I dag er replikering givet i et høj tilgængelighed og fejltolerant miljø for stort set enhver databaseteknologi, du bruger. Det er et emne, som vi har set igen og igen, men som aldrig bliver gammelt.
Hvis du bruger TimescaleDB, er den mest almindelige type replikering streaming replikering, men hvordan fungerer det?
I denne blog vil vi gennemgå nogle begreber relateret til replikering, og vi vil fokusere på streaming replikering til TimescaleDB, som er en funktionalitet, der er arvet fra den underliggende PostgreSQL-motor. Derefter vil vi se, hvordan ClusterControl kan hjælpe os med at konfigurere det.
Så streaming-replikering er baseret på at sende WAL-posterne og få dem anvendt på standby-serveren. Så lad os først se, hvad WAL er.
WAL
Write Ahead Log (WAL) er en standardmetode til at sikre dataintegritet, den er automatisk aktiveret som standard.
WAL'erne er REDO-logfilerne i TimescaleDB. Men hvad er REDO-logfilerne?
REDO-logfiler indeholder alle ændringer, der blev foretaget i databasen, og de bruges af replikering, gendannelse, online backup og punkt-i-tidsgendannelse (PITR). Eventuelle ændringer, der ikke er blevet anvendt på datasiderne, kan laves om fra REDO-logfilerne.
Brug af WAL resulterer i et betydeligt reduceret antal diskskrivninger, fordi kun logfilen skal skylles til disken for at garantere, at en transaktion er begået, snarere end hver datafil, der ændres af transaktionen.
En WAL-record specificerer, bit for bit, ændringerne i dataene. Hver WAL-post vil blive tilføjet til en WAL-fil. Indsættelsespositionen er et logsekvensnummer (LSN), der er en byteforskydning i logfilerne, som stiger med hver ny post.
WAL'erne er gemt i mappen pg_wal under databiblioteket. Disse filer har en standardstørrelse på 16MB (størrelsen kan ændres ved at ændre --with-wal-segsize-konfigurationsindstillingen, når serveren bygges). De har et unikt trinvist navn i følgende format:"00000001 00000000 00000000".
Antallet af WAL-filer indeholdt i pg_wal vil afhænge af den værdi, der er tildelt til parametrene min_wal_size og max_wal_size i postgresql.conf-konfigurationsfilen.
En parameter, som vi skal konfigurere, når vi konfigurerer alle vores TimescaleDB-installationer, er wal_level. Det bestemmer, hvor meget information der skrives til WAL. Standardværdien er minimal, hvilket kun skriver den information, der er nødvendig for at komme sig efter et nedbrud eller øjeblikkelig nedlukning. Arkiv tilføjer logning påkrævet til WAL-arkivering; hot_standby tilføjer yderligere information, der kræves for at køre skrivebeskyttede forespørgsler på en standby-server; og endelig tilføjer logical information, der er nødvendig for at understøtte logisk afkodning. Denne parameter kræver en genstart, så det kan være svært at ændre på kørende produktionsdatabaser, hvis vi har glemt det.
Streamende replikering
Streaming-replikering er baseret på logforsendelsesmetoden. WAL-posterne flyttes direkte fra en databaseserver til en anden for at blive anvendt. Vi kan sige, at det er en kontinuerlig PITR.
Denne overførsel udføres på to forskellige måder, ved at overføre WAL-poster én fil (WAL-segment) ad gangen (filbaseret logforsendelse) og ved at overføre WAL-poster (en WAL-fil er sammensat af WAL-poster) på flueben (rekordbaseret) logforsendelse), mellem en masterserver og en eller flere slaveservere uden at vente på, at WAL-filen udfyldes.
I praksis vil en proces kaldet WAL-modtager, der kører på slaveserveren, oprette forbindelse til masterserveren ved hjælp af en TCP/IP-forbindelse. På masterserveren eksisterer der en anden proces, kaldet WAL-afsender, og den er ansvarlig for at sende WAL-registre til slaveserveren, efterhånden som de sker.
