Den stigende efterspørgsel efter systemer med høj tilgængelighed og stramme SLA'er presser os til at erstatte manuelle procedurer med automatiserede løsninger. Men har du tiden og de nødvendige ressourcer til selv at håndtere kompleksiteten af failover-operationer? Vil du ofre nedetid i produktionsdatabasen for at lære det på den hårde måde?
ClusterControl giver avanceret support til fejlregistrering og håndtering. Det bruges af mange virksomhedsorganisationer og holder de mest kritiske produktionssystemer oppe og køre i 24/7-tilstand.
Denne databasestyringsløsning understøtter dig også med implementeringen af forskellige indlæsningsproxyer. Disse proxyer spiller en nøglerolle i HA-stakken, så der er ingen grund til at justere applikationsforbindelsesstreng eller DNS-indtastning for at omdirigere applikationsforbindelser til den nye masterknude.
Når der opdages fejl, udfører ClusterControl alt baggrundsarbejdet for at vælge en ny master, implementere fail-over-slaveservere og konfigurere belastningsbalancere. I denne blog lærer du, hvordan du opnår automatisk failover af TimescaleDB i dine produktionssystemer.
Implementering af hele replikeringstopologier
Fra ClusterControl 1.7.2 kan du implementere en hel TimescaleDB-replikeringsopsætning på samme måde, som du ville implementere PostgreSQL:du kan bruge menuen "Deploy Cluster" til at implementere en primær og en eller flere TimescaleDB-standbyservere. Lad os se, hvordan det ser ud.
Først skal du definere adgangsdetaljer, når du implementerer nye klynger ved hjælp af ClusterControl. Det kræver root- eller sudo-adgangskodeadgang til alle noder, som din nye klynge vil blive implementeret på.
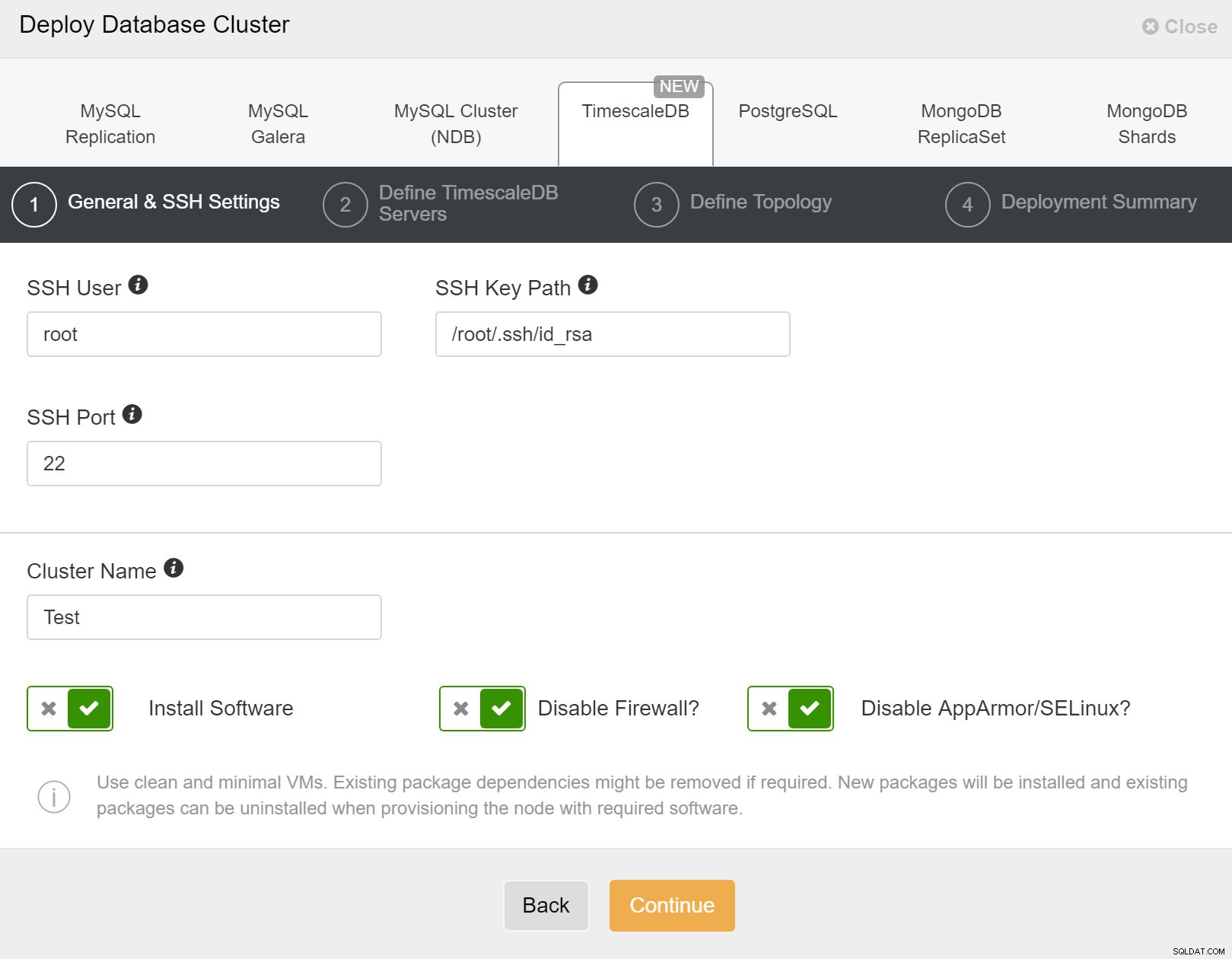 ClusterControl:Implementer ny klynge
ClusterControl:Implementer ny klynge Dernæst skal vi definere brugeren og adgangskoden for TimescaleDB-brugeren.
