Uanset hvilken side af ligningen du er på, er det nogle gange svært at finde en kvalificeret person til et bestemt job. I dette indlæg ser vi på en datamodel, der skal hjælpe rekrutterere og HR-afdelinger med at holde sig organiseret under ansættelsesprocessen.
De fleste af os har været involveret i ansættelsesprocessen – oftest som jobansøger. Vi kan dog også finde os selv involveret på ansættelsessiden, måske ved at teste ansøgerens tekniske viden. Rekrutteringsprocessen tager en vis tid, og gruppen af ansøgere bliver løbende mindre, efterhånden som vi kommer tættere på den endelige beslutning. Resultatet bør være valget af den bedste person til jobbet.
Rekruttering i sig selv er ret kompliceret, så vi vil diskutere en ret omfattende datamodel til at dække alle aspekter af processen. Læn dig tilbage i stolen og nyd dagens artikel!
Sådan fungerer rekrutteringsprocessen
De fleste dele af rekrutteringsprocessen er almindelig kendt, men vi vil diskutere præcis, hvordan det fungerer, før vi går videre til datamodellen.
-
Opdagelse af et behov
Dette er et absolut must i rekrutteringsprocessen; der vil ikke være nogen proces, hvis ledelsen ikke er opmærksom på behovet for at ansætte en ny medarbejder. Det behov kan være resultatet af at starte en ny virksomhed, vækst i en eksisterende virksomhed eller en nuværende medarbejders afgang.
Medmindre en virksomhed har strengt definerede stillinger (f.eks. banker), er det ikke altid let at bestemme, hvornår man skal ansætte en ny medarbejder. At tale med medarbejdere og se en masse overarbejde kan anspore en nyansættelse. Interne eller eksterne regler kan også kræve, at visse stillinger kun gives til personer med en specifik kompetence og relevant erhvervserfaring (f.eks. intern revisor).
-
Skitsering af stillingen og dens nødvendige færdigheder
For at få en idé om dette trin, tænk på en rigtig velskrevet jobbeskrivelse. Den indeholder:
- En liste over alle opgaver relateret til jobbet
- Minimum uddannelses- og erhvervserfaringskvalifikationer
- Specifikke færdigheder afgørende for jobfunktioner
- Yderligere eller foretrukne færdigheder
- En oversigt over, hvad arbejdsgiveren forventer af ansøgeren, og hvad ansøgeren kan forvente af dette job
- En lønklasse og måske en fordelspakke
Disse oplysninger er vigtige for både rekrutterere og ansøgere. Det nytter ikke noget at invitere ti ansøgere til udvælgelsesprocessen, hvis ingen af dem vil være tilfredse med det økonomiske tilbud. Og jo mere detaljeret jobbeskrivelsen er, jo lettere bliver det at tiltrække kvalificerede ansøgere.
-
Definition af, hvem der skal styre processen, og hvornår hver opgave skal ske
Det næste trin er at definere specifikke datoer for, hvornår hver del af processen skal ske. Virksomheder kan også tildele medarbejdere til hvert trin. Hvis virksomheden har en personaleafdeling, vil den sandsynligvis styre hver del af rekrutteringsprocessen, selvom andre medarbejdere kan bidrage med deres specifikke viden, når det er nødvendigt (f.eks. hvis vi ansætter en it-specialist, bør lederen af it-afdelingen vurdere kandidater ' tekniske færdigheder).
Hvis der ikke er en HR-afdeling, kan vi forvente, at ledelsespersonale vil stå for processen. I små og mellemstore virksomheder er dette ikke kun nødvendigt, det er ønsket.
-
Send jobbet
Nu er vi klar til at offentliggøre en jobbeskrivelse på vores side, på jobtavler eller aggregatorer eller i en avis. Jobopslaget skal indeholde punkterne i trin 2. Dette vil hjælpe potentielle kandidater med at beslutte, om de vil søge stillingen. Det er vigtigt at gøre jobbeskrivelsen nøjagtig; vi har alle spildt vores tid på at interviewe til et job, der ikke matchede beskrivelsen eller vores forventninger.
