Bucketizing dato og klokkeslæt data involverer organisering af data i grupper, der repræsenterer faste tidsintervaller til analytiske formål. Ofte er inputtet tidsseriedata gemt i en tabel, hvor rækkerne repræsenterer målinger taget med regelmæssige tidsintervaller. For eksempel kan målingerne være temperatur- og luftfugtighedsaflæsninger, der tages hvert 5. minut, og du vil gruppere dataene ved hjælp af timebaserede buckets og beregne aggregater som gennemsnit pr. time. Selvom tidsseriedata er en almindelig kilde til bucket-baseret analyse, er konceptet lige så relevant for alle data, der involverer dato- og tidsattributter og tilhørende mål. For eksempel vil du måske organisere salgsdata i regnskabsår og beregne aggregater som den samlede salgsværdi pr. regnskabsår. I denne artikel dækker jeg to metoder til at samle dato- og tidsdata. Den ene bruger en funktion kaldet DATE_BUCKET, som i skrivende stund kun er tilgængelig i Azure SQL Edge. En anden bruger en brugerdefineret beregning, der emulerer DATE_BUCKET-funktionen, som du kan bruge i enhver version, udgave og variant af SQL Server og Azure SQL Database.
I mine eksempler vil jeg bruge eksempeldatabasen TSQLV5. Du kan finde scriptet, der opretter og udfylder TSQLV5 her og dets ER-diagram her.
DATE_BUCKET
Som nævnt er DATE_BUCKET-funktionen i øjeblikket kun tilgængelig i Azure SQL Edge. SQL Server Management Studio har allerede IntelliSense-understøttelse, som vist i figur 1:
 Figur 1:Intellisence-understøttelse af DATE_BUCKET i SSMS
Figur 1:Intellisence-understøttelse af DATE_BUCKET i SSMS
Funktionens syntaks er som følger:
DATE_BUCKET (Inddata oprindelse repræsenterer et ankerpunkt på tidens pil. Det kan være af enhver af de understøttede dato- og klokkeslætsdatatyper. Hvis uspecificeret, er standarden 1900, 1. januar, midnat. Du kan derefter forestille dig, at tidslinjen er opdelt i diskrete intervaller begyndende med oprindelsespunktet, hvor længden af hvert interval er baseret på inputtet bucket width og datodel . Førstnævnte er mængden og sidstnævnte er enheden. For f.eks. at organisere tidslinjen i 2-måneders enheder, skal du angive 2 som spandbredden input og måned som datodelen input.
Indtastningen tidsstemplet er et vilkårligt tidspunkt, der skal forbindes med dens indholdsspand. Dens datatype skal matche datatypen for input oprindelse . Indtastningen tidsstemplet er den dato- og tidsværdi, der er knyttet til de mål, du registrerer.
Funktionens output er så startpunktet for den indeholdende bøtte. Datatypen for output er den for input tidsstemplet .
Hvis det ikke allerede var indlysende, ville du normalt bruge funktionen DATE_BUCKET som et grupperingssætelement i forespørgslens GROUP BY-sætning og naturligvis også returnere det i SELECT-listen sammen med aggregerede mål.
Stadig lidt forvirret over funktionen, dens input og output? Måske ville et specifikt eksempel med en visuel afbildning af funktionens logik hjælpe. Jeg starter med et eksempel, der bruger inputvariabler og senere i artiklen viser den mere typiske måde, du ville bruge det på som en del af en forespørgsel mod en inputtabel.
Overvej følgende eksempel:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Du kan finde en visuel afbildning af funktionens logik i figur 2.