Streaming replikering kan repræsenteres som følgende:
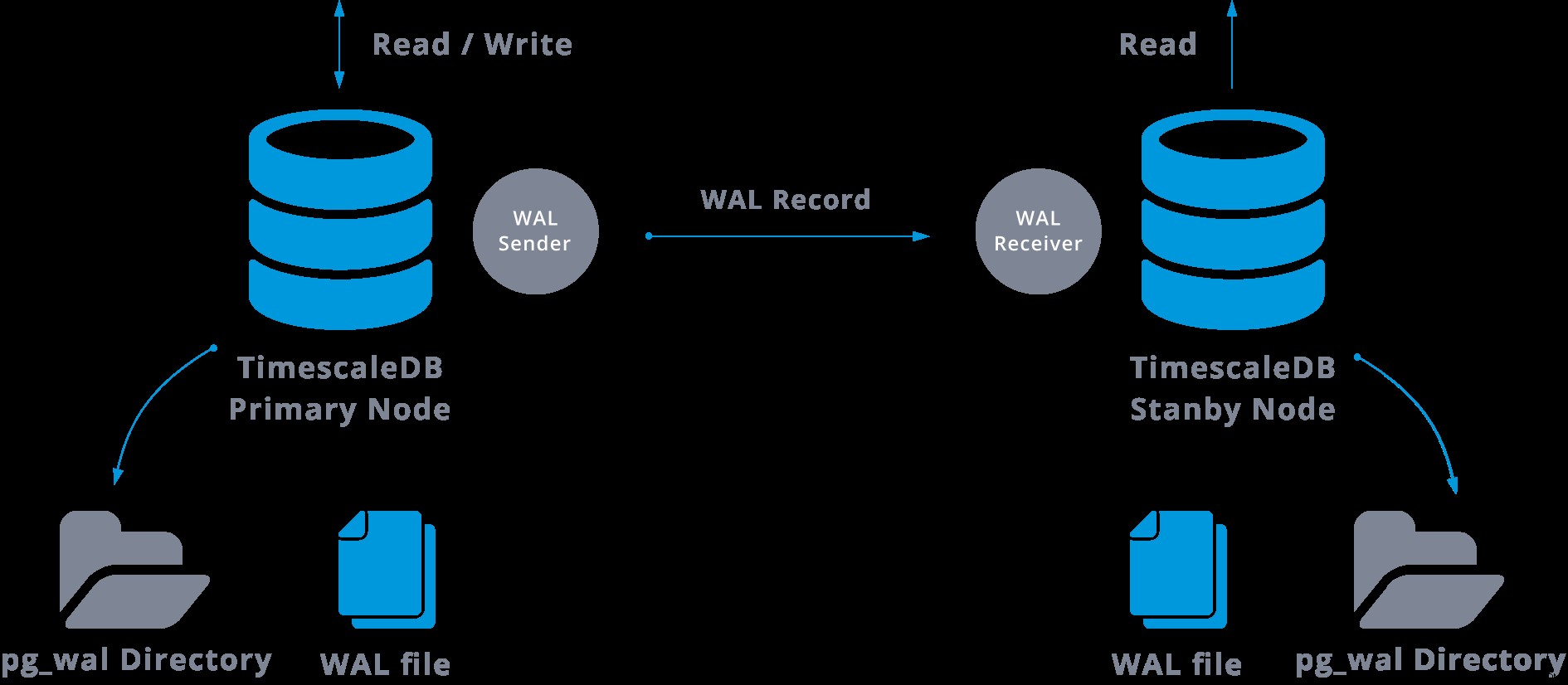
Ved at se på ovenstående diagram kan vi tænke, hvad der sker, når kommunikationen mellem WAL-afsenderen og WAL-modtageren svigter?
Når vi konfigurerer streamingreplikering, har vi mulighed for at aktivere WAL-arkivering.
Dette trin er faktisk ikke obligatorisk, men er ekstremt vigtigt for robust replikeringsopsætning, da det er nødvendigt at undgå, at hovedserveren genbruger gamle WAL-filer, som endnu ikke er blevet anvendt på slaven. Hvis dette sker, bliver vi nødt til at genskabe replikaen fra bunden.
