I mit sidste indlæg ("Dude, hvem ejer den #temp-tabel?"), foreslog jeg, at du i SQL Server 2012 og nyere kunne bruge Extended Events til at overvåge oprettelsen af #temp-tabeller. Dette vil give dig mulighed for at korrelere specifikke objekter, der optager meget plads i tempdb, med den session, der skabte dem (for eksempel for at afgøre, om sessionen kunne dræbes for at forsøge at frigøre pladsen). Hvad jeg ikke diskuterede, er overheaden af denne sporing – vi forventer, at udvidede begivenheder er lettere end spor, men ingen overvågning er helt gratis.
Da de fleste mennesker lader standardsporingen være aktiveret, lader vi det være på plads. Vi tester begge dynger ved hjælp af SELECT INTO (som standardsporingen ikke vil indsamle) og klyngede indekser (hvilket det vil), og vi vil time partiet alene som en baseline, og derefter køre partiet igen med Extended Events-sessionen kørende. Vi vil også teste mod både SQL Server 2012 og SQL Server 2014. Selve batchen er ret simpel:
INDSTIL ANTAL TIL; VÆLG SYSDATETIME();GO -- kør kun denne del for heap-batchen:SELECT TOP (100) [object_id] INTO #foo FRA sys.all_objects BESTIL EFTER [object_id]; DROP TABLE #foo; -- Kør kun denne del for CIX-batchen:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FRA sys.all_objects BESTIL EFTER [object_id]; DROP TABLE #bar; GÅ 100000 VÆLG SYSDATETIME();