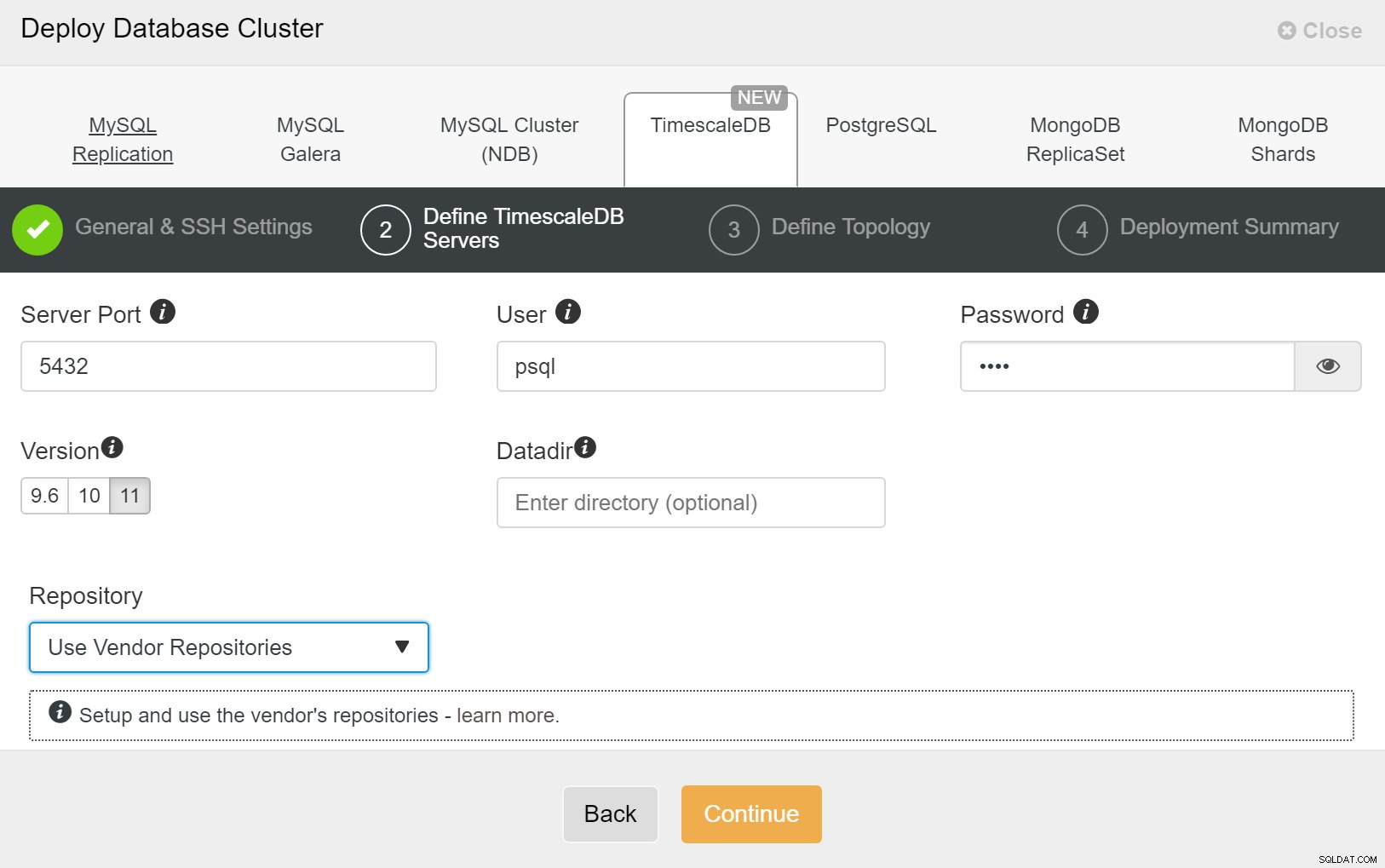 ClusterControl:Implementer databaseklynge
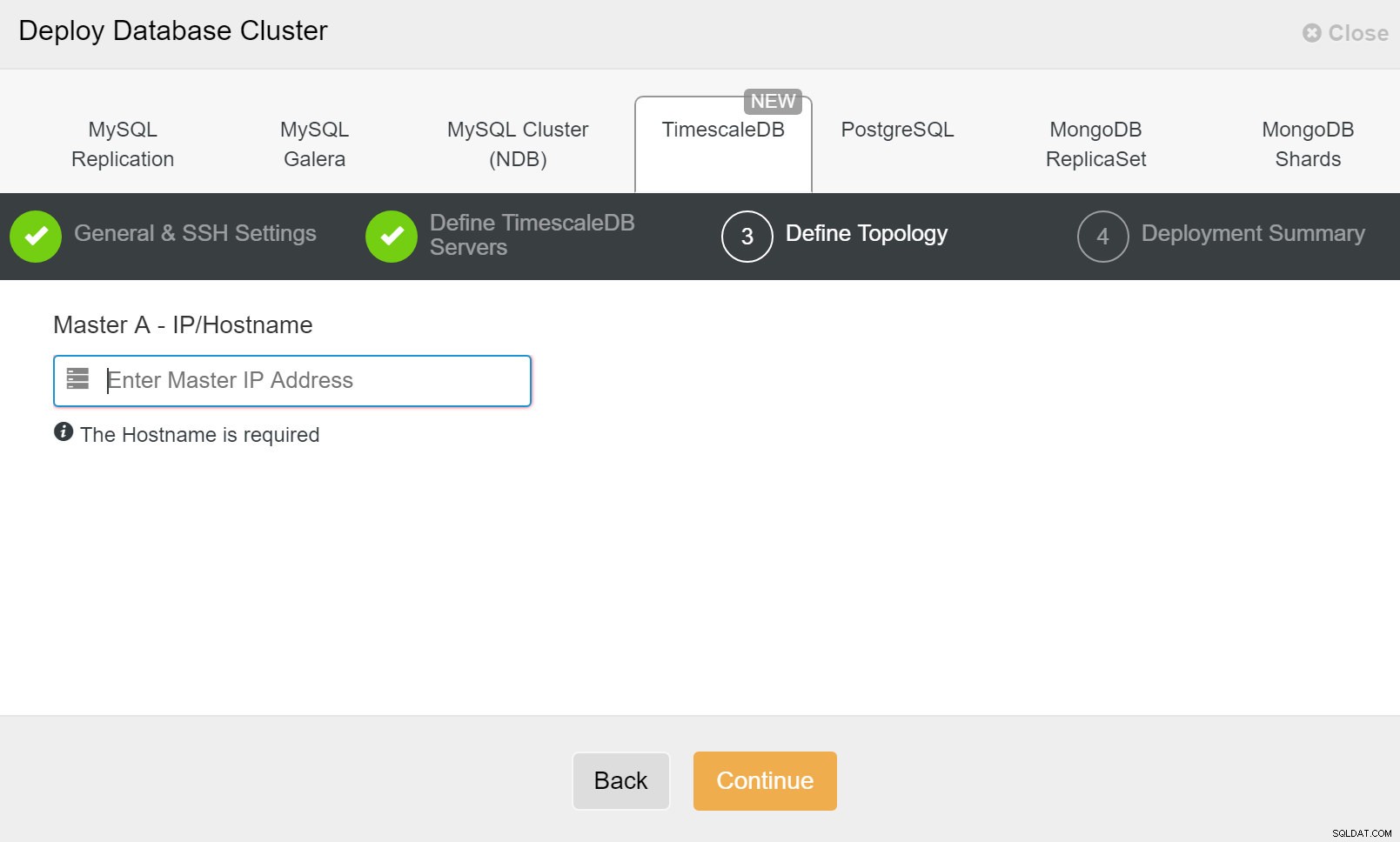
ClusterControl:Implementer databaseklynge Til sidst vil du definere topologien - hvilken vært der skal være den primære og hvilke værter der skal konfigureres som standby. Mens du definerer værter i topologien, vil ClusterControl kontrollere, om ssh-adgangen fungerer som forventet - dette lader dig fange eventuelle forbindelsesproblemer tidligt. På den sidste skærm vil du blive spurgt om typen af replikering synkron eller asynkron.
