Virtuel IP-adresse er en IP-adresse, der ikke svarer til en faktisk fysisk netværksgrænseflade. Den flyder mellem flere netværksgrænseflader, og kun én aktiv grænseflade vil indeholde IP-adressen for fejltolerance og mobilitet. ClusterControl bruger Keepalved til at levere virtuel IP-adresseintegration med databasebelastningsbalancer for at eliminere ethvert enkelt fejlpunkt (SPOF) på belastningsbalancerniveau.
I dette blogindlæg viser vi dig, hvordan ClusterControl konfigurerer virtuel IP-adresse, og hvad du kan forvente, når failover eller failback sker. Det er vigtigt at forstå denne adfærd for at minimere enhver serviceafbrydelse og udjævne vedligeholdelsesoperationer, der skal udføres lejlighedsvis.
Krav
Der er nogle krav for at køre Keepalived i dit netværk:
- IP-protokol 112 (Virtual Router Redundancy Protocol - VRRP) skal understøttes i netværket. Nogle netværk deaktiverer understøttelse af VRRP, især inter-VLAN-kommunikation. Bekræft dette med netværksadministratoren.
- Hvis du bruger multicast, skal netværket understøtte multicast-anmodning (brug ip a | grep -i multicast). Ellers kan du bruge unicast via unicast_src_ip og unicast_peer muligheder. Det er nyttigt at bruge multicast, når du har et dynamisk miljø som et cloudmiljø, eller når IP-tildeling udføres via DHCP.
- Et sæt VRRP-instanser skal bruge et unikt virtuel_router_id værdi, som ikke kan deles mellem andre instanser. Ellers vil du se falske pakker og vil sandsynligvis bryde master-backup-omskifteren.
- Hvis du kører på et cloudmiljø som AWS, skal du sandsynligvis bruge et eksternt script (tip:brug "notify"-indstillingen) for at adskille og tilknytte den virtuelle IP-adresse (Elastic IP), så den genkendes og kan dirigeres af routeren.
Implementering af Keepalived
For at installere Keepalved gennem ClusterControl skal du have to eller flere load balancere installeret af eller importeret til ClusterControl. Til produktionsbrug anbefaler vi stærkt, at load balancer-softwaren kører på en selvstændig vært og ikke er placeret sammen med dine databasenoder.
Når du har mindst to belastningsbalancere administreret af ClusterControl, for at installere Keepalived og aktivere virtuel IP-adresse, skal du bare gå til ClusterControl -> vælg klyngen -> Administrer -> Load Balancer -> Keepalived:
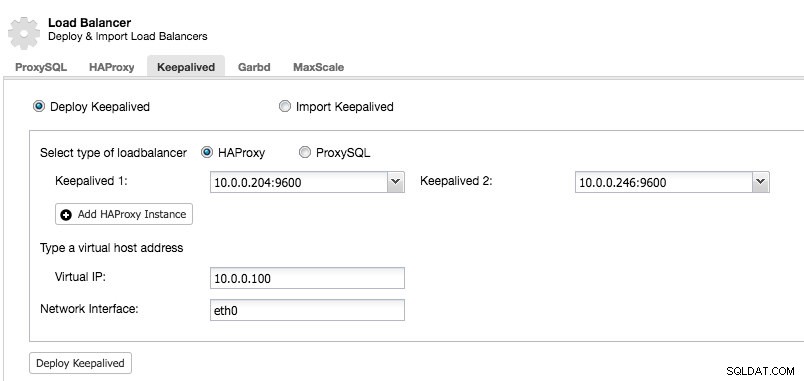
De fleste af felterne er selvforklarende. Du kan implementere et nyt sæt Keepalved eller importere eksisterende Keepalved-forekomster. De vigtige felter inkluderer den faktiske virtuelle IP-adresse og netværksgrænsefladen, hvor den virtuelle IP-adresse vil eksistere. Hvis værterne bruger to forskellige grænsefladenavne, skal du angive grænsefladenavnet på Keepalved 1-værten og derefter manuelt ændre konfigurationsfilen på Keepalved 2 med et korrekt grænsefladenavn senere.