-
Udvælgelse, test og interview af kandidater
Efter ansøgningsperiodens udløb vil ansøgere med de mest relevante færdigheder og erfaringer blive inviteret til en indledende evalueringsfase (normalt en samtale eller test). De øvrige ansøgere får besked om, at de ikke er udvalgt til jobbet. En stor virksomhed bør invitere et foruddefineret minimumsantal af kandidater til den indledende evaluering. Dette sparer tid for både ansøgere og virksomheden.
Små og mellemstore virksomheder kan beslutte at fortsætte processen, indtil de finder den bedste pasform. I sådanne tilfælde vil ansøgningsperioden forblive åben, indtil den rigtige kandidat er fundet, og alle andre datoer vil blive defineret undervejs.
Interview- og testprocessen vil variere afhængigt af virksomhedens størrelse og organisation. I store virksomheder med HR-afdelinger vil der sandsynligvis være et sæt tests for at kontrollere ansøgeres jobfærdigheder. Andre test kan måle psykologiske og personlighedstræk for at bestemme ansøger-job-match, ansøger-virksomhed-match eller endda ansøgerens fornuft. ☺
Disse tests vil normalt være opdelt i flere trin, og hvert trin vil reducere antallet af ansøgere.
-
Det sidste interview
Dette trin vil sandsynligvis være et interview med de bedste få ansøgere. Det er det vigtigste trin i processen, fordi ansøgerne kan tale for sig selv, demonstrere deres kompetence og personlighed og afgøre, om virksomheden og stillingen vil passe dem godt. Efter dette trin vil den bedste ansøger modtage et tilbud. Hvis de accepterer, er rekrutteringsprocessen til den pågældende stilling slut. Hvis ansøgeren afslår jobtilbuddet, vil virksomheden give et tilbud til deres næste valg.
-
Er der forskelle i rekrutteringsprocessen for små, mellemstore og store virksomheder? Hvordan løser vi dem i vores model?
Der vil være visse forskelle i rekrutteringsprocesserne for små, mellemstore og store virksomheder. Derudover vil processen variere afhængigt af de stillinger, der rekrutteres. Tænk på, hvor forskellige de nødvendige færdigheder og erfaringer er for en content manager, en ornitolog og en krydstogtskibskaptajn. Nogle job vil have flere tests og samtaler, andre kan kun have nogle få. Men i sidste ende handler det hele om at få de rigtige svar og at rangere ansøgere.
I denne model vil jeg behandle alle tests og interviews på samme måde. Vi gemmer hver ansøgers svar, relaterer dem til det relevante spørgsmål og gemmer ansøgerens score for hvert trin i processen.
-
Hvem kan bruge denne datamodel?
Denne model er meget specifik og bør kun bruges til rekrutteringsprocessen. Men det er ikke begrænset til HR-afdelinger; du kan også bruge denne model til at drive en professionel rekrutteringstjeneste.
-
Datamodellen
Datamodellen består af fem hovedfagområder:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Jeg vil beskrive hvert fagområde separat, i samme rækkefølge som de er opført.
Afsnit 1:Job
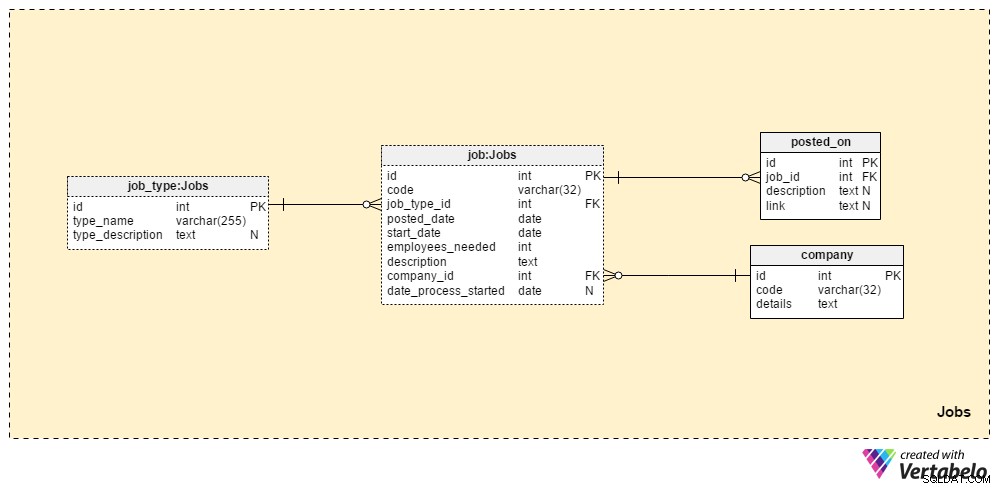
Jobs sektionen gemmer alle detaljer for alle de stillinger, vi nogensinde har slået op. De to ordbogstabeller, company tabellen og job_type tabel, er en del af den indledende opsætning. De resterende to tabeller, job og posted_on , indeholder "rigtige" data relateret til jobopslag.