Når vi konfigurerer replikering med kontinuerlig arkivering, starter vi fra en sikkerhedskopi, og for at nå tilstanden til synkronisering med masteren, skal vi anvende alle de ændringer, der er hostet i WAL, der skete efter sikkerhedskopieringen. Under denne proces vil standby først gendanne alle de tilgængelige WAL på arkivplaceringen (gøres ved at kalde restore_command). Restore_command vil mislykkes, når vi når den sidste arkiverede WAL-post, så efter det, vil standbyen kigge på pg_wal-mappen for at se, om ændringen eksisterer der (dette er faktisk lavet for at undgå datatab, når masterserveren går ned og nogle ændringer, der allerede er flyttet ind i replikaen og anvendt der, er endnu ikke blevet arkiveret).
Hvis det mislykkes, og den anmodede post ikke findes der, vil den begynde at kommunikere med masteren gennem streaming-replikering.
Når streamingreplikering mislykkes, vil den gå tilbage til trin 1 og gendanne posterne fra arkivet igen. Denne løkke med hentning fra arkivet, pg_wal og via streaming-replikering fortsætter, indtil serveren stoppes eller failover udløses af en triggerfil.
Dette vil være et diagram over en sådan konfiguration:
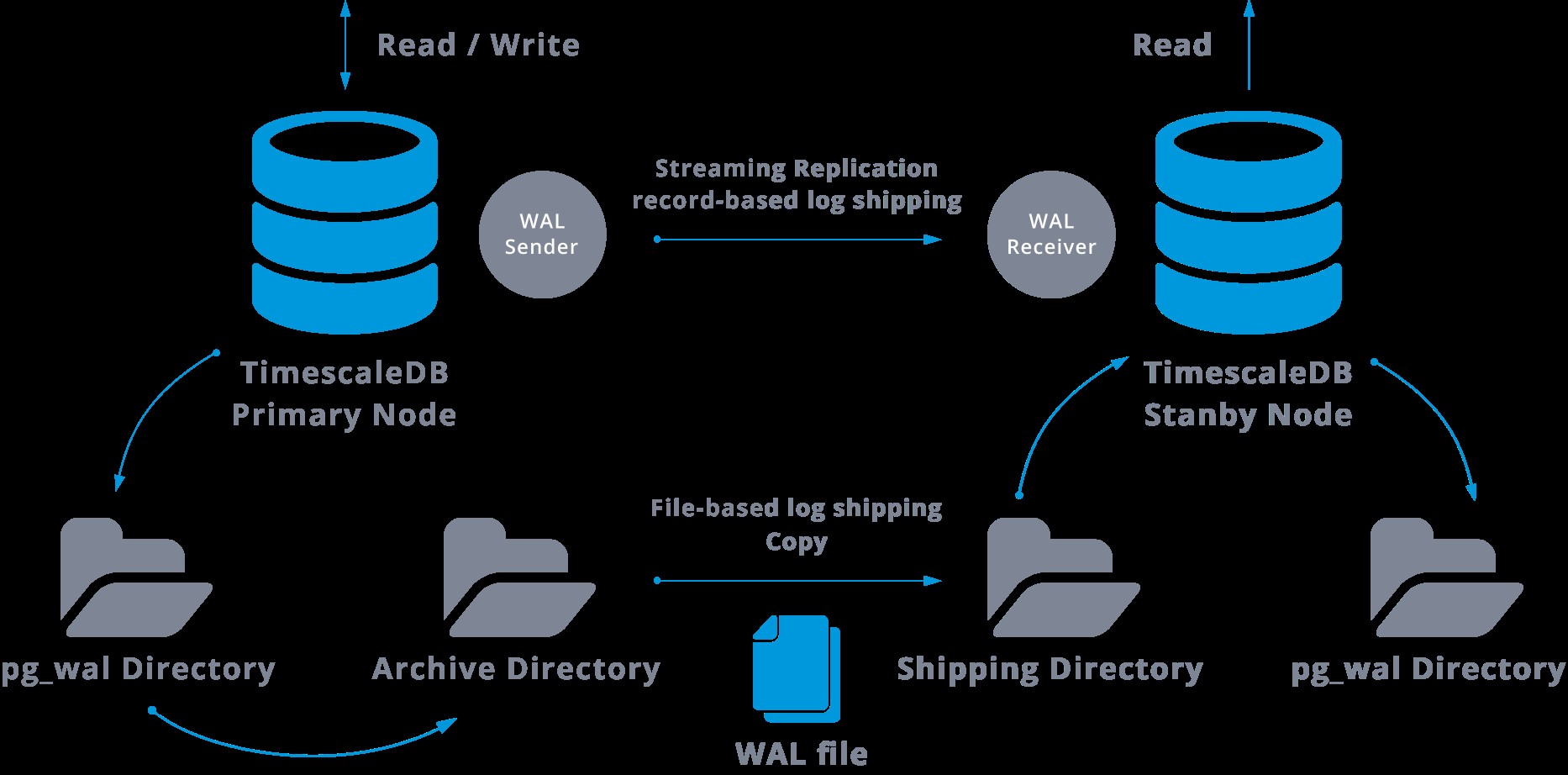
Streaming-replikering er som standard asynkron, så på et givet tidspunkt kan vi have nogle transaktioner, der kan begås i masteren og endnu ikke replikeres til standby-serveren. Dette indebærer et vist potentielt datatab.
Denne forsinkelse mellem commit og virkningen af ændringerne i replikaen formodes dog at være virkelig lille (nogle millisekunder), naturligvis forudsat at replikaserveren er kraftig nok til at holde trit med belastningen.
I de tilfælde, hvor selv risikoen for et lille datatab ikke er acceptabel, kan vi bruge funktionen til synkron replikering.
I synkron replikering vil hver commit af en skrivetransaktion vente, indtil der modtages bekræftelse af, at commit er blevet skrevet til skrive-ahead-log på disken på både den primære og standby-serveren.