 ClusterControl-implementering
ClusterControl-implementering Det er det, så er det et spørgsmål om at starte implementeringen. Et job oprettes i ClusterControl, og du vil kunne følge fremskridtene.
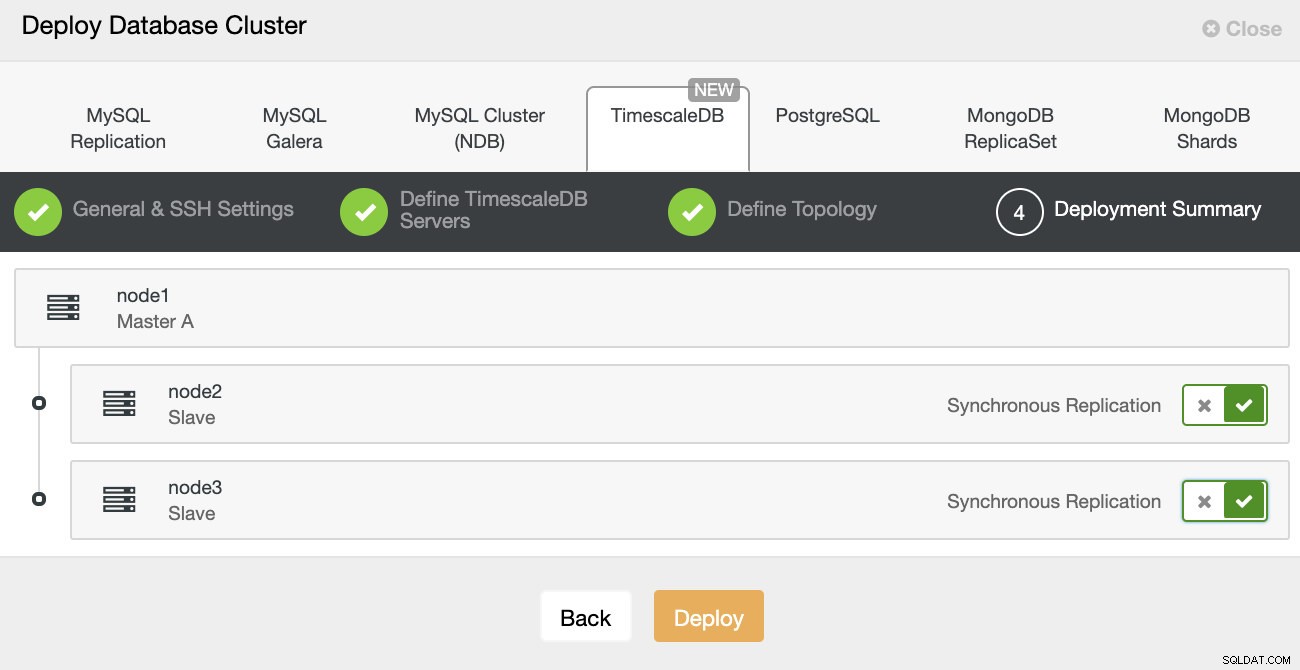
 ClusterControl:Definer topologi for TimescleDb-klyngen
ClusterControl:Definer topologi for TimescleDb-klyngen Når du er færdig, vil du se topologiopsætningen med roller i klyngen. Bemærk, at vi også tilføjede en belastningsbalancer (HAProxy) foran databaseforekomsterne, så den automatiske failover vil ikke kræve ændringer i databaseforbindelsesindstillingerne.
