups" ”, “Brugere ekstra”
Dette betyder ikke, at relationer ikke eksisterer her; de bliver bare ikke understreget.
Emneområdet "Andre tabeller" er for tabeller, der ikke rigtig passer ind i en bestemt gruppe.
Hvordan ser modellen ud?
Den omarrangerede model ser sådan ud:
Der er åbenbart brugt en navnekonvention. Her er en oversigt over de retningslinjer, vi fulgte:
- Tabelnavne er for det meste flertal:
users,contracts,folders,roles,tasks. Nogle tabelnavne er ental, såsomproject. - Den primære nøgle i de fleste tabeller kaldes simpelthen
idog er en char(36)-type. - Når der opstår en en-til-mange-relation, hedder fremmednøglen normalt
parent_id. (Eksempel:contacts_audit.parent_ider en reference tilcontacts.id.) - I mange-til-mange-relationer, "
parent_id" kan ikke bruges som navn for flere kolonner. I stedet bruges et enkelt tabelnavn med suffikset "_id". (Eksempel:contacts_bugs.bug_ider reference tilbug.id.) - Der er situationer, hvor den samme kolonne bruges som en fremmednøgle for flere tabeller. (Eksempel:
calls.parent_ider refereret til id-kolonnen i hver af følgende tabeller:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Jeg har ikke tjekket værdierne i databasen, men mit gæt ville være, at der ikke er de samme nøgleværdier i disse tabeller. Da alle er af typen char(36), er der sandsynligvis brugt en kombination af tabelnavn og autoincrement. Vi tjekker det i kommende artikler.) - Vi bruger de samme navne for kolonner, der har samme betydning i forskellige tabeller. (Eksempel:
modified_user_id,created_byogassigned_user_idkan findes i mange tabeller i modellen. Alle henvises tilusers.id.)
Hvad er det næste?
I de kommende artikler vil vi bruge SuiteCRM GUI og holde øje med de ændringer, som dette forårsager i databasen. Med den information vil vi forsøge at lave ændringer i modellen, omorganisere fagområder og etablere forbindelser, hvor det er nødvendigt. Vi vil også kigge efter andre SuiteCRM-specifikke regler, såsom måden primære nøgler genereres på.
Håndtering af store databasediagrammer er aldrig en nem opgave. Ligesom at bygge et godt fundament for et hjem, vil det give fordele senere at bruge mere tid på det grundlæggende nu. Hvis vi vil analysere modeller som den bag SuiteCRM, er det Sisyphus-stil at analysere, før vi har organiseret modelstrukturen og defineret tabelrelationer.