Lad os starte vores SQL-rejse for at forstå aggregeringsdata i SQL og typer af aggregeringer, herunder simple og glidende aggregeringer.
Før vi hopper til aggregeringerne, er det værd at overveje interessante fakta, som nogle udviklere ofte savner, når det kommer til SQL generelt og aggregeringen i særdeleshed.
I denne artikel refererer SQL til T-SQL, som er Microsoft-versionen af SQL og har flere funktioner end standard SQL.
Matematik bag SQL
Det er meget vigtigt at forstå, at T-SQL er baseret på nogle solide matematiske begreber, selvom det ikke er et stift matematikbaseret sprog.
Ifølge bogen "Microsoft_SQL_Server_2008_T_SQL_Fundamentals" af Itzik Ben-Gan er SQL designet til at forespørge og administrere data i et relationelt databasestyringssystem (RDBMS).
Selve det relationelle databasestyringssystem er baseret på to solide matematiske grene:
- Mængdeteori
- Prdikatlogik
Mængdeteori
Mængdeori, som navnet indikerer, er en gren af matematikken om mængder, som også kan kaldes samlinger af bestemte distinkte objekter.
Kort sagt, i mængdeteori tænker vi på ting eller objekter som en helhed på samme måde, som vi tænker på en individuel genstand.
For eksempel er en bog et sæt af alle de bestemte særskilte bøger, så vi tager en bog som en helhed, hvilket er nok til at få detaljer om alle bøgerne i den.
Prdikatlogik
Prædikatlogik er en boolsk logik, som returnerer sand eller falsk afhængigt af variablernes betingelse eller værdier.
Prædikatlogik kan bruges til at håndhæve integritetsregler (prisen skal være større end 0,00) eller filtrere data (hvor prisen er mere end 10,00), men i forbindelse med T-SQL har vi tre logiske værdier som følger:
- Sandt
- Falsk
- Ukendt (Nul)
Dette kan illustreres som følger:
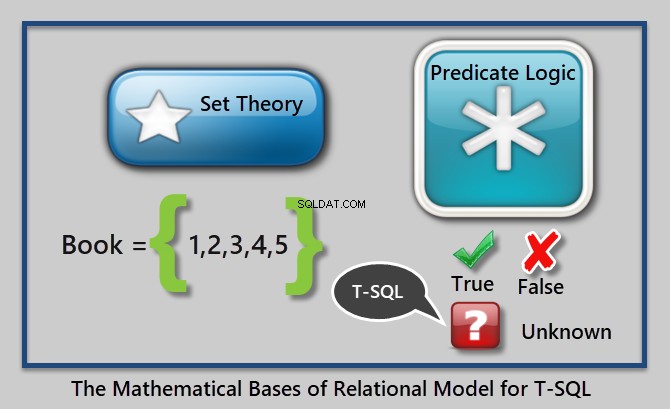
Et eksempel på et prædikat er "Hvor prisen på bogen er større end 10,00".
Det er nok om matematik, men husk, at jeg vil henvise til det senere i artiklen.
Hvorfor er det nemt at aggregere data i SQL
At aggregere data i SQL i sin enkleste form handler om at få at vide om totalerne på én gang.
For eksempel, hvis vi har en kundetabel, som indeholder en liste over alle kunderne sammen med deres detaljer, kan aggregerede data fra kundetabellen give os det samlede antal kunder, vi har.
Som diskuteret tidligere, tænker vi på et sæt som et enkelt element, så vi anvender simpelthen en aggregeret funktion på tabellen for at få totalerne.
Da SQL oprindeligt er et sætbaseret sprog (som diskuteret tidligere), så er det relativt nemmere at anvende aggregerede funktioner på det sammenlignet med andre sprog.
For eksempel, hvis vi har en produkttabel, som har registreringer af alle produkterne i databasen, kan vi med det samme anvende tællefunktionen på en produkttabel for at få det samlede antal produkter i stedet for at tælle dem en efter en i en løkke.