VRRP-instans
På nuværende tidspunkt installerer ClusterControl v1.5.1 Keepalved v1.3.5 (afhængigt af værtsoperativsystemet), og følgende er, hvad der er konfigureret til VRRP-instansen:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl konfigurerer VRRP-instansen til at kommunikere gennem unicast. Med unicast skal vi definere alle unicast-peers i de andre Keepalved-knuder. Det er mindre dynamisk, men fungerer det meste af tiden. Med multicast kan du fjerne disse linjer (unicast_*) og stole på multicast IP-adresse til værtsopdagelse og peering. Det er enklere, men det er almindeligvis blokeret af netværksadministratorer.
Den næste del er den virtuelle IP-adresse. Du kan angive flere virtuelle IP-adresser pr. VRRP-instans, adskilt af en ny linje. Load balancing i HAProxy/ProxySQL og Keepalved på samme tid kræver også muligheden for at binde til en IP-adresse, der er ikke-lokal, hvilket betyder, at den ikke er tildelt en enhed på det lokale system. Dette gør det muligt for en kørende load balancer-instans at binde til en IP, der ikke er lokal til failover. Således konfigurerer ClusterControl også net.ipv4.ip_nonlocal_bind=1 inde i /etc/sysctl.conf.
Det næste direktiv er track_script , hvor du kan angive scriptet til sundhedstjekprocessen, som er forklaret i næste afsnit.
Sundhedstjek
ClusterControl konfigurerer Keepalved til at udføre sundhedstjek ved at undersøge fejlkoden, der returneres af track_script. I Keepalived-konfigurationsfilen, som som standard er placeret på /etc/keepalived/keepalived.conf, skulle du se noget som dette:
track_script {
chk_proxysql
}Hvor den kalder chk_proxysql, som indeholder:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Kommandoen "killall -0" returnerer exitkode 0, hvis der kører en proces kaldet "proxysql" på værten. Ellers ville instansen skulle degradere sig selv og begynde at starte failover som forklaret i næste afsnit. Vær opmærksom på, at Keepalived også understøtter Linux Virtual Server (LVS)-komponenter til at udføre sundhedstjek, hvor den også er i stand til belastningsbalancerende TCP/IP-forbindelser, svarende til HAProxy, men det er uden for rammerne af dette blogindlæg.
Simulering af failover
For VRRP-komponenter bruger Keepalved VRRP-protokol (IP-protokol 112) til at kommunikere mellem VRRP-instanser. Den højere prioritetsværdi af en MASTER betyder, at masteren altid vil have det højere privilegium til at holde den virtuelle IP-adresse, medmindre du konfigurerer instansen med "nopreempt". Lad os bruge et eksempel til bedre at forklare failover- og failback-flowet. Overvej følgende diagram:
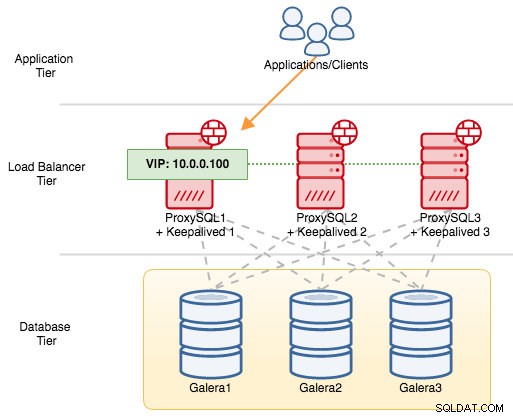
Der er tre ProxySQL-instanser foran tre MySQL Galera-noder. Hver ProxySQL-vært er konfigureret med Keepalived som MASTER med følgende prioritetsnummer:
- ProxySQL1 - prioritet 101
- ProxySQL2 - prioritet 100
- ProxySQL3 - prioritet 99
Når Keepalived startes som MASTER, vil den først annoncere prioritetsnummeret til medlemmerne og derefter knytte sig til den virtuelle IP-adresse. I modsætning til BACKUP-forekomsten vil den kun observere annoncen og kun tildele den virtuelle IP-adresse, når den har bekræftet, at den kan ophøje sig selv til en MASTER.