job_type ordbogen indeholder en liste over forskellige og UNIKKE jobtyper. Vi kan forvente værdier som “senior database administrator” eller "IT-journalist" skal gemmes i type_name attribut. type_description attribut kan gemme en mere detaljeret beskrivelse af jobbet.
company ordbogen indeholder en liste over alle de virksomheder, vi arbejder med. Hvis vi kun ansætter medarbejdere til vores virksomhed, vil denne ordbog kun indeholde vores virksomhedsnavn. Hvis vi er et rekrutteringsbureau, gemmer det navnene på alle de virksomheder, der har ansat os.
En liste over alle jobstillinger, vi nogensinde har slået op, gemmes i "job"-tabellen. Attributterne i denne tabel er:
code– Vores interne UNIQUE ID bruges til at angive et job.job_type_id– Refererer til den relaterede jobtype.posted_date– Datoen, hvor denne stilling blev slået op.start_date– Den forventede startdato (første arbejdsdag) for det pågældende job.employees_needed– Antallet af medarbejdere, vi ønsker at ansætte under denne rekrutteringsproces. For det meste vil dette have en værdi på "1", men i nogle tilfælde - f.eks. ved opstart af ny virksomhed eller etablering af ny afdeling – vi kan forvente større værdier.description– En detaljeret beskrivelse af denne stilling. Dette er stedet, hvor vi viser alle nødvendige, foretrukne og ønskede jobfærdigheder.company_id– Henviser til id'et for det firma, der hyrede os. Hvis vi er et rekrutteringsbureau, vil dette referere til et virksomhedsnavn gemt icompanybord. Ellers vil det være vores eget firmas ID.date_process_started– Startdatoen for rekrutteringsprocessen. Dette kunne være NULL, hvis vi skal definere fremtidige trin og handlinger vedrørende dette job.
Den sidste tabel i dette emneområde er posted_on bord. For hver job_id , gemmer vi et link til jobopslaget og den tilhørende description . Vi kunne bruge disse data til at finde ud af, hvor ansøgerne finder vores jobstillinger.
Afsnit 2:Ansøgere, rekrutterere og dokumenter
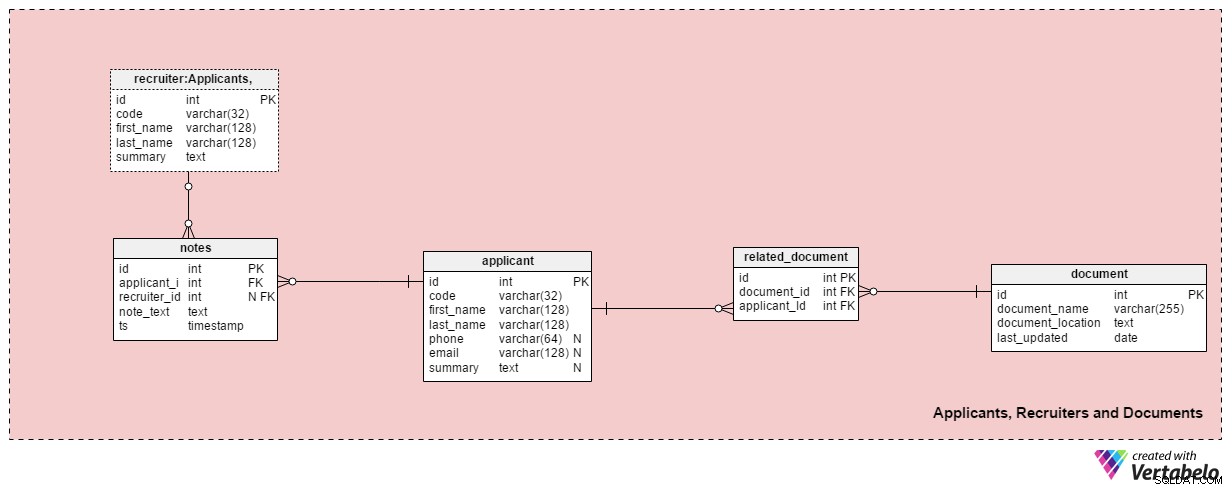
Dette emneområde indeholder alle de tabeller, der er nødvendige for at gemme oplysninger om rekrutterere, ansøgere og deres relaterede dokumenter.