Begge instanser har tempdb konfigureret med fire datafiler og med TF 1117 og TF 1118 aktiveret, i en VM med fire CPU'er, 16 GB hukommelse og kun SSD. Jeg oprettede med vilje små #temp-tabeller for at forstærke enhver observeret indvirkning på selve batchen (som ville blive overdøvet, hvis oprettelsen af #temp-tabellerne tog lang tid eller forårsagede overdreven autovæksthændelser).
Jeg kørte disse batches i hvert scenarie, og her var resultaterne, målt i batchvarighed i sekunder:
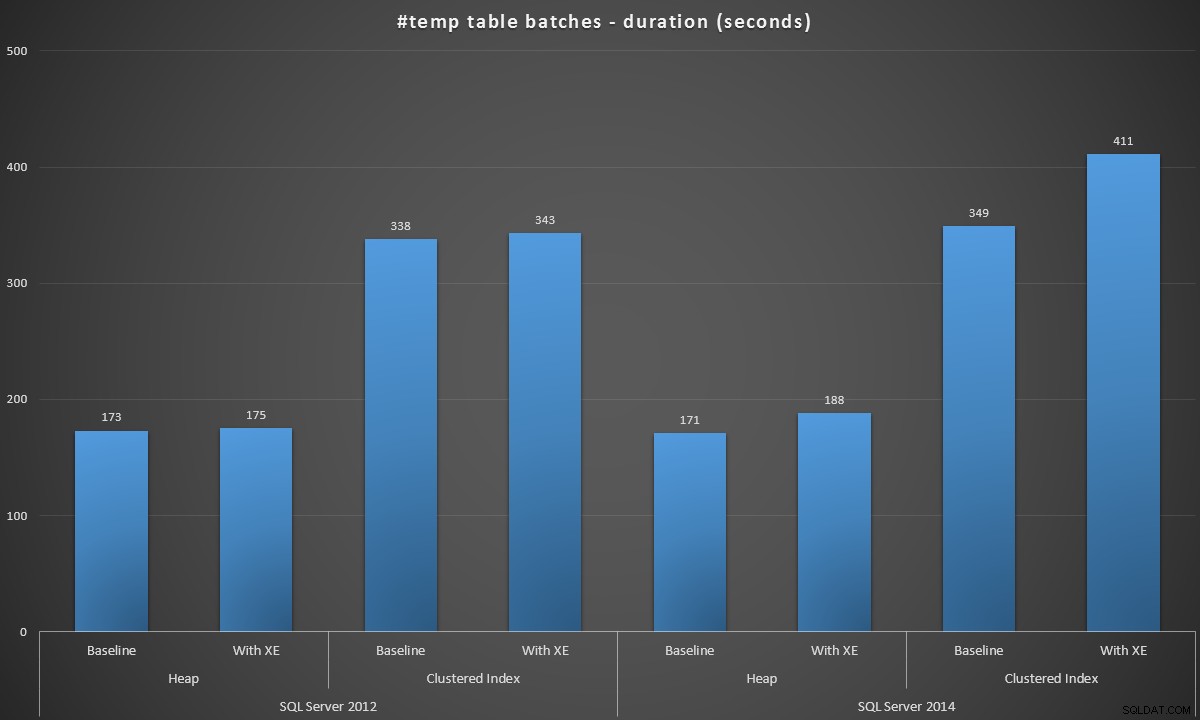
Batchvarighed, i sekunder, for oprettelse af 100.000 #temp-tabeller
Hvis vi udtrykker dataene lidt anderledes, hvis vi dividerer 100.000 med varigheden, kan vi vise antallet af #temp-tabeller, vi kan oprette pr. sekund i hvert scenarie (læs:gennemløb). Her er disse resultater:
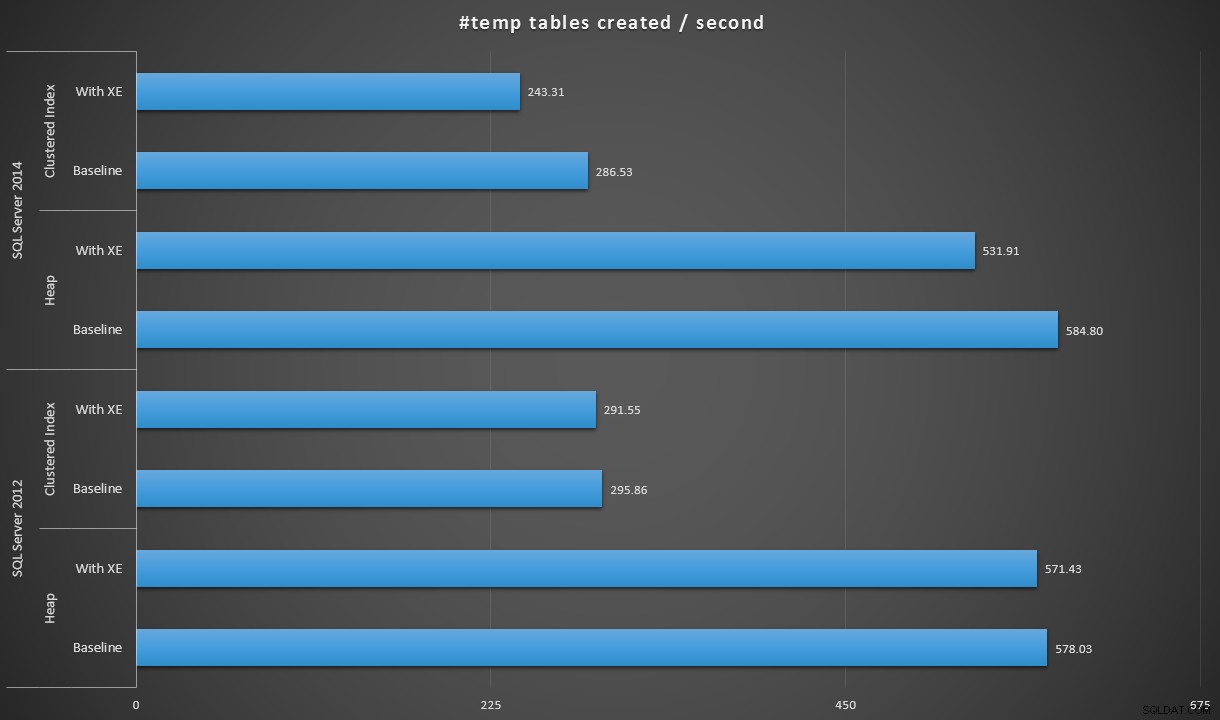
#temp-tabeller oprettet pr. sekund under hvert scenarie
Resultaterne var lidt overraskende for mig – jeg forventede, at med SQL Server 2014-forbedringerne i ivrig skrivelogik, ville heappopulationen i det mindste køre meget hurtigere. Hoben i 2014 var to sølle sekunder hurtigere end 2012 ved baseline-konfigurationen, men Extended Events kørte tiden en del op (omtrent en stigning på 10 % i forhold til baseline); mens den klyngede indekstid var sammenlignelig med 2012 ved baseline, men steg med næsten 18 % med udvidede begivenheder aktiveret. I 2012 var deltaerne for heaps og clustered indekser meget mere beskedne – henholdsvis 1,1 % og 1,5 %. (Og for at være klar, skete der ingen autogrow-begivenheder under nogen af testene.)