Dataaggregationsopskrift
For at aggregere data i SQL har vi som minimum brug for følgende ting:
- Data (tabel) med kolonner, der giver mening, når de er aggregerede
- En samlet funktion, der skal anvendes på dataene
Forberedelse af prøvedata (tabel)
Lad os tage et eksempel på en simpel rækkefølgetabel, som indeholder tre ting (kolonner):
- Ordrenummer (OrderId)
- Dato, hvor ordren blev afgivet (OrderDate)
- Beløbet for ordren (TotalAmount)
Lad os oprette AggregateSample-databasen for at komme videre:
-- Create aggregate sample database CREATE DATABASE AggregateSample
Opret nu ordretabellen i eksempeldatabasen som følger:
-- Create order table in the aggregate sample database USE AggregateSample CREATE TABLE SimpleOrder (OrderId INT PRIMARY KEY IDENTITY(1,1), OrderDate DATETIME2, TotalAmount DECIMAL(10,2) )
Populering af prøvedata
Udfyld tabellen ved at tilføje en række:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ); GO
Lad os se på tabellen nu:
-- View order table SELECT OrderId ,OrderDate ,TotalAmount FROM SimpleOrder
Bemærk venligst, at jeg bruger dbForge Studio til SQL Server i denne artikel, så kun output-looket kan variere, hvis du kører den samme kode i SSMS (SQL Server Management Studio), der er ingen forskel, hvad angår scripts og deres resultater.
Grundlæggende aggregerede funktioner
De grundlæggende aggregerede funktioner, der kan anvendes på tabellen, er som følger:
- Sum
- Tæl
- Min.
- Maks.
- Gennemsnit
Aggregerende enkeltoptagelsestabel
Nu er det interessante spørgsmål, "kan vi aggregere (sum eller tælle) data (registreringer) i en tabel, hvis den kun har én række som i vores tilfælde?" Svaret er "Ja", det kan vi, selvom det ikke giver meget mening, men det kan hjælpe os med at forstå, hvordan data bliver klar til aggregering.
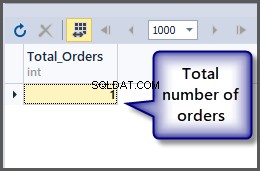
For at få det samlede antal ordrer, bruger vi funktionen count() med tabellen, som diskuteret tidligere, vi kan simpelthen anvende aggregatfunktionen på tabellen, da SQL er et sæt baseret sprog og operationer kan anvendes på et sæt direkte.
-- Getting total number of orders placed so far SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
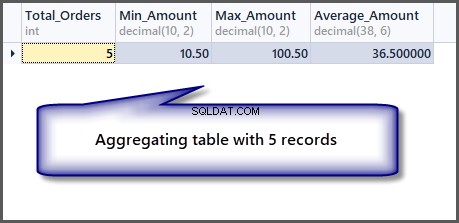
Hvad nu med ordren med et minimum, maksimum og gennemsnitsbeløb for en enkelt post:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
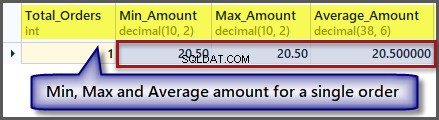
Som vi kan se fra outputtet, er minimum-, maksimum- og gennemsnitsbeløbet det samme, hvis vi har en enkelt post, så det er muligt at anvende en aggregeret funktion på en enkelt post, men det giver os de samme resultater.
Vi har brug for mindst mere end én registrering for at give mening i de aggregerede data.