Denne metode minimerer muligheden for tab af data, da det skal ske, at både master og standby svigter på samme tid.
Den åbenlyse ulempe ved denne konfiguration er, at responstiden for hver skrivetransaktion øges, da vi skal vente til alle parter har svaret. Så tidspunktet for en commit er som minimum rundrejsen mellem mesteren og replikaen. Skrivebeskyttede transaktioner vil ikke blive påvirket af det.
For at opsætte synkron replikering skal hver af standby-serverne angive et applikationsnavn i filen primary_conninfo for recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Vi skal også specificere listen over de standby-servere, der skal deltage i den synkrone replikering:synchronous_standby_name ='slaveX,slaveY'.
Vi kan opsætte en eller flere synkrone servere, og denne parameter specificerer også, hvilken metode (FØRST og ALLE) der skal vælges synkrone standbys fra de anførte.
For at implementere TimescaleDB med streaming-replikeringsopsætninger (synkron eller asynkron), kan vi bruge ClusterControl, som vi kan se her.
Efter at vi har konfigureret vores replikering, og den er oppe og køre, skal vi have nogle ekstra funktioner til overvågning og backupstyring. ClusterControl giver os mulighed for at overvåge og administrere sikkerhedskopier/retention af vores TimescaleDB-klynge fra samme sted uden noget eksternt værktøj.
Sådan konfigureres streamingreplikering på TimescaleDB
Opsætning af streamingreplikering er en opgave, der kræver nogle trin, der skal følges grundigt. Hvis du vil konfigurere det manuelt, kan du følge vores blog om dette emne.
Du kan dog implementere eller importere din nuværende TimescaleDB på ClusterControl, og derefter kan du konfigurere streaming-replikering med nogle få klik. Lad os se, hvordan vi kan gøre det.
Til denne opgave antager vi, at du har din TimescaleDB-klynge administreret af ClusterControl. Gå til ClusterControl -> Vælg Cluster -> Cluster Actions -> Tilføj replikeringsslave.