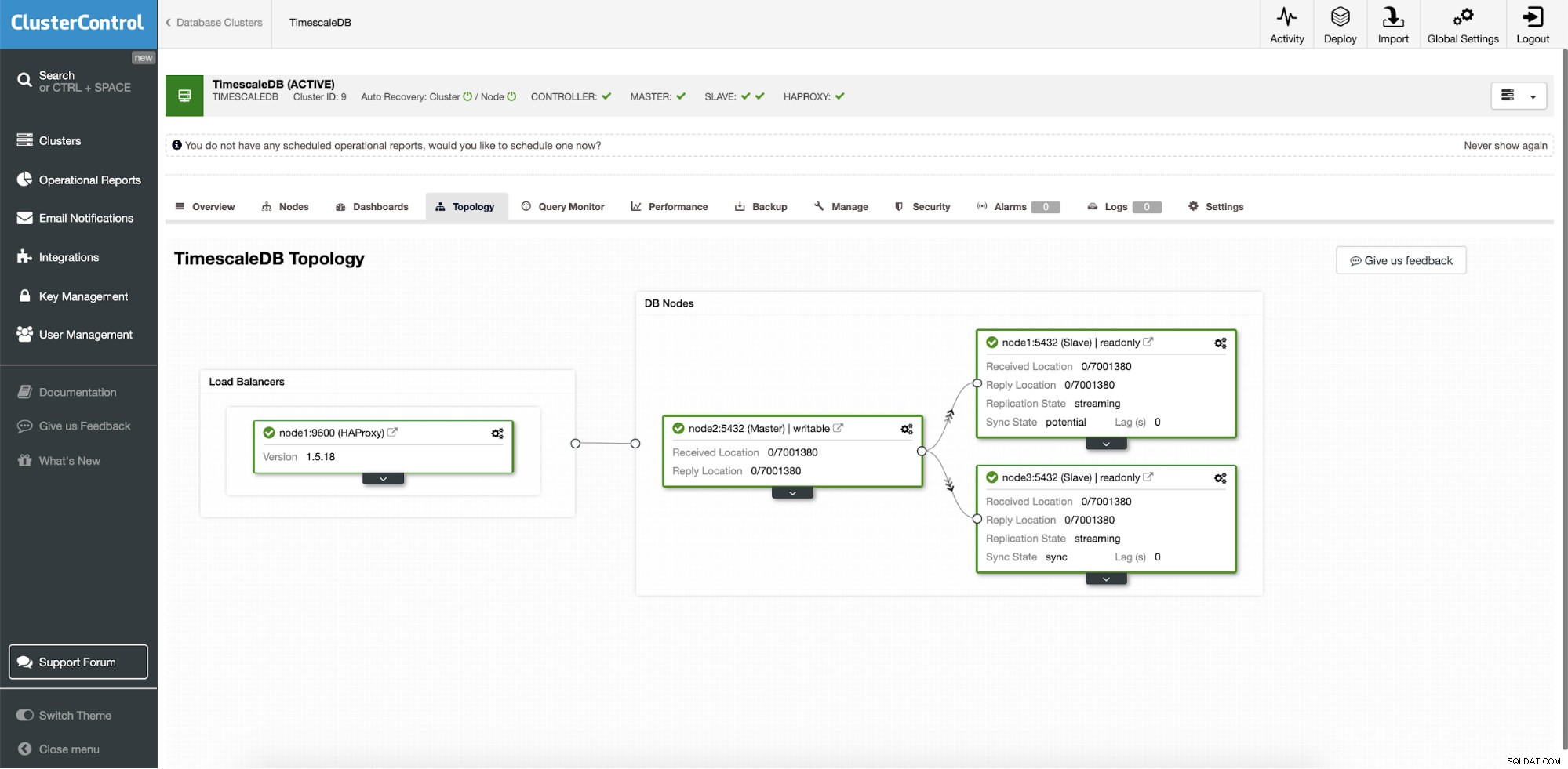 ClusterControl:Topologi
ClusterControl:Topologi Når Timescale er implementeret af ClusterControl, er automatisk gendannelse aktiveret som standard. Tilstanden kan kontrolleres i klyngebjælken.
 ClusterControl:Autogendannelsesklynge og nodetilstand
ClusterControl:Autogendannelsesklynge og nodetilstand Failover-konfiguration
Når replikeringsopsætningen er implementeret, er ClusterControl i stand til at overvåge opsætningen og automatisk gendanne eventuelle fejlbehæftede servere. Det kan også orkestrere ændringer i topologi.
ClusterControl automatisk failover blev designet med følgende principper:
- Sørg for, at masteren virkelig er død, før du failover
- Failover kun én gang
- Undgå failover til en inkonsekvent slave
- Skriv kun til masteren
- Gendan ikke automatisk den mislykkede master
Med de indbyggede algoritmer kan failover ofte udføres ret hurtigt, så du kan sikre de højeste SLA'er for dit databasemiljø.