Tabel med sammenlægning af flere poster
Lad os nu tilføje yderligere fire poster som følger:
INSERT INTO dbo.SimpleOrder ( OrderDate ,TotalAmount ) VALUES ( '20180101' -- OrderDate - datetime2 ,20.50 -- TotalAmount - decimal(10, 2) ), ( '20180102' -- OrderDate - datetime2 ,30.50 -- TotalAmount - decimal(10, 2) ), ( '20180103' -- OrderDate - datetime2 ,10.50 -- TotalAmount - decimal(10, 2) ), ( '20180110' -- OrderDate - datetime2 ,100.50 -- TotalAmount - decimal(10, 2) ); GO
Tabellen ser nu ud som følger:
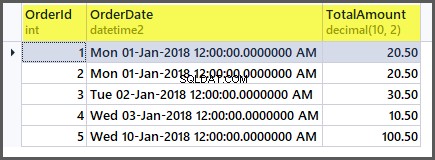
Hvis vi anvender de samlede funktioner på tabellen nu, vil vi få gode resultater:
-- Getting order with minimum amount, maximum amount, average amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) Average_Amount FROM SimpleOrder
Grupper aggregerede data
Vi kan gruppere de aggregerede data efter en hvilken som helst kolonne eller et sæt kolonner for at få aggregater baseret på den kolonne.
For eksempel, hvis vi ønsker at vide det samlede antal ordrer pr. dato, vi skal gruppere tabellen efter dato ved at bruge Group by-sætning som følger:
-- Getting total orders per date SELECT OrderDate ,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate
Udgangen er som følger:
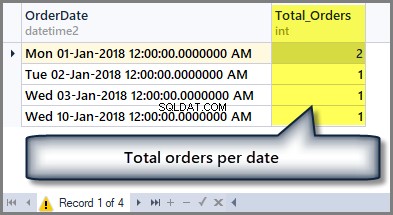
Så hvis vi ønsker at se summen af hele ordrebeløbet, vi kan ganske enkelt anvende sumfunktionen på kolonnen samlet beløb uden nogen gruppering som følger:
-- Sum of all the orders amount SELECT SUM(TotalAmount) AS Sum_of_Orders_Amount FROM SimpleOrder
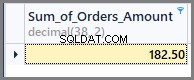
For at få summen af ordrebeløb pr. dato tilføjer vi blot gruppe efter dato til ovenstående SQL-sætning som følger:
-- Sum of all the orders amount per date SELECT OrderDate ,SUM(TotalAmount) AS Sum_of_Orders FROM SimpleOrder GROUP BY OrderDate
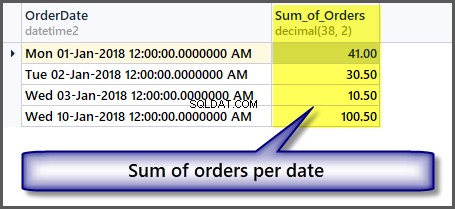
Få totaler uden at gruppere data
Vi kan med det samme få totaler såsom samlede ordrer, maksimum ordrebeløb, minimum ordrebeløb, sum af ordrebeløb, gennemsnitlig ordrebeløb uden behov for at gruppere det, hvis aggregeringen er beregnet til alle tabellerne.
-- Getting order with minimum amount, maximum amount, average amount, sum of amount and total orders SELECT COUNT(*) AS Total_Orders ,MIN(TotalAmount) AS Min_Amount ,MAX(TotalAmount) AS Max_Amount ,AVG(TotalAmount) AS Average_Amount ,SUM(TotalAmount) AS Sum_of_Amount FROM SimpleOrder
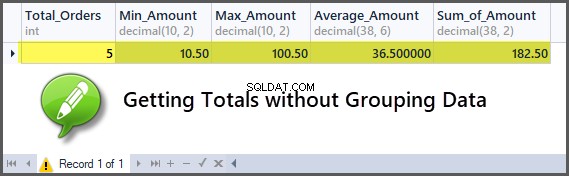
Tilføjelse af kunder til ordrerne
Lad os tilføje noget sjov ved at tilføje kunder i vores tabel. Vi kan gøre dette ved at oprette en anden tabel over kunder og videregive kunde-id til ordretabellen, men for at holde det simpelt og for at håne datavarehus-stilen (hvor tabeller er denormaliserede), tilføjer jeg kolonnen kundenavn i ordretabellen som følger :