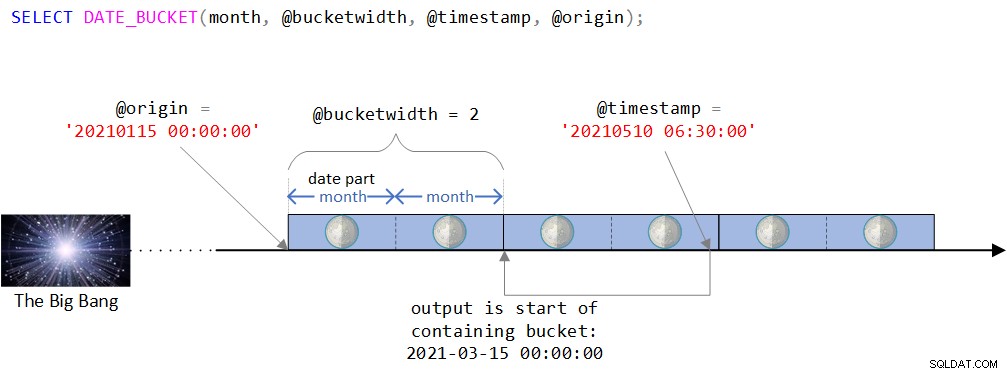 Figur 2:Visuel afbildning af DATE_BUCKET-funktionens logik
Figur 2:Visuel afbildning af DATE_BUCKET-funktionens logik
Som du kan se i figur 2, er oprindelsespunktet DATETIME2-værdien 15. januar 2021, midnat. Hvis dette oprindelsespunkt virker lidt mærkeligt, ville du have ret i intuitivt at fornemme, at du normalt ville bruge et mere naturligt, som i begyndelsen af et år eller begyndelsen af en dag. Faktisk ville du ofte være tilfreds med standarden, som som du husker er den 1. januar 1900 ved midnat. Jeg ønskede med vilje at bruge et mindre trivielt oprindelsespunkt for at kunne diskutere visse kompleksiteter, som måske ikke er relevante, når man bruger et mere naturligt. Mere om dette snart.
Tidslinjen opdeles derefter i diskrete 2-måneders intervaller, der starter med udgangspunktet. Inputtidsstemplet er DATETIME2-værdien 10. maj 2021 kl. 6:30.
Bemærk, at inputtidsstemplet er en del af den bucket, der starter den 15. marts 2021, midnat. Faktisk returnerer funktionen denne værdi som en DATETIME2-type værdi:
--------------------------- 2021-03-15 00:00:00.0000000
Emulerer DATE_BUCKET
Medmindre du bruger Azure SQL Edge, hvis du ønsker at samle dato- og tidsdata, skal du for øjeblikket oprette din egen tilpassede løsning for at efterligne, hvad DATE_BUCKET-funktionen gør. At gøre det er ikke alt for komplekst, men det er heller ikke for enkelt. Håndtering af dato- og tidsdata involverer ofte vanskelig logik og faldgruber, som du skal være forsigtig med.
Jeg bygger beregningen i trin og bruger de samme input, som jeg brugte med DATE_BUCKET-eksemplet, jeg viste tidligere:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Sørg for at inkludere denne del før hver af de kodeeksempler, jeg viser, hvis du rent faktisk vil køre koden.
I trin 1 bruger du DATEDIFF-funktionen til at beregne forskellen i datodel enheder mellem oprindelse og tidsstempel . Jeg vil referere til denne forskel som diff1 . Dette gøres med følgende kode:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Med vores eksempelinput returnerer dette udtryk 4.
Den vanskelige del her er, at du skal beregne, hvor mange hele enheder af datodel eksisterer mellem oprindelse og tidsstempel . Med vores eksempelinput er der 3 hele måneder mellem de to og ikke 4. Grunden til, at DATEDIFF-funktionen rapporterer 4, er, at når den beregner forskellen, ser den kun på den anmodede del af inputs og højere dele, men ikke lavere dele . Så når du spørger om forskellen i måneder, bekymrer funktionen sig kun om års- og månedsdelene af inputs og ikke om delene under måneden (dag, time, minut, sekund osv.). Der er faktisk 4 måneder mellem januar 2021 og maj 2021, men dog kun 3 hele måneder mellem de fulde input.