applicant tabel viser alle de ansøgere, vi nogensinde har haft kontakt med. Hver ansøger er UNIKT defineret i vores system med en "kode". Udover det gemmer vi hver ansøgers for- og efternavn, phone nummer, email adresse og deres summary . Dette bord kan justeres til specifikke behov, f.eks. tilføjelse af yderligere telefonnumre, e-mails eller fysiske adresser.
Vi fortæller ansøgere om tilgængelige dokumenter. En liste over alle tilgængelige dokumenter (CV eller CV, grader eller eksamensbeviser, udskrifter, certificeringer osv.) er gemt i document bord. For hvert dokument gemmer vi dets navn i systemet, dets placering og tidspunktet for den seneste opdatering.
Vi vil relatere ansøgere til dokumenter ved hjælp af related_document bord. Den indeholder kun to fremmednøgler, som danner document_id – applicant_id UNIKT par.
recruiter tabel viser de medarbejdere, der kan tildeles en jobansøgning, eller som indtaster noter relateret til en ansøger. Hver rekrutterer er UNIKT defineret af hendes eller hans code . Vi gemmer kun grundlæggende detaljer såsom first_name , last_name og rekruttererens summary .
Den sidste tabel i dette emneområde er notes bord. Det er her, vi gemmer alle noter relateret til en ansøger. Vi kunne gemme noter som "Ansøger gik glip af mødet" eller "Ansøger klarede sig godt ved første samtale" . For hver note gemmer vi ID'et på den rekrutterer, der lavede den note, ID'et for den relaterede ansøger, note_text , og tidsstemplet, da noten blev oprettet.
Afsnit 3:Testdetaljer
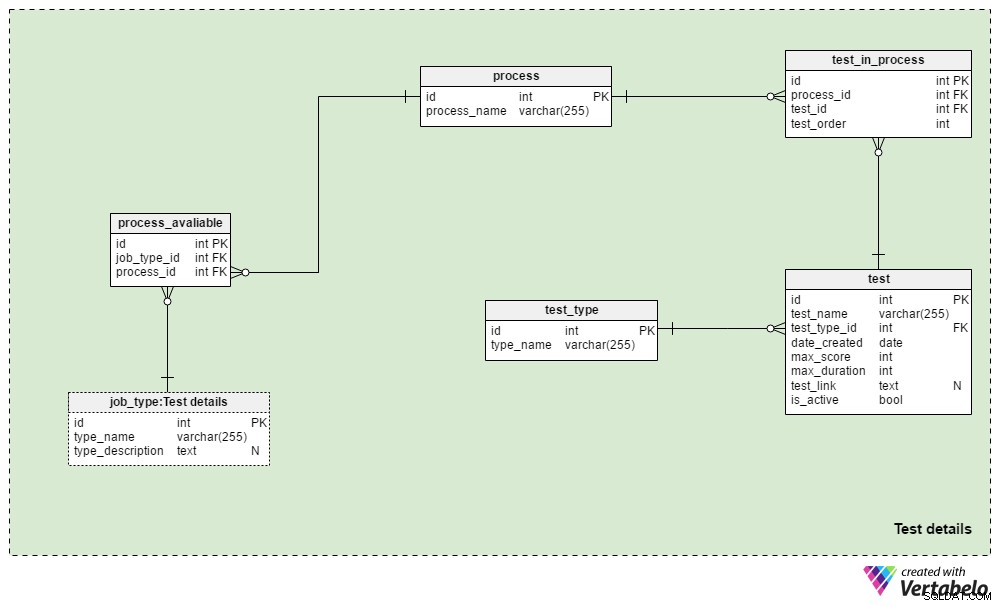
Test details Fagområdet indeholder de tabeller, der bruges til at definere rekrutteringsprocesser, og de test, der bruges under disse processer. Vi vil generelt altid bruge den samme udvælgelsesproces for den samme jobtype:ændringer foretages kun, når de er påkrævet af forretningsforhold. Vi kunne bruge et par forskellige processer til hver jobtype, og vi vil næsten helt sikkert bruge den samme proces til forskellige jobtyper.
process tabel er en simpel ordbog, der kun indeholder et UNIKT process_name attribut. Den viser alle de rekrutteringsprocesser, vi nogensinde har brugt og bruger i øjeblikket.