-- Adding CustomerName column and data to the order table ALTER TABLE SimpleOrder ADD CustomerName VARCHAR(40) NULL GO UPDATE SimpleOrder SET CustomerName = 'Eric' WHERE OrderId = 1 GO UPDATE SimpleOrder SET CustomerName = 'Sadaf' WHERE OrderId = 2 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 3 GO UPDATE SimpleOrder SET CustomerName = 'Asif' WHERE OrderId = 4 GO UPDATE SimpleOrder SET CustomerName = 'Peter' WHERE OrderId = 5 GO
Få samlede ordrer pr. kunde
Kan du nu gætte, hvordan man får samlede ordrer pr. kunde? Du skal gruppere efter kunde (CustomerName) og anvende den samlede funktion count() på alle posterne som følger:
-- Total orders per customer
SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder
GROUP BY CustomerName
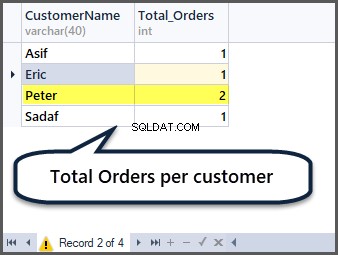
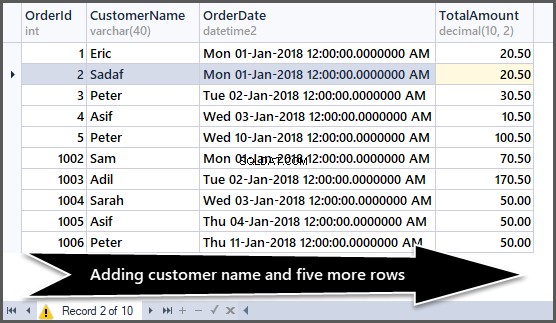
Tilføjelse af yderligere fem poster til ordretabellen
Nu skal vi tilføje fem rækker mere til den simple rækkefølge tabel som følger:
-- Adding 5 more records to order table
INSERT INTO SimpleOrder (OrderDate, TotalAmount, CustomerName)
VALUES
('01-Jan-2018', 70.50, 'Sam'),
('02-Jan-2018', 170.50, 'Adil'),
('03-Jan-2018',50.00,'Sarah'),
('04-Jan-2018',50.00,'Asif'),
('11-Jan-2018',50.00,'Peter')
GO
Tag et kig på dataene nu:
-- Viewing order table after adding customer name and five more rows SELECT OrderId,CustomerName,OrderDate,TotalAmount FROM SimpleOrder GO
Få samlede ordrer pr. kunde sorteret efter maksimum til minimum ordrer
Hvis du er interesseret i de samlede ordrer pr. kunde sorteret efter maksimum til minimum ordrer, er det slet ikke en dårlig idé at dele dette op i mindre trin som følger:
-- (1) Getting total orders SELECT COUNT(*) AS Total_Orders FROM SimpleOrder
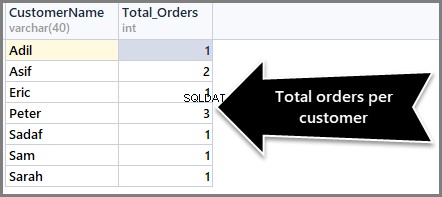
-- (2) Getting total orders per customer SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName
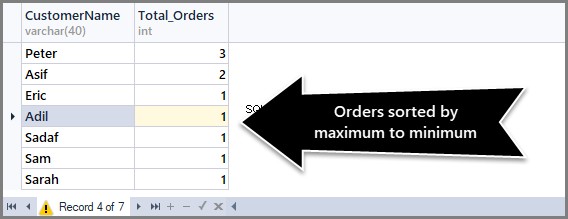
For at sortere ordrer tæller fra maksimum til minimum, skal vi bruge Ordre efter DESC (faldende rækkefølge) klausulen med count() i slutningen som følger:
-- (3) Getting total orders per customer from maximum to minimum orders SELECT CustomerName,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY CustomerName ORDER BY COUNT(*) DESC
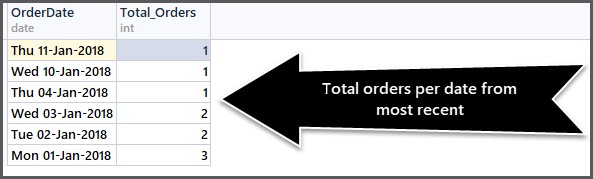
Få det samlede antal ordrer pr. dato sorteret efter seneste ordre først
Ved at bruge ovenstående metode kan vi nu finde ud af de samlede ordrer pr. dato sorteret efter seneste ordre først som følger:
-- Getting total orders per date from most recent first SELECT CAST(OrderDate AS DATE) AS OrderDate,COUNT(*) AS Total_Orders FROM SimpleOrder GROUP BY OrderDate ORDER BY OrderDate DESC
CAST-funktionen hjælper os med kun at få datodelen. Outputtet er som følger:
Du kan bruge så mange kombinationer som muligt, så længe de giver mening.