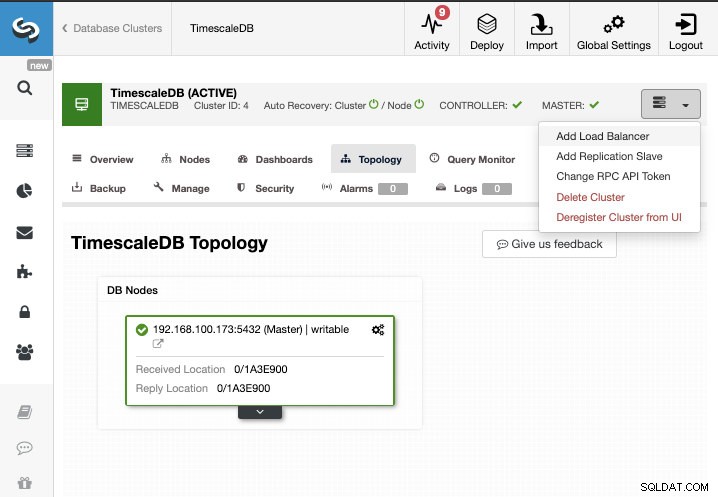
Vi kan oprette en ny replikeringsslave (standby), eller vi kan importere en eksisterende. I dette tilfælde opretter vi en ny.
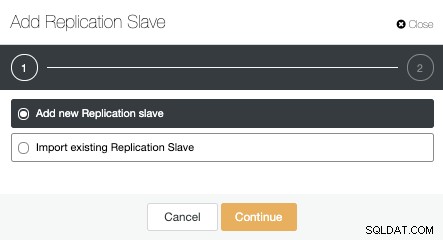
Nu skal vi vælge Master-noden, tilføje IP-adressen eller værtsnavnet til den nye standby-server og databaseporten. Vi kan også angive, om vi ønsker, at ClusterControl skal installere softwaren, og om vi vil konfigurere synkron eller asynkron streamingreplikering.
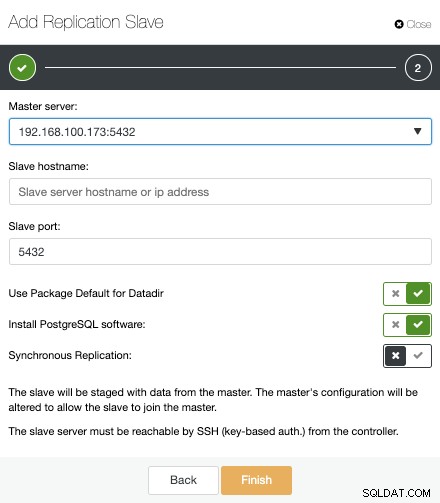
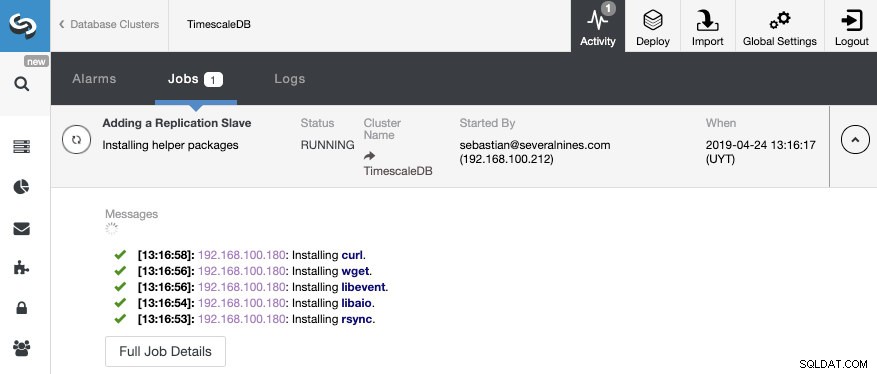
Det er alt. Vi behøver kun at vente, indtil ClusterControl afslutter jobbet. Vi kan overvåge status fra aktivitetssektionen.