Formålet med trin 2 er så at beregne hvor mange hele enheder af datodel eksisterer mellem oprindelse og tidsstempel . Jeg vil referere til denne forskel som diff2 . For at opnå dette kan du tilføje diff1 enheder af datodel til oprindelse . Hvis resultatet er større end tidsstempel , trækker du 1 fra diff1 at beregne diff2 , ellers træk 0 fra og brug derfor diff1 som diff2 . Dette kan gøres ved hjælp af et CASE-udtryk, som sådan:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Dette udtryk returnerer 3, som er antallet af hele måneder mellem de to input.
Husk, at jeg tidligere nævnte, at jeg i mit eksempel med vilje brugte et oprindelsespunkt, der ikke er naturligt, som en rund begyndelse af en periode, så jeg kan diskutere visse kompleksiteter, der så kunne være relevante. For eksempel, hvis du bruger måned som datodelen og den nøjagtige begyndelse af en måned (1 af en eller anden måned ved midnat) som oprindelse, kan du roligt springe trin 2 over og bruge diff1 som diff2 . Det er fordi oprindelse + diff1 kan aldrig være> tidsstempel i et sådant tilfælde. Mit mål er dog at give et logisk ækvivalent alternativ til DATE_BUCKET-funktionen, der ville fungere korrekt for ethvert oprindelsespunkt, fælles eller ej. Så jeg vil inkludere logikken for trin 2 i mine eksempler, men husk bare, når du identificerer tilfælde, hvor dette trin ikke er relevant, kan du roligt fjerne den del, hvor du trækker output fra CASE-udtrykket fra.
I trin 3 identificerer du, hvor mange enheder af datodel der er i hele spande, der eksisterer mellem oprindelse og tidsstempel . Jeg vil referere til denne værdi som diff3 . Dette kan gøres med følgende formel:
diff3 = diff2 / <bucket width> * <bucket width>
Tricket her er, at når du bruger divisionsoperatoren / i T-SQL med heltalsoperander, får du heltalsdeling. For eksempel er 3/2 i T-SQL 1 og ikke 1,5. Udtrykket diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Dette udtryk returnerer 2, som er antallet af måneder i hele 2-måneders buckets, der er mellem de to input.
I trin 4, som er det sidste trin, tilføjer du diff3 enheder af datodel til oprindelse for at beregne starten af den indeholdende spand. Her er koden til at opnå dette:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denne kode genererer følgende output:
--------------------------- 2021-03-15 00:00:00.0000000
Som du husker, er dette det samme output produceret af DATE_BUCKET-funktionen for de samme input.
Jeg foreslår, at du prøver dette udtryk med forskellige input og dele. Jeg viser et par eksempler her, men prøv gerne dit eget.
Her er et eksempel, hvor oprindelse er lige lidt foran tidsstempel i måneden:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denne kode genererer følgende output:
--------------------------- 2021-03-10 06:30:01.0000000
Bemærk, at starten af den indeholdende spand er i marts.
Her er et eksempel, hvor oprindelse er på samme tidspunkt i måneden som tidsstempel :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denne kode genererer følgende output:
--------------------------- 2021-05-10 06:30:00.0000000
Bemærk, at denne gang starter den indeholdende spand i maj.
Her er et eksempel med 4-ugers spande:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Bemærk, at koden bruger ugen del denne gang.
Denne kode genererer følgende output:
--------------------------- 2021-02-12 00:00:00.0000000
Her er et eksempel med 15-minutters buckets:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Denne kode genererer følgende output:
--------------------------- 2021-02-03 21:15:00.0000000
Bemærk, at delen er minut . I dette eksempel vil du bruge 15-minutters buckets begyndende i bunden af timen, så et oprindelsespunkt, der er bunden af en hvilken som helst time, ville fungere. Faktisk ville et startpunkt, der har en minutenhed på 00, 15, 30 eller 45 med nuller i de nederste dele, med en hvilken som helst dato og time, fungere. Så den standard, som DATE_BUCKET-funktionen bruger til input oprindelse ville virke. Når du bruger det brugerdefinerede udtryk, skal du selvfølgelig være eksplicit om oprindelsespunktet. Så for at sympatisere med DATE_BUCKET-funktionen kan du bruge basisdatoen ved midnat, som jeg gør i eksemplet ovenfor.