Kørende aggregationer
Nu hvor vi er fortrolige med at anvende aggregerede funktioner på vores data, lad os gå videre til den avancerede form for aggregering, og en sådan aggregering er den løbende aggregering.
Kørende aggregeringer er de aggregeringer, der anvendes på en delmængde af data i stedet for på hele datasættet, hvilket hjælper os med at skabe små vinduer på dataene.
Hidtil har vi set alle aggregerede funktioner anvendes på alle rækker i tabellen, som kan grupperes efter en kolonne som ordredato eller kundenavn, men med kørende aggregeringer har vi frihed til at anvende aggregerede funktioner uden at gruppere hele datasæt.
Det betyder naturligvis, at vi kan anvende aggregatfunktionen uden at bruge Group By-klausulen, hvilket er noget mærkeligt for de SQL-begyndere (eller nogle gange overser nogle udviklere dette), som ikke er fortrolige med vinduesfunktionerne og kørende aggregeringer.
Windows på data
Som tidligere nævnt anvendes den kørende aggregering på et undersæt af datasæt eller (med andre ord) på små vinduer med data.
Tænk på vinduer som et sæt i et sæt eller en tabel(r) i en tabel. Et godt eksempel på vinduer på data i vores tilfælde er, at vi har ordretabellen, som indeholder ordrer afgivet på forskellige datoer, så hvad hvis hver dato er et separat vindue, så kan vi anvende aggregerede funktioner på hvert vindue på samme måde, som vi anvendte til bordet.
Hvis vi sorterer ordretabellen (SimpleOrder) efter ordredato (OrderDate) som følger:
-- View order table sorted by order date
SELECT so.OrderId
,so.OrderDate
,so.TotalAmount
,so.CustomerName FROM SimpleOrder so
ORDER BY so.OrderDate
Windows på data klar til at køre sammenlægninger kan ses nedenfor:

Vi kan også betragte disse vinduer eller undersæt som seks miniordre datobaserede tabeller og aggregater kan anvendes på hver af disse minitabeller.
Brug af partition af inde i OVER() klausul
Kørende aggregeringer kan anvendes ved at partitionere tabellen ved hjælp af "Partition by" inde i OVER()-sætningen.