Processen er konfigurerbar. Den leveres med flere parametre, som du kan bruge til at tilpasse gendannelse til dit miljøs specifikationer.
| max_replication_lag | Maksimal tilladt replikeringsforsinkelse i sekunder før |
| replikeringsstop_ved_fejl | Failover/switchover-procedurer vil mislykkes, hvis der opstår fejl, der kan forårsage tab af data. Aktiveret som standard. 0 betyder deaktiver, |
| replikation_auto_genopbygningsslave | Hvis SQL THREAD er stoppet, og fejlkoden er ikke-nul, vil slaven automatisk blive genopbygget. 1 betyder aktiver, 0 betyder deaktiver (standard). |
| replikation_failover_sortliste | Kommasepareret liste over værtsnavn:port-par. Sortlistede servere vil ikke blive betragtet som en kandidat under failover. replication_failover_blacklist ignoreres, hvis replication_failover_whitelist er indstillet. |
| replikation_failover_whitelist | Kommasepareret liste over værtsnavn:port-par. Kun hvidlistede servere vil blive betragtet som en kandidat under failover. Hvis ingen server på hvidlisten er tilgængelig (op/tilsluttet), vil failoveren mislykkes. replication_failover_blacklist ignoreres, hvis replication_failover_whitelist er indstillet. |
Failover-håndtering
Når en masterfejl opdages, oprettes en liste over masterkandidater, og en af dem vælges til at være den nye master. Det er muligt at have en hvidliste over servere, der skal promoveres til primær, samt en sortliste over servere, der ikke kan promoveres til primær. De resterende slaver er nu slaver fra den nye primære, og den gamle primære genstartes ikke.
Nedenfor kan vi se en simulering af knudefejl.
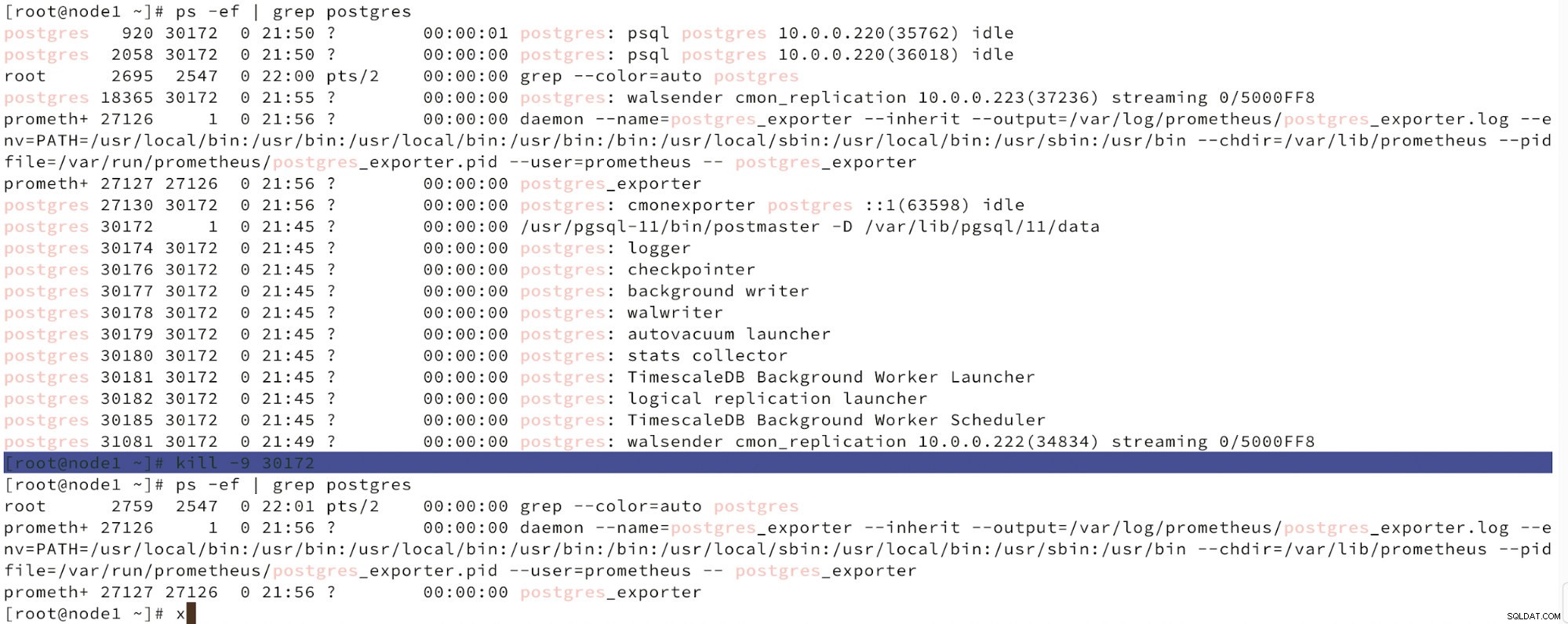 Simuler masterknudefejl med kill
Simuler masterknudefejl med kill Når nodefejl detekteres, og automatisk gendannelse detekteres, udløser ClusterControl job til at udføre failover. Nedenfor kan vi se handlinger, der er truffet for at genoprette klyngen.