Vi vil relatere processer til forskellige jobtyper. Vi gemmer disse relationer i process_available bord. Dens eneste attributter er det UNIKKE par job_type_id – process_id . Når der er flere tilgængelige processer for en jobtype, giver dette rekruttereren mulighed for at vælge en.
test_in_process tabel bruges til at definere rækkefølgen af test under denne proces. Attributterne i denne tabel er:
process_idogtest_id– Refererer til den relaterede proces og test.test_order– Ordinalnummeret for den pågældende test eller trin i processen. Sammen medprocess_id, dette danner den UNIKKE nøgle i tabellen. Vi kan kun have ét trin ad gangen under processen.
test tabel viser alle tests aktuelt og tidligere brugt i rekrutteringsprocessen. Vi vil også behandle CV-anmeldelser og samtaler som test. Selvom de ikke behøver definerede spørgsmål og svar, er de en del af en evaluering. For hver test gemmer vi:
test_name– En UNIK betegnelse for hver test.test_type_id– Refererer tiltest_typeordbog.date_created– Datoen, hvor vi oprettede denne test i vores system.max_score– Den maksimale score, der kan opnås for denne test. Denne værdi er summen af alle korrekte svar på denne test eller den højeste karakter, som rekrutterere kunne give til et CV eller en samtale.max_duration– Hvor lang tid (i minutter) har ansøgeren til at gennemføre testen.test_link– Indeholder et link til teststedet. Denne værdi kan være NULL, når vi ikke bruger en test i processen.is_active– Angiver, om vi i øjeblikket bruger denne test.
Vi har allerede nævnt test_type ordbog. Den indeholder alle de UNIKKE testnavne efter format, f.eks. "CV-gennemgang" , "online færdighedstest" , "papirfærdighedstest" og "interview" .
Denne model inkluderer ikke den nødvendige struktur til at gemme testspørgsmål og -svar. Det gemmer snarere et link til de steder, der indeholder disse oplysninger. Det samme design vil blive brugt i Applications emneområde.
Afsnit 4:Programmer
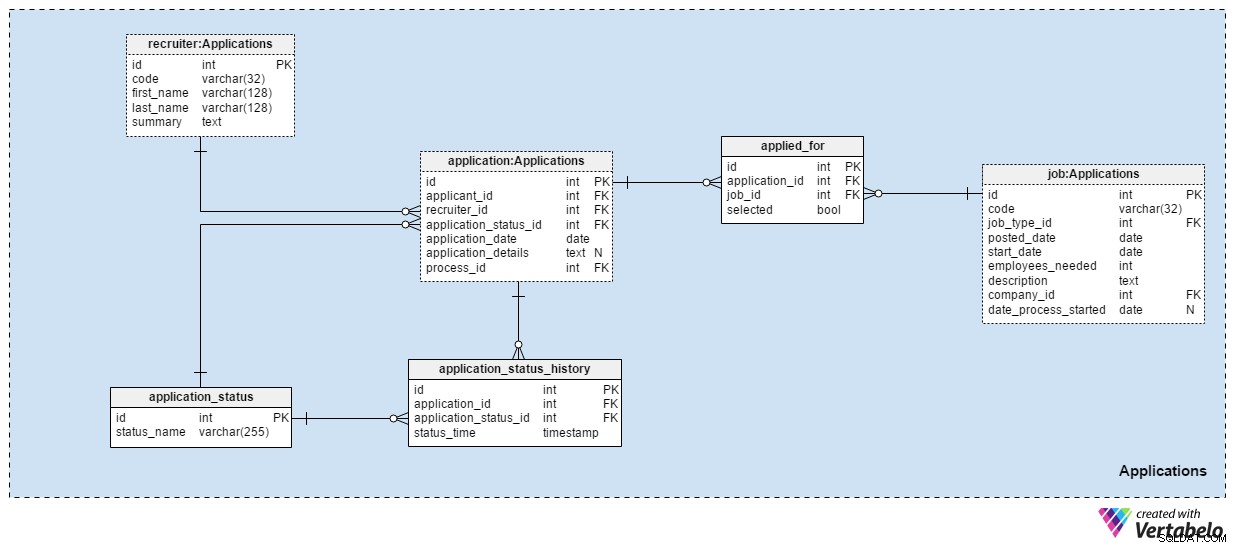
Applications emneområdet er nok det vigtigste i denne datamodel. Alle andre nævnte fagområder beskrev hidtil ansøgninger. Denne gemmer de rigtige ting.