For eksempel, hvis vi ønsker at opdele rækkefølgetabellen efter datoer, såsom at hver dato er en undertabel eller et vindue på datasættet, så skal vi opdele data efter ordredato, og dette kan opnås ved at bruge en aggregeret funktion såsom COUNT( ) med OVER() og partitioner med inde i OVER() som følger:
-- Running Aggregation on Order table by partitioning by dates SELECT OrderDate, Total_Orders=COUNT(*) OVER(PARTITION BY OrderDate) FROM SimpleOrder

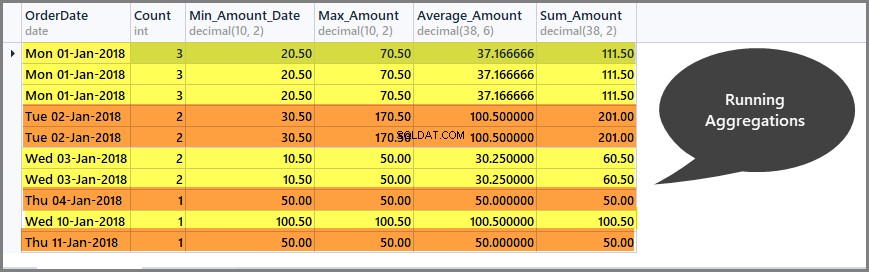
Hent løbende totaler pr. dato vindue (partition)
Kørende aggregeringer hjælper os med at begrænse aggregeringsomfanget til kun det definerede vindue, og vi kan få løbende totaler pr. vindue som følger:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per date window (partition by date) SELECT CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY OrderDate), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY OrderDate) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY OrderDate) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY OrderDate), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY OrderDate) FROM SimpleOrder
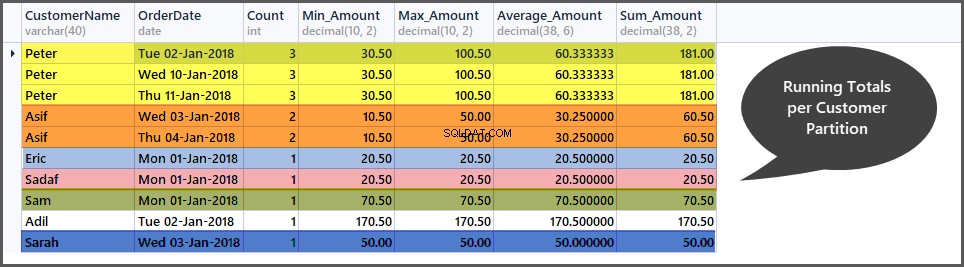
Få løbende totaler pr. kundevindue (partition)
Ligesom de løbende totaler pr. datovindue, kan vi også beregne løbende totaler pr. kundevindue ved at opdele ordresættet (tabellen) i små kundeundersæt (partitioner) som følger:
-- Getting total orders, minimum amount, maximum amount, average amount and sum of all amounts per customer window (partition by customer) SELECT CustomerName, CAST (OrderDate AS DATE) AS OrderDate, Count=COUNT(*) OVER (PARTITION BY CustomerName), Min_Amount=MIN(TotalAmount) OVER (PARTITION BY CustomerName) , Max_Amount=MAX(TotalAmount) OVER (PARTITION BY CustomerName) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName), Sum_Amount=SUM(TotalAmount) OVER (PARTITION BY CustomerName) FROM SimpleOrder ORDER BY Count DESC,OrderDate
Glidende aggregationer
Glidende sammenlægninger er de sammenlægninger, der kan anvendes på rammerne i et vindue, hvilket betyder, at man indsnævrer omfanget yderligere inden for vinduet (partition).
Med andre ord giver løbende totaler os totaler (sum, gennemsnit, min, maks, antal) for hele vinduet (delmængde), vi opretter i en tabel, mens glidende totaler giver os totaler (sum, gennemsnit, min, maks, tæller) for rammen (undermængde af undermængde) inden for vinduet (undermængde) i tabellen.
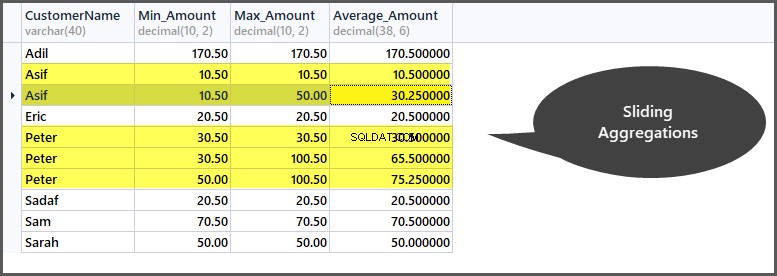
For eksempel, hvis vi opretter et vindue på data baseret på (opdeling efter kunde) kunde, så kan vi se, at kunden "Peter" har tre poster i sit vindue, og alle sammenlægninger anvendes på disse tre poster. Hvis vi nu kun vil oprette en ramme for to rækker ad gangen, betyder det, at aggregeringen bliver yderligere indsnævret, og at den derefter anvendes på den første og anden række og derefter den anden og tredje række og så videre.