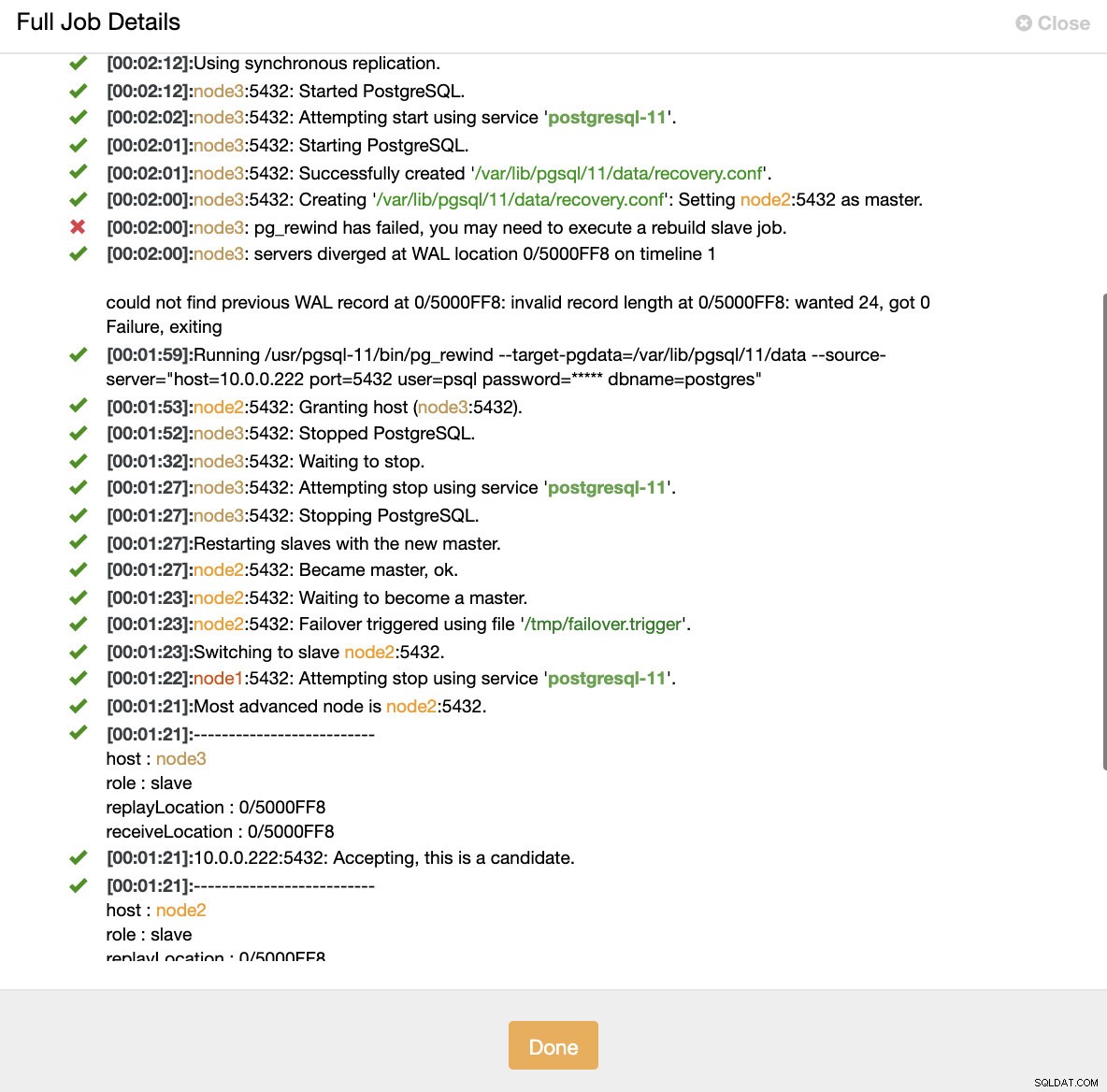 ClusterControl:Job udløst for at genopbygge klyngen
ClusterControl:Job udløst for at genopbygge klyngen ClusterControl holder med vilje den gamle primære offline, fordi det kan ske, at nogle af dataene ikke er blevet overført til standby-serverne. I et sådant tilfælde er den primære den eneste vært, der indeholder disse data, og du vil måske gendanne de manglende data manuelt. For dem, der ønsker at få den mislykkede primære automatisk genopbygget, er der en mulighed i cmon-konfigurationsfilen:replication_auto_rebuild_slave. Som standard er det deaktiveret, men når brugeren aktiverer det, vil den mislykkede primære blive genopbygget som en slave af den nye primære. Selvfølgelig, hvis der mangler data, som kun findes på den mislykkede primære, vil disse data gå tabt.