Hver ansøgning, vi nogensinde har modtaget, registreres i application bord. For hver ansøgning gemmer vi de relaterede ansøgeres ID, rekrutterings-ID og en reference til den aktuelle status for den pågældende ansøgning. Vi opdaterer denne status, samtidig med at vi foretager en ny indtastning i application_status_history bord. application_date attribut bruges til at gemme den relevante dato, mens alle yderligere detaljer gemmes i tekstformat. process_id attribut gemmer en reference til den proces, der er valgt for den pågældende applikation.
Ansøgninger vil ændre status over tid. En liste over alle applikationsstatusser er gemt i application_status ordbog. Den eneste attribut er status_name og den kan kun indeholde UNIKKE værdier. Forventede værdier inkluderer:"applied" , "CV gennemgået" , "valgt til testen" , "afvist efter CV-gennemgang" , "bestod testen" , "inviteret til et interview" og "opsagt af ansøger" .
Vi gemmer alle ansøgningsstatusser i application_status_history bord. Denne tabel indeholder referencer til application tabellen og application_status ordbog. Vi gemmer også den nøjagtige status_time når denne status blev tildelt applikationen. application_id – status_time par danner den UNIKKE nøgle i denne tabel.
I de fleste tilfælde vil en ansøger kun søge én stilling med én ansøgning. Det er muligt, at en ansøger vil søge mere end én stilling, og vi vælger den bedst egnede rolle til dem under udvælgelsesprocessen. I applied_for tabel, gemmer vi det UNIKKE par application_id – job_id . Vi registrerer også, om ansøgeren relateret til den pågældende ansøgning blev selected til den stilling. Vi kan forvente, at alle selected værdier vil blive sat til "False" i begyndelsen af udvælgelsesprocessen, og at vi kun opdaterer én pr. hver stilling til "True" .
Afsnit 5:Applikationstests
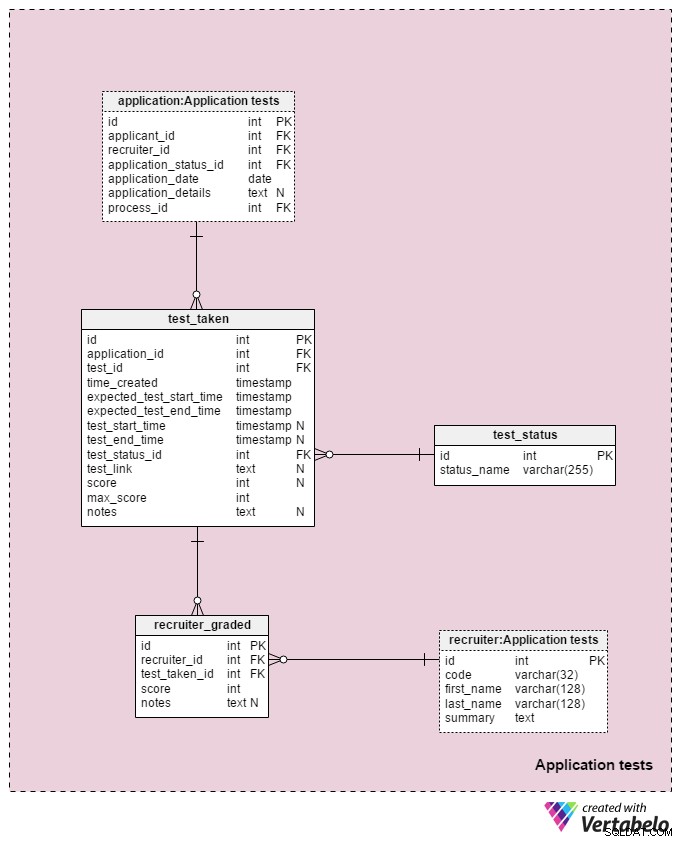
Det sidste emneområde i vores model vil blive brugt til at gemme resultaterne af hver test taget under udvælgelsesprocessen. To tabeller brugt i dette emneområde er kopier fra andre emneområder:application og recruiter . De bruges her til at forenkle modellen.