Brug af RÆKKER FOREGÅENDE med Order By inde i OVER()-klausul
Glidende aggregeringer kan anvendes ved at tilføje RÆKKER
Hvis vi f.eks. kun ønsker at aggregere data for to rækker ad gangen for hver kunde, skal vi bruge glidende aggregeringer til ordretabellen som følger:
-- Getting minimum amount, maximum amount, average amount per frame per customer window SELECT CustomerName, Min_Amount=Min(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING), Max_Amount=Max(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) , Average_Amount=AVG(TotalAmount) OVER (PARTITION BY CustomerName ORDER BY OrderDate ROWS 1 PRECEDING) FROM SimpleOrder so ORDER BY CustomerName
For at forstå, hvordan det virker, lad os se på den originale tabel i sammenhæng med rammer og vinduer:
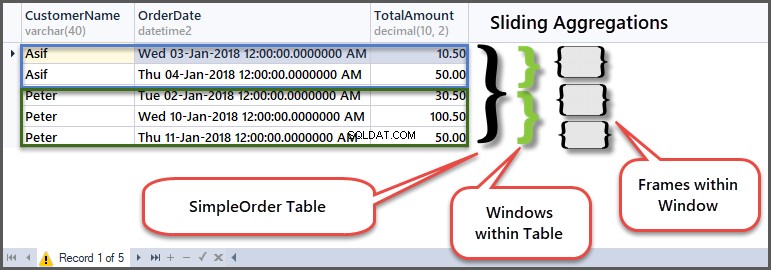
I den første række af kunden Peter vinduet afgav han en ordre med beløbet 30,50, da dette er begyndelsen af rammen inden for kundevinduet, så min og max er det samme, da der ikke er nogen tidligere række at sammenligne med.
Dernæst forbliver minimumsbeløbet det samme, men maksimumbeløbet bliver 100,50, da beløbet i den foregående række (første række) er 30,50, og dette rækkebeløb er 100,50, så maksimum af de to er 100,50.
Når du derefter flytter til den tredje række, vil sammenligningen finde sted med den anden række, så minimumsbeløbet af de to er 50,00 og det maksimale antal af de to rækker er 100,50.
MDX Year to Date (YTD) funktion og løbende aggregationer
MDX er et flerdimensionelt udtrykssprog, der bruges til at forespørge multidimensionelle data (såsom kube) og bruges i business intelligence (BI)-løsninger.
Ifølge https://docs.microsoft.com/en-us/sql/mdx/ytd-mdx fungerer funktionen Year to Date (YTD) i MDX på samme måde som kørende eller glidende aggregeringer. For eksempel viser YTD ofte brugt i kombination med ingen angivet parameter en løbende total til dato.
Det betyder, at hvis vi anvender denne funktion på år, giver den alle årsdata, men hvis vi borer ned til marts, vil det give os alle totalerne fra begyndelsen af året til marts og så videre.
Dette er meget nyttigt i SSRS-rapporter.
Ting at gøre
Det er det! Du er klar til at lave nogle grundlæggende dataanalyse efter at have gennemgået denne artikel, og du kan forbedre dine færdigheder yderligere ved at gøre følgende:
- Prøv venligst at skrive et kørende aggregeringsscript ved at oprette vinduer på andre kolonner, f.eks. Samlet beløb.
- Prøv også at skrive et glidende aggregeret script ved at oprette rammer på andre kolonner, f.eks. Samlet beløb.
- Du kan tilføje flere kolonner og poster til tabellen (eller endnu flere tabeller) for at prøve andre aggregeringskombinationer.
- De eksempler på scripts, der er nævnt i denne artikel, kan omdannes til lagrede procedurer, der skal bruges i SSRS-rapporter bag datasæt(er).
Referencer:
- Ytd (MDX)
- dbForge Studio til SQL Server