Kan du i øvrigt se, hvorfor dette ville være et godt eksempel, hvor det er helt sikkert at springe trin 2 over i løsningen? Hvis du faktisk valgte at springe trin 2 over, får du følgende kode:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Det er klart, at koden bliver væsentligt enklere, når trin 2 ikke er nødvendig.
Grupper og aggregerer data efter dato- og tidsintervaller
Der er tilfælde, hvor du har brug for at samle dato- og tidsdata, der ikke kræver sofistikerede funktioner eller uhåndterlige udtryk. Antag for eksempel, at du vil forespørge på visningen Sales.OrderValues i TSQLV5-databasen, gruppere dataene årligt og beregne det samlede antal ordrer og værdier pr. år. Det er klart, at det er nok at bruge YEAR(orderdate)-funktionen som grupperingssætelementet, sådan som:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Denne kode genererer følgende output:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Men hvad nu hvis du ønskede at samle dataene efter din organisations regnskabsår? Nogle organisationer bruger et regnskabsår til regnskabs-, budget- og finansiel rapporteringsformål, ikke i overensstemmelse med kalenderåret. Lad os f.eks. sige, at din organisations regnskabsår kører på en regnskabskalender fra oktober til september og er angivet med det kalenderår, hvor regnskabsåret slutter. Så en begivenhed, der fandt sted den 3. oktober 2018, hører til det regnskabsår, der startede den 1. oktober 2018, sluttede den 30. september 2019 og er angivet med året 2019.
Dette er ret nemt at opnå med DATE_BUCKET-funktionen, som sådan:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Og her er koden, der bruger den brugerdefinerede logiske ækvivalent til DATE_BUCKET-funktionen:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Denne kode genererer følgende output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Jeg brugte variabler her for bucket-bredden og oprindelsespunktet for at gøre koden mere generaliseret, men du kan erstatte dem med konstanter, hvis du altid bruger de samme, og derefter forenkle beregningen efter behov.
Som en lille variation af ovenstående, antag, at dit regnskabsår løber fra den 15. juli i et kalenderår til den 14. juli i det næste kalenderår og er angivet med det kalenderår, som begyndelsen af regnskabsåret tilhører. Så en begivenhed, der fandt sted den 18. juli 2018, tilhører regnskabsåret 2018. En begivenhed, der fandt sted den 14. juli 2018, hører til regnskabsåret 2017. Ved at bruge DATE_BUCKET-funktionen ville du opnå dette på denne måde:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Du kan se ændringerne i forhold til det foregående eksempel i kommentarerne.
Og her er koden, der bruger den brugerdefinerede logiske ækvivalent til DATE_BUCKET-funktionen:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Denne kode genererer følgende output:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Selvfølgelig er der alternative metoder, du kan bruge i specifikke tilfælde. Tag eksemplet før det sidste, hvor regnskabsåret løber fra oktober til september og angives med det kalenderår, hvor regnskabsåret slutter. I et sådant tilfælde kan du bruge følgende, meget enklere udtryk:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Og så ville din forespørgsel se sådan ud:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Men hvis du ønsker en generaliseret løsning, der ville fungere i mange flere tilfælde, og som du kunne parametrisere, vil du naturligvis gerne bruge den mere generelle form. Hvis du har adgang til DATE_BUCKET-funktionen, er det fantastisk. Hvis du ikke gør det, kan du bruge den tilpassede logiske ækvivalent.
Konklusion
DATE_BUCKET-funktionen er en ganske praktisk funktion, der gør det muligt for dig at samle dato- og tidsdata. Det er nyttigt til at håndtere tidsseriedata, men også til at samle data, der involverer dato- og tidsattributter. I denne artikel forklarede jeg, hvordan DATE_BUCKET-funktionen fungerer og gav en tilpasset logisk ækvivalent, hvis den platform, du bruger, ikke understøtter den.