Vær opmærksom på, at hvis du dræber "proxysql"- eller "haproxy"-processen manuelt via kill-kommando, vil systemd process manager som standard forsøge at gendanne den proces, der er ved at blive stoppet ungerligt. Desuden, hvis du har ClusterControl automatisk gendannelse slået til, vil ClusterControl altid forsøge at starte processen, selvom du udfører en ren nedlukning via systemd (systemctl stop proxysql). For bedst at simulere fejlen, foreslår vi, at brugeren slår ClusterControls automatiske gendannelsesfunktion fra eller blot lukker ProxySQL-serveren ned for at afbryde kommunikationen.
Hvis vi lukker ProxySQL1 ned, vil den virtuelle IP-adresse blive overført til den næste vært, som har højere prioritet på det pågældende tidspunkt (som er ProxySQL2):
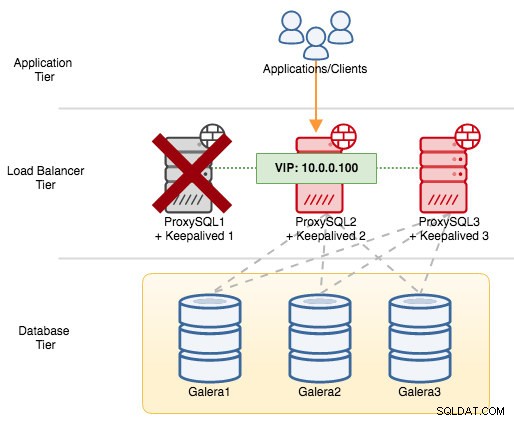
Du vil se følgende i syslog for den mislykkede node:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Mens du var på den sekundære node, skete følgende:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.I dette tilfælde tog failover omkring 3 sekunder, med maksimal failover-tid ville være interval + advert_int . Bag kulisserne er databaseslutpunktet ændret, og databasetrafik bliver dirigeret gennem ProxySQL2, uden at applikationer opdager det.
Når ProxySQL1 kommer online igen, vil den tvinge til et nyt MASTER-valg og overtage IP-adressen på grund af højere prioritet:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Samtidig degraderer ProxySQL2 sig selv til BACKUP-tilstand og fjerner den virtuelle IP-adresse fra netværksgrænsefladen:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.På dette tidspunkt er ProxySQL1 tilbage online og bliver den aktive load balancer, der betjener forbindelserne fra applikationer og klienter. VRRP vil normalt foregribe en lavere prioritet server, når en højere prioritet server kommer online. Hvis du gerne vil have IP-adressen til at forblive på ProxySQL2, efter at ProxySQL1 vender tilbage online, skal du bruge "nopreempt"-muligheden. Dette gør det muligt for den lavere prioriterede maskine at bevare masterrollen, selv når en højere prioritet maskine kommer online igen. Men for at dette skal virke, skal starttilstanden for denne post være BACKUP. Ellers vil du bemærke følgende linje:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERDa ClusterControl som standard konfigurerer alle noder som MASTER, skal du konfigurere følgende konfigurationsmulighed for den respektive VRRP-instans i overensstemmelse hermed:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Genstart Keepalved-processen for at indlæse disse ændringer. Den virtuelle IP-adresse vil kun blive overført til ProxySQL1 eller ProxySQL3 (afhængigt af prioritet og hvilken node der er tilgængelig på det tidspunkt), hvis sundhedstjekket mislykkes på ProxySQL2. I mange tilfælde vil det være tilstrækkeligt at køre Keepalved på to værter.