Så jeg tænkte, hvad nu hvis jeg lavede en slankere, slankere session med udvidede begivenheder? Jeg kunne helt sikkert fjerne nogle af disse handlingskolonner – måske har jeg kun brug for loginnavn og spid, og kan ignorere appnavnet, værtsnavnet og potentielt dyre sql_text. Måske kunne jeg droppe det ekstra filter mod commit (samler dobbelt så mange hændelser, men mindre CPU brugt på filtrering) og tillade tab af flere hændelser for at reducere den potentielle indvirkning på arbejdsbyrden. Denne mere slanke session ser sådan ud:
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] PÅ SERVER TILFØJ BEGIVENHED sqlserver.object_created( ACTION ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_i_codesq.DAR) N/Get_i_codesqd'0 ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)MED ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS]Middelbar STARTSÆTNING1EVENT_LOSS 2;Ak nej, samme resultater. Lidt over tre minutter for bunken og knap syv minutter for det klyngede indeks. For at grave dybere ned i, hvor den ekstra tid blev brugt, så jeg 2014-forekomsten med SQL Sentry og kørte kun den klyngede indeksbatch uden nogen udvidede begivenhedssessioner konfigureret. Så kørte jeg batchen igen, denne gang med den lettere XE-session konfigureret. Batchtiderne var 5:47 (347 sekunder) og 6:55 (415 sekunder) – så meget på linje med den forrige batch (jeg var glad for at se, at vores overvågning ikke bidrog yderligere til varigheden :-)) . Jeg bekræftede, at ingen begivenheder blev droppet, og igen, at der ikke fandt nogen autogrow-begivenheder sted.