Alle detaljer relateret til hver test er gemt i test_taken bord. Denne tabel indeholder også alle andre trin i processen, der kunne bedømmes, såsom en CV-gennemgang. Attributterne i denne tabel er:
application_id– Henviser tilapplicationbord. Dette vedrører en prøve med den ansøger, der tog den pågældende prøve.test_id– Henviser tiltestkatalog. Vi kunne også henvise tiltest_in_processtabel her, som ville give os flere oplysninger om den taget test. Jeg besluttede at lade være, fordi denne struktur giver os mere fleksibilitet. (F.eks. hvis vi ønsker at tillade ansøgere at tage en prøve to gange eller uden for de sædvanlige tider).time_created– Det faktiske tidspunkt, hvor vi indsatte denne test i vores system.expected_test_start_timeogexpected_test_end_time– Start- og sluttidspunkter, som drøftet med ansøgeren. Vi kan ændre disse værdier, hvis ansøgeren eller rekrutteringsmedarbejderen bliver nødt til at udsætte testen.test_start_timeogtest_end_time– De faktiske start- og sluttidspunkter for testen. Disse vil indeholde NULL-værdier, når testen oprettes; værdierne vil blive opdateret, når ansøgeren starter og afslutter denne test.test_status_id– Henviser tiltest_statusordbog.test_link– Links til testen med ansøgerens svar. Den vil blive opdateret, når ansøgeren afleverer testen.score– Ansøgerens score på denne prøve. Dette bestemmes enten manuelt af en rekrutterer (f.eks. til en CV-gennemgang) eller automatisk (summen af alle testpunkter). Det kunne også indeholde en NULL-værdi for test, der ikke er bedømt eller bedømt på en foruddefineret skala. Desuden kan en test, der er planlagt, men endnu ikke afsluttet, have en NULL-værdi.max_score– Testens maksimalt opnåelige score. Dette er det samme som værdien gemt itest.”max_scoreattribut. Jeg vil beholde denne værdi, fordi rekrutteringslederen kunne ændre testen, mens den afgives, og derfor ændre den maksimale score, der kunne opnås.notes– Eventuelle yderligere bemærkninger eller bemærkninger, der er indtastet af rekrutterere vedrørende den specifikke test.
Kombinationen af test_id – application_id – expected_test_start_time attributter danner den UNIKKE nøgle i denne tabel. Før vi tilføjer en ny testsession, bør vi stadig tjekke for overlappende testintervaller for den relaterede ansøger og alle relaterede rekrutterere.
test_status ordbogen indeholder en liste over hver UNIKKE status_name der kunne tildeles en prøve. Nogle forventede værdier inkluderer:"ikke startet" , "i gang" , "fuldført med succes" , "udført uden succes" , "udsat" , "annulleret" og "ansøger annulleret" .
Den sidste tabel i vores model er recruiter_graded tabel, som gemmer alle karakterer, rekrutterere gav ved karaktergivning af hver test. Derfor gemmer vi referencer til recruiter og test_taken tabeller. Vi gemmer også score opnået såvel som eventuelle notes . Disse oplysninger er meget vigtige, især når vi bedømmer prøver manuelt (dvs. til CV-gennemgange og interviews).
I dag har vi diskuteret en datamodel, der kan dække næsten enhver situation i udvælgelses- og rekrutteringsprocessen – inklusive ualmindelige undtagelser.
De fleste af os har en vis ekspertise med dette emne. Del venligst din oplevelse, mens du var i rollen som rekrutterer eller på den anden side af skrivebordet. Dækker denne model de situationer, du stod i? Hvis ikke, hvilke ændringer vil du foreslå?