Genopbygning af standby-servere
En anden funktion er "Rebuild Replication Slave", som er tilgængelig for alle slaver (eller standby-servere) i replikeringsopsætningen. Dette skal f.eks. bruges, når du vil slette dataene på standby og genopbygge dem igen med en frisk kopi af data fra den primære. Det kan være en fordel, hvis en standby-server af en eller anden grund ikke er i stand til at oprette forbindelse og replikere fra den primære.
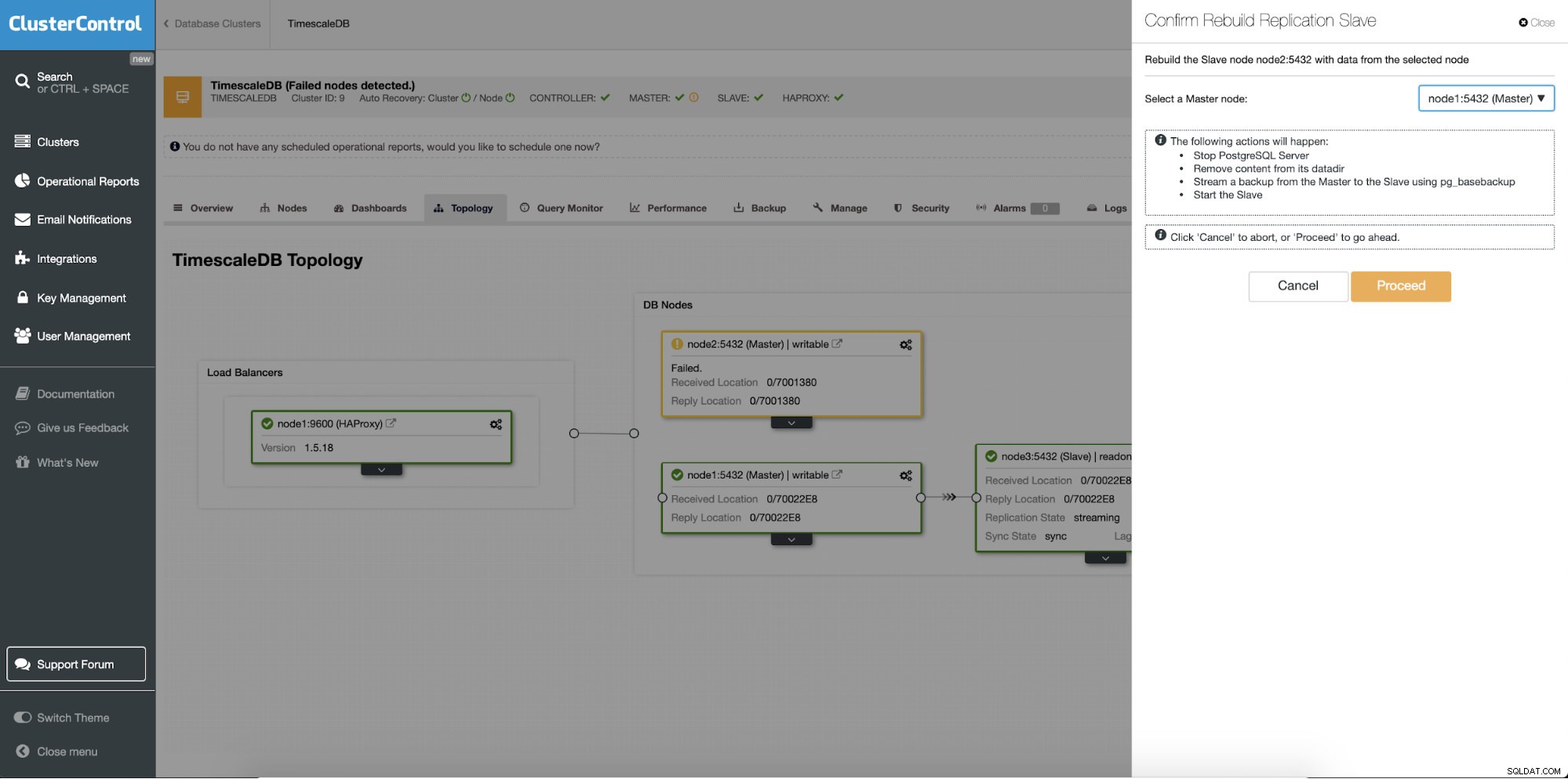 ClusterControl:Genopbyg replikeringsslave
ClusterControl:Genopbyg replikeringsslave  ClusterControl:Genopbyg slave
ClusterControl:Genopbyg slave