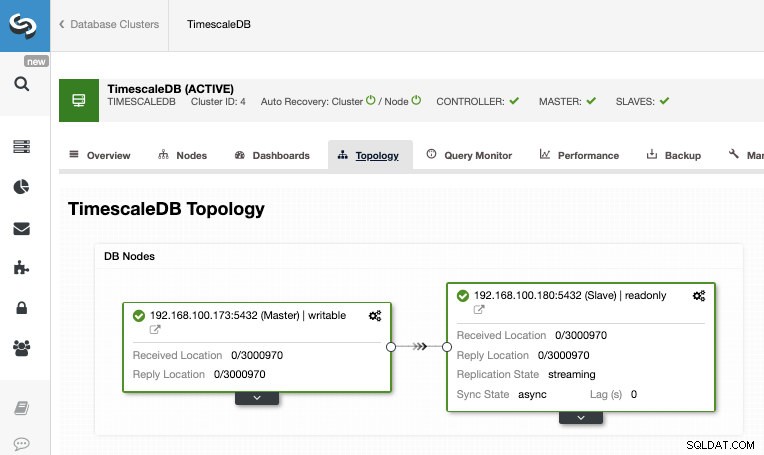
Når jobbet er afsluttet, bør vi have konfigureret streamingreplikeringen, og vi kan kontrollere den nye topologi i sektionen ClusterControl Topologivisning.
Ved at bruge ClusterControl kan du også udføre adskillige administrationsopgaver på din TimescaleDB som backup, monitor og advarsel, automatisk failover, tilføje noder, tilføje load balancere og endnu mere.
Failover
Som vi kunne se, bruger TimescaleDB en strøm af WAL-poster (Write-ahead-log) til at holde standby-databaserne synkroniseret. Hvis hovedserveren fejler, indeholder standby næsten alle data fra hovedserveren og kan hurtigt gøres til den nye masterdatabaseserver. Dette kan være synkront eller asynkront og kan kun gøres for hele databaseserveren.
For effektivt at sikre høj tilgængelighed er det ikke nok at have en master-standby-arkitektur. Vi er også nødt til at aktivere en eller anden automatisk form for failover, så hvis noget fejler, kan vi have den mindst mulige forsinkelse med at genoptage normal funktionalitet.
TimescaleDB inkluderer ikke en automatisk failover-mekanisme til at identificere fejl på masterdatabasen og give slaven besked om at tage ejerskab, så det vil kræve lidt arbejde på DBA's side. Du vil også kun have én server, der fungerer, så genskabelse af master-standby-arkitekturen skal udføres, så vi vender tilbage til den samme normale situation, som vi havde før problemet.
ClusterControl inkluderer en automatisk failover-funktion til TimescaleDB for at forbedre den gennemsnitlige tid til reparation (MTTR) i dit høje tilgængelighedsmiljø. I tilfælde af fejl vil ClusterControl promovere den mest avancerede slave til master, og den omkonfigurerer de(n) resterende slave(r) til at oprette forbindelse til den nye master. HAProxy kan også implementeres automatisk for at tilbyde et enkelt databaseslutpunkt til applikationer, så de ikke påvirkes af en ændring af masterserveren.
Begrænsninger
Relaterede ressourcer ClusterControl for TimescaleDB Sådan implementerer du nemt TimescaleDB PostgreSQL-streamingreplikering - et dybt dykVi har nogle velkendte begrænsninger, når vi bruger Streaming Replication:
- Vi kan ikke replikere til en anden version eller arkitektur
- Vi kan ikke ændre noget på standby-serveren
- Vi har ikke meget detaljerede oplysninger om, hvad vi kan replikere
Så for at overvinde disse begrænsninger har vi den logiske replikeringsfunktion. Hvis du vil vide mere om denne replikeringstype, kan du tjekke følgende blog.
Konklusion
En master-standby-topologi har mange forskellige anvendelser som analyse, backup, høj tilgængelighed, failover. Under alle omstændigheder er det nødvendigt at forstå, hvordan streaming-replikeringen fungerer på TimescaleDB. Det er også nyttigt at have et system til at administrere hele klyngen og give dig mulighed for at skabe denne topologi på en nem måde. I denne blog så vi, hvordan man opnår det ved at bruge ClusterControl, og vi gennemgik nogle grundlæggende begreber om streamingreplikering.