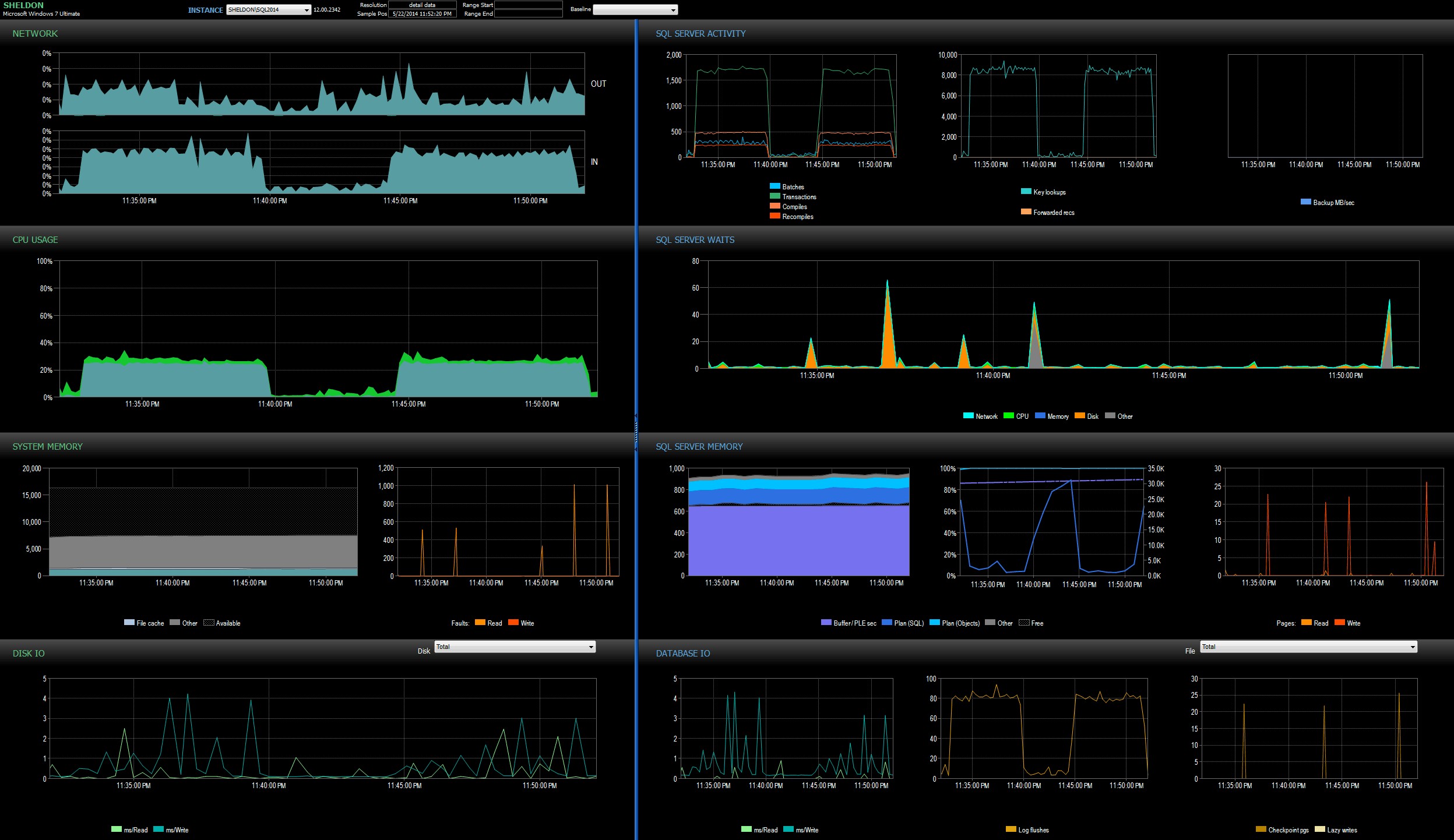
Jeg så på SQL Sentry-dashboardet i historiktilstand, som gjorde det muligt for mig hurtigt at se ydeevnemålingerne for begge batches side om side:
SQL Sentry-dashboard, i historiktilstand, viser begge batches em>Begge batches var stort set identiske med hensyn til netværk, CPU, transaktioner, kompileringer, nøgleopslag osv. Der er en lille forskel i Waits – spidserne under den første batch var udelukkende WRITELOG, mens der var nogle mindre CXPACKET-ventinger fundet i andet parti. Min arbejdsteori langt efter midnat er, at måske en god del af den observerede forsinkelse skyldtes kontekstskifte forårsaget af Extended Events-processen. Da vi ikke har noget overblik over præcis, hvad XE laver under dynen, og vi ved heller ikke, hvilken underliggende mekanik der har ændret sig i XE mellem 2012 og 2014, er det den historie, jeg vil holde fast i indtil nu, indtil jeg er mere komfortabel med xperf og/eller WinDbg.
Konklusion
Under alle omstændigheder er det klart, at sporing af #temp-tabeller ikke er gratis, og prisen kan variere afhængigt af typen af #temp-tabeller, du opretter, mængden af information, du indsamler i dine XE-sessioner, og endda versionen af SQL Server, du bruger. Så du kan køre lignende tests som det, jeg har gjort her, og beslutte, hvor værdifuldt at indsamle disse oplysninger i dit miljø.